docker搭建Hadoop CDH高可用集群实现
目录
- 0. docker安装
- 1. 构建Centos-cdh镜像
- 2. 容器安装ClouderaManager
- 2.1 初始化环境
- 2.2 配置中文环境变量
- 2.3 设置NTP时间同步服务
- 2.4 安装mysql
- 2.5 准备Cloudera-Manager安装包
- 2.6 安装jdk
- 2.7 启动前准备
- 3. 配置CDH的worker节点
- 3.1 创建多个worker容器
- 3.2 环境配置
- 4. CM管理平台创建CDH集群
- 4.1 登陆CM管理平台
首先我们为了之后继续搭建软件,这里没有使用docker-compose,而是通过构建四台centos,再在里面搭建我们所需要的组件
宿主机最好提供10 GB的RAM,硬盘占用大概会在40G以上
本次采用的在线安装方式,cdh为6.3.2版本,系统为centos7.4, docker节点可以为任意多个,下文将以3个docker容器为示例进行展示。此方法也可用在docker swarm上,docker容器能够互连,网络互通即可
离线安装包地址:
链接: https://pan.baidu.com/s/1vMm0yMYya2vhbEabeJMPHQ 提取码: xbrx
0. docker安装
卸载(可选)
如果之前安装过旧版本的Docker,可以使用下面命令卸载:
yum remove docker \
docker-client \
docker-client-latest \
docker-common \
docker-latest \
docker-latest-logrotate \
docker-logrotate \
docker-selinux \
docker-engine-selinux \
docker-engine \
docker-ce
安装docker
首先需要大家虚拟机联网,安装yum工具
yum install -y yum-utils \
device-mapper-persistent-data \
lvm2 --skip-broken
然后更新本地镜像源:
# 设置docker镜像源
yum-config-manager \
--add-repo \
https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
# 第二步
sed -i 's/download.docker.com/mirrors.aliyun.com\/docker-ce/g' /etc/yum.repos.d/docker-ce.repo
# 第三步
yum makecache fast
然后输入命令:
yum install -y docker-ce
docker-ce为社区免费版本。稍等片刻,docker即可安装成功。
1. 构建Centos-cdh镜像
宿主机初始化
yum install -y wget \ && mkdir -p /etc/yum.repos.d/repo_bak \ && mv /etc/yum.repos.d/*.repo /etc/yum.repos.d/repo_bak/ \ && wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo \ && wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo \ && yum clean all \ && yum makecache \ && yum update –y
构建容器的Dockerfile文件(创建这个文件)
FROM docker.io/ansible/centos7-ansible RUN yum -y install openssh-server RUN yum -y install bind-utils RUN yum -y install which RUN yum -y install sudo
在Dockerfile同级目录执行:
docker build -t centos7-cdh .
生成要用的基础centos7的镜像

接着我们给镜像创建一个网桥
docker network create --subnet=172.10.0.0/16 hadoop_net && docker network ls
启动容器
docker run -d \ --add-host cm.hadoop:172.10.0.2 \ --net hadoop_net \ --ip 172.10.0.2 \ -h cm.hadoop \ -p 10022:22 \ -p 7180:7180 \ --restart always \ --name cm.hadoop \ --privileged \ centos7-cdh \ /usr/sbin/init \ && docker ps
参数解释:
- run -d # 后台启动
- --add-host cm.hadoop:172.10.0.2 # 给容器分配一个固定的ip,主机名为:cm.hadoop
- --net hadoop_net # 将容器加入到上一步创建的网桥中
- -p # 端口映射
- --restart always # docker重启后会自动开启此容器
- --name cm.hadoop # 给容器起名字,在docker中可以用主机名代替ip镜像访问
- --privileged # 声明此容器可以定制化,例如使container内的root拥有真正的root权限等
2. 容器安装ClouderaManager
2.1 初始化环境
我们进入容器,配置一些东西
docker exec -it cm.hadoop bash
将root的登录密码改为root
$ su root $ passwd $ root $ root
安装基础环境
yum install -y kde-l10n-Chinese telnet reinstall glibc-common vim wget ntp net-tools && yum clean all
此步如果出错,请尝试容器是否可以正常联网,检查docker网桥设置
2.2 配置中文环境变量
vim ~/.bashrc ,在末尾添加
export LC_ALL=zh_CN.utf8 export LANG=zh_CN.utf8 export LANGUAGE=zh_CN.utf8
执行
localedef -c -f UTF-8 -i zh_CN zh_CN.utf8 \ && source ~/.bashrc \ && echo $LANG

