详解R语言实现前向逐步回归(前向选择模型)
目录
- 前向逐步回归原理
- 数据导入并分组
- 导入数据
- 特征与标签分开存放
- 前向逐步回归构建输出特征集合
- 从空开始一次创建属性列表
- 模型效果评估
前向逐步回归原理
前向逐步回归的过程是:遍历属性的一列子集,选择使模型效果最好的那一列属性。接着寻找与其组合效果最好的第二列属性,而不是遍历所有的两列子集。以此类推,每次遍历时,子集都包含上一次遍历得到的最优子集。这样,每次遍历都会选择一个新的属性添加到特征集合中,直至特征集合中特征个数不能再增加。
数据导入并分组
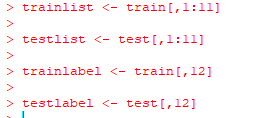
导入数据,将数据集抽取70%作为训练集,剩下30%作为测试集。特征与标签分开存放。
导入数据
R语言的实现如下图:

train和test中存储的数据情况如下:

特征与标签分开存放
R语言的实现如下图:
前向逐步回归构建输出特征集合
通过for循环,从属性的一个子集开始进行遍历。第一次遍历时,该子集为空。每一个属性被加入子集后,通过线性回归来拟合模型,并计算在测试集上的误差,每次遍历选择得到误差最小的一列加入输出特征集合中。最终得到输出特征集合的关联索引和属性名称。
从空开始一次创建属性列表
R语言的实现如下图:

模型效果评估
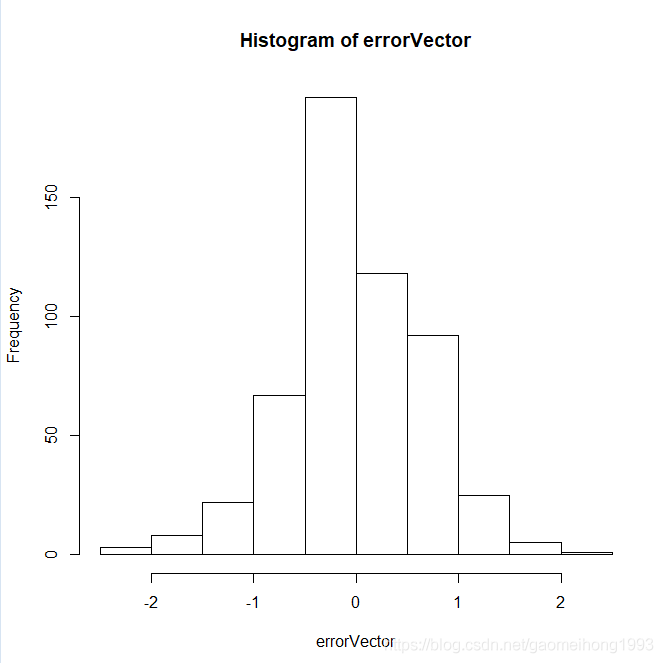
分别画出RMSE与属性个数之间的关系,前向逐步预测算法对数据预测对错误直方图,和真实标签与预测标签散点图。R实现如下:





到此这篇关于详解R语言实现前向逐步回归(前向选择模型)的文章就介绍到这了,更多相关R语言 前向逐步回归内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

