从Hello World开始理解GraphQL背后处理及执行过程
目录
- 前言
- Hello World
- SchemaParser
- Parser#parseDocument
- RuntimeWiring
- RuntimeWiring.Builder#type
- GraphQL
- build
- execute
- Execution#execute
- AsynExecutionStrategy#execute
- ExecutionStrategy#resolveFieldWithInfo
- 总体执行过程
前言
在上篇文章《初识GraphQL》中我们大致的了解了GraphQL作用,并通过简单示例初步体验了GraphQL的使用。下面我们从Hello World开始来进一步了解GraphQL背后的处理。
Hello World
package com.graphqljava.tutorial.bookdetails;
import graphql.ExecutionResult;
import graphql.GraphQL;
import graphql.schema.GraphQLSchema;
import graphql.schema.StaticDataFetcher;
import graphql.schema.idl.RuntimeWiring;
import graphql.schema.idl.SchemaGenerator;
import graphql.schema.idl.SchemaParser;
import graphql.schema.idl.TypeDefinitionRegistry;
public class HelloWorld {
public static void main(String[] args) {
// 从最简单的schema字符串开始,省去对graphqls文件的读取
String schema = "type Query{hello: String}";
// 用于获得graphql schema定义,并解析放入TypeDefinitionRegistry中,以便放置在SchemaGenerator中使用
SchemaParser schemaParser = new SchemaParser();
// 解析schema定义字符串,并创建包含一组类型定义的TypeDefinitionRegistry
TypeDefinitionRegistry typeDefinitionRegistry = schemaParser.parse(schema);
// runtime wiring 是data fetchers、type resolves和定制标量的规范,这些都需要连接到GraphQLSchema中
RuntimeWiring runtimeWiring = RuntimeWiring.newRuntimeWiring()
// 添加一个类型连接
.type("Query", builder -> builder.dataFetcher("hello", new StaticDataFetcher("world")))
.build();
//schemaGenerator对象可以使用typeDefinitionRegistry、runtimeWiring生成工作运行时schema
SchemaGenerator schemaGenerator = new SchemaGenerator();
//graphQLSchema代表graphql引擎的组合类型系统。
GraphQLSchema graphQLSchema = schemaGenerator.makeExecutableSchema(typeDefinitionRegistry, runtimeWiring);
//构建GraphQL用于执行查询
GraphQL build = GraphQL.newGraphQL(graphQLSchema).build();
//执行并获得结果
ExecutionResult executionResult = build.execute("{hello}");
System.out.println(executionResult.getData().toString());
}
}
从上面的代码注释可以看到GraphQL大致执行的过程:
- 根据给定的schema内容使用SchemaParser进行解析获得schema定义TypeDefinitionRegistry。
- 拿到了schema定义之后还需要定义RuntimeWiring用于定义不同类型的type resolves和对应的数据提取器data fetchers。
- 使用GraphQLSchema把TypeDefinitionRegistry和RuntimeWiring组合在一起便于以后的使用。
- 使用GraphQLSchema构建出GraphQL用于后面的QL执行。
- 传入QL使用GraphQL执行并获得结果ExecutionResult。
从外层使用代码可以得出核心处理类为:SchemaParser、TypeDefinitionRegistry、RuntimeWiring、GraphQLSchema、GraphQL。
