MySql存储过程循环的使用分析详解
目录
- 简介
- 场景描述
- 解决方案
- 案例
- 总结
简介
每一门数据库语言语法都基本相似,但是对于他们各自的一些特性(函数、存储过程等)的用法就不大相同了,就好比Oracle与Mysql存储过程写起来就很多不同的地方,在这里主要是跟大家分享一下MySql存储过程中使用游标循环的处理方法。
场景描述
我们举一个简单的场景,首先我们可能会有这样一种情况,考试成绩表(t_achievement)有一堆的sql脚本处理,需要依赖另一个学生表(t_student)数据对部分学生做考试成绩汇总记录到成绩汇总表(t_achievement_report)。
解决方案
- 有一种方式就是通过代码优先将要汇总的学生表数据获取出来,然后按成绩汇总流程逐个将学生信息数据传递到成绩汇总业务代码进行处理。
- 另一种方式也是我们今天的主题,那就是通过存储过程的方式去做。
案例
建表语句:
-- 学生信息表 DROP TABLE IF EXISTS t_student; CREATE TABLE `t_student` ( `id` BIGINT(12) NOT NULL AUTO_INCREMENT COMMENT '主键', `code` VARCHAR(10) NOT NULL COMMENT '学号', `name` VARCHAR(20) NOT NULL COMMENT '姓名', `age` INT(2) NOT NULL COMMENT '年龄', `gender` CHAR(1) NOT NULL COMMENT '性别(M:男,F:女)', PRIMARY KEY (`id`), UNIQUE KEY UK_STUDENT (`code`) ) CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci;
-- 学生成绩表 DROP TABLE IF EXISTS t_achievement; CREATE TABLE `t_achievement` ( `id` BIGINT(12) NOT NULL AUTO_INCREMENT COMMENT '主键', `year` INT(4) NOT NULL COMMENT '学年', `subject` CHAR(2) NOT NULL COMMENT '科目(01:语文,02:数学,03:英语)', `score` INT(3) NOT NULL COMMENT '得分', `student_id` BIGINT(12) NOT NULL COMMENT '所属学生id', PRIMARY KEY (`id`) ) CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci;
-- 成绩汇总表 DROP TABLE IF EXISTS t_achievement_report; CREATE TABLE `t_achievement_report` ( `id` BIGINT(12) NOT NULL AUTO_INCREMENT COMMENT '主键', `student_id` BIGINT(12) NOT NULL COMMENT '学生id', `year` INT(4) NOT NULL COMMENT '学年', `total_score` INT(4) NOT NULL COMMENT '总分', `avg_score` DECIMAL(4,2) NOT NULL COMMENT '平均分', PRIMARY KEY (`id`) ) CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci;
初始化数据:
INSERT INTO t_student(id, CODE, NAME, age, gender) VALUES (1, '2022010101', '小张', 18, 'M'), (2, '2022010102', '小李', 18, 'F'), (3, '2022010103', '小明', 18, 'M'); INSERT INTO t_achievement(YEAR, SUBJECT, score, student_id) VALUES (2022, '01', 80, 1), (2022, '02', 85, 1), (2022, '03', 90, 1), (2022, '01', 60, 2), (2022, '02', 90, 2), (2022, '03', 98, 2), (2022, '01', 75, 3), (2022, '02', 100, 3), (2022, '03', 85, 3);


存储过程:
在这里主要以上面的场景为例,使用存储过程循环去处理数据。写一个存储过程,将以上数据每个学生的成绩进行汇总。
-- 如果存储过程存在,先删除存储过程
DROP PROCEDURE IF EXISTS statistics_achievement;
DELIMITER $$
-- 定义存储过程
CREATE PROCEDURE statistics_achievement()
BEGIN
-- 定义变量记录循环处理是否完成
DECLARE done BOOLEAN DEFAULT FALSE;
-- 定义变量传递学生id
DECLARE studentid BIGINT(12);
-- 定义游标
DECLARE cursor_student CURSOR FOR SELECT id FROM t_student;
