Redis分布式锁的使用和实现原理详解
模拟一个电商里面下单减库存的场景。
1.首先在redis里加入商品库存数量。
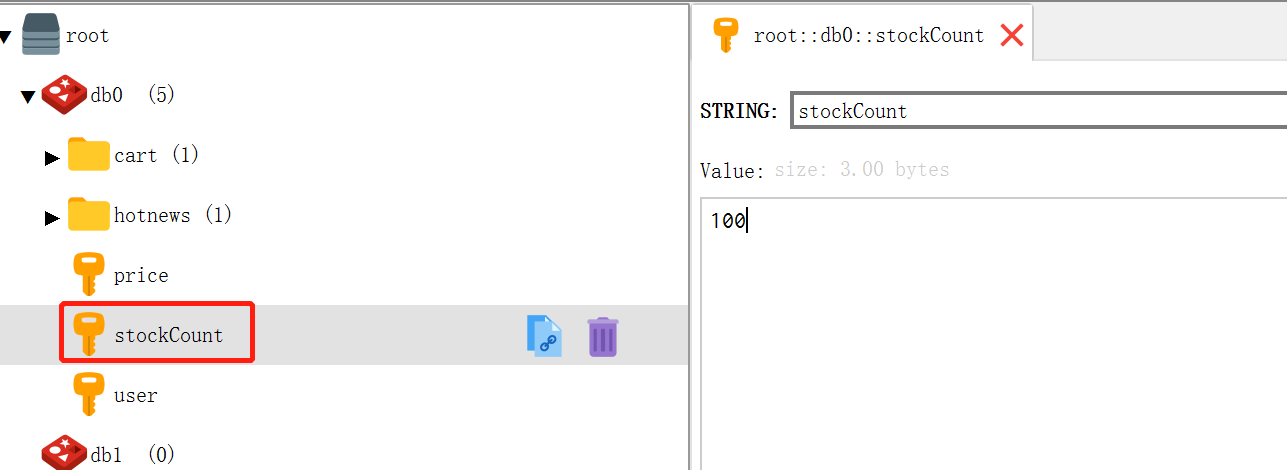
2.新建一个Spring Boot项目,在pom里面引入相关的依赖。
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-redis</artifactId> </dependency>
3.接下来,在application.yml配置redis属性和指定应用的端口号:
server: port: 8090 spring: redis: host: 192.168.0.60 port: 6379
4.新建一个Controller类,扣减库存第一版代码:
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import javax.annotation.Resource;
import java.util.Objects;
@RestController
public class StockController {
private static final Logger logger = LoggerFactory.getLogger(StockController.class);
@Resource
private StringRedisTemplate stringRedisTemplate;
@RequestMapping("/reduceStock")
public String reduceStock() {
// 从redis中获取库存数量
int stock = Integer.parseInt(Objects.requireNonNull(stringRedisTemplate.opsForValue().get("stockCount")));
if (stock > 0) {
// 减库存
int restStock = stock - 1;
// 剩余库存再重新设置到redis中
stringRedisTemplate.opsForValue().set("stockCount", String.valueOf(restStock));
logger.info("扣减成功,剩余库存:{}", restStock);
} else {
logger.info("库存不足,扣减失败。");
}
return "success";
}
}
上面第一版的代码存在什么问题:超卖。假如多个线程同时调用获取库存数量的代码,那么每个线程拿到的都是100,判断库存都大于0,都可以执行减库存的操作。假如两个线程都做减库存更新缓存,那么缓存的库存变成99,但实际上,应该是减掉2个库存。
那么很多人的第一个想法是加synchronized同步代码块,因为获取数量和减库存不是原子性操作,有多个线程来执行代码的时候,只允许一个线程执行代码块里的代码。那么改完的第二版的代码如下:
@RequestMapping("/reduceStock")
public String reduceStock() {
synchronized (this) {
// 从redis中获取库存数量
int stock = Integer.parseInt(Objects.requireNonNull(stringRedisTemplate.opsForValue().get("stockCount")));
if (stock > 0) {
// 减库存
int restStock = stock - 1;
// 剩余库存再重新设置到redis中
stringRedisTemplate.opsForValue().set("stockCount", String.valueOf(restStock));
logger.info("扣减成功,剩余库存:{}", restStock);
} else {
logger.info("库存不足,扣减失败。");
}
}
return "success";
}
