MySQL索引优化之适合构建索引的几种情况详解
目录
- 结论
- 建立索引的场景
- 小结
结论
- 在where后面的过滤字段上建立索引(select/update/delete后面的where都是适用的),使用索引加快过滤效率,不用进行全表扫描
- 在具有唯一要求的字段上添加唯一索引,加快查询效率,查到即可直接返回
- group by或者order by后面的字段添加索引,由于索引是排好序的,所以建立索引就等同于在查询之前已经是排好序了(这里需要注意建立的联合索引建立中字段的顺序,可以结合具体案例场景7进行学习)
- 在DISTINCT(去重字段)后面的字段添加索引,由于建立了索引,那么相同的数据就是挨在一起的,所以就可以进行快速的去重操作,否则可能就需要将相同的数据找出来在进行去重操作
- 在多表连接join的时候在连接的字段上建立索引(小表驱动大表)
- 取字符串一定前缀建立索引(不是用整个字符串作为索引,否则将会占用太大的空间)
- 在频繁使用的列上建立索引(可以建立联合索引,同时最频繁使用的字段应该在联合索引的最左侧,最左侧原则)
- 在区分度高的列上建立索引(主键的区分度最高,因为所有的键都是唯一的)
建立索引的场景
场景一:在where字段后面的字段建立索引
-- 描述:当where中有多个条件需要进行匹配的时候,那么可以创建联合索引,这样所有的条件都可以使用索引,大大提高了检索的效率 select * from student_info where student_id = 1; -- 当然数据量比较大的时候给where后面的字段添加索引 create index student_id_index on student_info (student_id)
未添加索引前,耗费0.383秒,基本遍历整个表

添加索引后,耗费0.001秒,使用了索引(但是创建索引的时候会耗费一定时间)

在频繁的查询的业务中可以对where筛选的字段建立索引,如果where筛选的字段有多个还可以建立联合索引
场景二:在具有唯一性约束的字段上建立唯一索引(查找到目标即可返回不用继续查找)
select * from student_info where id = 1001; -- 因为学号是唯一的,所以可以在学号这个字段上添加唯一所用 create index id_unique on student_info(id);
具有唯一性约束的字段上就可以建立唯一索引,虽然建立了唯一索引对insert操作有一定的影响(需要判断新增的数据是否已经在表中),但是建立唯一索引对于查询的效率是显著提升的,例如上面的例子,因为建立了唯一索引,一旦查找到id为1001的学生信息之后就不需要判断数据库中是否还有id等于1001的学生(只有唯一一份),直接返回信息即可,如果没有建立索引,那么就需要全表扫描
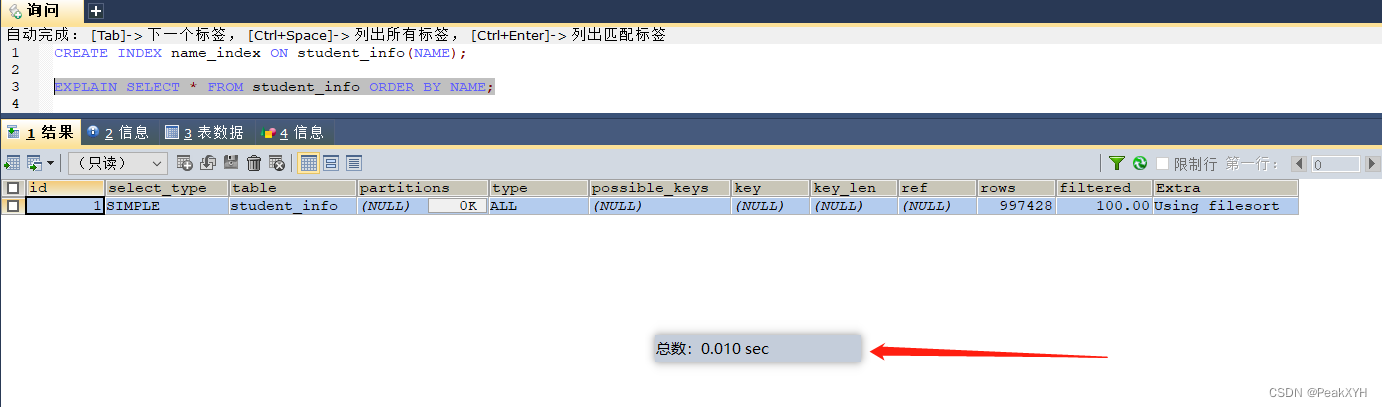
场景三:经常group by和order by的字段上建立索引(因为索引本身就是排好序的,相当于查询之前就已经进行了排序)
select * from student_info order by name; -- 这里就可以给name字段进行索引的添加 select * from student_info group by class_id; -- 这里就可以给class_id字段添加索引
建立索引前,耗时0.501秒,使用的是所有数据在内存中排序

建立索引后,耗时0.01秒
场景四:在DISTINCT后面的字段添加索引(索引已经将相同的字段排好序,去重效率更高)