-- 定义CONTINUE HANDLER,当循环结束时 done=true
DECLARE CONTINUE HANDLER FOR SQLSTATE '02000' SET done=TRUE;
-- 打开游标
OPEN cursor_student;
-- 重复遍历
REPEAT
-- 每次读取一次游标
FETCH cursor_student INTO studentid;
-- 计算总分、平均分插入汇总表
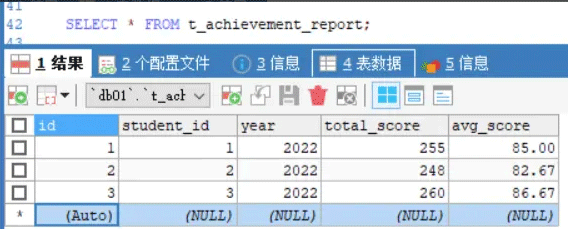
INSERT INTO t_achievement_report(student_id, `YEAR`, total_score, avg_score)
SELECT studentid, `YEAR`, SUM(score), ROUND(SUM(score) / 3, 2) FROM t_achievement t1 WHERE student_id = studentid AND NOT EXISTS(
SELECT 1 FROM t_achievement_report t2 WHERE student_id = studentid AND t1.year = t2.year
) GROUP BY `YEAR`;
-- 结束循环,意思是等到done=true时,结束循环REPEAT
UNTIL done END REPEAT;
-- 查询结果,仅会展示查出的最后一条
SELECT studentid;
-- 关闭游标
CLOSE cursor_student;
END$$
DELIMITER ;
-- 执行存储过程 CALL statistics_achievement();
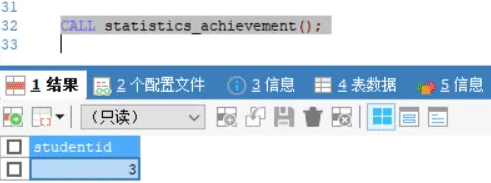
- 执行结果,返回查询结果3,即最后一条学生记录id
总结
存储过程也有很强大的功能,如果是一名DBA那么写存储过程是分分钟的事,但是作为一名专做业务的码农还是不建议去使用存储过程写业务代码。前公司同事适应了写存储过程,有业务改动时不时的直接用存储过程搞定了,到最后直接就是一大堆堆存储过程代码,一个存储过程下来几百上千行sql代码头都看晕掉,出问题巨难维护,稍有不熟的人员都不敢轻举妄动,今天在这里也只是为了讲解存储过程中的循环而举了个栗子请别介意。
总之我认为存储过程主要还是用来临时处理一些数据方便而用一下,特别有些业务改造大,需要做数据割接总不能挨个去写一个业务代码吧。
到此这篇关于MySql存储过程循环的使用分析详解的文章就介绍到这了,更多相关MySql存储过程循环内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
MySQL存储过程中使用WHILE循环语句的方法
本文实例讲述了MySQL存储过程中使用WHILE循环语句的方法.分享给大家供大家参考.具体如下: mysql> mysql> delimiter $$ mysql> mysql> CREATE PROCEDURE myProc() -> BEGIN -> -> DECLARE i int; -> SET i=1; -> loop1: WHILE i<=10 DO -> IF MOD(i,2)<>0 THEN /*Even num
-
Mysql存储过程循环内嵌套使用游标示例代码
BEGIN -- 声明变量 DECLARE v_addtime_begin varchar(13); DECLARE v_addtime_end varchar(13); DECLARE v_borrow_id int; DECLARE v_count int; DECLARE s1 int; /** 声明游标,并将查询结果存到游标中 **/ DECLARE c_borrow CURSOR FOR SELECT ID from rocky_borrow WHERE BORROWTYPE = 2
-
mysql存储过程 游标 循环使用介绍
Mysql的存储过程是从版本5才开始支持的,所以目前一般使用的都可以用到存储过程.今天分享下自己对于Mysql存储过程的认识与了解. 一些简单的调用以及语法规则这里就不在赘述,网上有许多例子.这里主要说说大家常用的游标加循环的嵌套使用. 首先先介绍循环的分类: (1)WHILE ... END WHILE (2)LOOP ... END LOOP (3)REPEAT ... END REPEAT (4)GOTO 这里有三种标准的循环方式:WHILE循环,LOOP循环以及REPEAT循环.还有一种
-

MySql存储过程循环的使用分析详解
目录 简介 场景描述 解决方案 案例 总结 简介 每一门数据库语言语法都基本相似,但是对于他们各自的一些特性(函数.存储过程等)的用法就不大相同了,就好比Oracle与Mysql存储过程写起来就很多不同的地方,在这里主要是跟大家分享一下MySql存储过程中使用游标循环的处理方法. 场景描述 我们举一个简单的场景,首先我们可能会有这样一种情况,考试成绩表(t_achievement)有一堆的sql脚本处理,需要依赖另一个学生表(t_student)数据对部分学生做考试成绩汇总记录到成绩汇总表(t_
-
mysql存储过程原理与使用方法详解
