PostgreSQL聚合函数的分组排序使用示例
聚合函数
用于汇总的函数。
COUNT
COUNT,计算表中的行数(记录数)。
计算全部数据的行数:
SELECT COUNT(*) FROM Product;
NULL之外的数据行数:
SELECT COUNT(purchase_price) FROM Product;结果如下图。
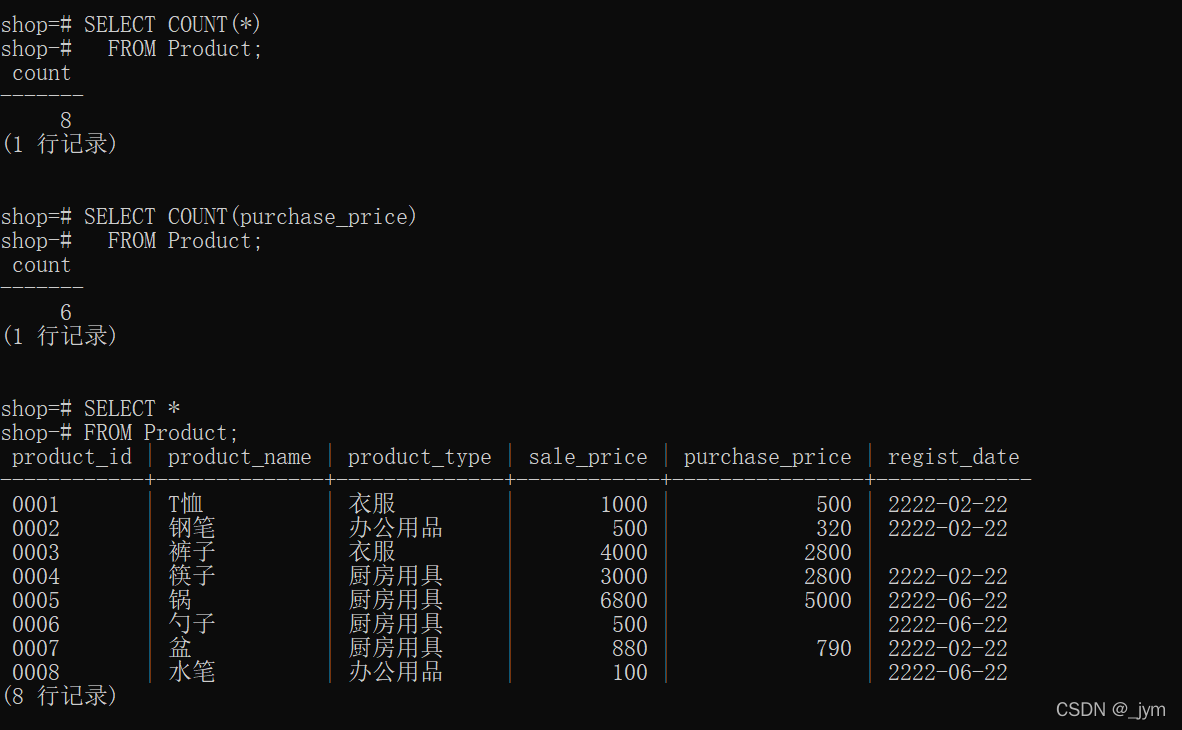
对于一个含NULL的表:
将列名作为参数,得到NULL之外的数据行数;将星号作为参数,得到所有数据的行数(包含NULL)。
SUM、AVG
SUM、AVG函数只能对数值类型的列使用。
SUM,求表中的数值列的数据的和。
SELECT SUM(sale_price) FROM Product;purchase_price里面的数据有NULL,四则运算中存在NULL,结果也是NULL,但这里面结果不是NULL。
这是因为,聚合函数以列名为参数,计算的时候会排除NULL的数据。
SELECT SUM(sale_price), SUM(purchase_price) FROM Product;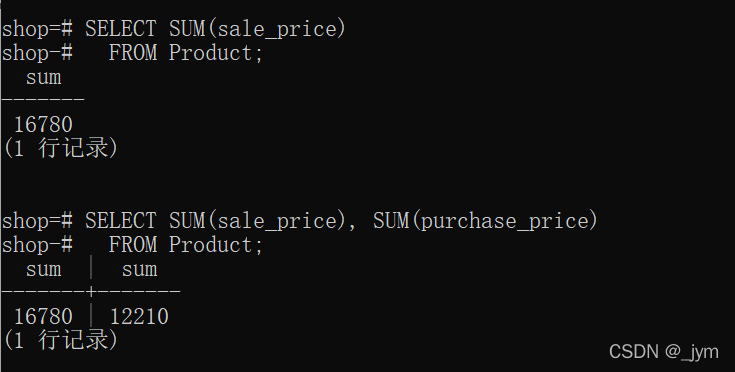
AVG,求表中的数值列的数据的平均值。
SELECT AVG(sale_price) FROM Product;对于列里面数据有NULL的,会事先去掉NULL再计算。如AVG(purchase_price),分母是6而不是8。
SELECT AVG(sale_price), AVG(purchase_price) FROM Product;
MAX、MIN
MAX,求表中任意列数据最大值。
MIN,求表中任意列数据最小值。
SELECT MAX(sale_price), MIN(purchase_price) FROM Product;SELECT MAX(regist_date), MIN(regist_date) FROM Product;
聚合函数+DISTINCT
计算去除重复数据后的数据行数:
DISTINCT要写在括号中,目的是在计算行数前先去重。
SELECT COUNT(DISTINCT product_type) FROM Product;
所有的聚合函数的参数中都可以使用DISTINCT。
下面这个SUM(DISTINCT sale_price),先把sale_price里面的数据去重,然后再求和。
SELECT SUM(sale_price), SUM(DISTINCT sale_price) FROM Product;GROUP BY
对表分组:前面使用聚合函数,对表中所有数据进行汇总处理。
还可以先把表分成几组,再进行汇总处理。
格式:
SELECT <列名1>,<列名2>,...FROM <表名>GROUP BY <列名1>,<列名2>,...;按商品种类统计数据:
使用GROUP BY product_type,会按商品种类对表切分。
GROUP BY指定的列,称为聚合键、分组列。
SELECT product_type, COUNT(*) FROM Product GROUP BY product_type;按商品种类对表切分,得到以商品种类为分界的三组数据,然后,计算每种商品数据行数。
