Python读取xlsx文件报错:xlrd.biffh.XLRDError: Excel xlsx file;not supported问题解决
目录
- 发现错误
- (1)检查第三方库xlrd的版本:
- (2)别忘了修改import名称与调用的包名称
- 总结
发现错误
利用Python库xlrd中的xlrd.open_workbook()函数读取自定义xlsx表格文件时出错如下:
Traceback (most recent call last):
File "C:/Users/llll/PycharmProjects/pythonProject1/RandomForestRegression.py", line 96, in <module>
x_train , y_train , x_test , y_test = load_data(2,60,1,9,0,r'C:\Users\llll\Desktop\特征表.xlsx')
File "C:/Users/llll/PycharmProjects/pythonProject1/RandomForestRegression.py", line 14, in load_data
workbook = xlrd.open_workbook(str(FilePath)) #excel路径
File "C:\Users\llll\PycharmProjects\pythonProject1\venv\lib\site-packages\xlrd\__init__.py", line 170, in open_workbook
raise XLRDError(FILE_FORMAT_DESCRIPTIONS[file_format]+'; not supported')
xlrd.biffh.XLRDError: Excel xlsx file; not supported
Process finished with exit code 1
经过查资料总结后得到如下解法:
(1)检查第三方库xlrd的版本:
我这里的版本为xlrd2.0.1最新版本,问题就出在这里,需要卸载最新版本,安装旧版本,卸载安装过程如下。
PyCharm查看版本、添加与移除第三方库的方法:
●File-Settings
●Project-Python Interpreter
●移除操作:选中需要删除的包并点减号
●添加操作:点击加号
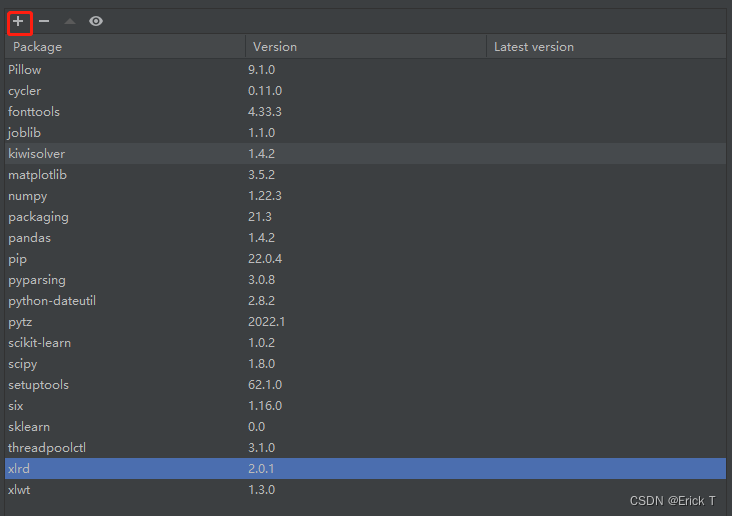
●搜索框中搜索:
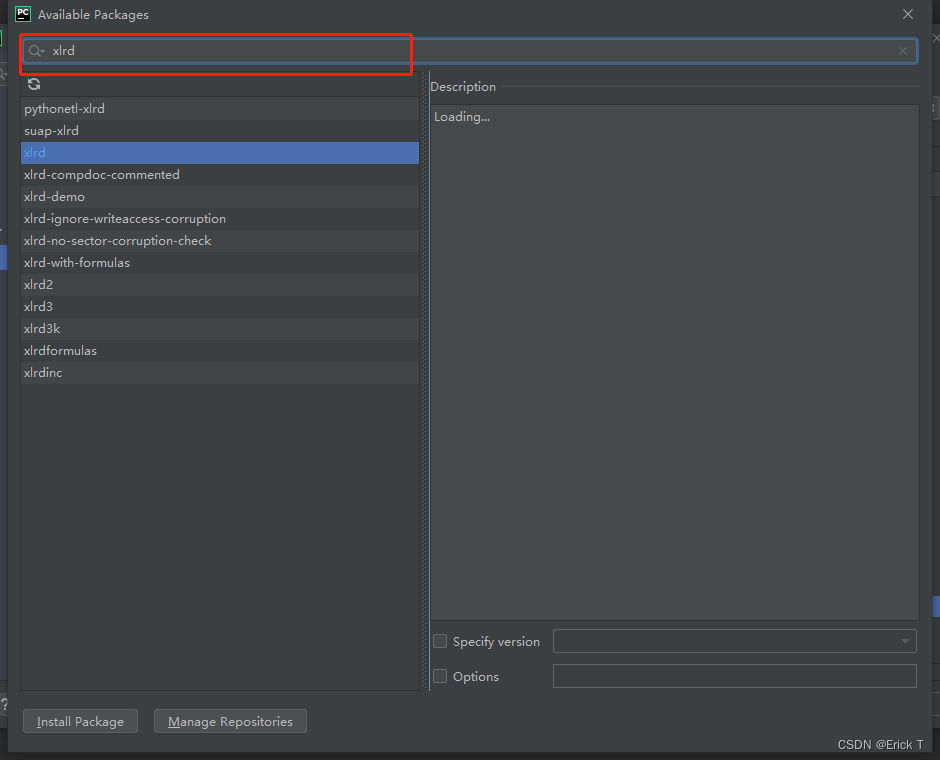
●找到并点击需要安装的包,Install Package:
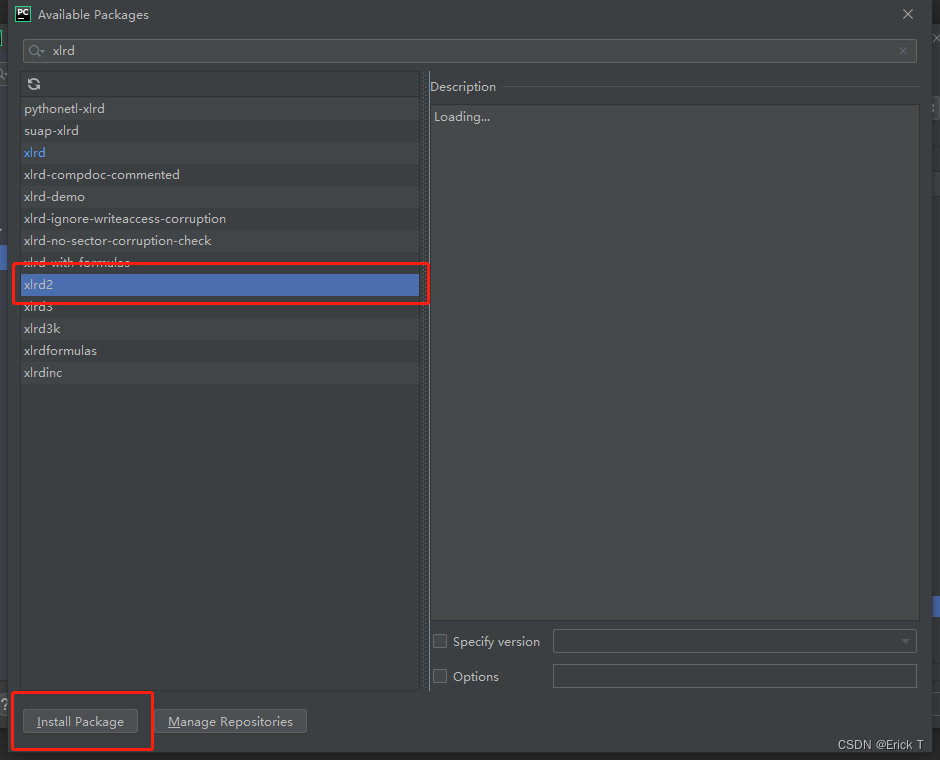
按照上述步骤卸载xlrd后再安装xlrd2后,错误解决。
(2)别忘了修改import名称与调用的包名称
总结
到此这篇关于Python读取xlsx文件报错:xlrd.biffh.XLRDError: Excel xlsx file;not supported问题解决的文章就介绍到这了,更多相关读取xlsx文件报错xlrd.biffh.XLRDError内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
关于Python 解决Python3.9 pandas.read_excel(‘xxx.xlsx‘)报错的问题