但使用synchronize存在的问题,就是只能保证单机环境运行时没有问题的。但现在的软件公司里,基本上都是集群架构,是多实例,前面使用Nginx做负载均衡,大概架构如下:
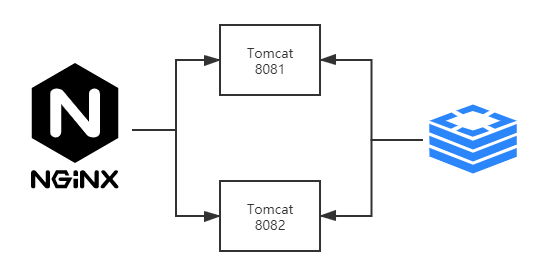
Nginx分发请求,把请求发送到不同的Tomcat容器,而synchronize只能保证一个应用是没有问题的。
那么代码改进第三版,就是引入redis分布式锁,具体代码如下:
@RequestMapping("/reduceStock")
public String reduceStock() {
String lockKey = "stockKey";
try {
boolean result = stringRedisTemplate.opsForValue().setIfAbsent(lockKey, "1");
if (!result) {
return "errorCode";
}
// 从redis中获取库存数量
int stock = Integer.parseInt(Objects.requireNonNull(stringRedisTemplate.opsForValue().get("stockCount")));
if (stock > 0) {
// 减库存
int restStock = stock - 1;
// 剩余库存再重新设置到redis中
stringRedisTemplate.opsForValue().set("stockCount", String.valueOf(restStock));
logger.info("扣减成功,剩余库存:{}", restStock);
} else {
logger.info("库存不足,扣减失败。");
}
} finally {
stringRedisTemplate.delete(lockKey)
}
return "success";
}
如果有一个线程拿到锁,那么其他的线程就会等待。一定要记得在finally里面把使用完的锁要删除掉。否则一旦抛出异常,只有一个线程会一直持有锁,其他线程没有机会获取。
但如果在执行if (stock > 0) {代码块里的代码,因为宕机或重启没有执行完,也会一直持有锁,所以,这里需要把锁加一个超时时间:
boolean result = stringRedisTemplate.opsForValue().setIfAbsent(lockKey, "1"); stringRedisTemplate.expire(lockKey, 10, TimeUnit.SECONDS);
但如果上面两行代码在中间执行出问题了,设置超时时间的代码还没执行,也会出现锁不能释放的问题。好在有对应的方法:就是把上面两行代码设置成一个原子操作:
// 这里默认设置超时时间为10秒 boolean result = stringRedisTemplate.opsForValue().setIfAbsent(lockKey, "1", 10, TimeUnit.SECONDS);
到此为止,如果并发量不是很大的话,基本上是没有问题的。
但是,如果请求的并发量很大,就会出现新的问题:有种比较特殊的情况,第一个线程执行了15秒,但是执行到10秒钟的时候,锁已经失效释放了,那么在高并发场景下,第二个线程发现锁已经失效,那么它就可以拿到这把锁进行加锁,
假设第二个线程执行需要8秒,它执行到5秒钟后,此时第一个线程已经执行完了,执行完那一刻,进行了删除key的操作,但是此时的锁是第二个线程加的,这样第一个线程把第二个线程加的锁删掉了。
那意味着第三个线程又可以拿到锁,第三个线程执行了3秒钟,此时第二个线程执行完毕,那么第二个线程把第三个线程的锁又删除了。导致锁失效。
那么解决的思路就是,我自己加的锁,不要被别人删掉。那么可以为每个进来的请求生成一个唯一的id,作为分布式锁的值,然后在释放时,判断一下当前线程的id,是不是和缓存里的id是否相等。
@RequestMapping("/reduceStock")
public String reduceStock() {
