JavaScript正则表达式下之相关方法
上篇文章给大家介绍了JavaScript 正则表达式上之基本语法介绍了JavaScript正则表达式的语法,有了这些基本知识,可以看看正则表达式在JavaScript的应用了,在一切开始之前,看看RegExp实例的几个属性
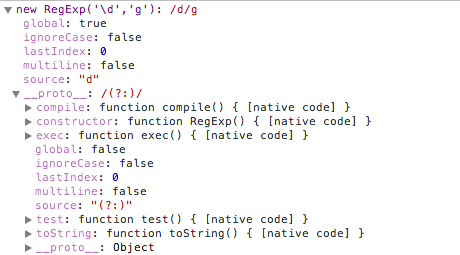
RegExp实例对象有五个属性
1.global:是否全局搜索,默认是false
2.ignoreCase:是否大小写敏感,默认是false
3.multiline:多行搜索,默认值是false
4.lastIndex:是当前表达式模式首次匹配内容中最后一个字符的下一个位置,每次正则表达式成功匹配时,lastIndex属性值都会随之改变。
5.source:正则表达式的文本字符串
除了将正则表达式编译为内部格式从而使执行更快的compile()方法,对象还有两个我们常用的方法
regObj.test(strObj)
方法用于测试字符串参数中是否存正则表达式模式,如果存在则返回true,否则返回false
var reg=/\d+\.\d{1,2}$/g;reg.test('123.45'); //truereg.test('0.2'); //truereg.test('a.34'); //falsereg.test('34.5678'); //false
regObj.exec(strObj)
方法用于正则表达式模式在字符串中运行查找,如果 exec() 找到了匹配的文本,则返回一个结果数组。否则,返回 null。除了数组元素和 length 属性之外,exec() 方法还返回两个属性。index 属性声明的是匹配文本的第一个字符的位置。input 属性则存放的是被检索的字符串 string。
调用非全局的 RegExp对象的 exec() 时,返回数组的第 0 个元素是与正则表达式相匹配的文本,第 1 个元素是与 RegExpObject 的第 1 个子表达式相匹配的文本(如果有的话),第 2 个元素是与 RegExp对象的第 2 个子表达式相匹配的文本(如果有的话),以此类推。
调用全局的RegExp对象的 exec()时,它会在 RegExp实例的 lastIndex 属性指定的字符处开始检索字符串 string。当 exec() 找到了与表达式相匹配的文本时,在匹配后,它将把 RegExp实例的 lastIndex 属性设置为匹配文本的最后一个字符的下一个位置。可以通过反复调用 exec() 方法来遍历字符串中的所有匹配文本。当 exec() 再也找不到匹配的文本时,它将返回 null,并把 lastIndex 属性重置为 0。
var reg=/\d/g;var r=reg.exec('a1b2c3'); console.log(reg.lastIndex); //2r=reg.exec('a1b2c3');console.log(reg.lastIndex); //4
两次执行r的结果

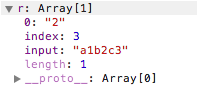
var reg=/\d/g;while(r=reg.exec('a1b2c3')){ console.log(r.index+':'+r[0]);}
1:13:25:3
除了上面的两个方法,有些字符串函数可以传入RegExp对象作为参数,进行一些复杂的操作
strObj.search(RegObj)
search() 方法用于检索字符串中指定的子字符串,或检索与正则表达式相匹配的子字符串。search() 方法不执行全局匹配,它将忽略标志 g。它同时忽略 regexp 的 lastIndex 属性,并且总是从字符串的开始进行检索,这意味着它总是返回 stringObject 的第一个匹配的位置。
'a1b2c3'.search(/\d/g); //1'a1b2c3'.search(/\d/); //1
strObj.match(RegObj)
match() 方法将检索字符串 stringObject,以找到一个或多个与 regexp 匹配的文本。但regexp是否具有标志 g对结果影响很大。
如果 regexp 没有标志 g,那么 match() 方法就只能在 strObj 中执行一次匹配。如果没有找到任何匹配的文本, match() 将返回 null。否则,它将返回一个数组,其中存放了与它找到的匹配文本有关的信息。该数组的第 0 个元素存放的是匹配文本,而其余的元素存放的是与正则表达式的子表达式匹配的文本。除了这些常规的数组元素之外,返回的数组还含有两个对象属性。index 属性声明的是匹配文本的起始字符在 stringObject 中的位置,input 属性声明的是对 stringObject 的引用。
var r='aaa123456'.match(/\d/);

