hive中的几种join到底有什么区别
目录
- 数据:
- 1. left join
- 2. join
- 3. full join
- 4. Join…on 1=1
- 5. union
- 6. union all
- union和union all的区别
- 总结
hive中,几种join的区别
数据:
tom,1
jey,2
lilly,7
lilly,8
tom,1
lilly,3
may,4
bob,5
以上两个为数据,没有什么意义,全是为了检测join的使用
看一下两张表,其实可以看出来,在name一行有重复的,也有不重复的,在id一行1表完全包含2表
1. left join
left join会把左边的表所有数据列出来,当左边表有而右边表没有的时候,就会用null代替
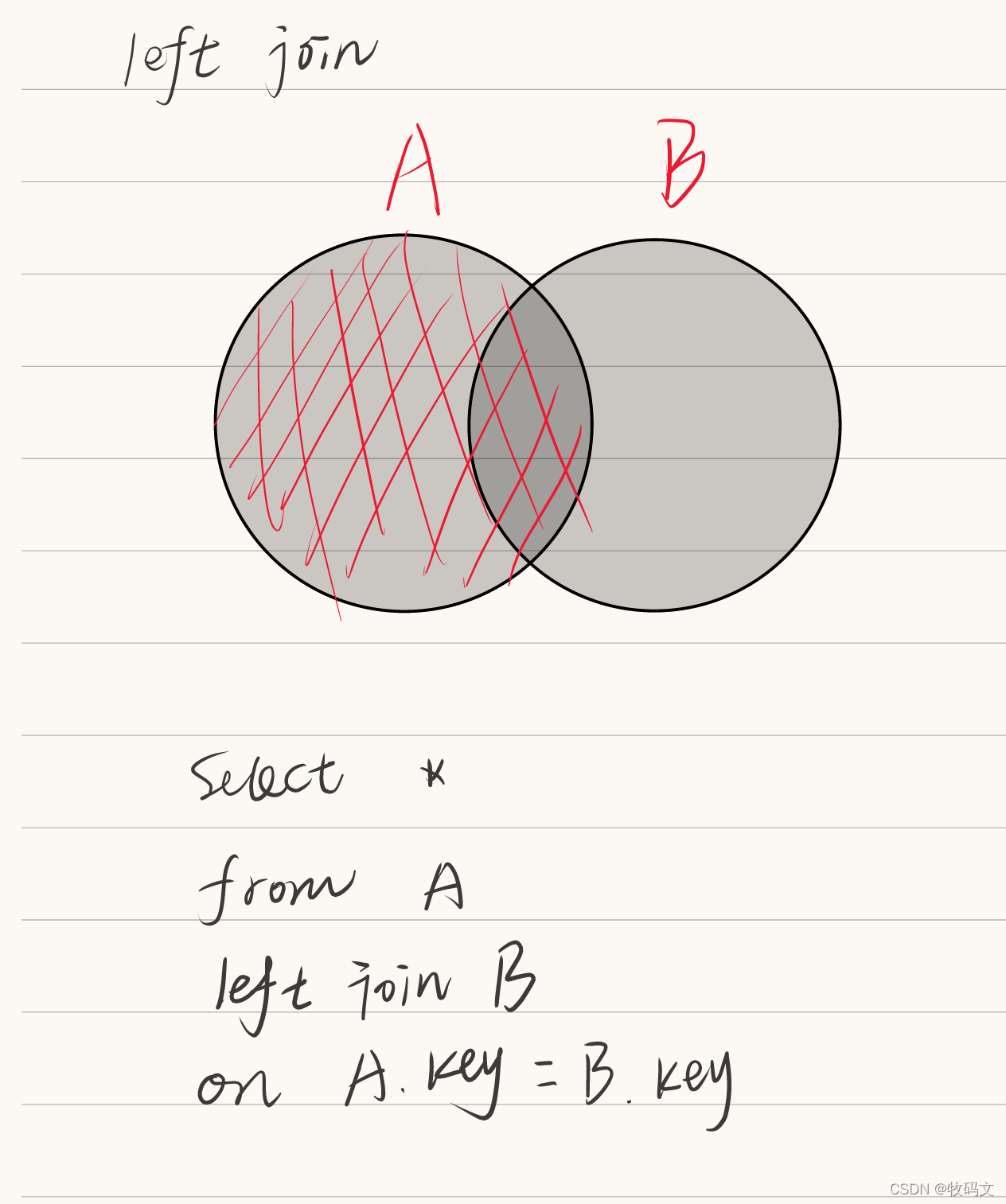
select * from jn1 left join jn2 on jn1.name=jn2.name;
jn1.name jn1.id jn2.name jn2.id
tom 1 tom 1
jey 2 NULL NULL
lilly 7 lilly 3
lilly 8 lilly 3
而右表有左表没有的就不会显示了
2. join
join会把两个表共有的部分筛选出来