String lockKey = "stockKey";
String id = UUID.randomUUID().toString();
try {
// 这里默认设置超时时间为30秒
boolean result = stringRedisTemplate.opsForValue().setIfAbsent(lockKey, id, 30, TimeUnit.SECONDS);
if (!result) {
return "errorCode";
}
// 从redis中获取库存数量
int stock = Integer.parseInt(Objects.requireNonNull(stringRedisTemplate.opsForValue().get("stockCount")));
if (stock > 0) {
// 减库存
int restStock = stock - 1;
// 剩余库存再重新设置到redis中
stringRedisTemplate.opsForValue().set("stockCount", String.valueOf(restStock));
logger.info("扣减成功,剩余库存:{}", restStock);
} else {
logger.info("库存不足,扣减失败。");
}
} finally {
if (id.contentEquals(Objects.requireNonNull(stringRedisTemplate.opsForValue().get(lockKey)))) {
stringRedisTemplate.delete(lockKey);
}
}
return "success";
}
到此为止,一个比较完善的锁就实现了,可以应付大部分场景。
当然,上面的代码还有一个问题,就是一个线程执行时间超过了过期时间,后面的代码还没有执行完,锁就已经删除了,还是会有些bug存在。解决的方法是给锁续命的操作。
在当前主线程获取到锁以后,可以fork出一个线程,执行Timer定时器操作,假如默认超时时间为30秒,那么定时器每隔10秒去看下这把锁还是否存在,存在就说明这个锁里的逻辑还没有执行完,那么就可以把当前主线程的超时时间重新设置为30秒;如果不存在,就直接结束掉。
但是上面的逻辑,在高并发场景下,实现比较完善还是比较困难的。好在现在已经有比较成熟的框架,那就是Redisson。官方地址https://redisson.org。
下面用Redisson来实现分布式锁。
首先引入依赖包:
<dependency> <groupId>org.redisson</groupId> <artifactId>redisson</artifactId> <version>3.6.5</version> </dependency>
配置类:
@Configuration
public class RedissonConfig {
@Bean
public Redisson redisson() {
// 单机模式
Config config = new Config();
config.useSingleServer().setAddress("redis://192.168.0.60:6379").setDatabase(0);
return (Redisson) Redisson.create(config);
}
}
接下来用redisson重写上面的减库存操作:
@Resource
private Redisson redisson;
@RequestMapping("/reduceStock")
public String reduceStock() {
String lockKey = "stockKey";
RLock redissonLock = redisson.getLock(lockKey);
try {
// 加锁,锁续命
redissonLock.lock();
// 从redis中获取库存数量
int stock = Integer.parseInt(Objects.requireNonNull(stringRedisTemplate.opsForValue().get("stockCount")));
