一文教会你用Python获取网页指定内容
目录
- 前言
- 1.抓取网页源代码
- 2.抓取一个网页源代码中的某标签内容
- 3.抓取多个网页子标签的内容
- 总结
前言
Python用做数据处理还是相当不错的,如果你想要做爬虫,Python是很好的选择,它有很多已经写好的类包,只要调用,即可完成很多复杂的功能
在我们开始之前,我们需要安装一些环境依赖包,打开命令行


确保电脑中具有python和pip,如果没有的话则需要自行进行安装
之后我们可使用pip安装必备模块 requests
pip install requests

requests是python实现的简单易用的HTTP库,使用起来比urllib简洁很多,requests 允许你发送 HTTP/1.1 请求。指定 URL并添加查询url字符串即可开始爬取网页信息
1.抓取网页源代码
以该平台为例,抓取网页中的公司名称数据,网页链接:https://www.crrcgo.cc/admin/crr_supplier.html?page=1
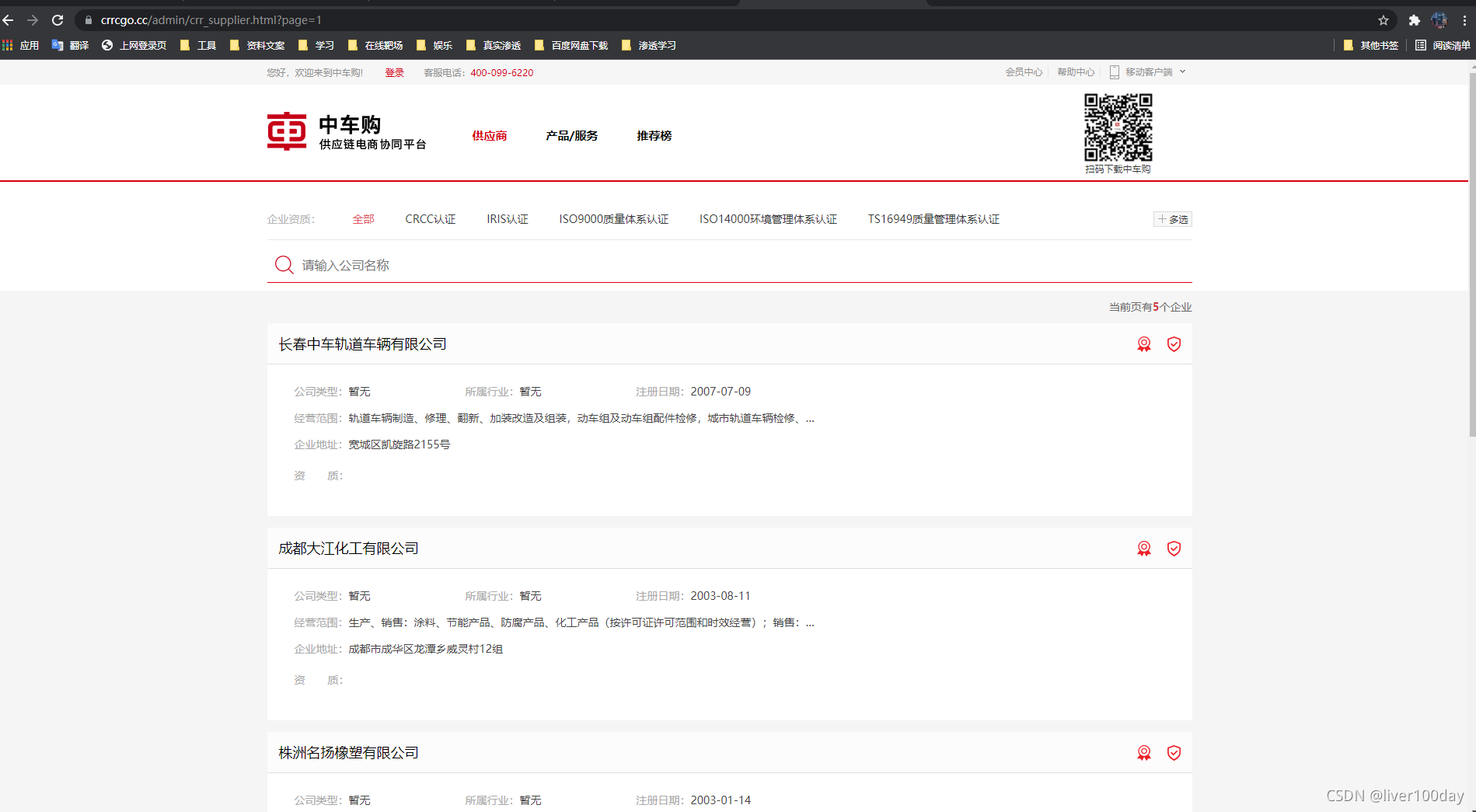
目标网页源代码如下:
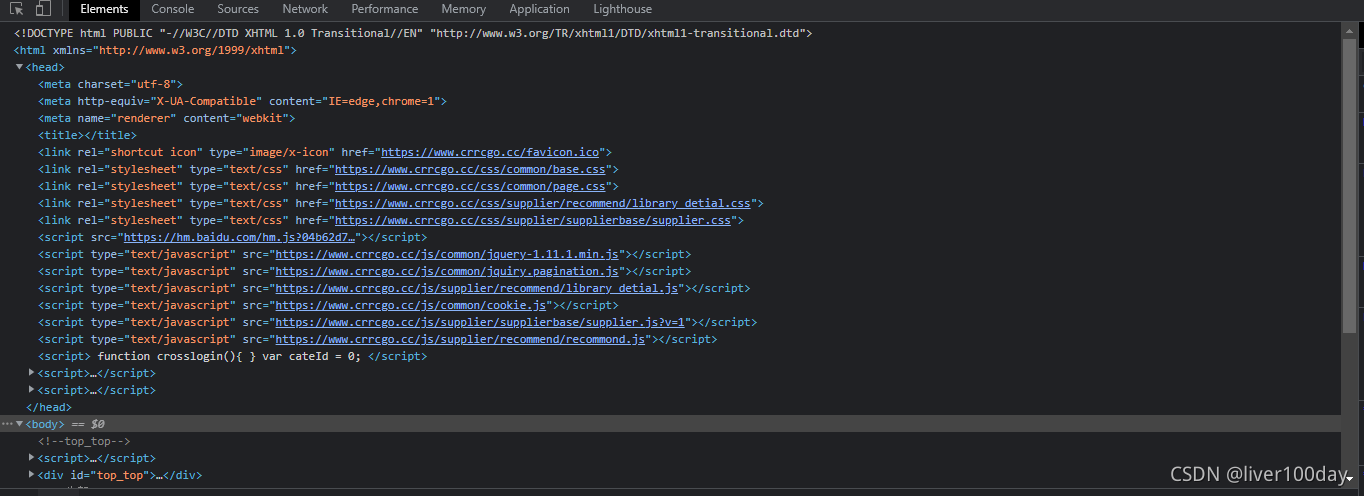
首先明确步骤
1.打开目标站点
2.抓取目标站点代码并输出
import requests
导入我们需要的requests功能模块
page=requests.get('https://www.crrcgo.cc/admin/crr_supplier.html?page=1')
这句命令的意思就是使用get方式获取该网页的数据。实际上我们获取到的就是浏览器打开百度网址时候首页画面的数据信息
print(page.text)
这句是把我们获取数据的文字(text)内容输出(print)出来
import requestspage=requests.get('https://www.crrcgo.cc/admin/crr_supplier.html?page=1')print(page.text)