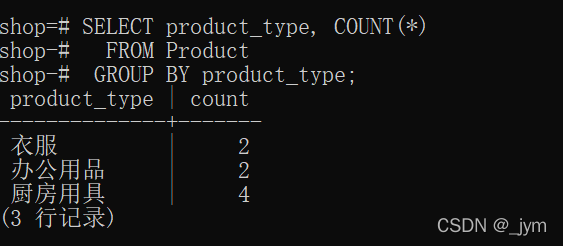
如果聚合键里面含有NULL,也将NULL作为一组特定数据。
SELECT purchase_price, COUNT(*) FROM Product GROUP BY purchase_price;
如果加上WHERE子句,格式如下:
SELECT <列名1>,<列名2>,...FROM <表名>WHEREGROUP BY <列名1>,<列名2>,...;先根据WHERE子句指定的条件进行筛选,然后再汇总处理。
下面语句的执行顺序:FROM、WHERE、GROUP BY、SELECT。
SELECT purchase_price, COUNT(*) FROM Product WHERE product_type = '衣服' GROUP BY purchase_price;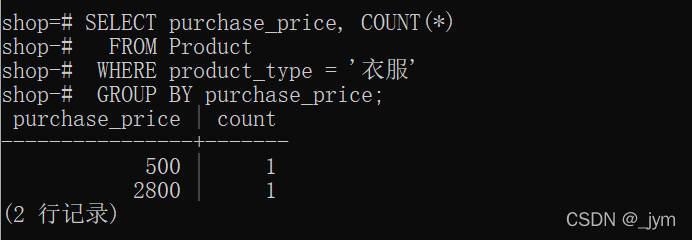
使用聚合函数和GROUP BY时需要注意:
1.SELECT子句中,只能存在三种元素:常数、聚合函数、GROPU BY子句指定的列名(聚合键)。
使用GROPU BY子句时,SELECT子句中不能出现聚合键之外的列名。
2.GROUP BY子句里面不能使用SELECT子句中定义的别名。
这是因为SQL语句在DBMS内部先执行GROUP BY子句,再执行SELECT子句。执行GROUP BY子句时候,DBMS还不知道别名代表的是啥,因为别名是在SELECT子句里面定义的。
3.GROUP BY子句执行结果的显示顺序是无序的。
4.只有SELECT子句、HAVING子句、ORDER BY子句里面能使用聚合函数。
HAVING
使用GROPU BY子句,得到将表分组后的结果。
使用HAVING子句,指定分组的条件,从分组后的结果里面选取特定的组。
格式:
SELECT <列名1>,<列名2>,...FROM <表名>WHEREGROUP BY <列名1>,<列名2>,...;HAVING <分组结果对应的条件>下面这个,选出包含两行数据的组。
SELECT product_type, COUNT(*) FROM Product GROUP BY product_typeHAVING COUNT(*) = 2;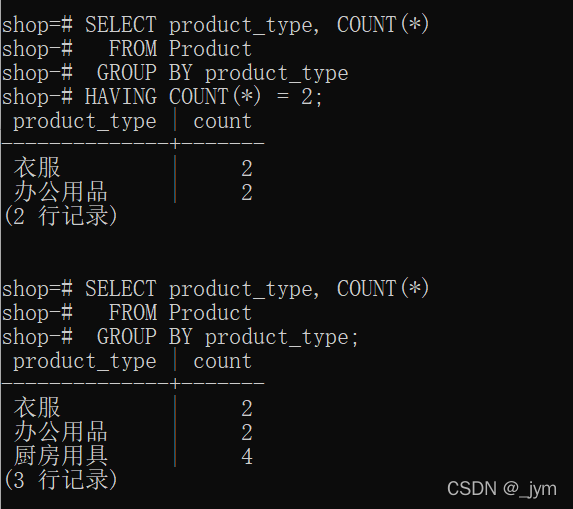
下面这个,选出平均值>=2500的组。
SELECT product_type, AVG(sale_price) FROM Product GROUP BY product_typeHAVING AVG(sale_price) >= 2500;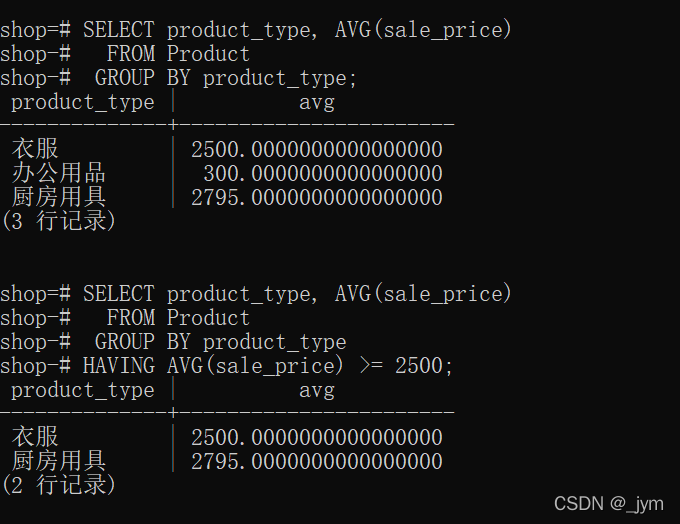
HAVING子句中,能用的三种元素:常数、聚合函数、GROPU BY子句指定的列名(聚合键)。
聚合键所对应的一些条件,可以写在HAVING子句中,也可写在WHERE子句中。
下面两段代码结果都一样。
HAVING子句用来指定组的条件。WHERE子句用来指定数据行的条件。聚合键所对应的一些条件还是写在WHERE子句中好点。