if (stock > 0) {
// 减库存
int restStock = stock - 1;
// 剩余库存再重新设置到redis中
stringRedisTemplate.opsForValue().set("stockCount", String.valueOf(restStock));
logger.info("扣减成功,剩余库存:{}", restStock);
} else {
logger.info("库存不足,扣减失败。");
}
} finally {
redissonLock.unlock();
}
return "success";
}
其实就是三个步骤:获取锁,加锁,释放锁。
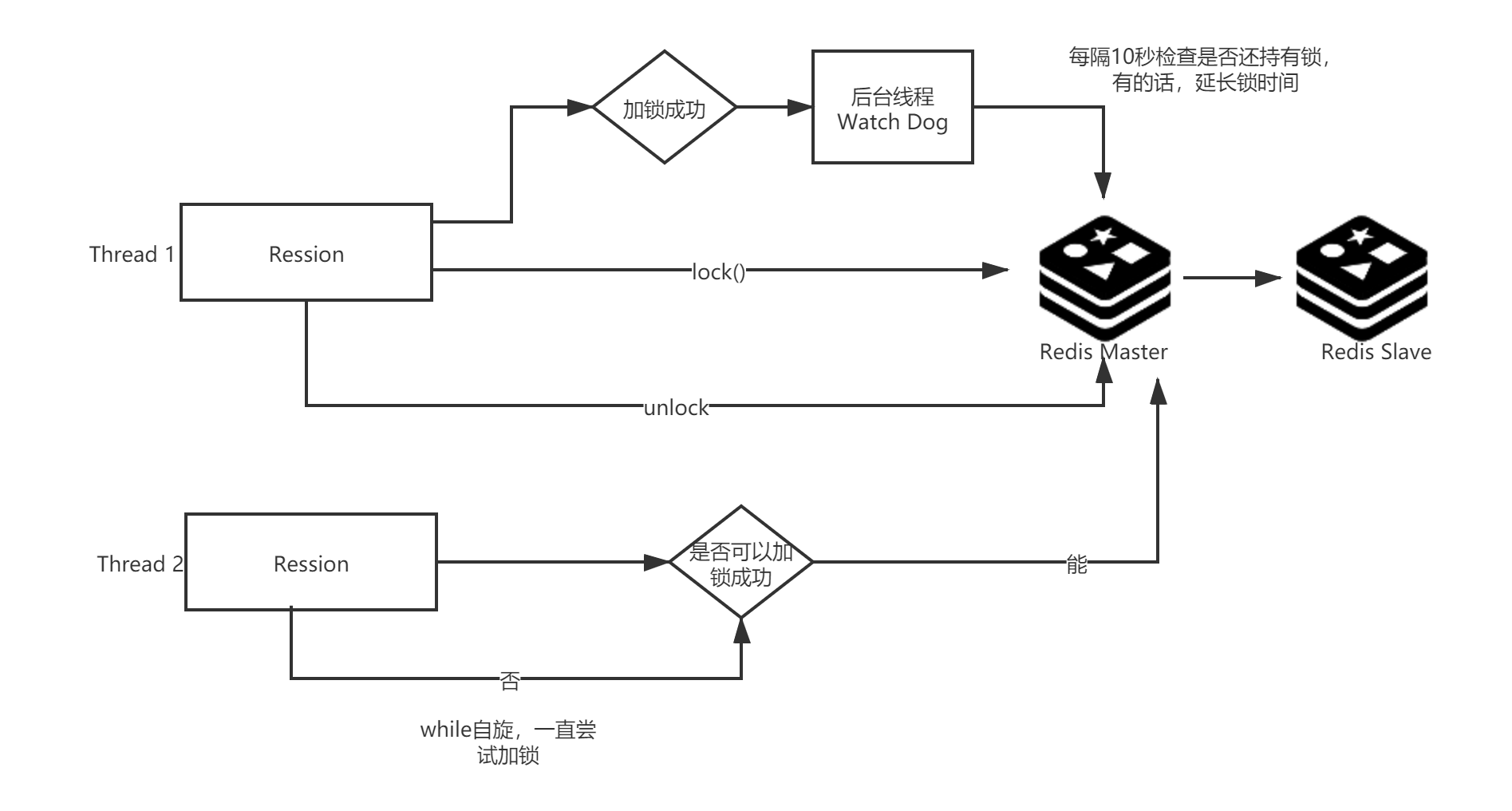
先简单看下Redisson的实现原理:
这里先说一下Redis很多操作使用Lua脚本来实现原子性操作,关于Lua语法,可以去网上找下相关教程。
使用Lua脚本的好处有:
1.减少网络开销,多个命令可以使用一次请求完成;
2.实现了原子性操作,Redis会把Lua脚本作为一个整体去执行;
3.实现事务,Redis自带的事务功能有限,而Lua脚本实现了事务的常规操作,而且还支持回滚。
但是Lua实际上不会使用很多,如果Lua脚本执行时间过长,因为Redis是单线程,因此会导致堵塞。
最后,说下Redisson分布式锁的代码实现,
找到上面的redissonLock.lock();
lock方法点进去,一直点到RedissonLock类里面的lockInterruptibly方法:
@Override
public void lockInterruptibly(long leaseTime, TimeUnit unit) throws InterruptedException {
// 获取线程id
long threadId = Thread.currentThread().getId();
Long ttl = tryAcquire(leaseTime, unit, threadId);
// lock acquired
if (ttl == null) {
return;
}
RFuture<RedissonLockEntry> future = subscribe(threadId);
commandExecutor.syncSubscription(future);
try {
while (true) {
ttl = tryAcquire(leaseTime, unit, threadId);
// lock acquired
if (ttl == null) {
break;
}
// waiting for message
if (ttl >= 0) {
getEntry(threadId).getLatch().tryAcquire(ttl, TimeUnit.MILLISECONDS);
} else {
getEntry(threadId).getLatch().acquire();
}
}
} finally {
unsubscribe(future, threadId);
}
// get(lockAsync(leaseTime, unit));
}
重点看下tryAcquire方法,把线程id作为一个参数传递进来,在这个方法里面,找到tryLockInnerAsync方法点进去,
<T> RFuture<T> tryLockInnerAsync(long leaseTime, TimeUnit unit, long threadId, RedisStrictCommand<T> command) {
internalLockLeaseTime = unit.toMillis(leaseTime);
return commandExecutor.evalWriteAsync(getName(), LongCodec.INSTANCE, command,