问题描述 使用pandas库的read_excel()方法读取外部excel文件报错, 截图如下 好像是缺少了什么方法的样子 问题分析 分析个啥, 水平有限, 直接面向stackoverflow编程 https://stackoverflow.com/questions/64264563/attributeerror-elementtree-object-has-no-attribute-getiterator-when-trying 我找到了下面的这几种说法 根据国外大神的指点, 我得出了这些
-

Python读取xlsx文件报错:xlrd.biffh.XLRDError: Excel xlsx file;not supported问题解决
目录 发现错误 (1)检查第三方库xlrd的版本: (2)别忘了修改import名称与调用的包名称 总结 发现错误 利用Python库xlrd中的xlrd.open_workbook()函数读取自定义xlsx表格文件时出错如下: Traceback (most recent call last): File "C:/Users/llll/PycharmProjects/pythonProject1/RandomForestRegression.py", line 96, in <
-
一文带你解决Python中的所有报错
目录 前言 Python安装 HTTPSConnectionPool(host=‘files.pythonhosted.org‘, port=443): Read timed out解决 xlrd.biffh.XLRDError: Excel xlsx file; not supported解决 Fatal error in launcher: Unable to create process using解决 报错Non-zero exit code (2)解决 [notice] A new r
-
python读取mat文件中的struct问题
目录 python读取mat文件中的struct mat文件结构如下 经过查找资料,总结如下 解决办法 python读取mat文件报错 python读取mat文件中的struct All devils are in the details,做个笔记. mat文件结构如下 ground_truth_data 是1x1的struct(结构体),包含2个字段,一个是list,一个是imgszie.如图1所示 图1 list是一个352x1的cell,点开后如图2,可以看到list中的每一个cell又由
-
解决pandas read_csv 读取中文列标题文件报错的问题
从windows操作系统本地读取csv文件报错 data = pd.read_csv(path) Traceback (most recent call last): File "C:/Users/arron/PycharmProjects/ML/ML/test.py", line 45, in <module> data = pd.read_csv(path) File "C:\Users\arron\AppData\Local\Continuum\Anacon
-
解决pandas中读取中文名称的csv文件报错的问题
