React Fiber 链表操作及原理示例详解
目录
- 正文
- 什么是Fiber
- Fiber节点React源码
- Fiber树是链表
- 节点独立
- 节省操作时间与单向操作
- 利于双缓存与异步可中断更新操作
- 异步可中断更新
- 双缓存
正文
看了React源码之后相信大家都会对Fiber有自己不同的见解,而我对Fiber最大的见解就是这玩意儿就是个链表。如果把整个Fiber树当成一个整体确实有点难理解源码,但是如果把它拆开了,将每个节点都看成一个独立单元却能得到一个很清晰的思路,接下来我就简单几点讲讲,我所认为的为什么React要用链表这种数据结构来构建Fiber架构
什么是Fiber
可能了解过React的靓仔就要说了,Fiber就是一个虚拟dom树;确实如此,但是16版本之前的React也存在虚拟dom树,为什么要用Fiber替代呢?
众所周知(可能有靓仔不知道),16.8之前React还没引入Fiber概念,Reconciler(协调器) 会在mount阶段与update阶段循环递归mountComponent与updateComponent,此时数据存储在调用栈当中,因为是递归执行,所以一当开始便无法停止直到递归执行结束;如果此时页面中的节点非常多我们要等到递归结束可能要耗费大量的时间,而且在此之间用户会觉得卡顿,这对用户来说绝对称不上是好的体验;
因此在16版本之后React有了异步可中断更新与双缓存的概念,也就是我们熟知的同步并发模式Concurrent模式,那么这些跟Fiber有什么关系呢?
Fiber节点React源码
首先我们来看一段关于Fiber节点的React源码
function FiberNode(tag, pendingProps, key, mode) {
// Instance
//静态属性
this.tag = tag;//
this.key = key;
this.elementType = null;//
this.type = null;//类型
this.stateNode = null; // Fiber
//关联属性
this.return = null;
this.child = null;
this.sibling = null
this.index = 0;
this.ref = null;
//工作属性
this.pendingProps = pendingProps;
this.memoizedProps = null;
this.updateQueue = null;
this.memoizedState = null;
this.dependencies = null;
this.mode = mode; // Effects
this.flags = NoFlags;
this.subtreeFlags = NoFlags;
this.deletions = null;
this.lanes = NoLanes;
this.childLanes = NoLanes;
this.alternate = null;
{
// Note: The following is done to avoid a v8 performance cliff.
//
// Initializing the fields below to smis and later updating them with
// double values will cause Fibers to end up having separate shapes.
// This behavior/bug has something to do with Object.preventExtension().
// Fortunately this only impacts DEV builds.
// Unfortunately it makes React unusably slow for some applications.
// To work around this, initialize the fields below with doubles.
//
// Learn more about this here:
// https://github.com/facebook/react/issues/14365
// https://bugs.chromium.org/p/v8/issues/detail?id=8538
this.actualDuration = Number.NaN;
this.actualStartTime = Number.NaN;
this.selfBaseDuration = Number.NaN;
this.treeBaseDuration = Number.NaN; // It's okay to replace the initial doubles with smis after initialization.
// This won't trigger the performance cliff mentioned above,
// and it simplifies other profiler code (including DevTools).
this.actualDuration = 0;
this.actualStartTime = -1;
this.selfBaseDuration = 0;
this.treeBaseDuration = 0;
}
{
// This isn't directly used but is handy for debugging internals:
this._debugSource = null;
this._debugOwner = null;
this._debugNeedsRemount = false;
this._debugHookTypes = null;
if (!hasBadMapPolyfill && typeof Object.preventExtensions === 'function') {
Object.preventExtensions(this);
}
}
}
可以看到在一个FiberNode当中存在很多属性,我们大体将他们分为三类:
- 静态属性:保存当前Fiber节点的 标签,类型等;
- 关联属性:用于连接其他Fiber节点形成Fiber树;
- 工作属性:保存当前Fiber节点的动态工作单元;
而多个Fiber节点之间正是通过关联属性的连接形成一个Fiber树;因为每一个Fiber节点都是相互独立的,因此Fiber节点之间通过指针指向的方式产生联系,return指向的是父级节点,child指向的是子节点,sibling指向的是兄弟节点;
如下列这段JSX代码为例
<div className="App">
<div className='div1'>
<div className='div2'>
</div>
</div>
<div className='div3'>
</div>
</div>
最终该JSX产生的树结构为
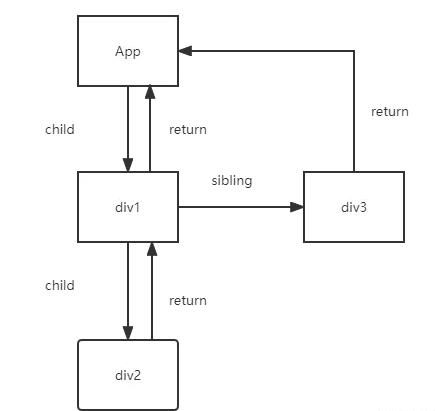
Fiber树的每个节点都是相互独立的,利用指针指向让他们关联在一起;那么我们是不是可以说Fiber树就是一个链表,关于什么是链表,可以参考我这篇博文 《作为前端你是否了解链表这种数据结构?》
Fiber树是链表
可能现在就有靓仔要问了,为什么React要选用链表这种数据结构搭建Fiber架构?