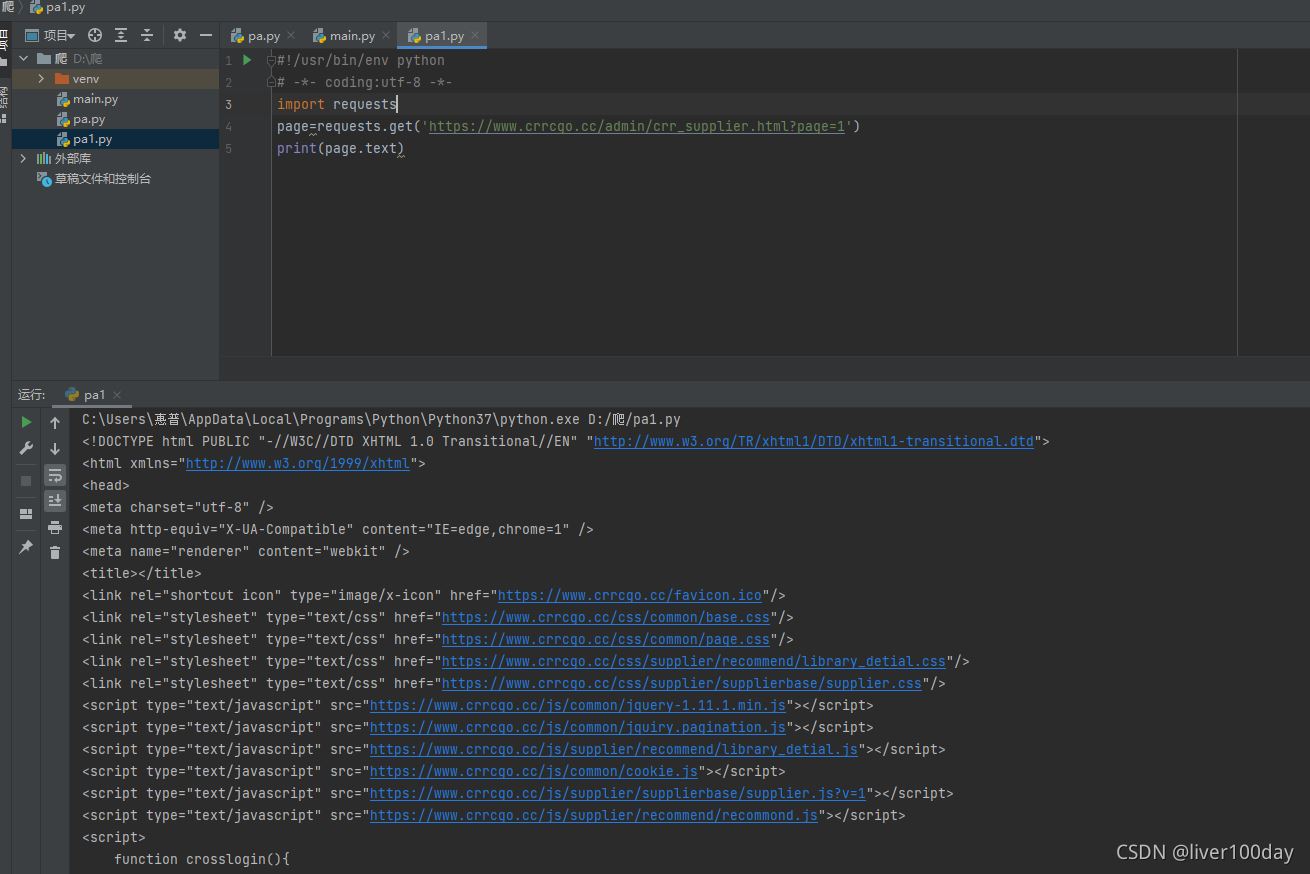
成功爬取到了目标网页源代码
2.抓取一个网页源代码中的某标签内容
但是上面抓取到的代码充满尖括号的一片字符,对我们没有什么作用,这样的充满尖括号的数据就是我们从服务器收到的网页文件,就像Office的doc、pptx文件格式一样,网页文件一般是html格式。我们的浏览器可以把这些html代码数据展示成我们看到的网页。
我们如果需要这些字符里面提取有价值的数据,就必须先了解标记元素
每个标记的文字内容都是夹在两个尖括号中间的,结尾尖括号用/开头,尖括号内(img和div)表示标记元素的类型(图片或文字),尖括号内可以有其他的属性(比如src)
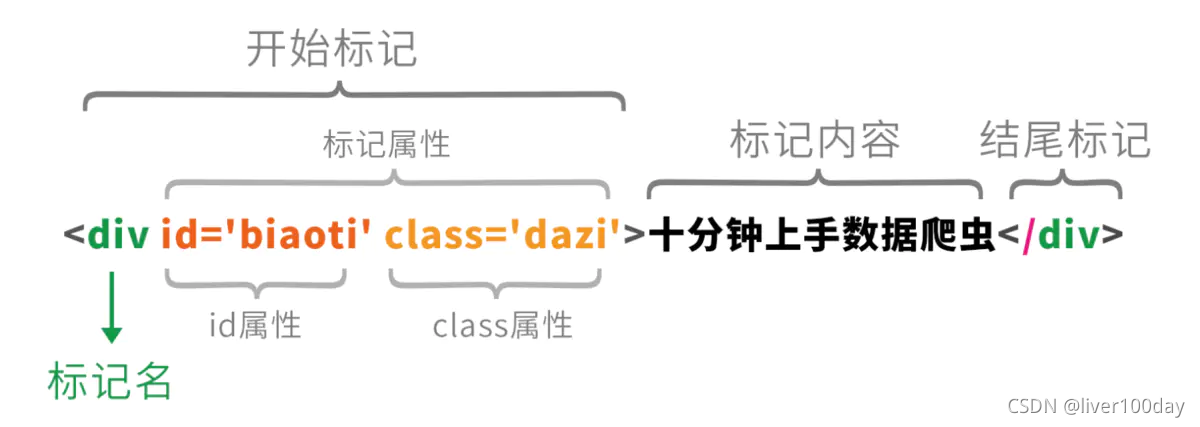
标记内容文字才是我们需要的数据,但我们要利用id或class属性才能从众多标记中找到需要的标记元素。
我们可以在电脑浏览器中打开任意网页,按下f12键即可打开元素查看器(Elements),就可以看到组成这个页面的成百上千个各种各样的标记元素
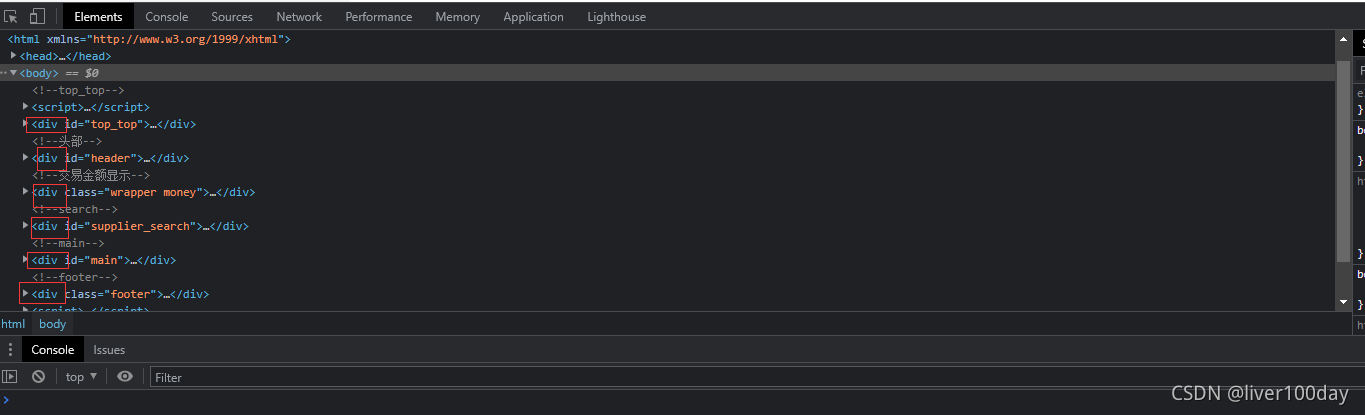
标记元素是可以一层一层嵌套的,比如下面就是body嵌套了div元素,body是父层、上层元素;div是子层、下层元素。
<body>
<div>十分钟上手数据爬虫</div>
</body>
回到抓取上面来,现在我只想在网页中抓取公司名这个数据,其他的我不想要
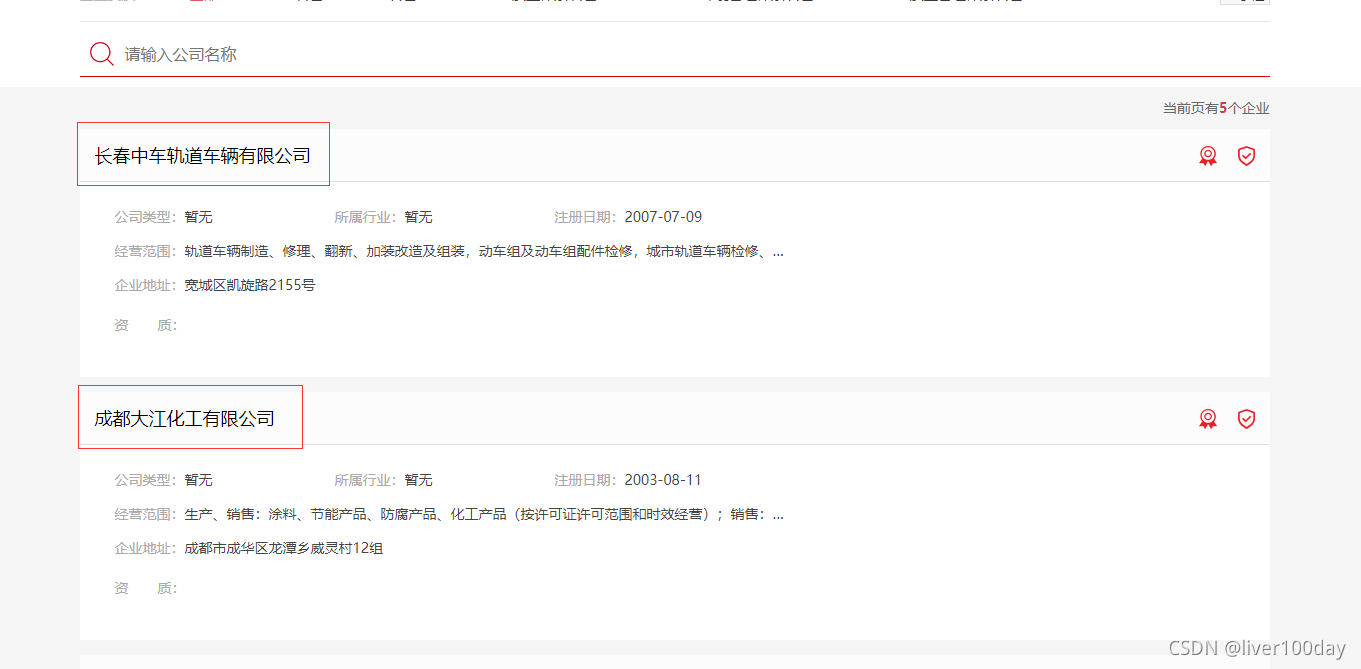
查看网页html代码,发现公司名在标签detail_head里面

import requests
req=requests.get('https://www.crrcgo.cc/admin/crr_supplier.html?page=1')
这两行上面解释过了,是获取页面数据
from bs4 import BeautifulSoup
