scrapy爬虫部署服务器的方法步骤
目录
- 一、scrapy爬虫部署服务器
- 1、scrapyd
- 2.安装
- 2、scrapy-client
- 3、scrapydweb(可选)
- 二、实际操作(一切的操作都在scrapyd启动的情况下)
- 三、数据展示
- 四、问题与思考
- 五、收获
一、scrapy爬虫部署服务器
scrapy通过命令行运行一般只用于测试环境,而用于运用在生产环境则一般都部署在服务器中进行远程操作。
scrapy部署服务器有一套完整的开源项目:scrapy+scrapyd(服务端)+scrapy-client(客户端)+scrapydweb
1、scrapyd
1.介绍
Scrapyd是用于部署和运行Scrapy爬虫的应用程序。它使您可以使用JSON API部署(上传)项目并控制其爬虫。
是目前分布式爬虫的最好解决方法之一
官方文档 https://scrapyd.readthedocs.io/
2.安装
pip install scrapyd
安装过程中可能会遇到大量的错误,大部分都是所依赖的包没有安装,安装过程中要确保scrapy已经安装成功,只要耐心的将所有缺少的依赖包安装上就可以了
打开命令行,输入scrapyd,如下图:

浏览器访问:http://127.0.0.1:6800/
2、scrapy-client
1.介绍:
scrapy-client它允许我们将本地的scrapy项目打包发送到scrapyd 这个服务端(前提是服务器scrapyd正常运行)
官方文档https://pypi.org/project/scrapyd-client/
2.安装
pip install scrapy-client
和上面的scrapyd一样,可能会遇到各种错误,耐心一点,大部分都是安装依赖
3、scrapydweb(可选)
1.介绍
ScrapydWeb:用于Scrapyd集群管理的Web应用程序,支持Scrapy日志分析和可视化。
官方文档:https://pypi.org/project/scrapydweb/
2.安装
pip install scrapyd
在保持scrapyd挂起的情况下运行命令scrapydweb,也就是需要打开两个doc窗口
运行命令scrapydweb,首次启动将会在当前目录下生成配置文件“scrapydweb_settings_v*.py”
更改配置文件
编辑配置文件,将ENABLE_LOGPARSER更改为False
添加访问权限
SCRAPYD_SERVERS = [
'127.0.0.1:6800',
# 'username:password@localhost:6801#group',
('username', 'password', 'localhost', '6801', 'group'),
]
HTTP基本认证
ENABLE_AUTH = True USERNAME = 'username' PASSWORD = 'password'
浏览器访问:http://127.0.0.1:5000/1/servers/

二、实际操作(一切的操作都在scrapyd启动的情况下)
1.上传爬虫

编辑scrapy.cfg,url是scrapyd服务器的位置,由于scrapyd在本地,所以是localhost。
注意:我们要切换到和scrapy.cfg同级目录下,继续以下操作
scrapyd-deploy

上图表示运行成功!

以上的文件夹是成功后自动创建的(为什么之前的截图有,我之前已经测试过)
然后输入以下命令上传服务器
scrapyd-deploy demo -p qcjob
结构:scrapyd-deploy -p (scrapyd-deploy <目标> -p <项目>)
运行成功的图片