"if (redis.call('exists', KEYS[1]) == 0) then " +
"redis.call('hset', KEYS[1], ARGV[2], 1); " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return nil; " +
"end; " +
"if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then " +
"redis.call('hincrby', KEYS[1], ARGV[2], 1); " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return nil; " +
"end; " +
"return redis.call('pttl', KEYS[1]);",
Collections.<Object>singletonList(getName()), internalLockLeaseTime, getLockName(threadId));
}
这里就是一堆Lua脚本,先看第一个if命令,先去判断 KEYS[1](就是对应的锁key的名字),如果不存在,在hashmap里,设置一个属性为线程id,值为1,再把map的过期时间设置为internalLockLeaseTime,这个值默认是30秒,
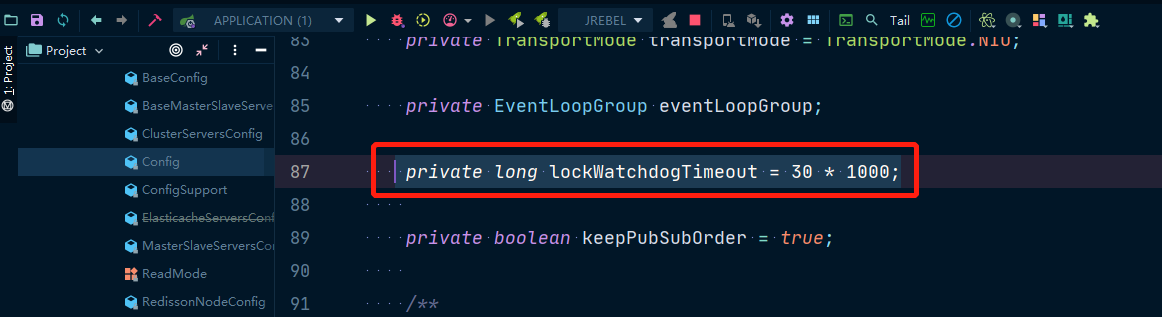
上面的操作对应的命令是:
hset keyname id:thread 1 pexpire keyname 30
然后返回nil,相当于null,那程序return了。
另外,Redisson还支持重入锁,那第二个if就是执行重入锁的操作,会判断锁是否存在,并且传入的线程id是否是当前线程的id,若果是,支持重复加锁进行自增操作;
如果是其他线程调用lock方法,上面两个if判断不会走,会返回锁剩余过期时间。
接着返回到tryAcquireAsync方法里面往下看:
实际上是加了一个监听器,在监听器里面有个很重要的方法scheduleExpirationRenewal,一看这个名字就能大概猜出是什么功能,
里面有个定时任务的轮询,
private void scheduleExpirationRenewal(final long threadId) {
if (expirationRenewalMap.containsKey(getEntryName())) {
return;
}
Timeout task = commandExecutor.getConnectionManager().newTimeout(new TimerTask() {
@Override
public void run(Timeout timeout) throws Exception {
// 判断传递进来的线程id是否是我们之前主线程设置的id,如果是,则增加续命,增加30秒。
RFuture<Boolean> future = commandExecutor.evalWriteAsync(getName(), LongCodec.INSTANCE, RedisCommands.EVAL_BOOLEAN,
"if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return 1; " +
"end; " +
"return 0;",
Collections.<Object>singletonList(getName()), internalLockLeaseTime, getLockName(threadId));
future.addListener(new FutureListener<Boolean>() {
@Override
public void operationComplete(Future<Boolean> future) throws Exception {
expirationRenewalMap.remove(getEntryName());
if (!future.isSuccess()) {