下面我们分配看看核心类是怎么处理的。
SchemaParser
解析schema字符串定义并生成TypeDefinitionRegistry。
public TypeDefinitionRegistry parse(String schemaInput) throws SchemaProblem {
try {
Parser parser = new Parser();
Document document = parser.parseDocument(schemaInput);
return buildRegistry(document);
} catch (ParseCancellationException e) {
throw handleParseException(e);
}
}
使用Document构建TypeDefinitionRegistry
public TypeDefinitionRegistry buildRegistry(Document document) {
List<GraphQLError> errors = new ArrayList<>();
TypeDefinitionRegistry typeRegistry = new TypeDefinitionRegistry();
List<Definition> definitions = document.getDefinitions();
for (Definition definition : definitions) {
if (definition instanceof SDLDefinition) {
typeRegistry.add((SDLDefinition) definition).ifPresent(errors::add);
}
}
if (errors.size() > 0) {
throw new SchemaProblem(errors);
} else {
return typeRegistry;
}
}
可以看的出来TypeDefinitionRegistry只是对Document的定义提取,重点还是在于Document的生成,我们可以先通过debugger来先看看Document的大致内容。
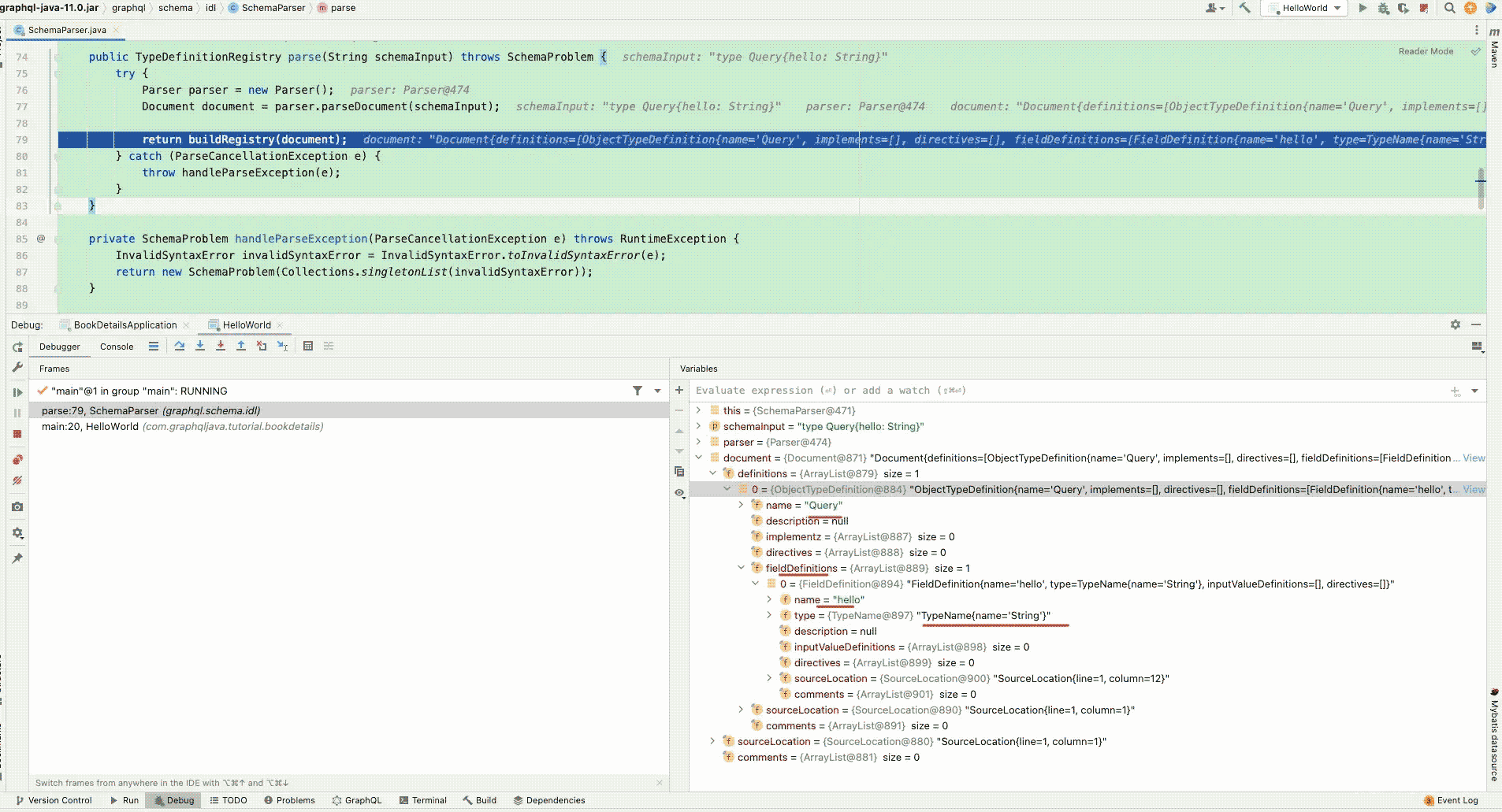
可以看到就是把schema字符串解析成了方便后续使用的Document对象,我们还是详细看看这个对象里面的属性和大概的生成过程。
Parser#parseDocument
public Document parseDocument(String input, String sourceName) {
CharStream charStream;
if(sourceName == null) {
charStream = CharStreams.fromString(input);
} else{
charStream = CharStreams.fromString(input, sourceName);
}
GraphqlLexer lexer = new GraphqlLexer(charStream);
CommonTokenStream tokens = new CommonTokenStream(lexer);
GraphqlParser parser = new GraphqlParser(tokens);
parser.removeErrorListeners();
parser.getInterpreter().setPredictionMode(PredictionMode.SLL);
parser.setErrorHandler(new BailErrorStrategy());
//词法分析从schema中解析出tokens(每个关键字、最后一个为EOF),documentContext包含children、start/stop字符等相当于结构。
GraphqlParser.DocumentContext documentContext = parser.document();
GraphqlAntlrToLanguage antlrToLanguage = new GraphqlAntlrToLanguage(tokens);
// 生成document
Document doc = antlrToLanguage.createDocument(documentContext);
Token stop = documentContext.getStop();
List<Token> allTokens = tokens.getTokens();
if (stop != null && allTokens != null && !allTokens.isEmpty()) {
Token last = allTokens.get(allTokens.size() - 1);
//
// do we have more tokens in the stream than we consumed in the parse?
