python深度学习人工智能BackPropagation链式法则
目录
- 1.链式法则
- 2.前向传播
- 3.后向传播
- 4.计算方式整理
- 5.总结
1.链式法则

根据以前的知识,如果我们需要寻找到目标参数的值的话,我们需要先给定一个初值,然后通过梯度下降,不断对其更新,直到最终的损失值最小即可。而其中最关键的一环,就是梯度下降的时候,需要的梯度,也就是需要求最终的损失函数对参数的导数。
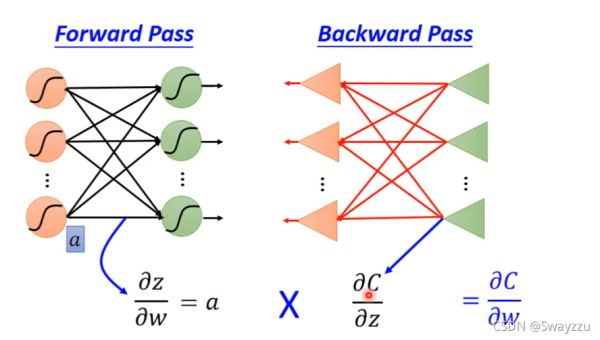
如下图,假设有一个神经元,是输入层,有2个数据,参数分别是w1和w2,偏置项为b,那么我们需要把这些参数组合成一个函数z,然后将其输入到sigmoid函数中,便可得到该神经元的输出结果。过程中,z对w求导十分好算,就是x1和x2。根据链式法则,如下图左下角所示,我们整体的计算过程就是,通过前向传播求出z对w的偏导,再通过反向传播找到损失函数C对z的偏导。

2.前向传播
计算z对w的偏导:前向传播相当简单,对参数的偏导结果就是参数对应的输入数据,如下图所示。输入数据对于输入层来说就是原始数据1和-1,对于其他层,输入数据就是通过sigmoid转换后的输出结果。

3.后向传播
计算C对z的偏导:
设每一个神经元中,sigmoid函数最终的输出为a,则C对z的偏导,根据链式法则,就可以写作a对z的偏导,乘上C对a的偏导。
a对z的偏导,只是一个sigmoid函数,该函数偏导可以计算。
C对a的偏导,由于a输入进了下一层的多个神经元,假设有2个,因此,C对a的偏导,等于分别对这两个神经元求偏导并求和。比如第一个神经元z' = 输入a*权重w3+...,那么C对这个神经元求偏导,就是C对z'求偏导,乘上z'对a求偏导,后一项十分简单,就是w3;对于z''来说,对a求偏导就是w4
那么问题又变成了,C对z', z''求偏导的结果是什么?

假!如! 损失函数C对z'和z''的偏导已知了:
以上C对z求偏导的计算过程,可以写作以下的式子,括号外就是a对z求偏导,括号内就是C对a求偏导:

这个式子可以看做一个反向传播的神经元,如下图所示:
这个神经元中,损失函数C对sigmoid转化前的z' 和z''求导的结果,就是输入,权重w3,w4是输入对应的权重,将这两个输入乘上参数后相加,再和sigmoid函数对z的导数相乘,最终得到C对z的偏导。而sigmoid对z的导数,这个是常数,并且已经是确定了的,因为我们通过前向传播计算,就已经能够将其确定。

有了第一个反向传播的输出结果,那么就可以有隐藏层的其他神经元所需要的结果,以此类推,对于所有神经元,我们均可算出损失函数对其z的偏导。有了这个,那么我们结合z对w的偏导,就可以计算出每一个参数w的梯度。从而进行梯度下降。
4.计算方式整理
假设我们计算的是输出层,那么我们通过前向传播后,已经得到了一个输出了,于是就已经有损失函数C了,同时前向传播也让我们得到了z'和z'',那么所有需要的数据已就绪,可以直接计算出来C对z'和z''的偏导。

假如我们计算的是中间层,在计算C对z'的偏导的时候,还需要下一层通过反向传播给到的C对两个其他z的结果,那么我们就继续往下计算,继续寻找下一层计算的时候,需要的下下一层的信息,一直到输出层后,我们得到一个,再往回推,以此递归计算前面待定的所有项。

5.总结
既然我们需要输出层的内容作为反向传播的输入,我们在进行完前向传播之后,就别考虑前面需要什么求导了,干脆直接从结尾开始算起,得到每一层的损失函数C对每一个z的偏导即可。