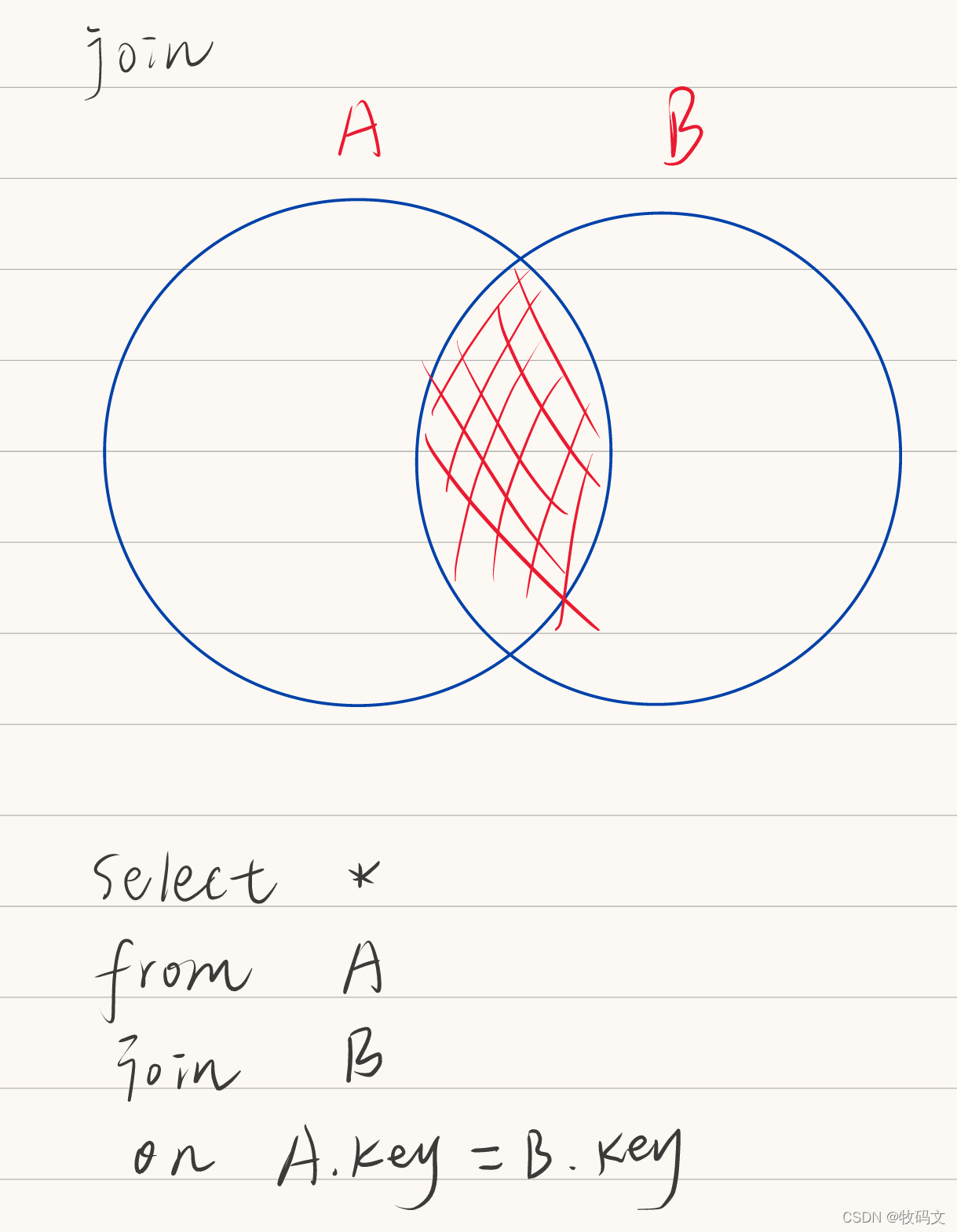
select * from jn1 join jn2 on jn1.name=jn2.name;
jn1.name jn1.id jn2.name jn2.id
tom 1 tom 1
lilly 7 lilly 3
lilly 8 lilly 3
可以看到,共有的部分筛选了出来
3. full join
会把两者没有的有的全部数据都选出来,没有的显示空值
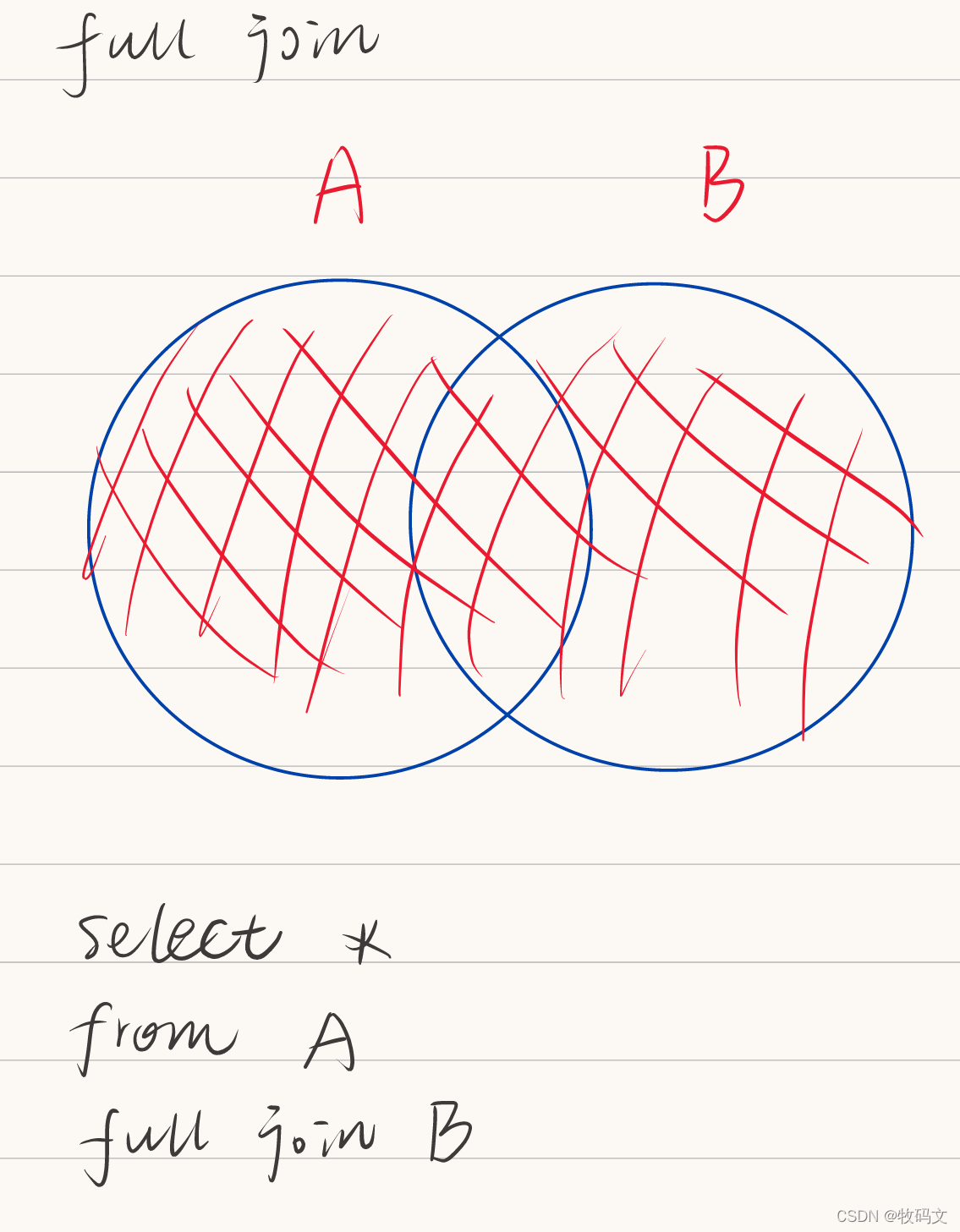
select * from jn1 full join jn2 on jn1.name = jn2.name;
jn1.name jn1.id jn2.name jn2.id
tom 1 tom 1
NULL NULL bob 5
jey 2 NULL NULL
lilly 7 lilly 3
lilly 8 lilly 3
NULL NULL may 4
4. Join…on 1=1
这种情况会有笛卡尔积的产生,就是表1的每一行都会和表2匹配一下,这样就会产生指数级的增长
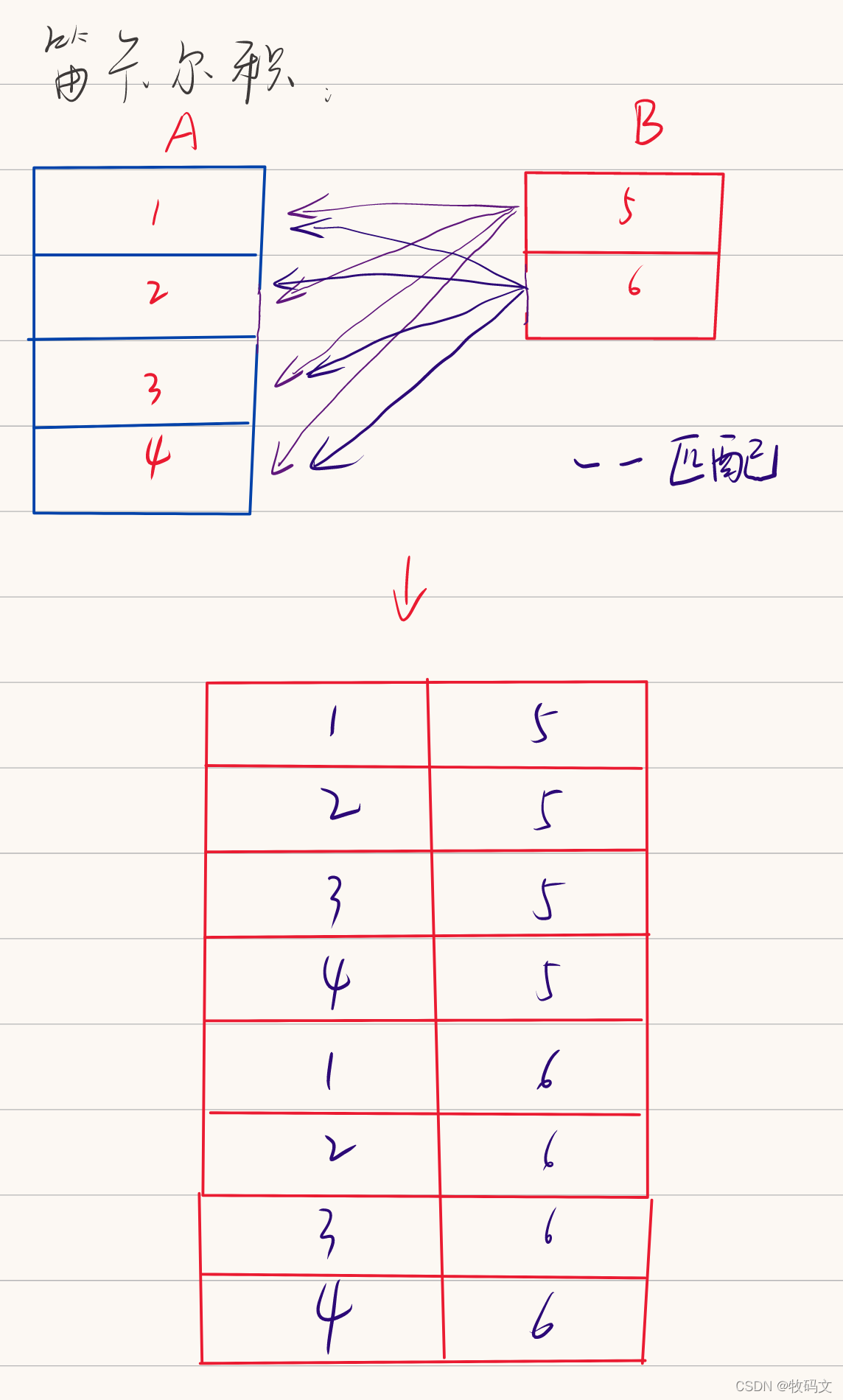
select * from jn1 join jn2 on 1=1;
jn1.name jn1.id jn2.name jn2.id
tom 1 lilly 3