// if yes then its invalid. We make sure its the same channel
boolean notEOF = last.getType() != Token.EOF;
boolean lastGreaterThanDocument = last.getTokenIndex() > stop.getTokenIndex();
boolean sameChannel = last.getChannel() == stop.getChannel();
if (notEOF && lastGreaterThanDocument && sameChannel) {
throw new ParseCancellationException("There are more tokens in the query that have not been consumed");
}
}
return doc;
}
tokens&documentContext

可以看到,主要是通过提取schema的关键字、识别结构最后生成Document主要内容为类型定义定义和类型定义中的字段定义。
RuntimeWiring
runtime wiring 是data fetchers、type resolves和定制标量的规范,这些都需要连接到GraphQLSchema中。
RuntimeWiring.Builder#type
这种形式允许使用lambda作为type wiring的构建器。
public Builder type(String typeName, UnaryOperator<TypeRuntimeWiring.Builder> builderFunction) {
TypeRuntimeWiring.Builder builder = builderFunction.apply(TypeRuntimeWiring.newTypeWiring(typeName));
return type(builder.build());
}
添加type wiring。
public Builder type(TypeRuntimeWiring typeRuntimeWiring) {
String typeName = typeRuntimeWiring.getTypeName();
Map<String, DataFetcher> typeDataFetchers = dataFetchers.computeIfAbsent(typeName, k -> new LinkedHashMap<>());
typeRuntimeWiring.getFieldDataFetchers().forEach(typeDataFetchers::put);
defaultDataFetchers.put(typeName, typeRuntimeWiring.getDefaultDataFetcher());
TypeResolver typeResolver = typeRuntimeWiring.getTypeResolver();
if (typeResolver != null) {
this.typeResolvers.put(typeName, typeResolver);
}
EnumValuesProvider enumValuesProvider = typeRuntimeWiring.getEnumValuesProvider();
if (enumValuesProvider != null) {
this.enumValuesProviders.put(typeName, enumValuesProvider);
}
return this;
}
可以看到主要就是网RuntimeWiring里面添加了dataFetchers、defaultDataFetchers、typeResolvers、enumValuesProviders。下面分别介绍下各属性的含义:
- DataFetcher:负责返回给定graphql字段数据值。graphql引擎使用datafetcher将逻辑字段解析/获取到运行时对象,该对象将作为整个graphql grapql.ExecutionResult的一部分发送回来。

GraphQLScalarType:scalar type是graphql树类型的叶节点。该类型允许你定义新的scalar type。
- TypeResolver:这在类型解析期间被调用,以确定在运行时GraphQLInterfaceTypes和GraphQLUnionTypes应该动态使用哪些具体的GraphQLObjectType。
- GraphQLInterfaceTypes:在graphql中,接口是一种抽象类型,它定义了一组字段,类型必须包含这些字段才能实现该接口。在运行时,TypeResolver用于获取一个接口对象值,并决定哪个GraphQLObjectType表示此接口类型。关于这个概念的更多细节,请参见graphql.org/learn/schem…
- GraphQLUnionTypes:联合类型,相当于组合。
- GraphQLObjectType:这是工作马类型,表示一个对象,它具有一个或多个字段值,这些字段可以根据对象类型等进行自身的处理,直到到达由GraphQLScalarTypes表示的类型树的叶节点。关于这个概念的更多细节,请参见graphql.org/learn/schem…
- SchemaDirectiveWiring:SchemaDirectiveWiring负责基于schema定义语言(SDL)中放置在该元素上的指令增强运行时元素。它可以增强graphql运行时元素并添加新的行为,例如通过更改字段graphql.schema. datafetcher。
- WiringFactory:WiringFactory允许您基于IDL定义更动态的连接TypeResolvers和DataFetchers。
- EnumValuesProvider:为每个graphql Enum值提供Java运行时值。用于IDL驱动的schema创建。Enum值被认为是静态的:在创建schema时调用。在执行查询时不使用。
- GraphqlFieldVisibility:这允许您控制graphql字段的可见性。默认情况下,graphql-java使每个定义的字段可见,但您可以实现此接口的实例并减少特定字段的可见性。
GraphQL
build
例子中通过传入GraphQLSchema构建GraphQL。
public GraphQL build() {
assertNotNull(graphQLSchema, "graphQLSchema must be non null");
assertNotNull(queryExecutionStrategy, "queryStrategy must be non null");
assertNotNull(idProvider, "idProvider must be non null");
return new GraphQL(graphQLSchema, queryExecutionStrategy, mutationExecutionStrategy, subscriptionExecutionStrategy, idProvider, instrumentation, preparsedDocumentProvider);
}
除了graphQLSchema都是默认值,我们大概看看各个成员分别是用来干嘛的:
- queryExecutionStrategy:异步非阻塞地运行字段的标准graphql执行策略。
- mutationExecutionStrategy:异步非阻塞执行,但串行:当时只有一个字段将被解析。关于每个字段的非串行(并行)执行,请参阅AsyncExecutionStrategy。
- subscriptionExecutionStrategy:通过使用reactive-streams作为订阅查询的输出结果来实现graphql订阅。
- idProvider:executionid的提供者
- instrumentation:提供了检测GraphQL查询执行步骤的功能。
- preparsedDocumentProvider:客户端连接文档缓存和/或查询白名单的接口。
execute
下面我们还是来看看具体的执行:
public ExecutionResult execute(ExecutionInput executionInput) {
try {
return executeAsync(executionInput).join();
} catch (CompletionException e) {
if (e.getCause() instanceof RuntimeException) {
throw (RuntimeException) e.getCause();
} else {
throw e;
}
}
}
用提供的输入对象执行graphql query。这将返回一个承诺(又名CompletableFuture),以提供一个ExecutionResult,这是执行所提供查询的结果。
public CompletableFuture<ExecutionResult> executeAsync(ExecutionInput executionInput) {
try {
log.debug("Executing request. operation name: '{}'. query: '{}'. variables '{}'", executionInput.getOperationName(), executionInput.getQuery(), executionInput.getVariables());
// 创建InstrumentationState对象,这是一个跟踪Instrumentation全生命周期的对象
InstrumentationState instrumentationState = instrumentation.createState(new InstrumentationCreateStateParameters(this.graphQLSchema, executionInput));
InstrumentationExecutionParameters inputInstrumentationParameters = new InstrumentationExecutionParameters(executionInput, this.graphQLSchema, instrumentationState);
// 检测输入对象
executionInput = instrumentation.instrumentExecutionInput(executionInput, inputInstrumentationParameters);