log.error("Can't update lock " + getName() + " expiration", future.cause());
return;
}
if (future.getNow()) {
// reschedule itself
scheduleExpirationRenewal(threadId);
}
}
});
}
}, internalLockLeaseTime / 3, TimeUnit.MILLISECONDS);
if (expirationRenewalMap.putIfAbsent(getEntryName(), task) != null) {
task.cancel();
}
}
接着推迟10秒钟(internalLockLeaseTime / 3),再执行续命操作逻辑。
到最后,再回到lockInterruptibly方法,如果ttl 为null,说明加锁成功了,就返回null,那如果其他线程的话,就会返回剩余过期时间,那么就会进入到while死循环里,一直尝试加锁,调用tryAcquire方法,在琐失效以后,再会尝试获取加锁。
到此为止,分析完毕。
总结
到此这篇关于Redis分布式锁的使用和实现原理的文章就介绍到这了,更多相关Redis分布式锁的使用和原理内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

浅谈Redis分布式锁的正确实现方式
前言 分布式锁一般有三种实现方式:1. 数据库乐观锁:2. 基于Redis的分布式锁:3. 基于ZooKeeper的分布式锁.本篇博客将介绍第二种方式,基于Redis实现分布式锁.虽然网上已经有各种介绍Redis分布式锁实现的博客,然而他们的实现却有着各种各样的问题,为了避免误人子弟,本篇博客将详细介绍如何正确地实现Redis分布式锁. 可靠性 首先,为了确保分布式锁可用,我们至少要确保锁的实现同时满足以下四个条件: 1.互斥性.在任意时刻,只有一个客户端能持有锁. 2.不会发生死锁.即使有一个
-
Java Redis分布式锁的正确实现方式详解
前言 分布式锁一般有三种实现方式:1. 数据库乐观锁:2. 基于Redis的分布式锁:3. 基于ZooKeeper的分布式锁.本篇博客将介绍第二种方式,基于Redis实现分布式锁.虽然网上已经有各种介绍Redis分布式锁实现的博客,然而他们的实现却有着各种各样的问题,为了避免误人子弟,本篇博客将详细介绍如何正确地实现Redis分布式锁. 可靠性 首先,为了确保分布式锁可用,我们至少要确保锁的实现同时满足以下四个条件: 互斥性.在任意时刻,只有一个客户端能持有锁. 不会发生死锁.即使有一个客户端在
-
基于redis分布式锁实现秒杀功能
最近在项目中遇到了类似"秒杀"的业务场景,在本篇博客中,我将用一个非常简单的demo,阐述实现所谓"秒杀"的基本思路. 业务场景 所谓秒杀,从业务角度看,是短时间内多个用户"争抢"资源,这里的资源在大部分秒杀场景里是商品:将业务抽象,技术角度看,秒杀就是多个线程对资源进行操作,所以实现秒杀,就必须控制线程对资源的争抢,既要保证高效并发,也要保证操作的正确. 一些可能的实现 刚才提到过,实现秒杀的关键点是控制线程对资源的争抢,根据基本的线程知识,可
-
基于Redis实现分布式锁以及任务队列
一.前言 双十一刚过不久,大家都知道在天猫.京东.苏宁等等电商网站上有很多秒杀活动,例如在某一个时刻抢购一个原价1999现在秒杀价只要999的手机时,会迎来一个用户请求的高峰期,可能会有几十万几百万的并发量,来抢这个手机,在高并发的情形下会对数据库服务器或者是文件服务器应用服务器造成巨大的压力,严重时说不定就宕机了,另一个问题是,秒杀的东西都是有量的,例如一款手机只有10台的量秒杀,那么,在高并发的情况下,成千上万条数据更新数据库(例如10台的量被人抢一台就会在数据集某些记录下 减1),那次这个
-
Redis上实现分布式锁以提高性能的方案研究