2.3 设置NTP时间同步服务
这一步是必须要做的,因为hadoop集群如果时间不同步会出现通讯失败的情况
安装ntp
yum install ntp -y
同步时间
ntpdate -u ntp1.aliyun.com
修改时区
ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
再创建一个定时任务,用于定时同步时间(防止虚拟机停止后时间异常)
crontab -e # 添加 0 */2 * * * /usr/sbin/ntpdate ntp1.aliyun.com
启动ntp服务
systemctl start ntpd && \ systemctl enable ntpd && \ date
2.4 安装mysql
使用wget安装(也可以单独部署,单独部署这里不再赘述):
mkdir -p /root/hadoop__CHD/mysql \ && wget -O /root/hadoop_CHD/mysql/mysql-5.7.27-1.el7.x86_64.rpm-bundle.tar \ https://dev.mysql.com/get/Downloads/MySQL-5.7/mysql-5.7.27-1.el7.x86_64.rpm-bundle.tar \ && ls /root/hadoop_CHD/mysql
使用wget会非常的慢,我们可以上传给宿主机,然后通过docker命令拷贝给centos-chd
# 前提是容器的/root/hadoop_CHD/mysql目录必须事先创建。
docker cp mysql-5.7.27-1.el7.x86_64.rpm-bundle.tar {容器ID}:/root/hadoop_CHD/mysql
准备MySQL JDBC驱动
mkdir -p /root/hadoop_CHD/mysql-jdbc \ && wget -O /root/hadoop_CHD/mysql-jdbc/mysql-connector-java-5.1.48.tar.gz \ https://dev.mysql.com/get/Downloads/Connector-J/mysql-connector-java-5.1.48.tar.gz \ && ls /root/hadoop_CHD/mysql-jdbc
2.5 准备Cloudera-Manager安装包
这样下载很慢,建议用finalshell等工具直接从自己的电脑上上传到虚拟机中,直接连接宿主机的10022端口即可
mkdir -p /root/hadoop_CHD/cloudera-repos \ && wget -O /root/hadoop_CHD/cloudera-repos/allkeys.asc \ https://archive.cloudera.com/cm6/6.3.0/allkeys.asc \ && wget -O /root/hadoop_CHD/cloudera-repos/cloudera-manager-agent-6.3.0-1281944.el7.x86_64.rpm \ https://archive.cloudera.com/cm6/6.3.0/redhat7/yum/RPMS/x86_64/cloudera-manager-agent-6.3.0-1281944.el7.x86_64.rpm \ && wget -O /root/hadoop_CHD/cloudera-repos/cloudera-manager-daemons-6.3.0-1281944.el7.x86_64.rpm \ https://archive.cloudera.com/cm6/6.3.0/redhat7/yum/RPMS/x86_64/cloudera-manager-daemons-6.3.0-1281944.el7.x86_64.rpm \ && wget -O /root/hadoop_CHD/cloudera-repos/cloudera-manager-server-6.3.0-1281944.el7.x86_64.rpm \ https://archive.cloudera.com/cm6/6.3.0/redhat7/yum/RPMS/x86_64/cloudera-manager-server-6.3.0-1281944.el7.x86_64.rpm \ && wget -O /root/hadoop_CHD/cloudera-repos/cloudera-manager-server-db-2-6.3.0-1281944.el7.x86_64.rpm \ https://archive.cloudera.com/cm6/6.3.0/redhat7/yum/RPMS/x86_64/cloudera-manager-server-db-2-6.3.0-1281944.el7.x86_64.rpm \ && wget -O /root/hadoop_CHD/cloudera-repos/enterprise-debuginfo-6.3.0-1281944.el7.x86_64.rpm \ https://archive.cloudera.com/cm6/6.3.0/redhat7/yum/RPMS/x86_64/enterprise-debuginfo-6.3.0-1281944.el7.x86_64.rpm \ && wget -O /root/hadoop_CHD/cloudera-repos/oracle-j2sdk1.8-1.8.0+update181-1.x86_64.rpm \ https://archive.cloudera.com/cm6/6.3.0/redhat7/yum/RPMS/x86_64/oracle-j2sdk1.8-1.8.0+update181-1.x86_64.rpm \ && ll /root/hadoop_CHD/cloudera-repos
准备Parcel包
mkdir -p /root/hadoop_CHD/parcel \ && wget -O /root/hadoop_CHD/parcel/ CDH-6.3.2-1.cdh6.3.2.p0.1605554-el7.parcel \ https://archive.cloudera.com/cdh6/6.3.2/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554-el7.parcel \ && wget -O /root/hadoop_CHD/parcel/manifest.json \ https://archive.cloudera.com/cdh6/6.3.2/parcels/manifest.json \ && ll /root/hadoop_CHD/parcel
搭建本地yum源
yum -y install httpd createrepo \ && systemctl start httpd \ && systemctl enable httpd \ && cd /root/hadoop_CHD/cloudera-repos/ && createrepo . \ && mv /root/hadoop_CHD/cloudera-repos /var/www/html/ \ && yum clean all \ && ll /var/www/html/cloudera-repos
2.6 安装jdk
yum install -y java-1.8.0-openjdk-devel.x86_64
查看一下:
java -version