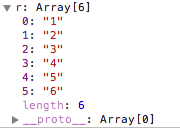
如果 regexp 具有标志 g,则 match() 方法将执行全局检索,找到 strObj 中的所有匹配子字符串。若没有找到任何匹配的子串,则返回 null。如果找到了一个或多个匹配子串,则返回一个数组。不过全局匹配返回的数组的内容与前者大不相同,它的数组元素中存放的是 strObj 中所有的匹配子串,而且也没有 index 属性或 input 属性。
var r='aaa123456'.match(/\d/g);
strObj.replace(regObj,replaceStr)
关于strng对象的replace方法,我们最常用的时传入两个字符串的做法,但这种做法有个缺陷,只能replace一次
'abcabcabc'.replace('bc','X'); //aXabcabc
replace方法的第一个参数还可以传入RegExp对象,传入正则表达式可以时replace方法更加强大灵活
'abcabcabc'.replace(/bc/g,'X'); //aXaXaX'abcaBcabC'.replace(/bc/gi,'X'); //aXaXaX
如果replace方法的第一个参数传入的是带分组的正则表达式,我们在第二个参数中可以使用$1...$9来获取相应分组内容,比如希望把字符串 1<%2%>34<%567%>89 的<%x%>换为$#x#$,我们可以这样
'1<%2%>34<%567%>89'.replace(/<%(\d+)%>/g,'@#$1#@');//1@#2#@34@#567#@89
当然还有很多方式可以达到这一目的,这里只是演示一下利用分组内容,我们在第二个参数中使用 @#$1#@,其中$1表示被捕获的分组内容,在一些js模板函数中可以经常见到这种方式替换字符串。
strObj.replace(regObj,function(){})
可以通过修改replace方法的第二个参数,使replace更加强大,在前面的介绍中,只能把所有匹配替换为固定内容,但如果我希望把一个字符串中所有数字,都用小括号包起来该怎么弄
'2398rufdjg9w45hgiuerhg83ghvif'.replace(/\d+/g,function(r){ return '('+r+')';}); //"(2398)rufdjg(9)w(45)hgiuerhg(83)ghvif"
把replace方法的第二个参数传入一个function,这个function会在每次匹配替换的时候调用,算是个每次替换的回调函数,我们使用了回调函数的第一个参数,也就是匹配内容,其实回调函数一共有四个参数
1.第一个参数很简单,是匹配字符串
2.第二个参数是正则表达式分组内容,没有分组则没有该参数
3.第三个参数是匹配项在字符串中的index
4.第四个参数则是原字符串
'2398rufdjg9w45hgiuerhg83ghvif'.replace(/\d+/g,function(a,b,c){ console.log(a+'\t'+b+'\t'+c); return '('+a+')';}); 2398 0 2398rufdjg9w45hgiuerhg83ghvif9 10 2398rufdjg9w45hgiuerhg83ghvif45 12 2398rufdjg9w45hgiuerhg83ghvif83 22 2398rufdjg9w45hgiuerhg83ghvif
这是没有分组的情况,打印出来的分别是 匹配内容、匹配项index和原字符串,看个有分组的例子,如果我们希望把一个字符串的<%%>外壳去掉,<%1%><%2%><%3%> 变成123
'<%1%><%2%><%3%>'.replace(/<%([^%>]+)%>/g,function(a,b,c,d){ console.log(a+'\t'+b+'\t'+c+'\t'+d); return b;}) //123<%1%> 1 0 <%1%><%2%><%3%> <%2%> 2 5 <%1%><%2%><%3%> <%3%> 3 10 <%1%><%2%><%3%>
根据这种参数replace可以实现很多强大的功能,尤其是在复杂的字符串替换语句中经常使用。
strObj.split(regObj)
我们经常使用split方法把字符串分割为字符数组
'a,b,c,d'.split(','); //["a", "b", "c", "d"]
和replace方法类似,在一些复杂的分割情况下我们可以使用正则表达式解决
'a1b2c3d'.split(/\d/); //["a", "b", "c", "d"]
这样就可以按照数字分割字符串了,是不是很强大。看完这两篇博客基本就能对平时用到的JavaScript正则表达式游刃有余了。要求在前端把一个div中的英文段落单词首字母都换成大写,你是不是知道该怎么做了?