我们需要使用BeautifulSoup这个功能模块来把充满尖括号的html数据变为更好用的格式,from bs4 import BeautifulSoup这个是说从bs4这个功能模块中导入BeautifulSoup,是的,因为bs4中包含了多个模块,BeautifulSoup只是其中一个
req.encoding = "utf-8"
指定获取的网页内容用utf-8编码
soup = BeautifulSoup(html.text, 'html.parser')
这句代码用html解析器(parser)来分析我们requests得到的html文字内容,soup就是我们解析出来的结果。
company_item=soup.find_all('div',class_="detail_head")
find是查找,find_all查找全部。查找标记名是div并且class属性是detail_head的全部元素
dd = company_item.text.strip()
strip() 方法用于移除字符串头尾指定的字符(默认为空格或换行符)或字符序列。在这里就是移除多余的尖括号的html数据
最后拼接之后代码如下:
import requests
from bs4 import BeautifulSoup
req = requests.get(url="https://www.crrcgo.cc/admin/crr_supplier.html?page=1")
req.encoding = "utf-8"
html=req.text
soup = BeautifulSoup(req.text,features="html.parser")
company_item = soup.find("div",class_="detail_head")
dd = company_item.text.strip()
print(dd)
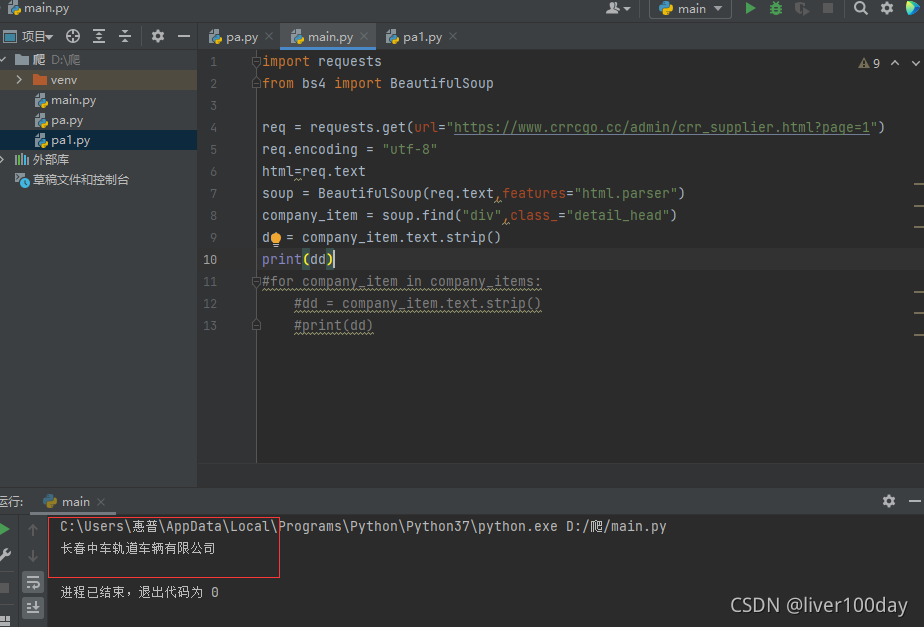
最后执行结果成功的抓取到了网页中我们想要的公司信息,但是却只抓取到了一个公司,其余的则并未抓取到
所以我们需要加入一个循环,抓取网页中所有公司名,并没多大改变