2.启动爬虫
cmd输入(爬取一天内关于java的职业需求)
curl http://localhost:6800/schedule.json -d project=qcjob -d spider=job -d key = java time=0
我编写的爬虫可以根据用户输入的参数来爬取数据
key=表示关键字(默认是全部)
time=表示时间(0=24小时,1=3天内,2=一周内,3=一个月内,默认为0)
当然scrapyd强大之处在于可以用http方式控制爬虫
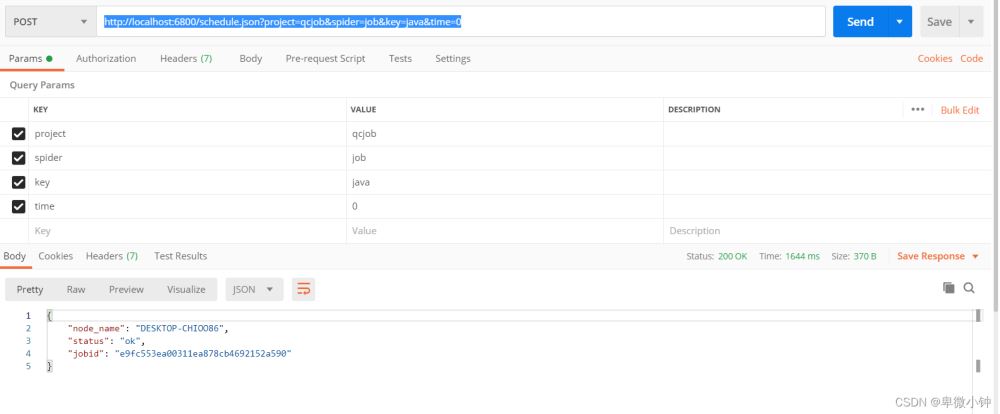
http://localhost:6800/schedule.json?project=qcjob&spider=job&key=java&time=0 #POST
以下是用postmain进行模拟post请求。
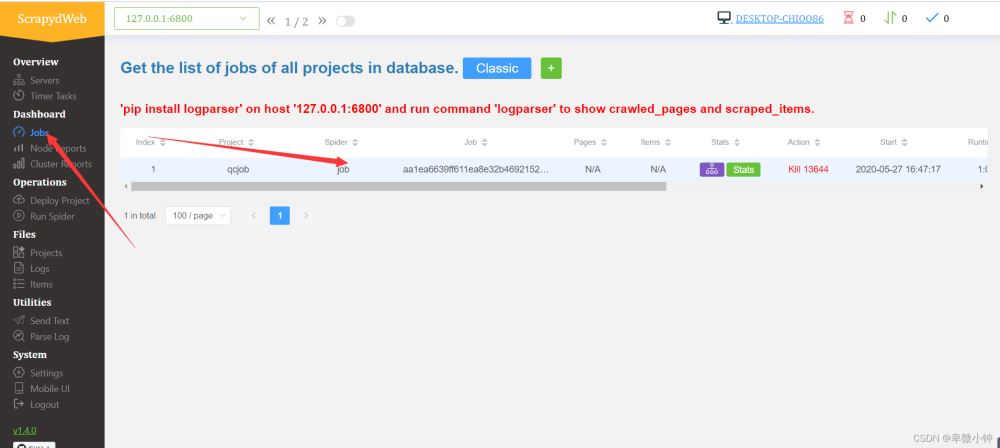
然后进入http://127.0.0.1:6800/
点击job,就可以查看爬虫是否运行,和运行时间

从图可以看出,这个爬虫运行了9分31秒。
当然我们也可以从scrapydweb中查看和管理爬虫浏览器访问:http://127.0.0.1:5000/1/servers/
我们可以通过可视化界面来控制爬虫运行,scrapyd可以启动多个不同的爬虫,一个爬虫的多个版本启动。是目前分布式爬虫的最好解决方法!!!
三、数据展示
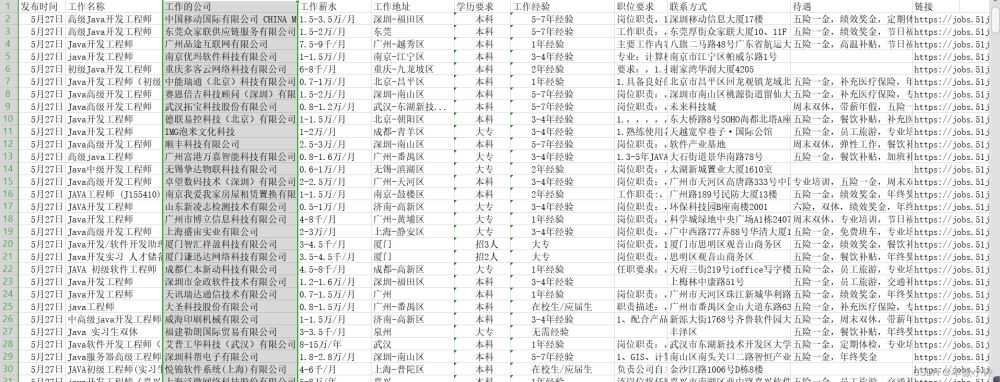
本次爬取花费9分31秒,共爬去25,000余条数据,爬虫速度开至每秒8次访问,以他该服务器的最大访问量
其中部分数据存在有误,为了保证速度,没有进行过多的筛取和排查,错误率保持较低水平