InstrumentationExecutionParameters instrumentationParameters = new InstrumentationExecutionParameters(executionInput, this.graphQLSchema, instrumentationState);
// 在执行检测 chain前调用
InstrumentationContext<ExecutionResult> executionInstrumentation = instrumentation.beginExecution(instrumentationParameters);
// 检测GraphQLSchema
GraphQLSchema graphQLSchema = instrumentation.instrumentSchema(this.graphQLSchema, instrumentationParameters);
// 对客户端传递的query进行验证并执行
CompletableFuture<ExecutionResult> executionResult = parseValidateAndExecute(executionInput, graphQLSchema, instrumentationState);
//
// finish up instrumentation
executionResult = executionResult.whenComplete(executionInstrumentation::onCompleted);
//
// allow instrumentation to tweak the result
executionResult = executionResult.thenCompose(result -> instrumentation.instrumentExecutionResult(result, instrumentationParameters));
return executionResult;
} catch (AbortExecutionException abortException) {
return CompletableFuture.completedFuture(abortException.toExecutionResult());
}
}
parseValidateAndExecute(executionInput, graphQLSchema, instrumentationState)进行验证并执行,验证我们就不看了直接看执行:
private CompletableFuture<ExecutionResult> execute(ExecutionInput executionInput, Document document, GraphQLSchema graphQLSchema, InstrumentationState instrumentationState) {
String query = executionInput.getQuery();
String operationName = executionInput.getOperationName();
Object context = executionInput.getContext();
Execution execution = new Execution(queryStrategy, mutationStrategy, subscriptionStrategy, instrumentation);
ExecutionId executionId = idProvider.provide(query, operationName, context);
log.debug("Executing '{}'. operation name: '{}'. query: '{}'. variables '{}'", executionId, executionInput.getOperationName(), executionInput.getQuery(), executionInput.getVariables());
CompletableFuture<ExecutionResult> future = execution.execute(document, graphQLSchema, executionId, executionInput, instrumentationState);
future = future.whenComplete((result, throwable) -> {
if (throwable != null) {
log.error(String.format("Execution '%s' threw exception when executing : query : '%s'. variables '%s'", executionId, executionInput.getQuery(), executionInput.getVariables()), throwable);
} else {
int errorCount = result.getErrors().size();
if (errorCount > 0) {
log.debug("Execution '{}' completed with '{}' errors", executionId, errorCount);
} else {
log.debug("Execution '{}' completed with zero errors", executionId);
}
}
});
return future;
}
这里打印日志为
Executing '9c81e267-c55a-4ebd-9f9c-3a2270b28103'. operation name: 'null'. query: '{hello}'. variables '{}'
还要继续往下看:
Execution#execute
public CompletableFuture<ExecutionResult> execute(Document document, GraphQLSchema graphQLSchema, ExecutionId executionId, ExecutionInput executionInput, InstrumentationState instrumentationState) {
// 获得要执行的操作
NodeUtil.GetOperationResult getOperationResult = NodeUtil.getOperation(document, executionInput.getOperationName());
Map<String, FragmentDefinition> fragmentsByName = getOperationResult.fragmentsByName;
OperationDefinition operationDefinition = getOperationResult.operationDefinition;
ValuesResolver valuesResolver = new ValuesResolver();
// 获得输入的参数
Map<String, Object> inputVariables = executionInput.getVariables();
List<VariableDefinition> variableDefinitions = operationDefinition.getVariableDefinitions();
Map<String, Object> coercedVariables;
try {
coercedVariables = valuesResolver.coerceArgumentValues(graphQLSchema, variableDefinitions, inputVariables);
} catch (RuntimeException rte) {
if (rte instanceof GraphQLError) {
return completedFuture(new ExecutionResultImpl((GraphQLError) rte));
}
throw rte;
}
ExecutionContext executionContext = newExecutionContextBuilder()
.instrumentation(instrumentation)
.instrumentationState(instrumentationState)
.executionId(executionId)
.graphQLSchema(graphQLSchema)
.queryStrategy(queryStrategy)
.mutationStrategy(mutationStrategy)
.subscriptionStrategy(subscriptionStrategy)
.context(executionInput.getContext())
.root(executionInput.getRoot())
.fragmentsByName(fragmentsByName)
.variables(coercedVariables)
.document(document)
.operationDefinition(operationDefinition)
// 放入dataloder
.dataLoaderRegistry(executionInput.getDataLoaderRegistry())
.build();
InstrumentationExecutionParameters parameters = new InstrumentationExecutionParameters(
executionInput, graphQLSchema, instrumentationState
);
// 获得执行上下文
executionContext = instrumentation.instrumentExecutionContext(executionContext, parameters);
return executeOperation(executionContext, parameters, executionInput.getRoot(), executionContext.getOperationDefinition());
}
获得了执行上下文并执行,下面继续看executeOperation:
private CompletableFuture<ExecutionResult> executeOperation(ExecutionContext executionContext, InstrumentationExecutionParameters instrumentationExecutionParameters, Object root, OperationDefinition operationDefinition) {
// ...