相关推荐
-

Javascript校验密码复杂度的正则表达式
目前使用的正则表达式如下: 复制代码 代码如下: (?=.*\d)(?=.*[a-zA-Z])(?=.*[^a-zA-Z0-9]).{8,30} 对应的验证规则是:密码中必须包含字母.数字.特称字符,至少8个字符,最多30个字符. 这个正则表达式在C#可以正常使用,但是在Javascript中却有问题. 请问是在js中如何写这样的正则表达式? 测试字符串:a123456- 解决方法如下所示: 把\d改为[0-9]问题就解决了,正则表达式如下: 复制代码 代码如下: var regex = new
-
js匹配网址url的正则表达式集合
DNS规定,域名中的标号都由英文字母和数字组成,每一个标号不超过63个字符,也不区分大小写字母.标号中除连字符(-)外不能使用其他的标点符号.级别最低的域名写在最左边,而级别最高的域名写在最右边.由多个标号组成的完整域名总共不超过255个字符.所以验证则网址url的正则可以如下几种 方法一: function checkUrl(urlString){ if(urlString!=""){ var reg=/(http|ftp|https):\/\/[\w\-_]+(\.[\w\-_]+
-
js正则表达式学习和总结(必看篇)
最近在做一个小项目时用到了正则匹配,感觉正则挺好用的,所以打算抽时间来小小总结一下. 正则表达式是一种文本模式,包括普通字符(例如,a 到 z 之间的字母)和特殊字符(称为"元字符").模式描述在搜索文本时要匹配的一个或多个字符串.RegExp 对象表示正则表达式,它是对字符串执行模式匹配的强大工具.正则表达式是一种查找以及字符串替换操作. 新建正则表达式 方式一:直接量语法 var reg = /pattern/attributes 方式二:创建 RegExp 对象的语法 var r
-
JS正则表达式匹配检测各种数值类型(数字验证)
验证数字的正则表达式集 验证数字:^[0-9]*$ 验证n位的数字:^\d{n}$ 验证至少n位数字:^\d{n,}$ 验证m-n位的数字:^\d{m,n}$ 验证零和非零开头的数字:^(0|[1-9][0-9]*)$ 验证有两位小数的正实数:^[0-9]+(.[0-9]{2})?$ 验证有1-3位小数的正实数:^[0-9]+(.[0-9]{1,3})?$ 验证非零的正整数:^\+?[1-9][0-9]*$ 验证非零的负整数:^\-[1-9][0-9]*$ 验证非负整数(正整数 + 0) ^\d
-
JavaScript正则表达式上之基本语法(推荐)
相关阅读: js正则表达式基本语法(精粹) 正则表达式语法 一个正则表达式就是由普通字符(例如字符 a 到 z)以及特殊字符(称为元字符)组成的文字模式.该模式描述在查找文字主体时待匹配的一个或多个字符串.正则表达式作为一个模板,将某个字符模式与所搜索的字符串进行匹配. 定义 JavaScript种正则表达式有两种定义方式,定义一个匹配类似 <%XXX%> 的字符串 1. 构造函数 复制代码 代码如下: var reg=new RegExp('<%[^%>]+%>','g')
-
js正则表达式注册页面表单验证
正则表达式方式的验证方式,这个验证比较标准而且比较全面,不过也是通过点击提交按钮才进行验证,本实例可以这样验证,具体内容如下 也可以这样验证 具体代码 <html> <head> <meta http-equiv="Content-Type" content="text/html; charset=gb2312" /> <title>表单验证类Validator v1</title> <style&g
-
js正则表达式验证URL函数代码(方便多个正则对比)