背景: 在很多互联网产品应用中,有些场景需要加锁处理,比如:秒杀,全局递增ID,楼层生成等等.大部分是解决方案基于DB实现的,Redis为单进程单线程模式,采用队列模式将并发访问变成串行访问,且多客户端对Redis的连接并不存在竞争关系. 项目实践 任务队列用到分布式锁的情况比较多,在将业务逻辑中可以异步处理的操作放入队列,在其他线程中处理后出队,此时队列中使用了分布式锁,保证入队和出队的一致性.关于redis队列这块的逻辑分析,我将在下一次对其进行总结,此处先略过. 接下来对redis实现的分
-
Redis构建分布式锁
1.前言 为什么要构建锁呢?因为构建合适的锁可以在高并发下能够保持数据的一致性,即客户端在执行连贯的命令时上锁的数据不会被别的客户端的更改而发生错误.同时还能够保证命令执行的成功率. 看到这里你不禁要问redis中不是有事务操作么?事务操作不能够实现上面的功能么? 的确,redis中的事务可以watch可以监控数据,从而能够保证连贯执行的时数据的一致性,但是我们必须清楚的认识到,在多个客户端同时处理相同的数据的时候,很容易导致事务的执行失败,甚至会导致数据的出错. 在关系型数据库中,用户首先向数
-
深入理解redis分布式锁和消息队列
最近博主在看redis的时候发现了两种redis使用方式,与之前redis作为缓存不同,利用的是redis可设置key的有效时间和redis的BRPOP命令. 分布式锁 由于目前一些编程语言,如PHP等,不能在内存中使用锁,或者如Java这样的,需要一下更为简单的锁校验的时候,redis分布式锁的使用就足够满足了. redis的分布式锁其实就是基于setnx方法和redis对key可设置有效时间的功能来实现的.基本用法比较简单. public boolean tryLock(String loc
-
Redis实现分布式锁的几种方法总结
Redis实现分布式锁的几种方法总结 分布式锁是控制分布式系统之间同步访问共享资源的一种方式.在分布式系统中,常常需要协调他们的动作.如果不同的系统或是同一个系统的不同主机之间共享了一个或一组资源,那么访问这些资源的时候,往往需要互斥来防止彼此干扰来保证一致性,在这种情况下,便需要使用到分布式锁. 我们来假设一个最简单的秒杀场景:数据库里有一张表,column分别是商品ID,和商品ID对应的库存量,秒杀成功就将此商品库存量-1.现在假设有1000个线程来秒杀两件商品,500个线程秒杀第一个商品,
-
Redis分布式锁的使用和实现原理详解
模拟一个电商里面下单减库存的场景. 1.首先在redis里加入商品库存数量. 2.新建一个Spring Boot项目,在pom里面引入相关的依赖. <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <dependency> <gr
-
Java分布式锁的概念与实现方式详解
什么是分布式锁?在回答这个问题之前,我们先回答一下什么是锁. 普通的锁,即在单机多线程环境下,当多个线程需要访问同一个变量或代码片段时,被访问的变量或代码片段叫做临界区域,我们需要控制线程一个一个的顺序执行,否则会出现并发问题. 如何控制呢?就是设置一个各个线程都能看的见的标志.然后,每个线程想访问临界区域时,都要先查看标志,如果标志没有被占用,则说明目前没有线程在访问临界区域.如果标志被占用了,则说明目前有线程正在访问临界区域,则当前线程需要等待. 这个标志,就是锁. 在单机多线程的java程
-
redis分布式锁的实现原理详解
首先,为了确保分布式锁可用,我们至少要确保锁的实现同时满足以下四个条件: 1.互斥性.在任意时刻,只有一个客户端能持有锁. 2.不会发生死锁.即使有一个客户端在持有锁的期间崩溃而没有主动解锁,也能保证后续其他客户端能加锁. 3.具有容错性.只要大部分的Redis节点正常运行,客户端就可以加锁和解锁. 4.解铃还须系铃人.加锁和解锁必须是同一个客户端,客户端自己不能把别人加的锁给解了. 下边是代码实现,首先我们要通过Maven引入Jedis开源组件,在pom.xml文件加入下面的代码: <depe
-
详解Redis分布式锁的原理与实现