本文实例讲述了mysql存储过程原理与使用方法.分享给大家供大家参考,具体如下: 存储过程包含了一系列可执行的sql语句,存储过程存放于MySQL中,通过调用它的名字可以执行其内部的一堆sql 存储过程的优点 #1. 用于替代程序写的SQL语句,实现程序与sql解耦 #2. 可以通过直接修改存储过程的方式修改业务逻辑(或bug),而不用重启服务器 #3. 执行速度快,存储过程经过编译之后会比单独一条一条执行要快 #4. 减少网络传输,尤其是在高并发情况下这点优势大,存储过程直接就在数据库服务器上
-
mysql存储过程之错误处理实例详解
本文实例讲述了mysql存储过程之错误处理.分享给大家供大家参考,具体如下: 当存储过程中发生错误时,重要的是适当处理它,例如:继续或退出当前代码块的执行,并发出有意义的错误消息.其中mysql提供了一种简单的方法来定义处理从一般条件(如警告或异常)到特定条件(例如特定错误代码)的处理程序.完事我们来使用DECLARE HANDLER语句来尝试声明一个处理程序,先来看语法: DECLARE action HANDLER FOR condition_value statement; 上述sql中,
-
MySQL的存储函数与存储过程相关概念与具体实例详解
目录 MySQL存储过程与存储函数的相关概念 存储过程 存储函数 存储函数与存储过程的对比 存储过程和函数的查看修改删除 MySQL存储过程与存储函数的相关概念 存储函数和存储过程的主要区别: 存储函数一定会有返回值的 存储过程不一定有返回值 存储过程和函数能后将复杂的SQL逻辑封装在一起,应用程序无需关注存储过程和函数内部复杂的SQL逻辑,而只需要简单地调用存储过程和函数即可 存储过程 一组预先编译的SQL语句的封装 执行过程:执行过程预先存储在MySQL服务器上,需要执行的时候,客户端只需要
-
MySQL定时任务(EVENT事件)如何配置详解
一.事件(EVENT)是干什么的 自MySQL5.1.6起,增加了一个非常有特色的功能 - 事件调度器(Event Scheduler),可以用做定时执行某些特定任务(例如:删除记录.数据统计报告.数据备份等等),来取代原先只能由操作系统的计划任务来执行的工作. 值得一提的是MySQL的事件调度器可以精确到每秒钟执行一个任务,而操作系统的计划任务(如:Linux的cron)只能精确到每分钟执行一次.对于一些对数据实时性要求比较高的应用(例如:股票.赔率.比分等)就非常适合. 事件有时
-
MySQL一些常用高级SQL语句详解
目录 一.MySQL进阶查询 二.MySQL数据库函数 三.MySQL存储过程 总结 一.MySQL进阶查询 首先先创建两张表 mysql -u root -pXXX #登陆数据库,XXX为密码 create database jiangsu; #新建一个名为jiangsu的数据库 use jiangsu; #使用该数据库 create table location(Region char(20),Store_name char(20)); #创建location表,字段1为Region,数据类
-
MySQL操作之JSON数据类型操作详解
上一篇文章我们介绍了mysql数据存储过程参数实例详解,今天我们看看MySQL操作之JSON数据类型的相关内容. 概述 mysql自5.7.8版本开始,就支持了json结构的数据存储和查询,这表明了mysql也在不断的学习和增加nosql数据库的有点.但mysql毕竟是关系型数据库,在处理json这种非结构化的数据时,还是比较别扭的. 创建一个JSON字段的表 首先先创建一个表,这个表包含一个json格式的字段: CREATE TABLE table_name ( id INT NOT NULL
-
MySQL数据库使用mysqldump导出数据详解
mysqldump是mysql用于转存储数据库的客户端程序.它主要产生一系列的SQL语句,可以封装到文件,该文件包含有所有重建您的数据库所需要的 SQL命令如CREATE DATABASE,CREATE TABLE,INSERT等等.可以用来实现轻量级的快速迁移或恢复数据库.是mysql数据库实现逻辑备份的一种方式. 在日常维护工作当中经常会需要对数据进行导出操作,而mysqldump是导出数据过程中使用非常频繁的一个工具:它自带的功能参数非常多,文章中会列举出一些常用的操作,在文章末尾会将所有
-
Mysql事项,视图,函数,触发器命令(详解)
事项开启和使用 //修改表的引擎 alter table a engine=myisam; //开启事务 begin; //关闭自动提交 set autocommit=0; //扣100 update bank set money=money-100 where bid=1; //回滚,begin开始的所有sql语句操作 rollback; //开启事务 begin; //关闭自动提交 set autocommit=0; //扣100 update bank set money=money-10
-
SQL Server 树形表非循环递归查询的实例详解
很多人可能想要查询整个树形表关联的内容都会通过循环递归来查...事实上在微软在SQL2005或以上版本就能用别的语法进行查询,下面是示例. --通过子节点查询父节点 WITH TREE AS( SELECT * FROM Areas WHERE id = 6 -- 要查询的子 id UNION ALL SELECT Areas.* FROM Areas, TREE WHERE TREE.PId = Areas.Id ) SELECT Area FROM TREE --通过父节点查询子节点 WIT