SELECT product_type, COUNT(*) FROM Product GROUP BY product_typeHAVING product_type = '衣服';SELECT product_type, COUNT(*) FROM ProductWHERE product_type = '衣服' GROUP BY product_type;
ORDER BY
使用ORDER BY子句,可以对查询结果进行排序。
格式:
SELECT <列名1>,<列名2>,...FROM <表名>ORDER BY <排序基准列1>,<排序基准列2>,...;ORDER BY子句写在SELECT语句末尾。
ORDER BY子句里面的列名称为排序键。
使用升序排列,使用ASC关键字,省略这个关键字,默认也是升序排列。
SELECT product_id, product_name, sale_price, purchase_price FROM ProductORDER BY sale_price;上面是升序排列,如果想要降序排列,使用DESC关键字。
SELECT product_id, product_name, sale_price, purchase_price FROM ProductORDER BY sale_price DESC;
上面的排序,sale_price=500的有两个数据,这两个数据的顺序是随机的。
可以再添加一个排序键,对这两个数据排序。
下面就实现了,价格相同时,按照商品编号升序排序。
多个排序键时,优先使用左边的键,该列存在相同值,再参考右边的键。
SELECT product_id, product_name, sale_price, purchase_price FROM ProductORDER BY sale_price, product_id;
如果,排序键里面有数据是NULL,NULL会在结果的开头或结尾显示。
SELECT product_id, product_name, sale_price, purchase_price FROM ProductORDER BY purchase_price;
ORDER BY子句里面可以使用SELECT子句中定义的别名。
这是由SQL语句在DBMS内部执行顺序决定的。SELECT子句执行顺序在ORDER BY前,GROPU BY后。
FROM、WHERE、GROPU BY、HAVING、SELECT、ORDER BY
SELECT product_id AS id, product_name, sale_price AS sp, purchase_price FROM ProductORDER BY sp, id;
ORDER BY子句可以使用在表里,但不在SELECT子句里的列。
SELECT product_name, sale_price, purchase_price FROM ProductORDER BY product_id;ORDER BY子句里面可以使用聚合函数。
SELECT product_type, COUNT(*) FROM Product GROUP BY product_typeORDER BY COUNT(*);以上就是PostgreSQL聚合函数的分组排序使用示例的详细内容,更多关于PostgreSQL聚合函数分组排序的资料请关注我们其它相关文章!