至此,我们得到了每一个神经元前向传播的z对w的偏导(其实就是sigmoid转化后的输出a),以及每一个神经元反向传播后的C对z的偏导,二者相乘,就得到了我们需要的结果,也就是每一个参数的梯度。
以上就是python深度学习人工智能BackPropagation链式法则的详细内容,更多关于python人工智能BackPropagation链式法则的资料请关注我们其它相关文章!
相关推荐
-

python人工智能深度学习算法优化
目录 1.SGD 2.SGDM 3.Adam 4.Adagrad 5.RMSProp 6.NAG 1.SGD 随机梯度下降 随机梯度下降和其他的梯度下降主要区别,在于SGD每次只使用一个数据样本,去计算损失函数,求梯度,更新参数.这种方法的计算速度快,但是下降的速度慢,可能会在最低处两边震荡,停留在局部最优. 2.SGDM SGM with Momentum:动量梯度下降 动量梯度下降,在进行参数更新之前,会对之前的梯度信息,进行指数加权平均,然后使用加权平均之后的梯度,来代替原梯度,进行参数的
-
python人工智能深度学习入门逻辑回归限制
目录 1.逻辑回归的限制 2.深度学习的引入 3.深度学习的计算方式 4.神经网络的损失函数 1.逻辑回归的限制 逻辑回归分类的时候,是把线性的函数输入进sigmoid函数进行转换,后进行分类,会在图上画出一条分类的直线,但像下图这种情况,无论怎么画,一条直线都不可能将其完全分开. 但假如我们可以对输入的特征进行一个转换,便有可能完美分类.比如: 创造一个新的特征x1:到(0,0)的距离,另一个x2:到(1,1)的距离.这样可以计算出四个点所对应的新特征,画到坐标系上如以下右图所示.这样转换之后
-
浅谈机器学习需要的了解的十大算法
毫无疑问,近些年机器学习和人工智能领域受到了越来越多的关注.随着大数据成为当下工业界最火爆的技术趋势,机器学习也借助大数据在预测和推荐方面取得了惊人的成绩.比较有名的机器学习案例包括Netflix根据用户历史浏览行为给用户推荐电影,亚马逊基于用户的历史购买行为来推荐图书. 那么,如果你想要学习机器学习的算法,该如何入门呢?就我而言,我的入门课程是在哥本哈根留学时选修的人工智能课程.老师是丹麦科技大学应用数学和计算机专业的全职教授,他的研究方向是逻辑学和人工智能,主要是用逻辑学的方法来建模.课程包
-
Python人工智能深度学习模型训练经验总结
目录 一.假如训练集表现不好 1.尝试新的激活函数 2.自适应学习率 ①Adagrad ②RMSProp ③ Momentum ④Adam 二.在测试集上效果不好 1.提前停止 2.正则化 3.Dropout 一.假如训练集表现不好 1.尝试新的激活函数 ReLU:Rectified Linear Unit 图像如下图所示:当z<0时,a = 0, 当z>0时,a = z,也就是说这个激活函数是对输入进行线性转换.使用这个激活函数,由于有0的存在,计算之后会删除掉一些神经元,使得神经网络变窄.
-
Python人工智能深度学习CNN
目录 1.CNN概述 2.卷积层 3.池化层 4.全连层 1.CNN概述 CNN的整体思想,就是对图片进行下采样,让一个函数只学一个图的一部分,这样便得到少但是更有效的特征,最后通过全连接神经网络对结果进行输出. 整体架构如下: 输入图片 →卷积:得到特征图(激活图) →ReLU:去除负值 →池化:缩小数据量同时保留最有效特征 (以上步骤可多次进行) →输入全连接神经网络 2.卷积层 CNN-Convolution 卷积核(或者被称为kernel, filter, neuron)是要被学出来的,
-
人工智能机器学习常用算法总结及各个常用算法精确率对比
本文讲解了机器学习常用算法总结和各个常用分类算法精确率对比.收集了现在比较热门的TensorFlow.Sklearn,借鉴了Github和一些国内外的文章. 机器学习的知识树,这个图片是Github上的,有兴趣的可以自己去看一下: 地址:https://github.com/trekhleb/homemade-machine-learning 简单的翻译一下这个树: 英文 中文 Machine Learning 机器学习 Supervised Learning 监督学习 Unsupervised
-
python深度学习人工智能BackPropagation链式法则
目录 1.链式法则 2.前向传播 3.后向传播 4.计算方式整理 5.总结 1.链式法则 根据以前的知识,如果我们需要寻找到目标参数的值的话,我们需要先给定一个初值,然后通过梯度下降,不断对其更新,直到最终的损失值最小即可.而其中最关键的一环,就是梯度下降的时候,需要的梯度,也就是需要求最终的损失函数对参数的导数. 如下图,假设有一个神经元,是输入层,有2个数据,参数分别是w1和w2,偏置项为b,那么我们需要把这些参数组合成一个函数z,然后将其输入到sigmoid函数中,便可得到该神经元的输出结
-
13个最常用的Python深度学习库介绍
如果你对深度学习和卷积神经网络感兴趣,但是并不知道从哪里开始,也不知道使用哪种库,那么这里就为你提供了许多帮助. 在这篇文章里,我详细解读了9个我最喜欢的Python深度学习库. 这个名单并不详尽,它只是我在计算机视觉的职业生涯中使用并在某个时间段发现特别有用的一个库的列表. 这其中的一些库我比别人用的多很多,尤其是Keras.mxnet和sklearn-theano. 其他的一些我是间接的使用,比如Theano和TensorFlow(库包括Keras.deepy和Blocks等). 另外的我只