ExecutionStrategyParameters parameters = newParameters()
.executionStepInfo(executionStepInfo)
.source(root)
.fields(fields)
.nonNullFieldValidator(nonNullableFieldValidator)
.path(path)
.build();
CompletableFuture<ExecutionResult> result;
try {
ExecutionStrategy executionStrategy;
if (operation == OperationDefinition.Operation.MUTATION) {
executionStrategy = mutationStrategy;
} else if (operation == SUBSCRIPTION) {
executionStrategy = subscriptionStrategy;
} else {
executionStrategy = queryStrategy;
}
log.debug("Executing '{}' query operation: '{}' using '{}' execution strategy", executionContext.getExecutionId(), operation, executionStrategy.getClass().getName());
result = executionStrategy.execute(executionContext, parameters);
} catch (NonNullableFieldWasNullException e) {
// ...
}
// ...
return deferSupport(executionContext, result);
}
日志输出:
Executing '9c81e267-c55a-4ebd-9f9c-3a2270b28103' query operation: 'QUERY' using 'graphql.execution.AsyncExecutionStrategy' execution strategy
最终使用AsyncExecutionStrategy策略执行,继续往下看:
AsynExecutionStrategy#execute
public CompletableFuture<ExecutionResult> execute(ExecutionContext executionContext, ExecutionStrategyParameters parameters) throws NonNullableFieldWasNullException {
Instrumentation instrumentation = executionContext.getInstrumentation();
InstrumentationExecutionStrategyParameters instrumentationParameters = new InstrumentationExecutionStrategyParameters(executionContext, parameters);
ExecutionStrategyInstrumentationContext executionStrategyCtx = instrumentation.beginExecutionStrategy(instrumentationParameters);
Map<String, List<Field>> fields = parameters.getFields();
// 字段名称
List<String> fieldNames = new ArrayList<>(fields.keySet());
List<CompletableFuture<FieldValueInfo>> futures = new ArrayList<>();
List<String> resolvedFields = new ArrayList<>();
for (String fieldName : fieldNames) {
List<Field> currentField = fields.get(fieldName);
ExecutionPath fieldPath = parameters.getPath().segment(mkNameForPath(currentField));
ExecutionStrategyParameters newParameters = parameters
.transform(builder -> builder.field(currentField).path(fieldPath).parent(parameters));
if (isDeferred(executionContext, newParameters, currentField)) {
executionStrategyCtx.onDeferredField(currentField);
continue;
}
resolvedFields.add(fieldName);
// 处理字段,这里处理的是"hello"
CompletableFuture<FieldValueInfo> future = resolveFieldWithInfo(executionContext, newParameters);
futures.add(future);
}
CompletableFuture<ExecutionResult> overallResult = new CompletableFuture<>();
executionStrategyCtx.onDispatched(overallResult);
//并行执行所有filed处理的futures
Async.each(futures).whenComplete((completeValueInfos, throwable) -> {
BiConsumer<List<ExecutionResult>, Throwable> handleResultsConsumer = handleResults(executionContext, resolvedFields, overallResult);
if (throwable != null) {
handleResultsConsumer.accept(null, throwable.getCause());
return;
}
List<CompletableFuture<ExecutionResult>> executionResultFuture = completeValueInfos.stream().map(FieldValueInfo::getFieldValue).collect(Collectors.toList());
executionStrategyCtx.onFieldValuesInfo(completeValueInfos);
Async.each(executionResultFuture).whenComplete(handleResultsConsumer);
}).exceptionally((ex) -> {
// if there are any issues with combining/handling the field results,
// complete the future at all costs and bubble up any thrown exception so
// the execution does not hang.