目录 前言 使用场景 为什么要使用分布式锁 如何使用分布式锁 流程图 分布式锁的状态 分布式锁的特点 分布式锁的实现方式(以redis分布式锁实现为例) 总结 前言 在单体应用中,如果我们对共享数据不进行加锁操作,会出现数据一致性问题,我们的解决办法通常是加锁.在分布式架构中,我们同样会遇到数据共享操作问题,此时,我们就需要分布式锁来解决问题,下面我们一起聊聊使用redis来实现分布式锁. 使用场景 库存超卖 比如 5个笔记本 A 看 准备买3个 B 买2个 C 4个 一下单 3+2+4 =9
-
Spring Boot 实现Redis分布式锁原理
目录 分布式锁实现 引入jar包 封装工具类 模拟秒杀扣减库存 测试代码 方案优化 问题1:扣减库存逻辑无法保证原子性, 问题2:如果加锁失败,则会直接访问,无法重入锁 总结 分布式锁实现 引入jar包 <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-redis</artifactId> <exclus
-
springboot+redis分布式锁实现模拟抢单
本篇内容主要讲解的是redis分布式锁,这个在各大厂面试几乎都是必备的,下面结合模拟抢单的场景来使用她:本篇不涉及到的redis环境搭建,快速搭建个人测试环境,这里建议使用docker:本篇内容节点如下: jedis的nx生成锁 如何删除锁 模拟抢单动作(10w个人开抢) jedis的nx生成锁 对于java中想操作redis,好的方式是使用jedis,首先pom中引入依赖: <dependency> <groupId>redis.clients</groupId> &
-
详解RedisTemplate下Redis分布式锁引发的系列问题
自己的项目因为会一直抓取某些信息,但是本地会和线上经常一起跑,造成冲突.这其实就是我们常说的分布式集群的问题了,本地和线上的服务器构成了集群以及QPS为2的小并发(其实也不叫并发,不知道拿什么词形容?). 首先,分布式集群的问题大家都知道,会造成数据库的插入重复问题,会造成一系列的并发性问题. 解决的方式呢也大概如下几点,百度以及谷歌上都能搜到的解决方式: 1:数据库添加唯一索引 2:设计接口幂等性 3:依靠中间件使用分布式锁,而分布式锁又分为Redis和Zookeeper 由于Zookeepe
-
详解redis分布式锁的这些坑
一.白话分布式 什么是分布式,用最简单的话来说,就是为了较低单个服务器的压力,将功能分布在不同的机器上面,本来一个程序员可以完成一个项目:需求->设计->编码->测试 但是项目多的时候,一个人也扛不住,这就需要不同的人进行分工合作了 这就是一个简单的分布式协同工作了: 二.分布式锁 首先看一个问题,如果说某个环节被终止或者别侵占,就会发生不可知的事情 这就会出现,设计好的或者设计的半成品会被破坏,导致后面环节出错: 这时候,我们就需要引入分布式锁的概念: 何为分布式锁 当在分布式模型下,
-
redis分布式锁之可重入锁的实现代码
上篇redis实现的分布式锁,有一个问题,它不可重入. 所谓不可重入锁,即若当前线程执行某个方法已经获取了该锁,那么在方法中尝试再次获取锁时,就会获取不到被阻塞. 同一个人拿一个锁 ,只能拿一次不能同时拿2次. 1.什么是可重入锁?它有什么作用? 可重入锁,也叫做递归锁,指的是在同一线程内,外层函数获得锁之后,内层递归函数仍然可以获取到该锁. 说白了就是同一个线程再次进入同样代码时,可以再次拿到该锁. 它的作用是:防止在同一线程中多次获取锁而导致死锁发生. 2.那么java中谁实现了可重入锁了?
-
Redisson实现Redis分布式锁的几种方式
目录 Redis几种架构 普通分布式锁 单机模式 哨兵模式 集群模式 总结 Redlock分布式锁 实现原理 问题合集 前几天发的一篇文章<Redlock:Redis分布式锁最牛逼的实现>,引起了一些同学的讨论,也有一些同学提出了一些疑问,这是好事儿.本文在讲解如何使用Redisson实现Redis普通分布式锁,以及Redlock算法分布式锁的几种方式的同时,也附带解答这些同学的一些疑问. Redis几种架构 Redis发展到现在,几种常见的部署架构有: 单机模式: 主从模式: 哨兵模式: 集