Linux上定位后台服务偶发崩溃的解决方法
问题描述
在最近的后台服务中,新增将某个指令的请求数据落盘保存的功能。在具体实现时,采用成员变量来保存请求消息代理头,在接收响应以及消息管理类释放时进行销毁。测试反馈,该服务偶发崩溃。
问题分析
测试环境上运行的是rel版程序,由于在编译时去掉了调试信息(-g)以及开启O3级别优化,从崩溃dump的堆栈上,只看到程序崩溃的调用栈,函数入参等被优化掉,由于此处没有打日志,只能想其他办法来复现。猜测是重复释放指针导致的崩溃,接下来继续分析。
从rel版本的调用栈上看,只看见最后销毁的函数调用,而在实际代码中,有两处销毁的函数调用入口,为什么在dump中看到的调用栈顺序与实际代码不一致呢?猜测是开启O3优化,将函数内联。
做了以下实验来分析,
void test_dump()
{
int* p = NULL;
*p = 2; // occur dump
}
void test_f2(int b)
{
b += 1;
test_dump();
}
void test_f1(int a)
{
a+=1;
test_f2(a);
}
int main()
{
test_f1(1);
return 0;
}
在Debug以及Rel模式下,触发崩溃,使用gdb来输出堆栈信息分别如下:
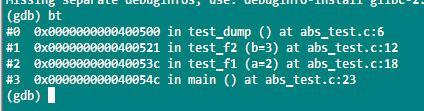

结论:在Rel模式下,O3级别的优化内联了调用函数,如果从崩溃点往上回溯有多个可能入口点,那仅凭dump信息不能确认是哪个入口触发的崩溃。
构造测试环境
通过分析代码,得知要触发可能的多重释放,需要构造一边创建,一边销毁的场景。
创建:可通过测试工具,定时高频发送特定指令,触发创建流程销毁:可在定时任务中,进行无效状态上报,触发销毁流程为了加快崩溃复现速度,创建以及销毁的速度需要合理匹配,如果太快销毁,会导致无法进入创建流程。经过分析尝试,最终设定测试工具每50毫秒发送一次,后台服务每50ms上报无效状态。
为进一步验证崩溃的想法,在销毁操作等关键路径添加日志,启动Rel版来重现。经过长时间的测试,获得了2次宝贵的崩溃dump以及对应的日志。每次dump要花费2个半小时甚至更多才能复现,说明这个问题是偶发问题,很可能与多线程竞态有关。复现该问题的时间成本有点高,不过,从获得的dump以及日志已足以定位问题。
日志分析
同一后台服务,不同业务模块的日志分布在不同日志文件中,在分析时,需要将各部分日志聚合起来,方便复现全流程。在聚合时,可以按需截取各模块的最后若干行日志,每种日志中包含正常以及异常的日志,将其汇总到单一文件,然后结合代码进行逐行关联分析。
在分析过程中,遇到一些框架方面的疑问,通过询问相关同事得到解答。目前的消息收发框架在接收消息时,先将消息放入线程池的消息队列,通过信号量来唤醒线程,线程从消息队列中获取消息,从消息中取出处理函数进行处理。
在应用层处理不同消息时,可能处理同一个变量时,会有发生竞态。通过对释放指针的分析,正常释放指针指都有一定的规律,当触发崩溃时,释放的指针值与正常的值有明显区别。
经验小结 发现有dump文件时,查看dump文件生成时间,将当时的日志以及可执行文件,连同dump文件一并放在独立的文件夹中,便于后续分析。因为当前的日志文件以及可执行文件可能被删除以及更新。每一次问题的解决,都是一次对已有系统的再深入认识,理解。构造复现环境时,要使用Rel版本,且只能通过日志来确认程序流程,而不是断点。在linux上,不能使用嵌套属性的互斥锁,它会破坏设计意图,让潜在的死锁更加难以发现。让错误尽早暴露好过后续找错。大胆假设,小心求证,胜利的曙光终会出现。
到此这篇关于Linux上定位后台服务偶发崩溃的解决方法的文章就介绍到这了,更多相关Linux上定位后台服务崩溃问题内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Linux上定位后台服务偶发崩溃的解决方法
问题描述 在最近的后台服务中,新增将某个指令的请求数据落盘保存的功能.在具体实现时,采用成员变量来保存请求消息代理头,在接收响应以及消息管理类释放时进行销毁.测试反馈,该服务偶发崩溃. 问题分析 测试环境上运行的是rel版程序,由于在编译时去掉了调试信息(-g)以及开启O3级别优化,从崩溃dump的堆栈上,只看到程序崩溃的调用栈,函数入参等被优化掉,由于此处没有打日志,只能想其他办法来复现.猜测是重复释放指针导致的崩溃,接下来继续分析. 从rel版本的调用栈上看,只看见最后销毁的函数调用,而在实
-

关于Linux服务器磁盘空间占满问题的解决方法
下面我们一起来看一篇关于Linux服务器磁盘占满问题解决(/dev/sda3 满了),希望碰到此类问题的人能带来帮助. 今天下班某电商技术部leader发现个问题,说他们服务器硬盘满了.把日志文件都删掉了,可硬盘空间依旧满.于是df -h查看了下各个挂载点的状况(如下图). /dev/sda3占用了100%,那么我们du -s -h ./*看下目录的占用情况(如下图). 在工作中,我们也许会遇到这样的问题,发现某个磁盘空间快满了,于是,找到一些无用的大文件将其删除后,发现磁盘空间还是没有释放掉,