overallResult.completeExceptionally(ex);
return null;
});
overallResult.whenComplete(executionStrategyCtx::onCompleted);
return overallResult;
}
可以看到这里会遍历所有fileds拿到每个filed future,最后并行执行,下面具体看看:
ExecutionStrategy#resolveFieldWithInfo
调用该函数来获取字段的值及额外的运行时信息,并根据graphql query内容进一步处理它。
protected CompletableFuture<FieldValueInfo> resolveFieldWithInfo(ExecutionContext executionContext, ExecutionStrategyParameters parameters) {
GraphQLFieldDefinition fieldDef = getFieldDef(executionContext, parameters, parameters.getField().get(0));
Instrumentation instrumentation = executionContext.getInstrumentation();
InstrumentationContext<ExecutionResult> fieldCtx = instrumentation.beginField(
new InstrumentationFieldParameters(executionContext, fieldDef, createExecutionStepInfo(executionContext, parameters, fieldDef))
);
CompletableFuture<Object> fetchFieldFuture = fetchField(executionContext, parameters);
CompletableFuture<FieldValueInfo> result = fetchFieldFuture.thenApply((fetchedValue) ->
completeField(executionContext, parameters, fetchedValue));
CompletableFuture<ExecutionResult> executionResultFuture = result.thenCompose(FieldValueInfo::getFieldValue);
fieldCtx.onDispatched(executionResultFuture);
executionResultFuture.whenComplete(fieldCtx::onCompleted);
return result;
}
调用该函数获取filed值,使用从filed GraphQlFiledDefinition关联的DataFetcher。
protected CompletableFuture<Object> fetchField(ExecutionContext executionContext, ExecutionStrategyParameters parameters) {
Field field = parameters.getField().get(0);
GraphQLObjectType parentType = (GraphQLObjectType) parameters.getExecutionStepInfo().getUnwrappedNonNullType();
GraphQLFieldDefinition fieldDef = getFieldDef(executionContext.getGraphQLSchema(), parentType, field);
GraphqlFieldVisibility fieldVisibility = executionContext.getGraphQLSchema().getFieldVisibility();
Map<String, Object> argumentValues = valuesResolver.getArgumentValues(fieldVisibility, fieldDef.getArguments(), field.getArguments(), executionContext.getVariables());
GraphQLOutputType fieldType = fieldDef.getType();
DataFetchingFieldSelectionSet fieldCollector = DataFetchingFieldSelectionSetImpl.newCollector(executionContext, fieldType, parameters.getField());
// ...
CompletableFuture<Object> fetchedValue;
// 获得dataFetcher,这里为HelloWorld的`new StaticDataFetcher("world")`
DataFetcher dataFetcher = fieldDef.getDataFetcher();
dataFetcher = instrumentation.instrumentDataFetcher(dataFetcher, instrumentationFieldFetchParams);