推荐大家收藏的一段代码,方便同时测试多个正则,查看不同的检测结果,结合chrome完美 核心代码 <script> /** * 正则表达式判断网址是否有效 */ (function(){ "use strict"; var urlDict=[ //Bad Case 'www.baidu.com', //常规网址,未带协议头的地址 'w.baidu.com', //常规网址,短子域名 'baidu.com', //常规网址,仅有主域名 '测试.com', //非常规合法网址,
-
JavaScript 中的正则表达式(推荐)
正则表达式的大致匹配过程是:依次拿出表达式和文本中的字符比较,如果每一个字符都能匹配,则匹配成功:一旦有匹配不成功的字符则匹配失败. 正则表达式通常用于在文本中查找匹配的字符串.Python里数量词默认是贪婪的(在少数语言里也可能是默认非贪婪),总是尝试匹配尽可能多的字符:非贪婪的则相反,总是尝试匹配尽可能少的字符.例如:正则表达式"ab*"如果用于查找"abbbc",将找到"abbb".而如果使用非贪婪的数量词"ab*?",
-
利用js正则表达式校验正数、负数、和小数
话不多少,直接附上代码实例,仅供参考 <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"> <html xmlns="http://www.w3.org/1999/xhtml"> <head> <title>&l
-
JS使用正则表达式过滤多个词语并替换为相同长度星号的方法
本文实例讲述了JS使用正则表达式过滤多个词语并替换为相同长度星号的方法.分享给大家供大家参考,具体如下: <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"> <html xmlns="http://www.w3.org/1999/xhtml"
-
JavaScript中一些常用的正则表达式(推荐)
正则表达式(regular expression)描述了一种字符串匹配的模式,可以用来检查一个串是否含有某种子串.将匹配的子串做替换或者从某个串中取出符合某个条件的子串等. var validateRegExp = { decmal: "^([+-]?)\\d*\\.\\d+$", // 浮点数 decmal1: "^[1-9]\\d*.\\d*|0.\\d*[1-9]\\d*$", // 正浮点数 decmal2: "^-([1-9]\\d*.\\d*|
-
js利用正则表达式检验输入内容是否为网址
js正则检验输入的是否为网址功能在网页中也是很常见的,友情链接部分.表单填写个人主页的时候,使用JavaScript取验证是否为网址. 这个检验不好写,最好还是使用正则表达式去认证. 规定,输入的东西只能是http://与https://开头,而且必须是网址. 有人说,为何像www.1.com这样的网页不行呢? 这是以免你拿用户输入的东西构造超级链接的时候,a标签中的href属性如果遇不到http://或者https://的东西,那么就会认为是根目录,会在你的网站的网址后面接着写入这个地址再跳转
-
JS去除空格和换行的正则表达式(推荐)
前几天在编程的时候,遇到一件问题折腾了很久才解决了,真把我气疯了!把一个字符串放到setTimeout里面没法执行方法,后来发现是因为字符串后面多了一个换行,不仔细看看不出来,使用正则表达式去除换行就可以了. //去除空格 String.prototype.Trim = function() { return this.replace(/\s+/g, ""); } //去除换行 function ClearBr(key) { key = key.replace(/<\