我是这么考虑的
- 节点独立
- 节省操作时间
- 利于双缓存与异步可中断更新操作
节点独立
不知道有没有靓仔会说React的Fiber架构拿父节点的child存子节点拿子节点的return存父节点怎么就节点独立了呢?这位靓仔贫道建议你再去学一下一般类型和引用类型;父节的child存的是子节点的内存地址,子节点的return存的是父节点的内存地址,因此并不会占用太多空间,说白了他们只是有一层关系将节点绑定在一起,但是这层关系并不是包含关系;就比如你女朋友是你女朋友,你是你一样,你们是情侣关系,并不是占有关系(不提倡啊!自由恋爱,人格独立);
节省操作时间与单向操作
如果Fiber树并不是链表这种数据结构而是数组这种数据结构会怎么样呢?我们都知道数组的存储需要在内存中开辟一长串有序的内存,如果我把中间的某个元素删除,那么后面的所有元素都要向上移动一个存储空间,如果现在我有1000个节点,我把第一个节点删了,那么后面的999个节点都需要在内存空间上向上移动一位,这显然是非常消耗时间的;但是如果是链表的话我们只需要将指针解绑,移动到上一位节点或者下一节点就能形成一个新的链表,这在时间上来说是非常有优势的;因为是 节点间相互独立因此我们仅仅只需要对指针进行操作并且它的操作是单向的我们不需要进行双向解绑;
我们继续以这段JSX为例
<div className="App">
<div className='div1'>
<div className='div2'>
</div>
</div>
<div className='div3'>
</div>
</div>
如果此时我们要将class为div1的节点删除fiber是如何操作的?我们用图来解释
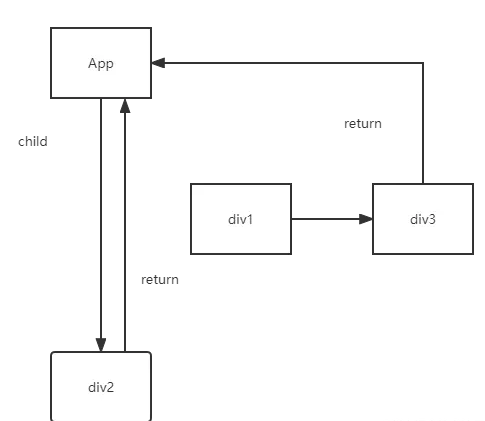
由图所示,我们只需要将App的child指针改为div2,将div2的return指针改为App即可,然后我们便可以对div1与div3进行销毁;
利于双缓存与异步可中断更新操作
异步可中断更新
我只能说React为了给用户良好的使用感受确实是下足了功夫,在React16之前React还采取着原始的同步更新,但是在在16之后React推出了concurrent模式也就是同步并发模式,在concurrent模式下你的mount与update都将成为异步可中断更新,至于react为什么要推出异步可中断更新可参考我这篇文章 《重学React之为什么需要Scheduler》
现在我们用最直观的浏览器反馈来看一下Concurrent模式与Legacy模式的区别
我们看看Legacy模式下的Performance的监听