for company_item in company_items:
dd = company_item.text.strip()
print(dd)
最终代码如下:
import requests
from bs4 import BeautifulSoup
req = requests.get(url="https://www.crrcgo.cc/admin/crr_supplier.html?page=1")
req.encoding = "utf-8"
html=req.text
soup = BeautifulSoup(req.text,features="html.parser")
company_items = soup.find_all("div",class_="detail_head")
for company_item in company_items:
dd = company_item.text.strip()
print(dd)

最终运行结果查询出了该网页中所有的公司名
3.抓取多个网页子标签的内容
那我现在想要抓取多个网页中的公司名呢?很简单,大体代码都已经写出,我们只需要再次加入一个循环即可
查看我们需要进行抓取的网页,发现当网页变化时,就只有page后面的数字会发生变化。当然很多大的厂商的网页,例如京东、淘宝 它们的网页变化时常让人摸不着头脑,很难猜测。
inurl="https://www.crrcgo.cc/admin/crr_supplier.html?page="
for num in range(1,6):
print("================正在爬虫第"+str(num)+"页数据==================")
写入循环,我们只抓取1到5页的内容,这里的循环我们使用range函数来实现,range函数左闭右开的特性使得我们要抓取到5页必须指定6
outurl=inurl+str(num)
req = requests.get(url=outurl)
将循环值与url拼接成完整的url,并获取页面数据
完整代码如下:
import requests