jdk会默认安装在/usr/lib/jvm目录下:

这样安装没有配置JAVA_HOME,我们需要进一步配置,不然后面安装会报错
( cat <<EOF #set java environment JAVA_HOME=/usr/lib/jvm/jre-1.8.0-openjdk PATH=$PATH:$JAVA_HOME/bin CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar export JAVA_HOME CLASSPATH PATH EOF ) >> /etc/profile && source /etc/profile && java -version
2.7 启动前准备
安装配置MySQL数据库(采用docker独立安装跳过此步)
cd /root/hadoop_CHD/mysql/ \ && tar -xvf mysql-5.7.27-1.el7.x86_64.rpm-bundle.tar \ && yum install -y libaio numactl \ && rpm -ivh mysql-community-common-5.7.27-1.el7.x86_64.rpm \ && rpm -ivh mysql-community-libs-5.7.27-1.el7.x86_64.rpm \ && rpm -ivh mysql-community-client-5.7.27-1.el7.x86_64.rpm \ && rpm -ivh mysql-community-server-5.7.27-1.el7.x86_64.rpm \ && rpm -ivh mysql-community-libs-compat-5.7.27-1.el7.x86_64.rpm \ && echo character-set-server=utf8 >> /etc/my.cnf \ && rm -rf /root/hadoop_CHD/mysql/ \ && yum clean all \ && rpm -qa |grep mysql
建数据库表
(
cat <<EOF
set password for root@localhost = password('123456Aa.');
grant all privileges on *.* to 'root'@'%' identified by '123456Aa.';
flush privileges;
CREATE DATABASE scm DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
CREATE DATABASE amon DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
CREATE DATABASE rman DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
CREATE DATABASE hue DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
CREATE DATABASE metastore DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
CREATE DATABASE sentry DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
CREATE DATABASE nav DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
CREATE DATABASE navms DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
CREATE DATABASE oozie DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
GRANT ALL ON scm.* TO 'scm'@'%' IDENTIFIED BY '123456Aa.';
GRANT ALL ON amon.* TO 'amon'@'%' IDENTIFIED BY '123456Aa.';
GRANT ALL ON rman.* TO 'rman'@'%' IDENTIFIED BY '123456Aa.';
GRANT ALL ON hue.* TO 'hue'@'%' IDENTIFIED BY '123456Aa.';
GRANT ALL ON metastore.* TO 'hive'@'%' IDENTIFIED BY '123456Aa.';