select distinct(student_id) from student_info; -- 这里就可以根据student_id字段建立索引 create index student_id_index on student_info;
建立了索引,那么默认就是按照索引字段的升序排列的,那么相同值的字段也就排列在一起了,那么去重也就变得简单、高效
场景五:在join多表连接大表中的连接字段建立索引
SELECT s.course_id,NAME,s.student_id,c.course_name FROM student_info s JOIN course c ON s.`course_id` = c.`course_id` WHERE NAME = 'xiaoyuanhao'; -- 根据大表驱动小表的原则需要在student_info表的course_id字段上建立索引
没有建立索引之前,耗时0.697s,没有使索引

建立索引后,使用了索引,耗时0.003s

小表驱动大表:
通过对小表进行逐一遍历,同时在大表中的连接字段建立索引即可加快查询,本案例中,每次取出课程表中course_id和学生表中学生的course_id进行连接操作,在学生表中对course_id建立索引即可
场景六:使用字符串的前缀建立索引
create table shop(address varchar(120) not null); alter table shop add index(address(12)); --这里只是对表中的address的前12个字符建立了索引,而不是整个字符串建立索引
前缀建立索引的原因:
- 由于有些字符串很长,如果为整个字符串建立索引,那么索引将占用很大的空间
- 由于需要存储整个字符串,那么数据项就会很大,那么索引树的深度就会加深,检索速度下降
- 虽然可能出现在索引中两个字符串相同,但是再根据主键进行回表操作效率依然比较高
如何确定前缀索引中前缀的长度呢?(也就是如果前缀的长度太短,那么索引的区分度就很低,从多个字符串截取的前缀数据可能都是一样的,但是如果前缀索引的前缀过长,那么前缀索引的优点就消失了)
引入了区别度的概念,select count(distinct left(索引字段,前缀索引长度) / count(*) from xxx),该值越接近1,那么区分度就越明显,那么该索引长度就是所求的前缀索引长度
场景七:在频繁使用的列上建立索引或联合索引(频繁使用的字段应该在索引的左侧)
select * from xiaoyuanhao where age = 18; select * from xiaoyuanhao where age = 19 and sex = 'man'; select * from xiaoyuanhao where age = 10 and sex = 'man' and password = '123456'; -- 在这里实际上就可以建立age,sex,password的联合索引,只需要建立一个索引,这三个查询都是可以使用的 create index age_sex_password_index on xiaoyuanhao(age,sex,password); select * from student_info group by class_id order by name; -- 在这里可以建立class_id和name的联合索引,但是一定要注意索引的顺序,一定是要class_id在前,name在后,因为在select语句中执行的顺序是先group by 之后才是 order by 索引如果索引的字段顺序是相反的,那么就无法使用索引 create index class_id_name_index on student(class_id,name);