ExecutionId executionId = executionContext.getExecutionId();
try {
log.debug("'{}' fetching field '{}' using data fetcher '{}'...", executionId, executionStepInfo.getPath(), dataFetcher.getClass().getName());
// 执行dataFetcher获取值,enviroment为上下文环境包含参数
Object fetchedValueRaw = dataFetcher.get(environment);
log.debug("'{}' field '{}' fetch returned '{}'", executionId, executionStepInfo.getPath(), fetchedValueRaw == null ? "null" : fetchedValueRaw.getClass().getName());
// 如果是具体值就返回已经有值的CompletableFuture,如果是CompletionStage就直接返回
fetchedValue = Async.toCompletableFuture(fetchedValueRaw);
} catch (Exception e) {
log.debug(String.format("'%s', field '%s' fetch threw exception", executionId, executionStepInfo.getPath()), e);
fetchedValue = new CompletableFuture<>();
fetchedValue.completeExceptionally(e);
}
fetchCtx.onDispatched(fetchedValue);
// 对结果的后续处理
return fetchedValue
.handle((result, exception) -> {
fetchCtx.onCompleted(result, exception);
if (exception != null) {
handleFetchingException(executionContext, parameters, field, fieldDef, argumentValues, environment, exception);
return null;
} else {
return result;
}
})
.thenApply(result -> unboxPossibleDataFetcherResult(executionContext, parameters, result))
.thenApply(this::unboxPossibleOptional);
}
总体执行过程
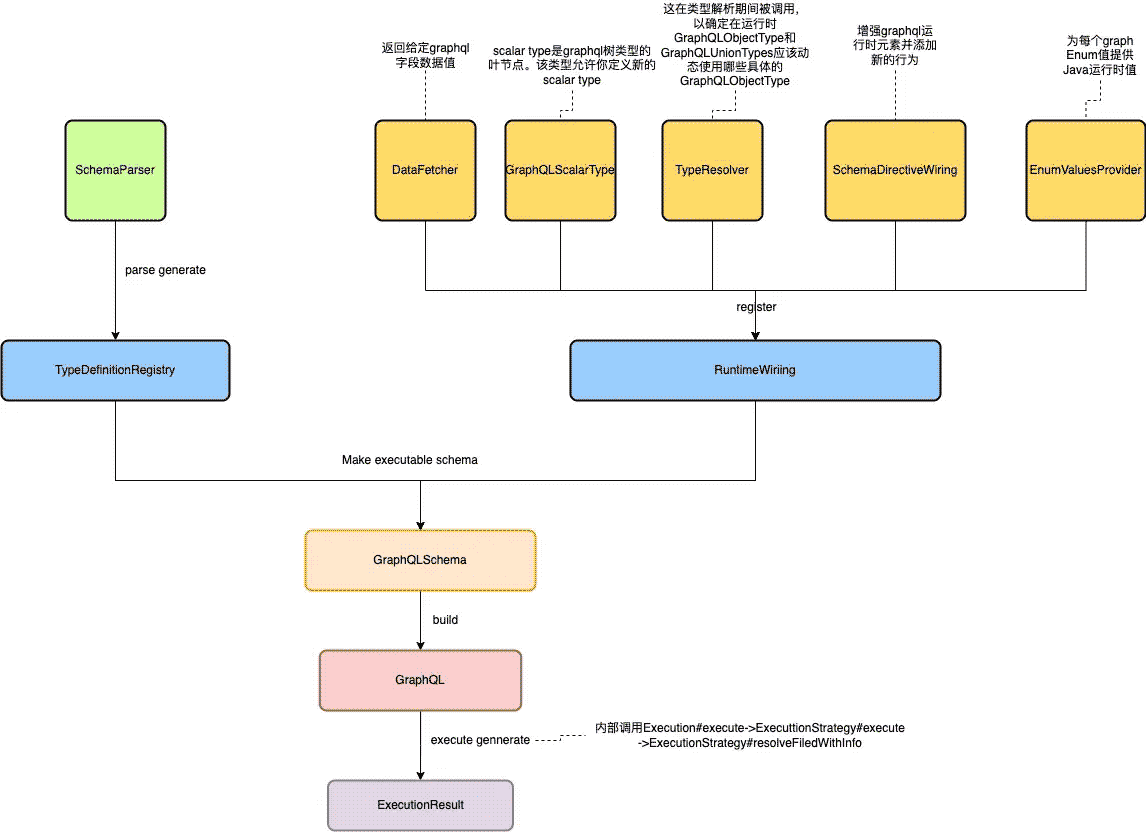
以上就是从Hello World开始理解GraphQL背后处理的详细内容,更多关于GraphQL处理的资料请关注我们其它相关文章!
相关推荐
-

GraphQL入门总体创建教程
目录 简介 简单示例 maven依赖 Schema 解析schema并关联对应的fetchers DataFetchers Default DataFetchers 总体创建过程 资料 简介 因为目前做的项目查询提供的接口都使用GraphQL替代典型的REST API,所以有必要去对它进行了解和源码的阅读.本篇主要大致了解下GraphQL. 一种用于API的查询语言,让你的请求数据不多不少.前端按需获取,后端动态返回(不需要的数据不会返回甚至不会查库),对比起典型的REST API将更加灵活,后
-
Java 通过API操作GraphQL
GraphQL可以通过Java的API来实现数据的查询,通过特定的SDL查询语句,获取特定的查询数据.相当于后端作为提供数据源的"数据库",前端根据定义的SDL语句查询需要的数据,将查询数据的控制权交给前端,提高后端接口的通用性和灵活性 引入依赖 <dependency> <groupId>com.graphql-java</groupId> <artifactId>graphql-java</artifactId> <
-
Java 使用 Graphql 搭建查询服务详解
背景 随着React的开源,facebook相继开源了很多相关的项目,这些项目在他们内部已经使用了多年,其中引起我注意的就是本次讨论的是graphql,目前官方只有nodejs版,由于很多公司的后台技术栈都是Java,所以便有了graphql的java版实现,在github上可以找到,废话不多说,直接看代码吧,具体介绍还是去看官网吧,不然就跑题了. GraphQLSchema Schema相当于一个数据库,它有很多GraphQLFieldDefinition组成,Field相当于数据库表/视图,
-
利用Spring Boot和JPA创建GraphQL API
目录 一.生成项目 1. 添加依赖项 二.Schema 三.Entity 和 Repository 四.Queries & Exceptions 1. 查询 2. Mutator 3. Exceptions 前言: GraphQL既是API查询语言,也是使用当前数据执行这些查询的运行时.GraphQL让客户能够准确地要求他们所需要的东西,仅此而已,使API随着时间的推移更容易发展,并通过提供API中数据的清晰易懂的描述,支持强大的开发工具. 在本文中,我们将创建一个简单的机场位置应用程序. 一.