from bs4 import BeautifulSoup
inurl="https://www.crrcgo.cc/admin/crr_supplier.html?page="
for num in range(1,6):
print("================正在爬虫第"+str(num)+"页数据==================")
outurl=inurl+str(num)
req = requests.get(url=outurl)
req.encoding = "utf-8"
html=req.text
soup = BeautifulSoup(req.text,features="html.parser")
company_items = soup.find_all("div",class_="detail_head")
for company_item in company_items:
dd = company_item.text.strip()
print(dd)
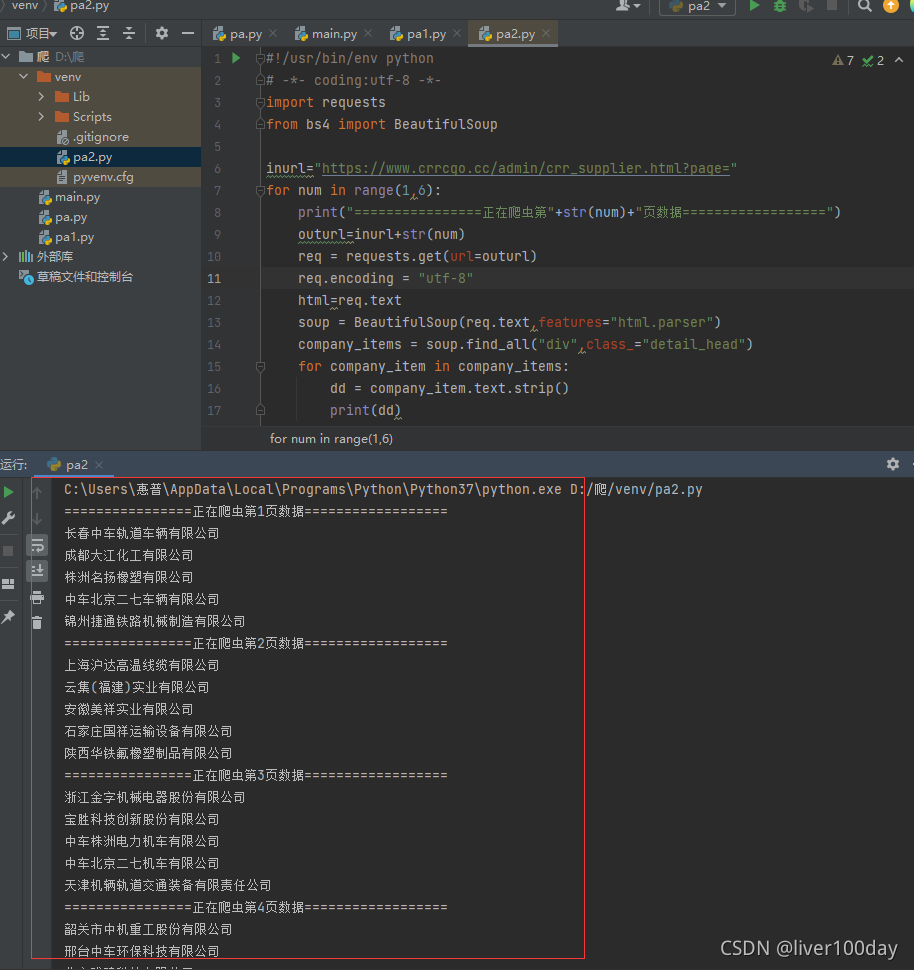
成功的抓取到了1-5页所有的公司名(子标签)内容
总结
到此这篇关于Python获取网页指定内容的文章就介绍到这了,更多相关Python获取网页指定内容内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python使用selenium + headless chrome获取网页内容的方法示例
使用python写爬虫时,优选selenium,由于PhantomJS因内部原因已经停止更新,最新版的selenium已经使用headless chrome替换掉了PhantomJS,所以建议将selenium更新到最新版,使用selenium + headless chrome 准备工作: 安装chrome.chrome driver.selenium 一.安装chrome 配置yum下载源,在目录/etc/yum.repos.d/下新建文件google-chrome.repo > cd /e