GRANT ALL ON sentry.* TO 'sentry'@'%' IDENTIFIED BY '123456Aa.';
GRANT ALL ON nav.* TO 'nav'@'%' IDENTIFIED BY '123456Aa.';
GRANT ALL ON navms.* TO 'navms'@'%' IDENTIFIED BY '123456Aa.';
GRANT ALL ON oozie.* TO 'oozie'@'%' IDENTIFIED BY '123456Aa.';
SHOW DATABASES;
EOF
) >> /root/c.sql
保存为:/root/c.sql
获取MySQL初始密码
systemctl start mysqld && grep password /var/log/mysqld.log | sed 's/.*(............)$/1/'
执行SQL脚本
mysql -u root -p
输入查询出的默认密码,然后执行:
source /root/c.sql
配置mysql jdbc驱动
$ mkdir -p /usr/share/java/ $ cd /root/hadoop_CHD/mysql-jdbc/ $ tar -zxvf mysql-connector-java-5.1.48.tar.gz $ cp /root/hadoop_CHD/mysql-jdbc/mysql-connector-java-5.1.48/mysql-connector-java-5.1.48-bin.jar /usr/share/java/mysql-connector-java.jar $ rm -rf /root/hadoop_CHD/mysql-jdbc/ $ ls /usr/share/java/
这里有坑,就是这个驱动版本不能太高,刚开始我的是5.1.47的驱动,然后就会报错,换了5.1.6的就好了(手动上传),还有就是驱动不能带版本号
名字要为mysql-connector-java.jar
安装Cloudera Manager
( cat <<EOF [cloudera-manager] name=Cloudera Manager 6.3.0 baseurl=http://172.10.0.2/cloudera-repos/ gpgcheck=0 enabled=1 EOF ) >> /etc/yum.repos.d/cloudera-manager.repo \ && yum clean all \ && yum makecache \ && yum install -y cloudera-manager-daemons cloudera-manager-agent cloudera-manager-server \ && yum clean all \ && rpm -qa | grep cloudera-manager
配置parcel库
cd /opt/cloudera/parcel-repo/;mv /root/hadoop_CHD/parcel/* ./ \
&& sha1sum CDH-6.3.2-1.cdh6.3.2.p0.1605554-el7.parcel | awk '{ print $1 }' > CDH-6.3.2-1.cdh6.3.2.p0.1605554-el7.parcel.sha \
&& rm -rf /root/hadoop_CHD/parcel/ \
&& chown -R cloudera-scm:cloudera-scm /opt/cloudera/parcel-repo/* \
&& ll /opt/cloudera/parcel-repo/
初始化scm库
/opt/cloudera/cm/schema/scm_prepare_database.sh mysql scm scm 123456Aa.
接着上面的,如果驱动没有问题

启动cloudera-server服务
systemctl start cloudera-scm-server.service \ && sleep 2 \ && tail -f /var/log/cloudera-scm-server/cloudera-scm-server.log | grep "INFO WebServerImpl:com.cloudera.server.cmf.WebServerImpl: Started Jetty server"
这里如果出错,请多看错误日志,一般为驱动未找到,或者是bean构建失败等等,如果失败不要反复重启服务,因为scm数据库里面的数据很可能会出现问题,应该删除该数据库再重新启动
到这里如果没有什么问题,你可以在你的浏览器里面看到页面,http://IP:7180/cmf/login 账号密码:admin/admin