相关推荐
-
PostgreSQL的中文拼音排序案例
前一段时间开发人员咨询,说postgresql里面想根据一个字段做中文的拼音排序,但是不得其解 环境: OS:CentOS 6.3 DB:PostgreSQL 9.2.4 TABLE: tbl_kenyon 场景: postgres=# \d tbl_kenyon Table "public.tbl_kenyon" Column | Type | Modifiers --------+------+--------------- vname | text | --使用排序后的结果,不是
-

postgresql 实现取出分组中最大的几条数据
看代码吧~ WITH Name AS ( SELECT * FROM ( SELECT xzqdm, SUBSTRING (zldwdm, 1, 9) xzdm, COUNT (*) sl FROM sddltb_qc WHERE xzqdm IN ('130432', '210604') GROUP BY xzqdm, SUBSTRING (zldwdm, 1, 9) ) AS A ORDER BY xzqdm, xzdm, sl ) SELECT xzqdm, xzdm, sl FROM (
-
postgresql使用filter进行多维度聚合的解决方法
你有没有碰到过有这样一种场景,就是我们需要看一下某个时间段内各种维度的汇总,比如这样:最近三年我们卖了多少货?有多少订单?平均交易价格多少?每个店铺卖了多少?交易成功的订单有多少?交易失败的订单有多少? 等等...,假使这些数据的明细都在一个表内,该这么做呢? 有没有简单方式?还有如何减少全表扫描以更改的拿到数据? 如果只是简单的利用聚合拿到数据可能您需要写很多sql,具体表现为每一个问题写一段sql 相互之间join起来,这样也许是个好主意,不过对于未充分优化的数据库系统,针对每一块的问题求解
-
Postgresql排序与limit组合场景性能极限优化详解
1 构造测试数据 create table tbl(id int, num int, arr int[]); create index idx_tbl_arr on tbl using gin (arr); create or replace function gen_rand_arr() returns int[] as $$ select array(select (1000*random())::int from generate_series(1,64)); $$ language sq
-
postgreSql分组统计数据的实现代码
1. 背景 比如气象台的气温监控,每半小时上报一条数据,有很多个地方的气温监控,这样数据表里就会有很多地方的不同时间的气温数据 2. 需求: 每次查询只查最新的气温数据按照不同的温度区间来分组查出,比如:高温有多少地方,正常有多少地方,低温有多少地方 3. 构建数据 3.1 创建表结构: -- DROP TABLE public.t_temperature CREATE TABLE public.t_temperature ( id int4 NOT NULL GENERATED ALWAYS
-
PostgreSQL聚合函数的分组排序使用示例
聚合函数 用于汇总的函数. COUNT COUNT,计算表中的行数(记录数). 计算全部数据的行数: SELECT COUNT(*) FROM Product; NULL之外的数据行数: SELECT COUNT(purchase_price) FROM Product; 结果如下图. 对于一个含NULL的表: 将列名作为参数,得到NULL之外的数据行数:将星号作为参数,得到所有数据的行数(包含NULL). SUM.AVG SUM.AVG函数只能对数值类型的列使用. SUM,求表中的数值列的数据
-
django 中的聚合函数,分组函数,F 查询,Q查询
先以mysql的语句,聚合用在分组里, 对mysql中groupby 是分组 每什么的时候就要分组,如 每个小组,就按小组分, group by 字段 having 聚合函数 #举例 :求班里的平均成绩, select Avg(score) from stu 在django中 聚合 是aggreate(*args,**kwargs),通过QuerySet 进行计算.做求值运算的时候使用 分组 是annotate(*args,**kwargs),括号里是条件,遇到 每什么的时候就要分组, 先从mo
-
MySQL 分组查询和聚合函数