-

一文教会你用Python获取网页指定内容
目录 前言 1.抓取网页源代码 2.抓取一个网页源代码中的某标签内容 3.抓取多个网页子标签的内容 总结 前言 Python用做数据处理还是相当不错的,如果你想要做爬虫,Python是很好的选择,它有很多已经写好的类包,只要调用,即可完成很多复杂的功能在我们开始之前,我们需要安装一些环境依赖包,打开命令行 确保电脑中具有python和pip,如果没有的话则需要自行进行安装 之后我们可使用pip安装必备模块 requests pip install requests requests是python
-
Python获取网页数据详解流程
Requests 库是 Python 中发起 HTTP 请求的库,使用非常方便简单. 发送 GET 请求 当我们用浏览器打开东旭蓝天股票首页时,发送的最原始的请求就是 GET 请求,并传入url参数. import requests url='http://push2his.eastmoney.com/api/qt/stock/fflow/daykline/get' 用Python requests库的get函数得到数据并设置requests的请求头. header={ 'User-Agent'
-
Python获取网页上图片下载地址的方法
本文实例讲述了Python获取网页上图片下载地址的方法.分享给大家供大家参考.具体如下: 这里获取网页上图片的下载地址是正在写的数据采集中的一段,代码如下: 复制代码 代码如下: #!/user/bin/python3 import urllib2 from HTMLParser import HTMLParser class MyHtmlParser(HTMLParser): links = [] def handle_starttag(self, tag, attrs):
-
python 获取网页编码方式实现代码