先别急着操作,先配置两个slave结点
3. 配置CDH的worker节点
以下为worker容器的准备方式,若为多个时,重复执行以下步骤,创建多个worker节点
3.1 创建多个worker容器
创建2个work容器
Worker-1:
docker run -d \ --add-host cm.hadoop:172.10.0.2 \ --add-host cdh01.hadoop:172.10.0.3 \ --net hadoop_net \ --ip 172.10.0.3 \ -h cdh01.hadoop \ -p 20022:22 \ --restart always \ --name cdh01.hadoop \ --privileged \ centos7-cdh \ /usr/sbin/init \ && docker ps
Worker-2:
docker run -d \ --add-host cm.hadoop:172.10.0.2 \ --add-host cdh02.hadoop:172.10.0.4 \ --net hadoop_net \ --ip 172.10.0.4 \ -h cdh02.hadoop \ -p 30022:22 \ --restart always \ --name cdh02.hadoop \ --privileged \ centos7-cdh \ /usr/sbin/init \ && docker ps
到这里正常的话我们就有三台主机了

和之前的操作一样,先安装基本工具
上一步创建的所有容器均执行,修改root的登录密码改为root
$ su root $ passwd $ root $ root
然后执行
配置中文环境
yum install -y kde-l10n-Chinese telnet reinstall glibc-common vim wget ntp net-tools && yum clean all
3.2 环境配置
配置中文环境变量
( cat <<EOF export LC_ALL=zh_CN.utf8 export LANG=zh_CN.utf8 export LANGUAGE=zh_CN.utf8 EOF ) >> ~/.bashrc \ && localedef -c -f UTF-8 -i zh_CN zh_CN.utf8 \ && source ~/.bashrc \ && echo $LANG
这一步是必须要做的,因为hadoop集群如果时间不同步会出现通讯失败的情况
安装ntp
yum install ntp -y
同步时间
ntpdate -u ntp1.aliyun.com
修改时区
ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
再创建一个定时任务,用于定时同步时间(防止虚拟机停止后时间异常)
crontab -e# 添加0 */2 * * * /usr/sbin/ntpdate ntp1.aliyun.com
启动ntp服务
systemctl start ntpd && \ systemctl enable ntpd && \ date
配置MySQL JDBC
这里为了防止出错,建议配置和master结点一样的驱动,且不要带版本号
mkdir -p /usr/share/java/
上传驱动即可
修改CM主机的host文件
这样我们可以很方便的使用后面的名字访问这些主机
echo "172.10.0.3 cdh01.hadoop cdh01" >> /etc/hosts echo "172.10.0.4 cdh02.hadoop cdh02" >> /etc/hosts
这里我们还可以配置一下免密码登录
4. CM管理平台创建CDH集群
4.1 登陆CM管理平台
http://IP:7180/cmf/login 账号密码:admin/admin
欢迎界面:

此面一直点击
继续,需要同意条款的同意条款
然后就可以来到集群安装的欢迎界面
我们来安装集群
选择继续,并给集群起一个名字
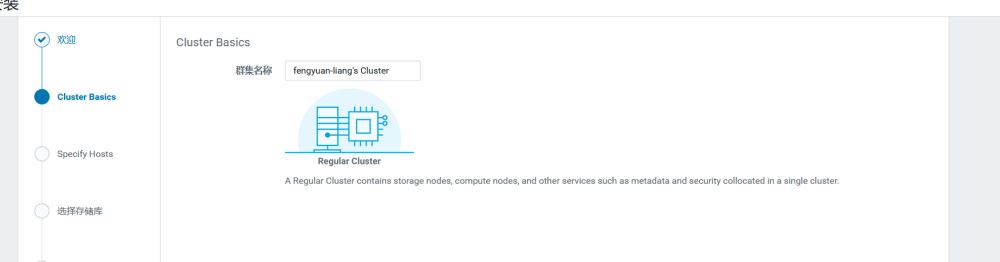
设置主机地址: 172.10.0.[2-4]