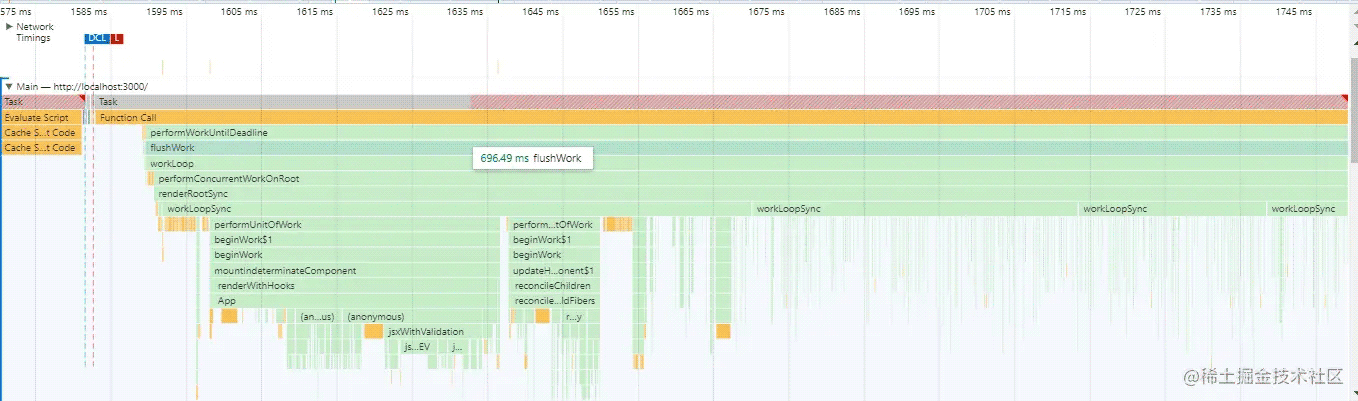
可以看到所有的render阶段方法都在同一个Task完成,如果运行时间过长将会造成卡顿;
我们再看Concurrent模式下的Performance的监听
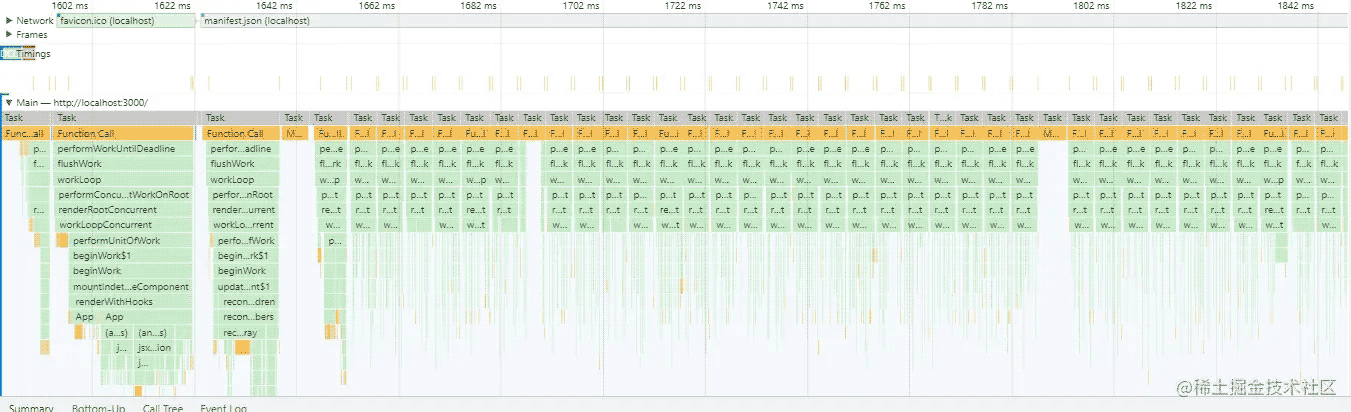
在concurrent模式下会react的render阶段会被分为若干个时长为5ms的Task
这一切归功于Scheduler调度器的功劳,因为16之前的React没有Scheduler所以采用的是所以采用的是递归的方式将数据存储在调用栈当中,递归一旦开始便无法停止,所以后来有了Scheduler;而采用链表这种数据结构(Fiber)存储数据却能很好的中断遍历;我们来看看Concurrent模式下的入口函数
function workLoopConcurrent() {
// Perform work until Scheduler asks us to yield
while (workInProgress !== null && !shouldYield()) {
performUnitOfWork(workInProgress);
}
}
可以看到当shouldYield() 为true时workLoopConcurrent方法将会中断工作,而shouldYield() 对应的正是scheduler是否需要更新调度的状态
双缓存
双缓存的概念在座的靓仔应该都清楚,React在运行时会有两棵Fiber树 (mount阶段只有workInProgress Fiber树), 一颗是current Fiber树,对应当前展示的内容,一颗是workInProgress Fiber树对应的是正在构建的Fiber树,在mount阶段的首次创建会创建一个fiberRootNode的根节点,fiberRootNode 有一个current工作单元属性,来回指向Fiber树,当workInProgess Fiber树构建完成之后current就指向workInprogress Fiber树,此时workInProgess Fiber树变为current Fiber树,而current Fiber树将变为workInProgess Fiber树,由于这一切都是在内存中进行的,所以称之为双缓存;
而这一切刚好运用了链表的灵活指向,不断形成一个新的链表;
以上就是React Fiber 链表操作原理详解的详细内容,更多关于React Fiber 链表的资料请关注我们其它相关文章!