tom 1 bob 5
tom 1 may 4
tom 1 tom 1
jey 2 lilly 3
jey 2 bob 5
jey 2 may 4
jey 2 tom 1
lilly 7 lilly 3
lilly 7 bob 5
lilly 7 may 4
lilly 7 tom 1
lilly 8 lilly 3
lilly 8 bob 5
lilly 8 may 4
lilly 8 tom 1
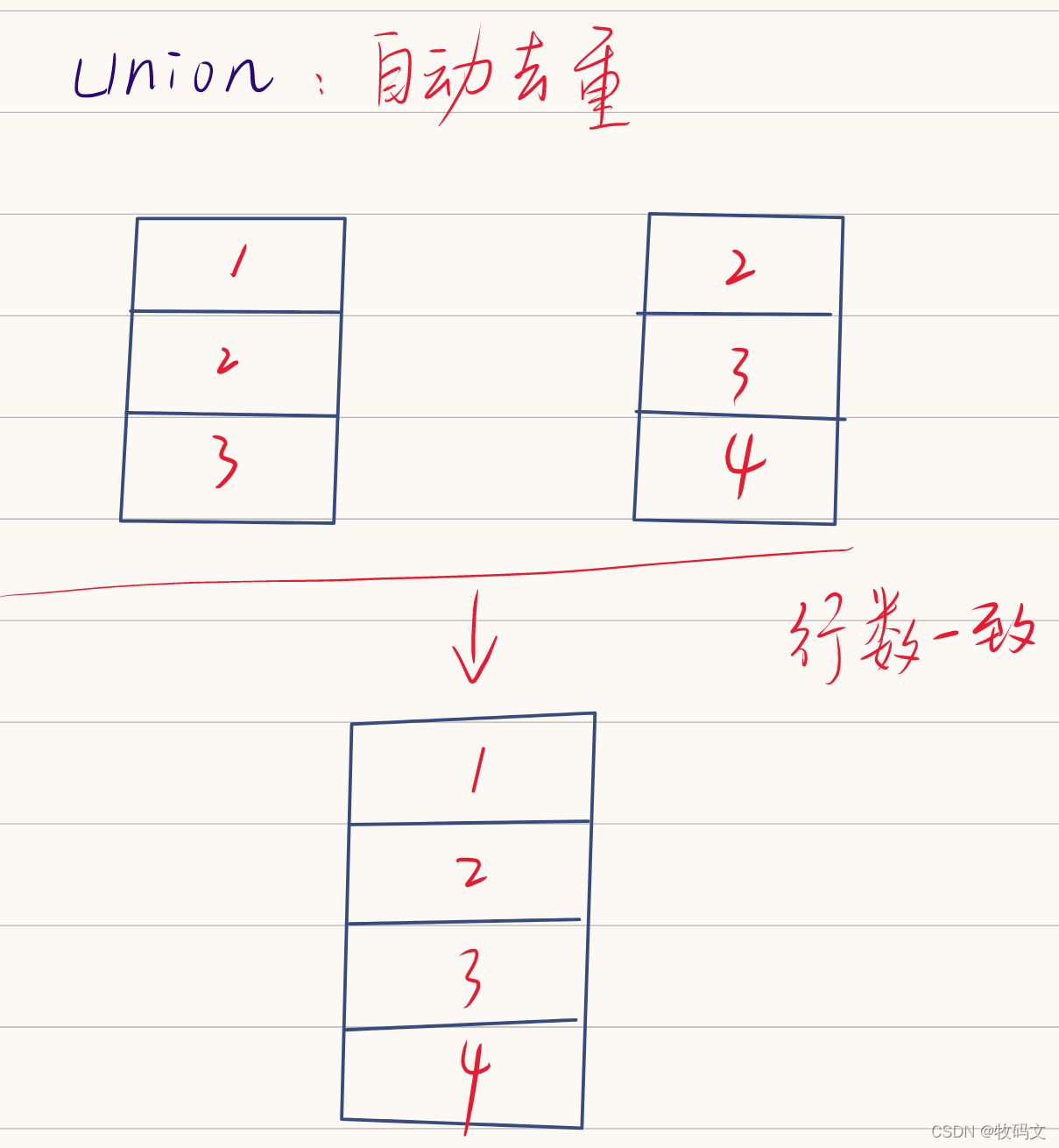
5. union
会把查询结果拼接起来,但是要求两个查询结果的行数必须保持一致
否则会报错
FAILED: SemanticException Schema of both sides of union should match
select * from jn1 union select * from jn2;
_u1.name _u1.id
jey 2
lilly 7
bob 5
lilly 3
lilly 8
tom 1
may 4
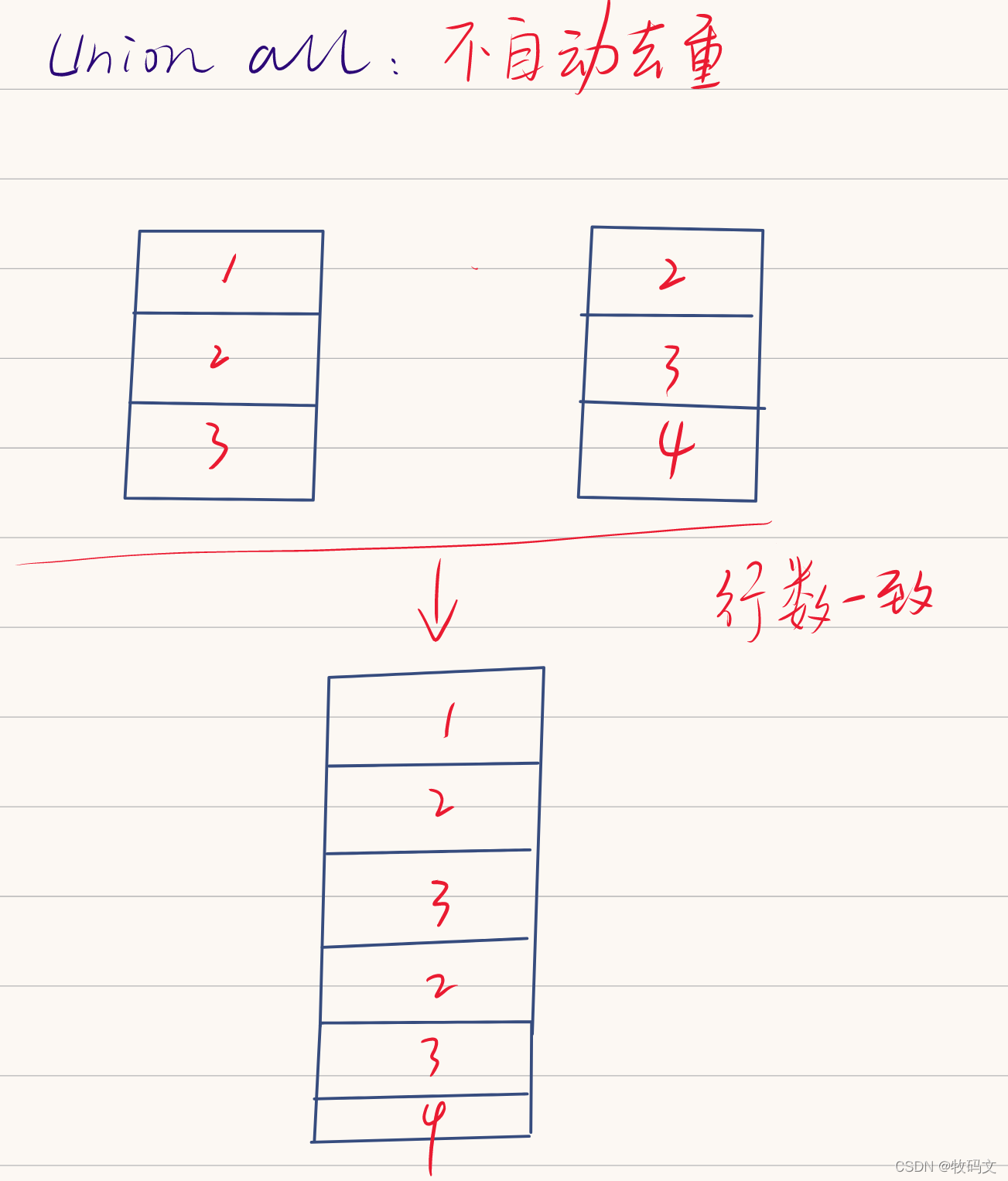
6. union all
union会组合起来,那么union all可以不
select * from jn1 union all select * from jn2;