选择存储
自定义存储库:http://172.10.0.2/cloudera-repos

Jdk安装

SSH凭据,密码为容器root用户的登录密码,此处为root

安装代理

安装大数据组件

集群状态检查

集群设置
选择你要安装的组件
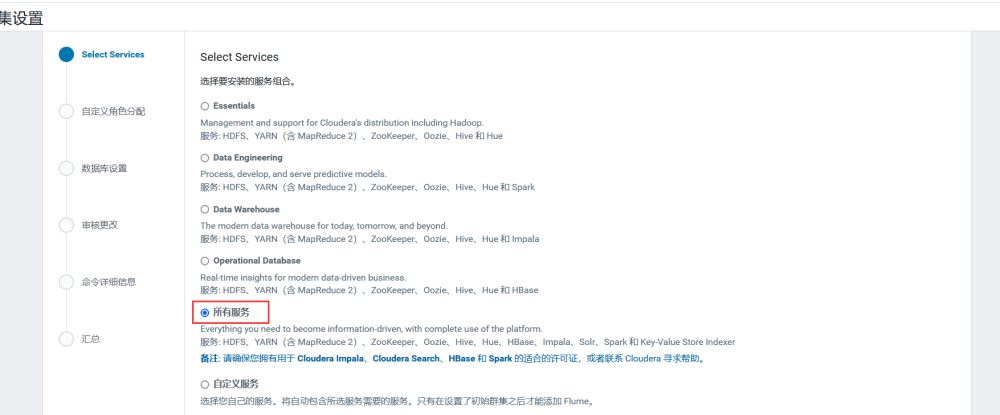
选择好你要安装的大数据组件,然后点继续

这里如果选择了hive之类的组件,需要在cm结点上创建一个数据库,可以用组件名命名
CREATE DATABASE scm DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci; CREATE DATABASE hive DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci; grant all privileges on scm.* to scm@'localhost' identified by '密码'; grant all privileges on scm.* to scm@'%' identified by '密码'; grant all privileges on hive.* to hive@'localhost' identified by '密码'; grant all privileges on hive.* to hive@'%' identified by '密码'; CREATE DATABASE hue DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci; grant all privileges on hue.* to hue@'%' identified by '密码'; grant all privileges on hue.* to hue@'localhost' identified by '密码2'; CREATE DATABASE rm DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci; grant all privileges on rm.* to rm@'localhost' identified by '密码'; grant all privileges on rm.* to rm@'%' identified by '密码'; flush privileges;

红色表示必填的项目

Datanode-> /dfs/datanode
Namenode-> /dfs/namenode
HDFS检查点-> /dfs/checkpoint
NodeManager 本地目录-> /dfs/nodemanager
然后就等待集群构建完成!

到此这篇关于docker搭建Hadoop CDH高可用集群实现的文章就介绍到这了,更多相关docker Hadoop CDH高可用集群内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
使用docker部署hadoop集群的详细教程
最近要在公司里搭建一个hadoop测试集群,于是采用docker来快速部署hadoop集群. 0. 写在前面 网上也已经有很多教程了,但是其中都有不少坑,在此记录一下自己安装的过程. 目标:使用docker搭建一个一主两从三台机器的hadoop2.7.7版本的集群 准备: 首先要有一台内存8G以上的centos7机器,我用的是阿里云主机. 其次将jdk和hadoop包上传到服务器中. 我安装的是hadoop2.7.7.包给大家准备好了,链接:https://pan.baidu.com/s/15n
-
Hadoop+HBase+ZooKeeper分布式集群环境搭建步骤
目录 一.环境说明 2.1 安装JDK 2.2 添加Hosts映射关系 2.3 集群之间SSH无密码登陆 三.Hadoop集群安装配置 3.1 修改hadoop配置 3.2 启动hadoop集群 四.ZooKeeper集群安装配置 4.1 修改配置文件zoo.cfg 4.2 新建并编辑myid文件 4.3 启动ZooKeeper集群 五.HBase集群安装配置 5.1 hbase-env.sh 5.2 hbase-site.xml 5.3 更改 regionservers 5.4 分发并同步安装
-
Hadoop部署的基础设施操作详解
目录 官网导读 基础设施 设置IP及主机名 关闭防火墙&selinux 设置hosts映射 时间同步 安装jdk 设置SSH免秘钥 结论 官网导读 hadoop.apache.org/docs/r2.6.5… 支持最好的平台:GNU/Linux 依赖的软件: Java™ must be installed. Recommended Java versions are described at HadoopJavaVersions.Hadoop基于Java开发,Java的移动性好 ssh must
-