相关推荐
-

React Fiber源码深入分析
目录 前言 React架构前世今生 React@15及之前 React@16及之后 Fiber Fiber简单理解 Fiber结构 Fiber工作原理 mount update 前言 本次React源码参考版本为17.0.3. React架构前世今生 查阅文档了解到, React@16.x是个分水岭. React@15及之前 在16之前,React架构大致可以分为两层: Reconciler: 主要职责是对比查找更新前后的变化的组件: Renderer: 主要职责是基于变化渲染页面: 但是Rea
-
react fiber执行原理示例解析
目录 为什么要使用fiber,要解决什么问题? fiber是什么? 数据结构 执行单元 浏览器工作: Fiber执行原理 workInProgress tree: currentFiber tree: Effects list: render阶段: 遍历节点过程: 收集effect list: commit阶段: 为什么commit必须是同步的操作的? 为什么要使用fiber,要解决什么问题? 在 react16 引入 Fiber 架构之前,react 会采用递归方法对比两颗虚拟DOM树,找出需
-
React Fiber结构的创建步骤
React Fiber的创建 当前React版本基于V17.0.2版本,本篇主要介绍fiber结构的创建. 一.开始之前 个人理解,如有不对,请指出. 首先需要配置好React的debugger开发环境,入口在这里:github 执行npm run i,安装依赖,npm start运行环境. 二.从React.render开始 通过在项目入口处调用React.render,打上Debug,查看React调用栈. const root = document.getElementById('root
-
详解React Fiber的工作原理
啥是React Fiber? React Fiber,简单来说就是一个从React v16开始引入的新协调引擎,用来实现Virtual DOM的增量渲染. 说人话:就是一种能让React视图更新过程变得更加流畅顺滑的处理手法. 我们都知道:进程大,线程小.而Fiber(纤维)是一种比线程还要细粒度的处理机制.从这个单词也可以猜测:React Fiber会很"细".到底怎么个细法,我们接着往下看. 为什么会有React Fiber? 之前说了,React Fiber是为了让React的视
-
详解React Fiber架构原理
目录 一.概述 二.Fiber架构 2.1 执行单元 2.2 数据结构 2.3 Fiber链表结构 2.4 Fiber节点 2.5 API 2.5.1 requestAnimationFrame 2.5.2 requestIdleCallback 三.Fiber执行流程 3.1 render阶段 3.1.1 遍历流程 3.1.2 收集effect list 3.2 commit阶段 3.2.1 根据effect list 更新视图 3.2.2 视图更新 四.总结 一.概述 在 React 16
-
React Fiber 链表操作及原理示例详解
目录 正文 什么是Fiber Fiber节点React源码 Fiber树是链表 节点独立 节省操作时间与单向操作 利于双缓存与异步可中断更新操作 异步可中断更新 双缓存 正文 看了React源码之后相信大家都会对Fiber有自己不同的见解,而我对Fiber最大的见解就是这玩意儿就是个链表.如果把整个Fiber树当成一个整体确实有点难理解源码,但是如果把它拆开了,将每个节点都看成一个独立单元却能得到一个很清晰的思路,接下来我就简单几点讲讲,我所认为的为什么React要用链表这种数据结构来构建Fib
-
C++递归与分治算法原理示例详解
目录 1. 汉诺塔问题 2. 全排列问题 4. 归并排序 5. 快速排序 6. 棋盘覆盖问题 1. 汉诺塔问题 递归算法,分为 3 步:将 n 个 a 上的盘子借助 c 移动到 b ① 将 n-1 个 a 上的盘子借助 b 移动到 c ② 将 a 上的盘子移动到 b ③ 将 c 上的 n-1 个盘子借助 a 移动到 b 所有盘子都移动到 b 上了 void hanoi(int n,char a,char b,char c)//将n个碟子从a借助c 移到b { if(n==0) return; e
-
Kotlin协程Dispatchers原理示例详解