lilly 3
tom 1
may 4
bob 5
tom 1
jey 2
lilly 7
lilly 8
union和union all的区别
从上述的两个结果就可以看出来了两者的区别,union会自动去重处理,所以结果把重复的数据去掉了,而union all则不会去重。
注意tips:left join会用之后,right join不用说了吧
总结
到此这篇关于hive中的几种join到底有什么区别的文章就介绍到这了,更多相关hive的join区别内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

hive中的几种join到底有什么区别
目录 数据: 1. left join 2. join 3. full join 4. Join…on 1=1 5. union 6. union all union和union all的区别 总结 hive中,几种join的区别 数据: tom,1jey,2lilly,7lilly,8 tom,1lilly,3may,4bob,5 以上两个为数据,没有什么意义,全是为了检测join的使用 看一下两张表,其实可以看出来,在name一行有重复的,也有不重复的,在id一行1表完全包含2表 1. le
-
Typescript 中的 interface 和 type 到底有什么区别详解
interface VS type 大家使用 typescript 总会使用到 interface 和 type,官方规范 稍微说了下两者的区别 An interface can be named in an extends or implements clause, but a type alias for an object type literal cannot. An interface can have multiple merged declarations, but a type
-
Mysql中常用的几种join连接方式总结
目录 1.内连接 2.左连接 3.右连接 4.查询左表独有数据 5.查询右表独有数据 6.全连接 7.查询左右表各自的独有的数据 总结 1.首先准备两张表 部门表: 员工表: 以下我们就对这两张表进行不同的连接操作 1.内连接 作用: 查询两张表的共有部分 语句:Select from tableA A Inner join tableB B on A.Key = B.Key 示例:SELECT * from employee e INNER JOIN department d on e.dep
-
Hive HQL支持2种查询语句风格