R语言实现LASSO回归的方法
Lasso回归又称为套索回归,是Robert Tibshirani于1996年提出的一种新的变量选择技术.Lasso是一种收缩估计方法,其基本思想是在回归系数的绝对值之和小于一个常数的约束条件下,使残差平方和最小化,从而能够产生某些严格等于0的回归系数,进一步得到可以解释的模型.R语言中有多个包可以实现Lasso回归,这里使用lars包实现. 1.利用lars函数实现lasso回归并可视化显示 x = as.matrix(data5[, 2:7]) #data5为自己的数据集 y = as.ma
-
R语言如何进行线性回归的拟合度详解
R语言进行线性回归的拟合度. 本文只是使用 R做回归计算,查看拟合度等,不讨论 R 函数的内部公式 在R中线性回归分析的函数是lm(),基本语法是 一元回归: lm(y ~ x,data) 多元回归:lm(y ~ x1+x2+x3-,data) 创建关系模型并获取系数 x <- c(151, 174, 138, 186, 128, 136, 179, 163, 152, 131) y <- c(63, 81, 56, 91, 47, 57, 76, 72, 62, 48) # 使用lm()函数
-
R语言逻辑回归、ROC曲线与十折交叉验证详解
自己整理编写的逻辑回归模板,作为学习笔记记录分享.数据集用的是14个自变量Xi,一个因变量Y的australian数据集. 1. 测试集和训练集3.7分组 australian <- read.csv("australian.csv",as.is = T,sep=",",header=TRUE) #读取行数 N = length(australian$Y) #ind=1的是0.7概率出现的行,ind=2是0.3概率出现的行 ind=sample(2,N,rep
-
R语言如何实现多元线性回归
R小白几天的摸索 红色为输入,蓝色为输出 输入数据 先把数据用excel保存为csv格式放在"我的文档"文件夹 打开R软件,不用新建,直接写 回归计算 求三个平方和 置信区间(95%) 散点图(最显著的因变量) 拟合图 一元线性回归 结果:(看图) 变量系数 Estimate 变量系数标准误 Std. Error T检验值 t value T检验p值 Pr(>|t|) 均方根误差 Residual standard error 判定系数 R-squared 调整判定系
-
R语言逻辑回归深入讲解
逻辑回归 > ###############逻辑回归 > setwd("/Users/yaozhilin/Downloads/R_edu/data") > accepts<-read.csv("accepts.csv") > names(accepts) [1] "application_id" "account_number" "bad_ind" "vehicle_
-
在R语言中实现Logistic逻辑回归的操作
逻辑回归是拟合回归曲线的方法,当y是分类变量时,y = f(x).典型的使用这种模式被预测Ÿ给定一组预测的X.预测因子可以是连续的,分类的或两者的混合. R中的逻辑回归实现 R可以很容易地拟合逻辑回归模型.要调用的函数是glm(),拟合过程与线性回归中使用的过程没有太大差别.在这篇文章中,我将拟合一个二元逻辑回归模型并解释每一步. 数据集 我们将研究泰坦尼克号数据集.这个数据集有不同版本可以在线免费获得,但我建议使用Kaggle提供的数据集. 目标是预测生存(如果乘客幸存,则为1,否则为0)基于
-
R语言实现线性回归的示例
在统计学中,线性回归(Linear Regression)是利用称为线性回归方程的最小平方函数对一个或多个自变量和因变量之间关系进行建模的一种回归分析. 简单对来说就是用来确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法. 回归分析中,只包括一个自变量和一个因变量,且二者的关系可用一条直线近似表示,这种回归分析称为一元线性回归分析.如果回归分析中包括两个或两个以上的自变量,且因变量和自变量之间是线性关系,则称为多元线性回归分析. 一元线性回归分析法的数学方程: y = ax + b
-
详解R语言实现前向逐步回归(前向选择模型)
目录 前向逐步回归原理 数据导入并分组 导入数据 特征与标签分开存放 前向逐步回归构建输出特征集合 从空开始一次创建属性列表 模型效果评估 前向逐步回归原理 前向逐步回归的过程是:遍历属性的一列子集,选择使模型效果最好的那一列属性.接着寻找与其组合效果最好的第二列属性,而不是遍历所有的两列子集.以此类推,每次遍历时,子集都包含上一次遍历得到的最优子集.这样,每次遍历都会选择一个新的属性添加到特征集合中,直至特征集合中特征个数不能再增加. 数据导入并分组 导入数据,将数据集抽取70%作为训练集,剩
-
详解R语言中的表达式、数学公式、特殊符号
