Python 数据分析教程探索性数据分析
目录
- 什么是探索性数据分析(EDA)?
- 描述性统计
- 分组数据
- 方差分析
- 相关性和相关性计算
什么是探索性数据分析(EDA)?
EDA 是数据分析下的一种现象,用于更好地理解数据方面,例如:
– 数据的主要特征
– 变量和它们之间的关系
– 确定哪些变量对我们的问题很重要
我们将研究各种探索性数据分析方法,
例如:
- 描述性统计,这是一种简要概述我们正在处理的数据集的方法,包括样本的一些度量和特征
- 分组数据 [使用group by 进行基本分组]
- ANOVA,方差分析,这是一种计算方法,可将观察集中的变化划分为不同的分量。
- 相关和相关方法
我们将使用的数据集是子投票数据集,您可以在 python 中将其导入为:
import pandas as pd
Df = pd.read_csv("https://vincentarelbundock.github.io / Rdatasets / csv / car / Child.csv")
描述性统计
描述性统计是了解数据特征和快速总结数据的有用方法。python 中的 Pandas 提供了一个有趣的方法describe() 。describe 函数对数据集应用基本统计计算,如极值、数据点计数标准差等。任何缺失值或 NaN 值都会被自动跳过。describe() 函数很好地描绘了数据的分布情况。
DF.describe()
这是您在运行上述代码时将获得的输出:

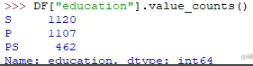
另一种有用的方法是 value_counts(),它可以获取分类属性值系列中每个类别的计数。例如,假设您正在处理一个客户数据集,这些客户在列名 age 下分为青年、中年和老年类别,并且您的数据框是“DF”。您可以运行此语句以了解有多少人属于各个类别。在我们的数据集示例中可以使用教育列
DF["education"].value_counts()
上述代码的输出将是:
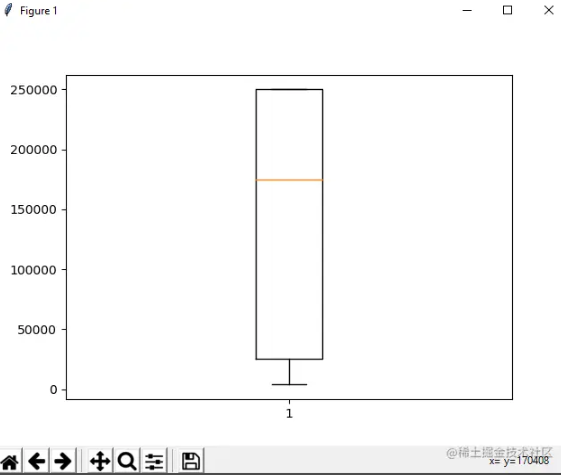
另一个有用的工具是 boxplot,您可以通过 matplotlib 模块使用它。箱线图是数据分布的图形表示,显示极值、中位数和四分位数。我们可以使用箱线图轻松找出异常值。现在再次考虑我们一直在处理的数据集,让我们在属性总体上绘制一个箱线图
import pandas as pd
import matplotlib.pyplot as plt
DF = pd.read_csv("https://raw.githubusercontent.com / fivethirtyeight / data / master / airline-safety / airline-safety.csv")
y = list(DF.population)
plt.boxplot(y)
plt.show()
发现异常值后,输出图将如下所示:
分组数据
Group by 是 pandas 中可用的一个有趣的度量,它可以帮助我们找出不同分类属性对其他数据变量的影响。让我们看一个在同一数据集上的示例,我们想找出人们的年龄和教育对投票数据集的影响。
DF.groupby(['education', 'vote']).mean()
输出会有点像这样:
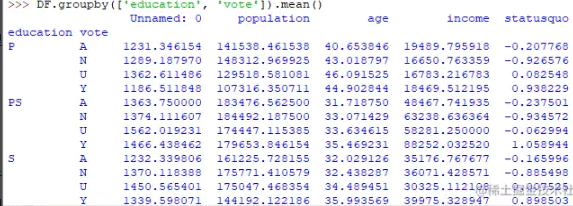
如果按输出表进行分组难以理解,则进一步的分析师使用数据透视表和热图对其进行可视化。
方差分析
ANOVA 代表方差分析。执行它是为了找出不同类别数据组之间的关系。
在 ANOVA 下,我们有两个测量结果:
– F-testscore:显示组均值相对于变化的变化
– p 值:显示结果的重要性
这可以使用 python 模块 scipy 方法名称f_oneway()
这些样本是每组的样本测量值。
作为结论,如果 ANOVA 检验给我们一个大的 F 检验值和一个小的 p 值,我们可以说其他变量和分类变量之间存在很强的相关性。
相关性和相关性计算
相关性是上下文中两个变量之间的简单关系,使得一个变量影响另一个变量。相关性不同于引起的行为。计算变量之间相关性的一种方法是找到 Pearson 相关性。在这里,我们找到两个参数,即皮尔逊系数和 p 值。当 Pearson 相关系数接近 1 或 -1 且 p 值小于 0.0001 时,我们可以说两个变量之间存在很强的相关性。
Scipy 模块还提供了一种执行 pearson 相关性分析的方法,
这里的示例是您要比较的属性。
到此这篇关于Python 数据分析教程探索性数据分析的文章就介绍到这了,更多相关Python 索性数据分析内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python中的探索性数据分析(功能式)
这里有一些技巧来处理日志文件提取.假设我们正在查看一些Enterprise Splunk提取.我们可以用Splunk来探索数据.或者我们可以得到一个简单的提取并在Python中摆弄这些数据. 在Python中运行不同的实验似乎比试图在Splunk中进行这种探索性的操作更有效.主要是因为我们可以无所限制地对数据做任何事.我们可以在一个地方创建非常复杂的统计模型. 理论上,我们可以在Splunk中做很多的探索.它有各种报告和分析功能. 但是... 使用Splunk需要假设我们知道我们正在寻找什么.在
-

Python Sweetviz轻松实现探索性数据分析