-
PHP在Windows IIS上传的图片无法访问的解决方法
PHP在Windows IIS上传的图片无法访问的解决方法 首先登录到网站后台进行了测试发现上传的图片在确实浏览器打不开且出现了无法访问的错误信息:" 401 - 未 授权: 由于凭据无效,访问被拒绝." 然后又测试了该服务器上其他几个php项目发现也出现了一样的错误: 图片上传成功,但浏览器没有权限访问. 因为测试的几个php系统是不一样的,有thinkphp,wordpress,百度ueditor编辑器. 所以这几个系统同时出现问题的概率实在是太小了,所以基本上排除了程序的bug,
-
Linux磁盘空间被未知资源耗尽的解决方法
在linux中,当我们使用rm在linux上删除了大文件,但是如果有进程打开了这个大文件,却没有关闭这个文件的句柄,那么linux内核还是不会释放这个文件的磁盘空间,最后造成磁盘空间占用100%,整个系统无法正常运行.这种情况下,通过df和du命令查找的磁盘空间,两者是无法匹配的,可能df显示磁盘100%,而du查找目录的磁盘容量占用却很小. 遇到这种情况,基本可以断定是某些大文件被某些程序占用了,并且这些大文件已经被删除了,但是对应的文件句柄没有被某些程序关闭,造成内核无法回收这些文件占用的空
-
iOS APP中保存图片到相册时崩溃的解决方法
环境: iPhone Version 11.0.3 , Xcode Version 9.0 问题: 昨天维护APP时,发现拍照后保存图片时应用崩溃,输出如下: This app has crashed because it attempted to access privacy-sensitive data without a usage description. The app's Info.plist must contain an NSPhotoLibraryAddUsageDescr
-
Linux中没有rc.local文件的完美解决方法
比较新的Linux发行版已经没有rc.local文件了.因为已经将其服务化了. 解决方法: 1.设置rc-local.service sudo vim /etc/systemd/system/rc-local.service [Unit] Description=/etc/rc.local Compatibility ConditionPathExists=/etc/rc.local [Service] Type=forking ExecStart=/etc/rc.local start Tim
-
windows下上传shell脚本不能运行的解决方法
windows下上传shell脚本至linux,其格式将为dos.dos模式的shell脚本将不能再linux下正确运行,需要修改文件模式为unix. 1 查看文件模式方法 linux服务器上,用vi编辑器打开shell脚本,随后进入命令行模式,输入"set ff",即可查看文件模式. 查看文件指令: 显示的文件格式: 2 修改文件模式的方法 在命令行模式下,输入"set ff=unix",即可将dos模式修改为unix模式. 修改文件模式命令: 查看修改后的文件模
-
Flutter项目在 iOS14 启动崩溃的解决方法
Flutter是什么? Flutter是Google一个新的用于构建跨平台的手机App的SDK.写一份代码,在Android 和iOS平台上都可以运行. 下面看下Flutter项目在 iOS14 启动崩溃的问题及解决方法 崩溃现象 在iOS14发布之后,运行APP就出现闪退,和机型没关,只要是iOS 14就必闪退 崩溃分析 1.启动就闪退,多起几次可能有一次没有问题. 2.启动后到某个页面卡死(必卡跳不过) 根本原因尚不明确,个人分析Product Name会影响Header Folder Pa
-
php上传文件中文文件名乱码的解决方法
可能会有不少朋友碰到一些问题就是上传文件时如果是英文倒好原文名不会有问题,如果是中文可能就会出现乱码了,今天我来给大家总结一下导致乱码php上传文件中文文件名乱码的原因与解决办法吧. 这几天在windows下安装了XAMPP,准备初步学习一下php的相关内容.这几天接触到了php上传文件,但是出现了一个郁闷问题,我准备上传一个excel文件,但是如果文件名是中文名就会报错. 一来二去很是郁闷,后来仔细想了想应该是文件编码的问题,我写的php文件使用的是UTF-8编码,如果没有猜错APACHE处理
-
Mysql 服务 1067 错误 的解决方法:修改mysql可执行文件路径
今天遇到mysql服务1067错误的问题,设置使用系统账户也无法启动mysql,后面认证看了系统的配置信息,发现启动文件也就是mysql安装路径是之前的(也说明之前安装mysql,没去卸载直接安装新的会出错),于是打算修改修改mysql可执行文件路径,换成现在的. 但是各种百度,都说的不明确,后面打算放弃了,干脆重装系统,才发现这个可以解决. 第一步:停止服务MySQL 第二步:(控制台:运行->regedit),根据路径HKEY_LOCAL_MACHINE\SYSTEM\CurrentCont