最新hadoop安装教程及hadoop的命令使用(亲测可用)
目录 01 引言 02 hadoop 安装 2.1 下载与安装 2.2 hadoop配置 2.3 免登陆配置 2.4 配置环境变量 2.5 配置域名 2.6 启动 03 相关命令 3.1 yarn相关命令 3.2 hdfs相关命令 04 一次填完所有的坑 01 引言 最近安装hadoop-2.7.7 版本的时候遇到了很多坑,本文来详细讲解如何安装和解决遇到的问题. 02 hadoop 安装 2.1 下载与安装 Step1: 下载 百度网盘下载 链接: https://pan.baidu.com/
-
ol7.7安装部署4节点hadoop 3.2.1分布式集群学习环境的详细教程
准备4台虚拟机,安装好ol7.7,分配固定ip192.168.168.11 12 13 14,其中192.168.168.11作为master,其他3个作为slave,主节点也同时作为namenode的同时也是datanode,192.168.168.14作为datanode的同时也作为secondary namenodes 首先修改/etc/hostname将主机名改为master.slave1.slave2.slave3 然后修改/etc/hosts文件添加 192.168.168.11 m
-
教你在k8s上部署HADOOP-3.2.2(HDFS)的方法
环境+版本k8s: v1.21.1hadoop: 3.2.2 dockerfile FROM openjdk:8-jdk # 如果要通过ssh连接容器内部,添加自己的公钥(非必须) ARG SSH_PUB='ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQC3nTRJ/aVb67l1xMaN36jmIbabU7Hiv/xpZ8bwLVvNO3Bj7kUzYTp7DIbPcHQg4d6EsPC6j91E8zW6CrV2fo2Ai8tDO/rCq9Se/64F3+8oEI
-
基于 ZooKeeper 搭建 Hadoop 高可用集群 的教程图解
一.高可用简介 Hadoop 高可用 (High Availability) 分为 HDFS 高可用和 YARN 高可用,两者的实现基本类似,但 HDFS NameNode 对数据存储及其一致性的要求比 YARN ResourceManger 高得多,所以它的实现也更加复杂,故下面先进行讲解: 1.1 高可用整体架构 HDFS 高可用架构如下: 图片引用自: https://www.edureka.co/blog/how-to-set-up-hadoop-cluster-with-hdfs-hi
-
CentOS下RabbitMq高可用集群环境搭建教程
CentOS下RabbitMq高可用集群环境搭建教程分享给大家. 准备工作 1.准备两台或多台安装有rabbitmq-server服务的服务器 我这里准备了两台,分别如下: 192.168.40.130 rabbitmq01 192.168.40.131 rabbitmq02 2.确保防火墙是关闭的3,官网参考资料 http://www.rabbitmq.com/clustering.html hosts映射 修改每台服务上的hosts文件(路径:/etc/hosts),设置成如下: 192.1
-
基于mysql+mycat搭建稳定高可用集群负载均衡主备复制读写分离操作
数据库性能优化普遍采用集群方式,oracle集群软硬件投入昂贵,今天花了一天时间搭建基于mysql的集群环境. 主要思路 简单说,实现mysql主备复制-->利用mycat实现负载均衡. 比较了常用的读写分离方式,推荐mycat,社区活跃,性能稳定. 测试环境 MYSQL版本:Server version: 5.5.53,到官网可以下载WINDWOS安装包. 注意:确保mysql版本为5.5以后,以前版本主备同步配置方式不同. linux实现思路类似,修改my.cnf即可. A主mysql.19
-
Redis5之后版本的高可用集群搭建的实现