索引建立需要符合顺序的原因:
索引字段的顺序如果是错误的,那么索引就会失效,因为索引实际上是排好序的,如果索引建立的时候是现根据name排好序之后在根据class_id进行排序,那么在面对需要先根据class_id排序再根据name排序的业务就无法进行使用
补充:
在select * from xxx where age = 19 and sex = ‘man’ and password = '123456’这里索引建立的顺序不一定是(age,sex,password)因为在实际执行的过程中,优化器会优化执行步骤会按照索引的顺序进行查询,但是group by 和 order by的执行顺序是无法改变的,索引必须严格的按照顺序建立索引,否则索引失效
小结
- 以上是适合建立索引的几种情况,但是实际上是否会使用索引,还是由优化起决定的,优化器会根据具体的查询以及数据量进行分析决定的
- 当建立了索引但是却没有使用的时候有可能是数据索引失效或者经过优化器分析没有必要使用索引
- 建立了索引也是存在失效的可能,下面的文章关于索引失效的案例,可以一起学习讨论:索引优化:MySQL索引优化之不适合构建索引及索引失效的几种情况详解
到此这篇关于MySQL索引优化之适合构建索引的几种情况详解的文章就介绍到这了,更多相关MySQL索引优化内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

MySQL细数发生索引失效的情况
目录 索引的存储结构 不合理的模糊查询条件 对索引使用函数 对索引进行表达式计算 对索引使用隐式转换 联合索引非最左匹配 where子句中的or 总结 索引的存储结构 首先了解一下索引的存储结构,知道了索引的存储结构,才方便我们更好地理解索引失效的问题. 索引的存储结构跟MySQL的存储引擎有关,存储引擎的不同采用的结构也会不同. MySQL默认的存储引擎InnoDB采用B+Tree作为索引的数据结构,在创建表时,InnoDB会默认创建一个主键索引,这是一个聚簇索引,其他索引都属于二级索引. M
-
MySQL索引失效场景及解决方案
目录 一.前言 二.最左前缀匹配原则 三.MySQL逻辑架构和优化器 四.索引失效场景以及为何会失效 五.总结 一.前言 在对SQL语句进行索引查询时会遇到索引失效的时候,对于该语句的可行性以及性能效率方面有至关重要的影响,本篇剖析索引为何失效,有哪些情况会导致索引失效以及对于索引失效时的优化解决方案,其中着重介绍最左前缀匹配原则.MySQL逻辑架构和优化器.索引失效场景以及为何会失效. 二.最左前缀匹配原则 之前有写了一篇关于MySQL添加索引特点及优化问题方面的文章,下面将介绍索引失效的相关
-
MySQL添加索引特点及优化问题
目录 一.索引的特点 二.索引类型 1.FULLTEXT 2.HASH 3.BTREE 4.RTREE 三.索引种类 四.索引的使用策略 1.什么时候要使用索引? 2.什么时候不要使用索引? 3.索引失效的情况? 4.mysql查询优化? 5.索引的常见问题 一.索引的特点 当MySQL单表记录数过大时,增删改查性能都会急剧下降.MySQL索引的建立对于MySQL的高效运行是很重要的,索引可以大大提高MySQL的检索速度.除非单表数据未来会一直不断上涨,否则不要一开始就考虑拆分,拆分会带来逻辑.