Sweetviz 是一个开源 Python 库,它只需三行代码就可以生成漂亮的高精度可视化效果来启动EDA(探索性数据分析).输出一个HTML.文末提供技术交流群,喜欢点赞支持,收藏. 如上图所示,它不仅能根据性别.年龄等不同栏目纵向分析数据,还能对每个栏目做众数.最大值.最小值等横向对比. 所有输入的数值.文本信息都会被自动检测,并进行数据分析.可视化和对比,最后自动帮你进行总结,是一个探索性数据分析的好帮手. 1.准备 请选择以下任一种方式输入命令安装依赖: 1. Windows 环境 打开
-
Python 更快进行探索性数据分析的四个方法
大家好,常用探索性数据分析方法很多,比如常用的 Pandas DataFrame 方法有 .head()..tail()..info()..describe()..plot() 和 .value_counts(). import pandas as pd import numpy as np df = pd.DataFrame( { "Student" : ["Mike", "Jack", "Diana", "Cha
-
利用Python自制网页并实现一键自动生成探索性数据分析报告
目录 前言 上传文件以及变量的筛选 前言 今天小编带领大家用Python自制一个自动生成探索性数据分析报告这样的一个工具,大家只需要在浏览器中输入url便可以轻松的访问,如下所示: 第一步 首先我们导入所要用到的模块,设置网页的标题.工具栏以及logo的导入,代码如下: from st_aggrid import AgGrid import streamlit as st import pandas as pd import pandas_profiling from streamlit_pan
-
Python 数据分析教程探索性数据分析
目录 什么是探索性数据分析(EDA)? 描述性统计 分组数据 方差分析 相关性和相关性计算 什么是探索性数据分析(EDA)? EDA 是数据分析下的一种现象,用于更好地理解数据方面,例如: – 数据的主要特征 – 变量和它们之间的关系 – 确定哪些变量对我们的问题很重要 我们将研究各种探索性数据分析方法, 例如: 描述性统计,这是一种简要概述我们正在处理的数据集的方法,包括样本的一些度量和特征 分组数据 [使用group by 进行基本分组] ANOVA,方差分析,这是一种计算方法,可将观察集
-
Python教程pandas数据分析去重复值
目录 加载数据 sample抽样函数 指定需要更新的值 append直接添加 append函数用法 根据某一列key值进行去重(key唯一) 加载数据 首先,我们需要加载到所需要的数据,这里我们所需要的数据是同过sample函数采样过来的. import pandas as pd #这里说明一下,clean_beer.csv数据有两千多行数据 #所以从其中采样一部分,来进行演示,当然可以简单实用data.head()也可以做练习 data = pd.read_csv('clean_beer.cs
-
Python 第三方库 Pandas 数据分析教程
目录 Pandas导入 Pandas与numpy的比较 Pandas的Series类型 Pandas的Series类型的创建 Pandas的Series类型的基本操作 pandas的DataFrame类型 pandas的DataFrame类型创建 Pandas的Dataframe类型的基本操作 pandas索引操作 pandas重新索引 pandas删除索引 pandas数据运算 算术运算 Pandas数据分析 pandas导入与导出数据 导入数据 导出数据 Pandas查看.检查数据 Pand
-
Python实现的大数据分析操作系统日志功能示例
本文实例讲述了Python实现的大数据分析操作系统日志功能.分享给大家供大家参考,具体如下: 一 代码 1.大文件切分 import os import os.path import time def FileSplit(sourceFile, targetFolder): if not os.path.isfile(sourceFile): print(sourceFile, ' does not exist.') return if not os.path.isdir(targetFolde
-
基于python实现微信好友数据分析(简单)
一.功能介绍 本文主要介绍利用网页端微信获取数据,实现个人微信好友数据的获取,并进行一些简单的数据分析,功能包括: 1.爬取好友列表,显示好友昵称.性别和地域和签名, 文件保存为 xlsx 格式 2.统计好友的地域分布,并且做成词云和可视化展示在地图上 二.依赖库 1.Pyecharts:一个用于生成echarts图表的类库,echarts是百度开源的一个数据可视化库,用echarts生成的图可视化效果非常棒,使用pyechart库可以在python中生成echarts数据图. 2.Itchat
-
python学习之panda数据分析核心支持库
前言 Python是一门实现数据可视化很好的语言,他们里面的很多库可以很好的画出图形,形象明了. 今天我们就来说说:Pandas数据分析核心支持库 初识Pandas: Pandas 是 Python 语言的一个扩展程序库,用于数据分析. Pandas 是一个开放源码.BSD 许可的库,提供高性能.易于使用的数据结构和数据分析工具. Pandas 名字衍生自术语 "panel data"(面板数据)和 "Python data analysis"(Python 数据分