一.安装redis 1.安装gcc yum install gcc 2.下载redis-5.0.8.tar.gz 3.把下载好的redis-5.0.8.tar.gz放在/gyu/software文件夹下,并解压 > tar xzf redis-5.0.8.tar.gz > cd redis-5.0.8 4.进入到解压好的redis-5.0.8目录下,进行编译与安装 > make & make install 5.启动并指定配置文件 > src/redis-server re
-
centos环境下nginx高可用集群的搭建指南
目录 1.概述 2.CentOS中nginx集群搭建 2.1 集群架构图 2.2 Keepalived 2.3 集群搭建准备 2.4 集群搭建 2.4.1 安装keepalived 2.4.2 配置keepalived.conf 2.4.3 编写nginx监测脚本 2.4.4 启动keepalived 2.4.5 启动nginx 2.4.6 测试 3.小结 4.参考文献 总结 1.概述 nginx单机部署时,一旦宕机就会导致整个服务的不可用,导致雪崩式效应.集群式部署是解决单点式雪崩效应的有效方
-
nginx搭建高可用集群的实现方法
目录 Keepalived+Nginx 高可用集群(主从模式) Keepalived+Nginx 高可用集群(主从模式) 集群架构图 1.准备两台装有Nginx虚拟机 2.都需安装Keepalived yum install keepalived -y 查看是否安装成功 rpm -q -a keepalived 安装之后,在 etc 里面生成目录 keepalived,有文件 keepalived.conf 3.完成高可用配置(主从配置) 修改/etc/keepalived/keepalivec
-
运用.net core中实例讲解RabbitMQ高可用集群构建
目录 一.集群架构简介 二.普通集群搭建 2.1 各个节点分别安装RabbitMQ 2.2 把节点加入集群 2.3 代码演示普通集群的问题 三.镜像集群 四.HAProxy环境搭建. 五.KeepAlived 环境搭建 一.集群架构简介 当单台 RabbitMQ 服务器的处理消息的能力达到瓶颈时,此时可以通过 RabbitMQ 集群来进行扩展,从而达到提升吞吐量的目的.RabbitMQ 集群是一个或多个节点的逻辑分组,集群中的每个节点都是对等的,每个节点共享所有的用户,虚拟主机,队列,交换器,绑
-
sentinel支持的redis高可用集群配置详解
目录 一.首先配置redis的主从同步集群 二.sentinel高可用 一.首先配置redis的主从同步集群 1.主库的配置文件不用修改,从库的配置文件只需增加一行,说明主库的IP端口.如果需要验证的,也要加多一行,认证密码. slaveof 192.168.20.26 5268 masterauth hodge01 一主多从的话,就启用多个从库.其中,从库都是一样的方案.本次有两个slave. 2.命令检查 /usr/local/redis/bin/redis-cli -p 5257 -a h
-
MySQL之高可用集群部署及故障切换实现
一.MHA 1.概念 2.MHA 的组成 3.MHA 的特点 二.搭建MySQL+MHA 思路和准备工作 1.MHA架构 数据库安装 一主两从 MHA搭建 2.故障模拟 模拟主库失效 备选主库成为主库 原故障主库恢复重新加入到MHA成为从库 3.准备4台安装MySQL虚拟机 MHA高可用集群相关软件包 MHAmanager IP:192.168.221.30 MySQL1 IP:192.168.221.20 MySQL2 IP:192.168.221.100 MySQL3 IP: 192.168
-
Redis高可用集群redis-cluster详解
哨兵模式主要解决了手动切换主从节点的问题 1 , 哨兵模式的缺陷 .主从节点切换的时候存在访问瞬断,等待时间较长, .只有一个master节点提供写,slave节点提供读,尽管写的效率是10万/秒,在电商大促时,写的压力全部集中在master节点上. .master节点的内存不能设置的太大,否则持久化文件过大,影响主从同步 2,redis-cluster集群模式 Redis Cluster是社区版推出的Redis分布式集群解决方案,主要解决Redis分布式方面的需求,比如,当遇到单机内存,并发和