之前在使用Pandas处理csv文件时,发现如果文件名为中文,则会报错: OSError: Initializing from file failed 后来在一位博主的博客中解释了是read_csv中engine参数的问题,默认是C engine,在读取中文标题时有可能会出错(在我这是必现),解决方法是将engine换为Python(官方文档的说法是C engine更快但是Python engine功能更完备),具体写法: df.read_csv('filename', engine='pyth
-
Python 解决OPEN读文件报错 ,路径以及r的问题
Python 中 'unicodeescape' codec can't decode bytes in position XXX: trun错误解决方案 背景描述 今天在运用Python pillow模块处理图片时遇到一个错误 SyntaxError: (unicode error) 'unicodeescape' codec can't decode bytes in position 2-3: truncated \UXXXXXXXX escape 刚开始以为是图片名字有中文,不识别,于是
-
解决Python 写文件报错TypeError的问题
处理上传的文件: f1 = request.FILES['pic'] fname = '%s/%s' % (settings.MEDIA_ROOT, f1.name) with open(fname, 'w') as pic: for c in f1.chunks(): pic.write(c) 测试报错: TypeError at /upload/ write() argument must be str, not bytes 把之前的打开语句修改为用二进制方式打开: f1 = request
-
解决python中import文件夹下面py文件报错问题
如下所示: 在需要导入的那个文件夹里面新建一个 __init__.py文件,哪怕这个文件是空的文件也可以. 补充知识:python中import其他目录下的文件出现问题的解决方法 在使用python进行编程的时候,import其他文件路径下的.py文件时报错 Traceback (most recent call last): File "download_and_convert_data.py", line 44, in <module> from .datasets i
-
python保存大型 .mat 数据文件报错超出 IO 限制的操作
python 保存 .mat 文件的大小是有限制的,似乎是 5G 以内,如果需要保存几十个 G 的数据的话,可以选用其他方式, 比如 h5 文件 import h5py def h5_data_write(train_data, train_label, test_data, test_label, shuffled_flag): print("h5py文件正在写入磁盘...") save_path = "../save_test/" + "train_t
-
利用Python读取CSV文件并计算某一列的均值和方差
近日需要对excel的csv文件进行处理,求取某银行历年股价的均值方差等一系列数据 文件的构成很简单,部分如下所示 总共有接近七千行数据,主要的工作就是将其中的股价数据提取出来,放入一个数组之中,然后利用numpy模块即可求出需要的数据. 这里利用了csv模块来对文件进行处理,最终实现的代码如下: import csv import numpy as np with open('pingan_stock.csv') as csv_file: row = csv.reader(csv_file,