python 获取网页编码方式实现代码 <span style="font-family: Arial, Helvetica, sans-serif; background-color: rgb(255, 255, 255);"> </span><span style="font-family: Arial, Helvetica, sans-serif; background-color: rgb(255, 255, 255);">
-
python获取网页中所有图片并筛选指定分辨率的方法
压测时,图片太少,想着下载网页中的图片,然后过滤指定分辨率,但网页中指定分辨率的图片太少了(见下) 后使用格式工厂转换图片 import urllib.request # 导入urllib模块 import re # 导入re模块 import os from PIL import Image htmlurl = 'http://www.win4000.com/wallpaper_detail_134824_3.html' downloadpath = 'C:\\Users\\yaowanjun
-
python基于BeautifulSoup实现抓取网页指定内容的方法
本文实例讲述了python基于BeautifulSoup实现抓取网页指定内容的方法.分享给大家供大家参考.具体实现方法如下: # _*_ coding:utf-8 _*_ #xiaohei.python.seo.call.me:) #win+python2.7.x import urllib2 from bs4 import BeautifulSoup def jd(url): page = urllib2.urlopen(url) html_doc = page.read() soup = B
-
python 获取剪切板内容的两种方法
第一种 # -*- coding: utf-8 -*- # @Time : 2020/3/16 21:26 # @File : get_text_from_cupboard_13.py # @Author: Hero Liu # python读取剪切板内容 import win32clipboard as w import win32con def get_text(): w.OpenClipboard() d = w.GetClipboardData(win32con.CF_TEXT) w.C