-
mysql 索引使用及优化详情
目录 前言 mysql索引原理 mysql索引分类 索引创建语法 1.创建索引 2.查看索引 3.删除索引 4.为 username和password创建联合索引 5.给user表添加一个info的字段,并为这个字段添加全文索引 已经存在的表创建.删除索引等 1.使用ALTER TABLE语句创建索引 2.使用ALTER TABLE语句删除索引 常用的索引设计原则 索引失效情况总结 尽量使用覆盖索引 前言 索引对有一定开发经验的同学来说并不陌生,合理使用索引,能大大提升sql查询的性能,可以这么
-
MySQL 回表,覆盖索引,索引下推
目录 回表 覆盖索引 索引下推 无索引下推: 查看索引下推的状态 有索引下推: 开启索引下推 回表 在研究mysql二级索引的时候,发现Mysql回表这个操作,往下研究了一下 字面意思,找到索引,回到表中找数据 解释一下就是: 先通过索引扫描出数据所在的行,再通过行主键ID 取出数据. 举个例子说明: SELECT * FROM INNODB_USER WHERE AGE = 18 AND USER_NAME LIKE '模糊查%'; 假如age和user_name两个字段是个联合索引,我们通过
-
哪些情况会导致 MySQL 索引失效
目录 前言 创建测试表和数据 索引失效情况1:非最左匹配 索引失效情况2:错误模糊查询 索引失效情况3:列运算 索引失效情况4:使用函数 索引失效情况5:类型转换 索引失效情况6:使用 is not null 总结 前言 为了验证 MySQL 中哪些情况下会导致索引失效,我们可以借助 explain 执行计划来分析索引失效的具体场景. explain 使用如下,只需要在查询的 SQL 前面添加上 explain 关键字即可,如下图所示: 而以上查询结果的列中,我们最主要观察 key 这一列,ke
-
MySQL索引优化之不适合构建索引及索引失效的几种情况详解
目录 结论 不建议建立索引的场景 索引失效的场景 小结 结论 具体案例下文有详尽描述 不适合建立索引的场景: 数据量比较小的表不建议建立索引 有大量重复数据的字段上不建议建立索引(类似:性别字段) 需要进行频繁更新的表不建议建立索引 where.group by.order by后面的没有使用到的字段不建立索引 不要定义冗余索引 索引失效的场景: 过滤条件使用不等于(!=.<>) 过滤条件使用is not null 在索引字段上使用函数或进行计算 在使用联合索引的时候,需要满足“最佳左前缀法则
-
Mysql索引分类及其使用实例详解
目录 Mysql的索引分类 单列索引 创建单列索引的几种方式: 唯一索引 创建唯一索引的几种方式: 联合索引(复合索引) 创建联合索引(复合索引)的方式: Mysql的索引类型 INDEX | NORMAL 普通索引 UNIQUE 唯一索引 PRIMARY KEY 主键索引 FULLTEXT 全文索引 SPATIAL 空间索引 Mysql的索引方法 BTREE HASH Mysql的索引使用示例 单列索引使用示例 复合索引使用示例 Mysql的索引分类 MySQL 索引MySQL索引的建立对于M
-
MySql索引和事务定义到使用全面涵盖
目录 索引是什么 索引的使用场景 索引的常见操作 索引背后的数据结构 事务是什么 事务的基本特性 小结 索引是什么 索引是一种特殊的文件,包含着对数据表里所有记录的引用指针.可以对表中的一列或多列创建索引,并指定索引的类型,各类索引有各自的数据结构实现.索引就相当于一本书的目录,通过索引 可快速定位.检索数据.使用索引大大提高了查找效率,但同时索引也占用了更多的空间,拖慢了增删改的速度. 索引的使用场景 1.数据量较大,且经常对这些列进行条件查询. 2.该数据库表的插入操作,及对这些列的修改操作
-
MySQL索引优化之适合构建索引的几种情况详解
目录 结论 建立索引的场景 小结 结论 在where后面的过滤字段上建立索引(select/update/delete后面的where都是适用的),使用索引加快过滤效率,不用进行全表扫描 在具有唯一要求的字段上添加唯一索引,加快查询效率,查到即可直接返回 group by或者order by后面的字段添加索引,由于索引是排好序的,所以建立索引就等同于在查询之前已经是排好序了(这里需要注意建立的联合索引建立中字段的顺序,可以结合具体案例场景7进行学习) 在DISTINCT(去重字段)后面的字段添加
-
MySQL设置global变量和session变量的两种方法详解
1.在MySQL中要修改全局(global)变量,有两种方法: 方法一,修改my.ini配置文件,如果要设置全局变量最简单的方式是在my.ini文件中直接写入变量配置,如下图所示.重启数据库服务就可以使全局变量生效. 我们打开几个mysql命令行,可以看到所有会话中的变量都生效了,如图 方法二,在不修改配置文件的基础上,使用关键字global设置全局变量 set global autocommit=1; 将autocommit变量的值设置为ON 需要注意的是,使用此方法对global全局变量的设