目录 前置知识 demo startCoroutineCancellable intercepted()函数 DefaultScheduler中找dispatch函数 Runnable传入 Worker线程执行逻辑 小结 前置知识 Kotlin协程不是什么空中阁楼,Kotlin源代码会被编译成class字节码文件,最终会运行到虚拟机中.所以从本质上讲,Kotlin和Java是类似的,都是可以编译产生class的语言,但最终还是会受到虚拟机的限制,它们的代码最终会在虚拟机上的某个线程上被执行. 之
-
react中使用antd及immutable示例详解
目录 一.react中使用antd组件库 二.Immutable 2.1 深拷贝和浅拷贝的关系 2.2 immutable优化性能方式 2.3 immutable的Map使用 2.4 immutable的List使用 2.5 实际场景formJS 三.redux中使用immutable 一.react中使用antd组件库 运行命令create-react-app antd-react创建新项目: 运行命令npm i antd安装: 使用: import React from 'react' im
-
React.memo函数中的参数示例详解
目录 React.memo?这是个啥? React.memo的第一个参数 父组件 子组件 React.memo优化 React.memo的第二个参数 父组件 子组件 React.memo优化 父组件 子组件 小结 React.memo?这是个啥? 按照官方文档的解释: 如果你的函数组件在给定相同 props 的情况下渲染相同的结果,那么你可以通过将其包装在 React.memo 中调用,以此通过记忆组件渲染结果的方式来提高组件的性能表现.这意味着在这种情况下,React 将跳过渲染组件的操作并直
-
Sentinel熔断规则原理示例详解分析
目录 概述 熔断(降级)策略 慢调用比例 概念 测试 异常比例 概念 测试 异常数 概念 测试 概述 除了流量控制以外,对调用链路中不稳定的资源进行熔断降级也是保障高可用的重要措施之一. 由于调用关系的复杂性,如果调用链路中的某个资源不稳定,最终会导致请求发生堆积. Sentinel 熔断降级会在调用链路中某个资源出现不稳定状态时(例如调用超时.异常比例升高.异常数堆积) 对这个资源的调用进行限制,让请求快速失败从而避免影响到其它的资源而导致级联错误. 当资源被降级后,在接下来的降级时间窗口之内
-
支持PyTorch的einops张量操作神器用法示例详解
目录 基础用法 高级用法 今天做visual transformer研究的时候,发现了einops这么个神兵利器,决定大肆安利一波. 先看链接:https://github.com/arogozhnikov/einops 安装: pip install einops 基础用法 einops的强项是把张量的维度操作具象化,让开发者"想出即写出".举个例子: from einops import rearrange # rearrange elements according to the
-
利用Python中xlwt模块操作excel的示例详解
目录 一.安装 二.创建表格并写入 三.设置单元格样式 四.设置单元格宽度 五.设置单元格背景色 六.设置单元格内容对齐方式 七.单元格添加超链接 八.单元格添加公式 九.单元格中输入日期 十.合并行和列 十一.单元格添加边框 一.安装 pip install xlwt 二.创建表格并写入 import xlwt # 创建一个workbook并设置编码 workbook = xlwt.Workbook(encoding = 'utf-8') # 添加sheet worksheet = workb
-
React路由拦截模式及withRouter示例详解
目录 一.路由拦截 二.路由模式 三.withRouter 一.路由拦截 在前面两篇 路由博客基础上,我们将ReactRouter.js的我的profile路由设置成路由拦截的: <Route path="/profile" render={() => isAuth() ? <Profile/> : <Redirect to="/login"></Redirect> }></Route> 新建Logi
-
React特征学习之Form格式示例详解
目录 Form 样式 React hook Form 样式 首先来看一个简单Form, 式样如下 import * as React from 'react'; const LoginForm = () => { return ( <form> <div> // Notice: 这里要用htmlFor,相当于id <label htmlFor="email">Email</label> <input id="emai