-
python 深度学习中的4种激活函数
这篇文章用来整理一下入门深度学习过程中接触到的四种激活函数,下面会从公式.代码以及图像三个方面介绍这几种激活函数,首先来明确一下是哪四种: Sigmoid函数 Tahn函数 ReLu函数 SoftMax函数 激活函数的作用 下面图像A是一个线性可分问题,也就是说对于两类点(蓝点和绿点),你通过一条直线就可以实现完全分类. 当然图像A是最理想.也是最简单的一种二分类问题,但是现实中往往存在一些非常复杂的线性不可分问题,比如图像B,你是找不到任何一条直线可以将图像B中蓝点和绿点完全分开的,你必须圈出
-
Python深度学习之图像标签标注软件labelme详解
前言 labelme是一个非常好用的免费的标注软件,博主看了很多其他的博客,有的直接是翻译稿,有的不全面.对于新手入门还是有点困难.因此,本文的主要是详细介绍labelme该如何使用. 一.labelme是什么? labelme是图形图像注释工具,它是用Python编写的,并将Qt用于其图形界面.说直白点,它是有界面的, 像软件一样,可以交互,但是它又是由命令行启动的,比软件的使用稍微麻烦点.其界面如下图: 它的功能很多,包括: 对图像进行多边形,矩形,圆形,多段线,线段,点形式的标注(可用于目
-
Python深度学习之简单实现猫狗图像分类
一.前言 本文使用的是 kaggle 猫狗大战的数据集 训练集中有 25000 张图像,测试集中有 12500 张图像.作为简单示例,我们用不了那么多图像,随便抽取一小部分猫狗图像到一个文件夹里即可. 通过使用更大.更复杂的模型,可以获得更高的准确率,预训练模型是一个很好的选择,我们可以直接使用预训练模型来完成分类任务,因为预训练模型通常已经在大型的数据集上进行过训练,通常用于完成大型的图像分类任务. tf.keras.applications中有一些预定义好的经典卷积神经网络结构(Applic
-
Python深度学习之使用Pytorch搭建ShuffleNetv2
一.model.py 1.1 Channel Shuffle def channel_shuffle(x: Tensor, groups: int) -> Tensor: batch_size, num_channels, height, width = x.size() channels_per_group = num_channels // groups # reshape # [batch_size, num_channels, height, width] -> [batch_size
-
Python深度学习之Pytorch初步使用
一.Tensor Tensor(张量是一个统称,其中包括很多类型): 0阶张量:标量.常数.0-D Tensor:1阶张量:向量.1-D Tensor:2阶张量:矩阵.2-D Tensor:-- 二.Pytorch如何创建张量 2.1 创建张量 import torch t = torch.Tensor([1, 2, 3]) print(t) 2.2 tensor与ndarray的关系 两者之间可以相互转化 import torch import numpy as np t1 = np.arra
-
Python深度学习之实现卷积神经网络
一.卷积神经网络 Yann LeCun 和Yoshua Bengio在1995年引入了卷积神经网络,也称为卷积网络或CNN.CNN是一种特殊的多层神经网络,用于处理具有明显网格状拓扑的数据.其网络的基础基于称为卷积的数学运算. 卷积神经网络(CNN)的类型 以下是一些不同类型的CNN: 1D CNN:1D CNN 的输入和输出数据是二维的.一维CNN大多用于时间序列. 2D CNNN:2D CNN的输入和输出数据是三维的.我们通常将其用于图像数据问题. 3D CNNN:3D CNN的输入和输出数
-
Python深度学习之使用Albumentations对图像做增强
目录 一.导入所需的库 二.定义可视化函数显示图像上的边界框和类标签 三.获取图像和标注 四.使用RandomSizedBBoxSafeCrop保留原始图像中的所有边界框 五.定义增强管道 六.输入用于增强的图像和边框 七.其他不同随机种子的示例 一.导入所需的库 import random import cv2 from matplotlib import pyplot as plt import albumentations as A 二.定义可视化函数显示图像上的边界框和类标签 可视化函数
-
Python深度学习pyTorch权重衰减与L2范数正则化解析
下面进行一个高维线性实验 假设我们的真实方程是: 假设feature数200,训练样本和测试样本各20个 模拟数据集 num_train,num_test = 10,10 num_features = 200 true_w = torch.ones((num_features,1),dtype=torch.float32) * 0.01 true_b = torch.tensor(0.5) samples = torch.normal(0,1,(num_train+num_test,num_fe