-
SQL索引失效的11种情况详析
目录 索引失效案例 [1]. 全值匹配 [2]. 最佳左前缀法则 [3]. 主键插入顺序 [4]. 计算.函数.类型转换(自动或手动)导致索引失效 [5]. 类型转换导致索引失效 [6]. 范围条件右边的列索引失效 [7]. 不等于(!= 或者<>)索引失效 [8]. is null可以使用索引,is not null无法使用索引 [9]. like以通配符%开头索引失效 [10]. OR 前后存在非索引的列,索引失效 [11]. 数据库和表的字符集统一使用utf8mb4 总结 数据库调优的大
-
Mysql效率优化定位较低sql的两种方式
关于mysql效率优化一般通过以下两种方式定位执行效率较低的sql语句. 通过慢查询日志定位那些执行效率较低的 SQL 语句,用 --log-slow-queries[=file_name] 选项启动时, mysqld 会 写一个包含所有执行时间超过 long_query_time 秒的 SQL 语句的日志文件,通过查看这个日志文件定位效率较低的 SQL . 慢查询日志在查询结束以后才纪录,所以在应用反映执行效率出现问题的时候查询慢查询日志并不能定位问题,可以使用 show processlis
-
MySQL null与not null和null与空值''''的区别详解
相信很多用了MySQL很久的人,对这两个字段属性的概念还不是很清楚,一般会有以下疑问: 我字段类型是not null,为什么我可以插入空值 为毛not null的效率比null高 判断字段不为空的时候,到底要 select * from table where column <> '' 还是要用 select * from table wherecolumn is not null 呢. 带着上面几个疑问,我们来深入研究一下null 和 not null 到底有什么不一样. 首先,我们要搞清楚
-
MySql分表、分库、分片和分区知识深入详解
一.前言 数据库的数据量达到一定程度之后,为避免带来系统性能上的瓶颈.需要进行数据的处理,采用的手段是分区.分片.分库.分表. 二.分片(类似分库) 分片是把数据库横向扩展(Scale Out)到多个物理节点上的一种有效的方式,其主要目的是为突破单节点数据库服务器的 I/O 能力限制,解决数据库扩展性问题.Shard这个词的意思是"碎片".如果将一个数据库当作一块大玻璃,将这块玻璃打碎,那么每一小块都称为数据库的碎片(DatabaseShard).将整个数据库打碎的过程就叫做分片,可以
-
docker在win10家庭版下构建laravel开发环境的教程详解
操作系统: win10 家庭版 安装docker: 官网下载的docker无法安装成功,提示操作系统版本问题~~~~ 所以直接下载了阿里提供的docker安装包: http://mirrors.aliyun.com/doc ... 社区版是-ce后缀的 阿里镜像加速 首先登录阿里云 查找容器镜像服务 win10找到C:Users用户.dockermachinemachinesdefault底下有个config.json文件,在属性RegistryMirror添加加速器地址,docker虚拟机重启
-
mysql查找删除重复数据并只保留一条实例详解
有这样一张表,表数据及结果如下: school_id school_name total_student test_takers 1239 Abraham Lincoln High School 55 50 1240 Abraham Lincoln High School 70 35 1241 Acalanes High School 120 89 1242 Academy Of The Canyons 30 30 1243 Agoura High School 89 40 1244 Agour
-
mysql 5.7 zip 文件在 windows下的安装教程详解
1.下载mysql最新版本. http://cdn.mysql.com//Downloads/MySQL-5.7/mysql-5.7.15-winx64.zip 2.解压到文件夹. D:\software\mysql\mysql5.7a 将my-default.ini 复制为 my.ini 3.编辑my.ini # These are commonly set, remove the # and set as required. basedir ="D:/software/mysql/mysql