-
vue中使用GraphQL的实例代码
上篇给大家介绍了Java 使用 Graphql 搭建查询服务详解.这里我们讲讲如何在Vue中使用GraphQL. 1. 初始化vue项目 npm install -g @vue/cli vue create vue-apollo-demo 选择默认cli的默认模板就可以了 添加 /src/graphql/article.js . /src/utils/graphql.js 两个文件. ├── node_modules └── public │ ├── favicon.ico │ └── inde
-
从Hello World开始理解GraphQL背后处理及执行过程
目录 前言 Hello World SchemaParser Parser#parseDocument RuntimeWiring RuntimeWiring.Builder#type GraphQL build execute Execution#execute AsynExecutionStrategy#execute ExecutionStrategy#resolveFieldWithInfo 总体执行过程 前言 在上篇文章<初识GraphQL>中我们大致的了解了GraphQL作用,并通
-
深入理解框架背后的原理及源码分析
目录 问题1 问题2 总结 近期团队中同学遇到几个问题,想在这儿跟大家分享一波,虽说不是很有难度,但是背后也折射出一些问题,值得思考. 开始之前先简单介绍一下我所在团队的技术栈,基于这个背景再展开后面将提到的几个问题,将会有更深刻的体会. 控制层基于SpringMvc,数据持久层基于JdbcTemplate自己封装了一套类MyBatis的Dao框架,视图层基于Velocity模板技术,其余组件基于SpringCloud全家桶. 问题1 某应用发布以后开始报数据库连接池不够用异常,日志如下: co
-
深入理解Javascript中的自执行匿名函数
格式: (function(){ //代码 })(); 解释:这是相当优雅的代码(如果你首次看见可能会一头雾水:)),包围函数(function(){})的第一对括号向脚本返回未命名的函数,随后一对空括号立即执行返回的未命名函数,括号内为匿名函数的参数. 来个带参数的例子: (function(arg){ alert(arg+100); })(20); // 这个例子返回120. 回来看看jquery的插件编写 (function($) { // Code goes here })(jQuery
-
深入理解javascript中的立即执行函数(function(){…})()
javascript和其他编程语言相比比较随意,所以javascript代码中充满各种奇葩的写法,有时雾里看花,当然,能理解各型各色的写法也是对javascript语言特性更进一步的深入理解. ( function(){-} )()和( function (){-} () )是两种javascript立即执行函数的常见写法,最初我以为是一个括号包裹匿名函数,再在后面加个括号调用函数,最后达到函数定义后立即执行的目的,后来发现加括号的原因并非如此.要理解立即执行函数,需要先理解一些函数的基本概念.
-
简单理解Java的垃圾回收机制与finalize方法的作用
垃圾回收器要回收对象的时候,首先要调用这个类的finalize方法(你可以 写程序验证这个结论),一般的纯Java编写的Class不需要重新覆盖这个方法,因为Object已经实现了一个默认的,除非我们要实现特殊的功能(这 里面涉及到很多东西,比如对象空间树等内容). 不过用Java以外的代码编写的Class(比如JNI,C++的new方法分配的内存),垃圾回收器并不能对这些部分进行正确的回收,这时就需要我们覆盖默认的方法来实现对这部分内存的正确释放和回收(比如C++需要delete). 总之,f
-
JVM系列之:再谈java中的safepoint说明
safepoint是什么 java程序里面有很多很多的java线程,每个java线程又有自己的stack,并且共享了heap.这些线程一直运行呀运行,不断对stack和heap进行操作. 这个时候如果JVM需要对stack和heap做一些操作该怎么办呢? 比如JVM要进行GC操作,或者要做heap dump等等,这时候如果线程都在对stack或者heap进行修改,那么将不是一个稳定的状态.GC直接在这种情况下操作stack或者heap,会导致线程的异常. 怎么处理呢? 这个时候safepoint
-
JVM的垃圾回收机制详解和调优
文章来源:matrix.org.cn 作者:ginger547 1.JVM的gc概述 gc即垃圾收集机制是指jvm用于释放那些不再使用的对象所占用的内存.java语言并不要求jvm有gc,也没有规定gc如何工作.不过常用的jvm都有gc,而且大多数gc都使用类似的算法管理内存和执行收集操作. 在充分理解了垃圾收集算法和执行过程后,才能有效的优化它的性能.有些垃圾收集专用于特殊的应用程序.比如,实时应用程序主要是为了避免垃圾收集中断,而大多数OLTP应用程序则注重整体效率.理解了应用程序的工作负荷
-
C++ 线程(串行 并行 同步 异步)详解
C++ 线程(串行 并行 同步 异步)详解 看了很多关于这类的文章,一直没有总结.不总结的话就会一直糊里糊涂,以下描述都是自己理解的非官方语言,不一定严谨,可当作参考. 首先,进程可理解成一个可执行文件的执行过程.在ios app上的话我们可以理解为我们的app的.ipa文件执行过程也即app运行过程.杀掉app进程就杀掉了这个app在系统里运行所占的内存. 线程:线程是进程的最小单位.一个进程里至少有一个主线程.就是那个main thread.非常简单的app可能只需要一个主线程即UI线程.
-
对比分析MySQL语句中的IN 和Exists
背景介绍 最近在写SQL语句时,对选择IN 还是Exists 犹豫不决,于是把两种方法的SQL都写出来对比一下执行效率,发现IN的查询效率比Exists高了很多,于是想当然的认为IN的效率比Exists好,但本着寻根究底的原则,我想知道这个结论是否适用所有场景,以及为什么会出现这个结果. 网上查了一下相关资料,大体可以归纳为:外部表小,内部表大时,适用Exists:外部表大,内部表小时,适用IN.那我就困惑了,因为我的SQL语句里面,外表只有1W级别的数据,内表有30W级别的数据,按网上的说法应
-
深入理解Vue官方文档梳理之全局API
Vue.extend 配置项data必须为function,否则配置无效.data的合并规则(可以看<Vue官方文档梳理-全局配置>)源码如下: 传入非function类型的data(上图中data配置为{a:1}),在合并options时,如果data不是function类型,开发版会发出警告,然后直接返回了parentVal,这意味着extend传入的data选项被无视了. 我们知道实例化Vue的时候,data可以是对象,这里的合并规则不是通用的吗?注意上面有个if(!vm)的判断,实例化