在R语言的绘图函数中,如果文本参数是合法的R语言表达式,那么这个表达式就被用Tex类似的规则进行文本格式化. y <- function(x) (exp(-(x^2)/2))/sqrt(2*pi) plot(y, -5, 5, main = expression(f(x) == frac(1,sqrt(2*pi))*e^(-frac(x^2,2))), lwd = 3, col = "blue") library(ggplot2) x <- seq(0, 2*pi, b
-
详解R语言中生存分析模型与时间依赖性ROC曲线可视化
R语言简介 R是用于统计分析.绘图的语言和操作环境.R是属于GNU系统的一个自由.免费.源代码开放的软件,它是一个用于统计计算和统计制图的优秀工具. 人们通常使用接收者操作特征曲线(ROC)进行二元结果逻辑回归.但是,流行病学研究中感兴趣的结果通常是事件发生时间.使用随时间变化的时间依赖性ROC可以更全面地描述这种情况下的预测模型. 时间依赖性ROC定义 令 Mi为用于死亡率预测的基线(时间0)标量标记. 当随时间推移观察到结果时,其预测性能取决于评估时间 t.直观地说,在零时间测量的标记值应该
-
详解R语言中的多项式回归、局部回归、核平滑和平滑样条回归模型
在标准线性模型中,我们假设 .当线性假设无法满足时,可以考虑使用其他方法. 多项式回归 扩展可能是假设某些多项式函数, 同样,在标准线性模型方法(使用GLM的条件正态分布)中,参数 可以使用最小二乘法获得,其中 在 . 即使此多项式模型不是真正的多项式模型,也可能仍然是一个很好的近似值 .实际上,根据 Stone-Weierstrass定理,如果 在某个区间上是连续的,则有一个统一的近似值 ,通过多项式函数. 仅作说明,请考虑以下数据集 db = data.frame(x=xr,y=y
-
详解R语言数据合并一行代码搞定
数据的合并 需要的函数 cbind(),rbind(),bind_rows(),merge() 准备数据 我们先构造一组数据,以便下面的演示 > data1<-data.frame( + namea=c("海波","立波","秀波"), + value=c("一波","接","一波") + ) > data1 namea value 1 海波 一波 2 立波 接 3 秀
-
详解R语言图像处理EBImage包
目录 什么是EBImage 1. 图像读取与保存 2.色彩管理 3.图像处理 4.空间变换 5.形态运算 6.图像分割 本文摘自<Keras深度学习:入门.实战及进阶>第四章部分章节. 什么是EBImage EBImage是R的一个扩展包,提供了用于读取.写入.处理和分析图像的通用功能,非常容易上手.EBImage包在Bioconductor中,通过以下命令进行安装. install.packages("BiocManager") BiocManager::install(
-
详解R语言caret包trainControl函数
目录 trainControl参数详解 源码 参数详解 示例 trainControl参数详解 源码 caret::trainControl <- function (method = "boot", number = ifelse(grepl("cv", method), 10, 25), repeats = ifelse(grepl("[d_]cv$", method), 1, NA), p = 0.75, search = "
-
详解R语言plot函数参数合集
最近用R语言画图,plot 函数是用的最多的函数,而他的参数非常繁多,由此总结一下,以供后续方便查阅. plot(x, y = NULL, type = "p", xlim = NULL, ylim = NULL, log = "", main = NULL, sub = NULL, xlab = NULL, ylab = NULL, ann = par("ann"), axes = TRUE, frame.plot = axes, panel.
-
详解R语言MCMC:Metropolis-Hastings采样用于回归的贝叶斯估计
MCMC是从复杂概率模型中采样的通用技术. 蒙特卡洛 马尔可夫链 Metropolis-Hastings算法 问题 如果需要计算有复杂后验pdf p(θ| y)的随机变量θ的函数f(θ)的平均值或期望值. 您可能需要计算后验概率分布p(θ)的最大值. 解决期望值的一种方法是从p(θ)绘制N个随机样本,当N足够大时,我们可以通过以下公式逼近期望值或最大值 将相同的策略应用于通过从p(θ| y)采样并取样本集中的最大值来找到argmaxp(θ| y). 解决方法 1.1直接模拟 1.2逆CDF 1.
-
详解R语言中的PCA分析与可视化
1. 常用术语 (1)标准化(Scale) 如果不对数据进行scale处理,本身数值大的基因对主成分的贡献会大.如果关注的是变量的相对大小对样品分类的贡献,则应SCALE,以防数值高的变量导入的大方差引入的偏见.但是定标(scale)可能会有一些负面效果,因为定标后变量之间的权重就是变得相同.如果我们的变量中有噪音的话,我们就在无形中把噪音和信息的权重变得相同,但PCA本身无法区分信号和噪音.在这样的情形下,我们就不必做定标. (2)特征值 (eigen value) 特征值与特征向量均为矩阵分