四、问题与思考
- 通过爬去可以看得出,如果采用单一的爬虫的话,爬取速度还是比较慢的,如果采用多个爬虫,分布式爬取的话,就存在数据是否重复以及数据的共用问题。
- 如果采用分布式爬虫的话,就涉及到ip代理,因为一台机器如果大量访问的话经过测试会导致浏览器访问,该网页都无法打开,如果设置IP代理,就需要大量的代理IP
- 虽然爬虫已经部署在服务器上,但是还是无法做到,通过用户输入关键字时间等地址等多个参数进行爬取数据,无法做到实时展示,只能先运行爬虫,爬取大量数据储存与数据库,然后才能进行分析,做出图表。
- 关于数据的统计与展示,单一的sql语句,很难满足其对大量数据的分析,可能需要用Python的数据分析库,对数据进行处理,然后才能展示。
五、收获
已经可以通过http请求的方式来控制爬虫的启动停止,以及传递参数,就等于scrapy爬虫是可以集成于web应用里面的。
到此这篇关于scrapy爬虫部署服务器的方法步骤的文章就介绍到这了,更多相关scrapy爬虫部署服务器内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Scrapy基于scrapy_redis实现分布式爬虫部署的示例
准备工作 1.安装scrapy_redis包,打开cmd工具,执行命令pip install scrapy_redis 2.准备好一个没有BUG,没有报错的爬虫项目 3.准备好redis主服务器还有跟程序相关的mysql数据库 前提mysql数据库要打开允许远程连接,因为mysql安装后root用户默认只允许本地连接,详情请看此文章 部署过程 1.修改爬虫项目的settings文件 在下载的scrapy_redis包中,有一个scheduler.py文件,里面有一个Scheduler类,是用来调
-