概述 相信我们经常会遇到这样的场景:想要了解双十一天猫购买化妆品的人员中平均消费额度是多少(这可能有利于对商品价格区间的定位):或者不同年龄段的化妆品消费占比是多少(这可能有助于对商品备货量的预估). 这个时候就要用到分组查询,分组查询的目的是为了把数据分成多个逻辑组(购买化妆品的人员是一个组,不同年龄段购买化妆品的人员也是组),并对每个组进行聚合计算的过程:. 分组查询的语法格式如下: select cname, group_fun,... from tname [where conditio
-
SQL分组函数group by和聚合函数(COUNT、MAX、MIN、AVG、SUM)的几点说明
1 分组聚合的原因 SQL中分组函数和聚合函数之前的文章已经介绍过,单说这两个函数有可能比较好理解,分组函数就是group by,聚合函数就是COUNT.MAX.MIN.AVG.SUM. 拿上图中的数据进行解释,假设按照product_type这个字段进行分组,分组之后结果如下图. SELECT product_type from productgroup by product_type 从图中可以看出被分为了三组,分别为厨房用具.衣服和办公用品,就相当于对product_type这个字段进行了
-
Python Pandas聚合函数的应用示例
目录 Python Pandas聚合函数 应用聚合函数 1) 对整体聚合 2) 对任意某一列聚合 3) 对多列数据聚合 4) 对单列应用多个函数 5) 对不同列应用多个函数 6) 对不同列应用不同函数 总结 Python Pandas聚合函数 在前一节,我们重点介绍了窗口函数.我们知道,窗口函数可以与聚合函数一起使用,聚合函数指的是对一组数据求总和.最大值.最小值以及平均值的操作,本节重点讲解聚合函数的应用. 应用聚合函数 首先让我们创建一个 DataFrame 对象,然后对聚合函数进行应用.
-
聚合函数和group by的关系详解
目录 前言 聚合函数介绍 group by介绍 解释聚合函数和group by的关系 使用group by和聚合函数需要注意的地方 总结 前言 world:世界表格continent:大洲名称name:国家名称population:人口数量 聚合函数介绍 sum() 求和函数 avg() 求平均值函数 max() 求最大值函数 min() 求最小值函数 count() 求行数函数 group by介绍 group up + 字段名:规定哪个字段分组聚合在单独使用使用时,作用为分组去重 结果与di
-
MySQL单表查询操作实例详解【语法、约束、分组、聚合、过滤、排序等】
本文实例讲述了MySQL单表查询操作.分享给大家供大家参考,具体如下: 语法 一.单表查询的语法 SELECT 字段1,字段2... FROM 表名 WHERE 条件 GROUP BY field HAVING 筛选 ORDER BY field LIMIT 限制条数 二.关键字的执行优先级(重点) 重点中的重点:关键
-
SQL学习笔记四 聚合函数、排序方法
聚合函数 count,max,min,avg,sum... select count (*) from T_Employee select Max(FSalary) from T_Employee 排序 ASC升序 DESC降序 select * from T_Employee order by Fage 先按年龄降序排列.如果年龄相同,则按薪水升序排列 select * from T_Employee order by FAge DESC,FSalary ASC order by 要放在 wh
-
mongoDB中聚合函数java处理示例详解
1.问题 最近在做项目的时候碰到一个对mongoDB的数据处理,从MongoDB中拿到内嵌文档的时间排序的list. 一开始考虑到直接对mongoDB中的属性排序,后面发现属性存在内嵌文档中,所以处理中需要用到聚合函数. 思考 (key)解决这个问题的过程让我学到很多,发现自己在解决一个问题不仅查找问题的姿势不对,浪费太多时间.而且在碰到问题之后,应该多看看解决办法,甚至解决了之后要去思考问题,回顾问题.而不是像以前一样,解决问题了就万事大吉,抛之脑后. 2.解决 需要对document中的一个
-
Pandas聚合运算和分组运算的实现示例
1.聚合运算 (1)使用内置的聚合运算函数进行计算 1>内置的聚合运算函数 sum(),mean(),max(),min(),size(),describe()...等等 2>应用聚合运算函数进行计算 import numpy as np import pandas as pd #创建df对象 dict_data = { 'key1':['a','b','c','d','a','b','c','d'], 'key2':['one','two','three','one','two','thre