目录 背景 风格一 风格二 两种风格的区别 背景 在平时业务运营分析中经常会提取数据,也就是大家俗称的Sql Boy,表哥表姐,各大公司数据中台现在大部分用的都是基于Hadoop的分布式系统基础架构,用的比较多的有Hive数据仓库工具,数据分析师在数据查询时用的就是HQL,语法与Mysql有所不同,基本每天都会写大量的HQL语句,但你有试过哪些风格的写法呢?哪种风格的查询语句更容易理解呢?可能不同的人有不同的看法,下面展示具体的风格代码样式,看看你喜欢哪种 Hadoop是一个由Apache基金会
-
浅谈JS中的三种字符串连接方式及其性能比较
工作中经常会碰到要把2个或多个字符串连接成一个字符串的问题,在JS中处理这类问题一般有三种方法,这里将它们一一列出顺便也对它们的性能做个具体的比较. 第一种方法 用连接符"+"把要连接的字符串连起来: str="a"; str+="b"; 毫无疑问,这种方法是最便捷快速的,如果只连接100个以下的字符串建议用这种方法最方便. 第二种方法 以数组作为中介用 join 连接字符串: var arr=new Array(); arr.push(a);
-
浅谈SQL Server中的三种物理连接操作(性能比较)
在SQL Server中,我们所常见的表与表之间的Inner Join,Outer Join都会被执行引擎根据所选的列,数据上是否有索引,所选数据的选择性转化为Loop Join,Merge Join,Hash Join这三种物理连接中的一种.