scrapy爬虫部署服务器的方法步骤
目录 一.scrapy爬虫部署服务器 1.scrapyd 2.安装 2.scrapy-client 3.scrapydweb(可选) 二.实际操作(一切的操作都在scrapyd启动的情况下) 三.数据展示 四.问题与思考 五.收获 一.scrapy爬虫部署服务器 scrapy通过命令行运行一般只用于测试环境,而用于运用在生产环境则一般都部署在服务器中进行远程操作. scrapy部署服务器有一套完整的开源项目:scrapy+scrapyd(服务端)+scrapy-client(客户端)+scrap
-
从0开始简单部署腾讯云服务器的方法步骤
由于是第一次发帖,如有写得不好,不对的地方希望大家在评论里指出,以后改进.谢谢!!!. 下面开始: 一:购买腾讯云: 首先进入腾讯云的官网:https://cloud.tencent.com/?fromSource=gwzcw.150044.150044.150044 注册后进行认证. 认证完了后选择 产品 - 云服务器 .如下图: 大家可按照自己的需要进行选择.我这里的话选择的是Windows 2008 便于操作. 如果大家只是想着弄来玩两天的话,腾讯有一个新用户15天的服务器体验活动,只需
-
IDEA使用Docker插件远程部署项目到云服务器的方法步骤
1. 打开2375端口 编辑docker.service vim /lib/systemd/system/docker.service 在 ExecStart 后添加配置 -H tcp://0.0.0.0:2375 -H unix://var/run/docker.sock 重启docker网络和docker systemctl daemon-reload systemctl restart-docker Centos7 开放端口 firewall-cmd --zone=public --add
-
Vue项目打包部署到apache服务器的方法步骤
vue项目在开发环境下,让项目运行起来,是通过npm run dev命令,原理是在本地搭建了一个express服务器. 但是在服务器上就不是这样的,必须要通npm run build命令来对整个项目进行打包,打包后会在项目目录下生成一个dist文件夹,内容如下: 然后就是把这些文件丢到服务器上的某个文件夹下,我这里的文件夹名字是ibms 遇到的问题: 1. 直接去访问http://www.xxx.com/ibms/,会发现网页是白屏的,什么都没有,这就比较奇怪了,其实是因为资源加载的路径有问题!
-
Vue-CLI3.x 自动部署项目至服务器的方法步骤
目录 前言 一 安装scp2 二.配置测试/生产环境 服务器SSH远程登陆账号信息 三.使用scp2库,创建自动化部署脚本 四.添加 package.json 中的 scripts 命令, 自定义名称为 "deploy", 结束语 前言 平时部署前端项目流程是:先部署到测试环境ok后再发布到生产环境上,部署到测试环境用 xshell 连上服务器,然后用 xftp 连接服务器,然后本地 build 项目,接着把 build 好的文件通过 xftp 上传到服务器上,整个流程感觉稍有繁琐,重
-
使用TS来编写express服务器的方法步骤
1. 前言 作为前端开发人员而言,ts已经成为了一项必不可少的技能,类型检查可以帮助我们再开发时避免一些不必要的bug,而且ts支持的类和装饰器等语法也更逼近后端语言,更适合服务器的开发. 本文将从零开始,搭建一个集成ts和eslint语法检查的express服务器. 2. 初始化express框架 我们可以使用官方提供的express生成器来快速生成express框架. 当然,express的初始化内容并不复杂,你也可以从一个app.js开始搭建自己喜欢的框架模式. # 使用express生成
-
Go语言利用ssh连接服务器的方法步骤
学习了Go语言后,打算利用最近比较空一点,写一个前端部署工具,不需要每次都复制粘贴的麻烦,需要完成部署的第一步就需要连接远程服务器 打开 ssh server 首先我们想要利用ssh连接服务器的前提是服务器打开了ssh server,ssh 分为client和server端 ,如果打开了client可以连接远程服务器,打开了server就可以被连接. 因为linux网上教程很多,windows比较少,所以这里只写windows版本的, 首先我们一般用Open SSH这个工具打开服务,window
-
Gogs+Jenkins+Docker 自动化部署.NetCore的方法步骤
环境说明 腾讯云轻量服务器, 配置 1c 2g 6mb ,系统是 ubuntu 20.14,Docker 和 Jenkins 都在这台服务器上面, 群晖218+一台,Gogs 在这台服务器上. Docker安装 卸载旧的 Docker sudo apt-get remove docker docker-engine docker.io containerd runc 更新 apt 包索引并安装包以允许 apt 通过 HTTPS 使用存储库 sudo apt-get update sudo apt
-
利用nginx搭建静态资源服务器的方法步骤
以windows为例,linux其实一样: 搭建静态资源服务器 我电脑上的work文件夹下面有很多图片,我想通过nginx搭建静态资源服务器,通过在地址栏输入ip+port的方式完成目录的映射 找到nginx安装目录,打开/conf/nginx.conf配置文件,添加一个虚拟主机 添加监听端口.访问域名 重点是添加location, 映射-URL:/work/; 注意:如果当前server模块中已有一个location且URL为"/",那么新建的location的url应为匹配路径,不
-
docker部署zabbix_agent的方法步骤
zabbix_agent部署: 建议:zabbix_agent使用docker-compose方式单独部署 启动方式: 1.run方式启动 docker run --rm --network zabbix --name zabbix_agent--link zabbix_server:zabbix-server -e ZBX_HOSTNAME="mythird" -e ZBX_SERVER_PORT="10051" -e ZBX_SERVER_HOST="