-
Python提取PDF指定内容并生成新文件
在之前的Python办公自动化案专题中,我们已经介绍了如何有选择的提取某些页面进行合并. 但是很多时候,我们并不会预知希望提取的页号,而是希望将包含指定内容的页面提取合并为新PDF,本文就以两个真实需求为例进行讲解. 01需求描述 数据是一份有286页的上市公司公开年报PDF,大致如下 现在需要利用 Python 完成以下两个需求 " 需求一:提取所有包含 战略 二字的页面并合并新PDF 需求二:提取所有包含图片的页面,并分别保存为 PDF 文件 " 02前置知识和逻辑梳理 2.1 P
-
python获取网页状态码示例
代码很简单,只需要2行代码就可实现想要的功能,虽然很短,但确实使用,主要使用了requests库. 测试2XX, 3XX, 4XX, 5XX都能准确识别. 复制代码 代码如下: #coding=utf-8 import requests def getStatusCode(url): r = requests.get(url, allow_redirects = False) return r.status_codeprint getStatusCode('http://www.jb51.net
-
asp获取远程网页的指定内容的实现代码
代码如下: 复制代码 代码如下: <% '用ASP获取远程目标网页指定内容,代码由广州网站建设http://www.jb51.net提供 On Error Resume Next Server.ScriptTimeOut=9999999 Function getHTTPPage(Path) t = GetBody(Path) getHTTPPage=BytesToBstr(t,"GB2312") End function Function Newstring(wstr,strng