理解这三种物理连接是理解在表连接时解决性能问题的基础,下面我来对这三种连接的原理,适用场景进行描述. 嵌套循环连接(Nested Loop Join) 循环嵌套连接是最基本的连接,正如其名所示那样,需要进行循环嵌套,嵌套循环是三种方式中唯一支持不等式连接的
-
Java开发中的23种设计模式详解(推荐)
设计模式(Design Patterns) --可复用面向对象软件的基础 设计模式(Design pattern)是一套被反复使用.多数人知晓的.经过分类编目的.代码设计经验的总结.使用设计模式是为了可重用代码.让代码更容易被他人理解.保证代码可靠性. 毫无疑问,设计模式于己于他人于系统都是多赢的,设计模式使代码编制真正工程化,设计模式是软件工程的基石,如同大厦的一块块砖石一样.项目中合理的运用设计模式可以完美的解决很多问题,每
-
SQL语句中不同的连接JOIN及join的用法
为了从两个表中获取数据,我们有时会用JOIN将两个表连接起来.通常有以下几种连接方式: JOIN or INNER JOIN(内连接) : 这两个是相同的,要求两边表同时有对应的数据,返回行,任何一边缺失数据就不显示. LEFT JOIN(左外连接):即使右边的表中没有匹配,也从左表返回所有的行. RIGHT JOIN(右外连接):即使左边的表中没有匹配,也从右表返回所有的行. FULL JOIN(全外连接):只要其中一个表中存在匹配就返回行. 如例,有grade表(课程号sn,分数scro
-
详解Python中的四种队列
队列是一种只允许在一端进行插入操作,而在另一端进行删除操作的线性表. 在Python文档中搜索队列(queue)会发现,Python标准库中包含了四种队列,分别是queue.Queue / asyncio.Queue / multiprocessing.Queue / collections.deque. collections.deque deque是双端队列(double-ended queue)的缩写,由于两端都能编辑,deque既可以用来实现栈(stack)也可以用来实现队列(queue
-
Python pandas 列转行操作详解(类似hive中explode方法)
最近在工作上用到Python的pandas库来处理excel文件,遇到列转行的问题.找了一番资料后成功了,记录一下. 1. 如果需要爆炸的只有一列: df=pd.DataFrame({'A':[1,2],'B':[[1,2],[1,2]]}) df Out[1]: A B 0 1 [1, 2] 1 2 [1, 2] 如果要爆炸B这一列,可以直接用explode方法(前提是你的pandas的版本要高于或等于0.25) df.explode('B') A B 0 1 1 1 1 2 2 2 1 3