关于Kafka消费者订阅方式
目录
- Kafka消费者订阅方式
- 1.指定主题消费
- 2.指定分区消费
- 3.取消订阅
- Kafka概述
- 定义
- 消息队列
- 1.传统消息队列的应用场景
- 2.消息队列的两种模式
- Kafka 基础架构
Kafka消费者订阅方式
Kafka为消费者提供了三种类型的订阅消费方式:订阅主题集合、正则表达式订阅主题、订阅指定主题的分区集合。三种方式只能使用其中一种。
1.指定主题消费
一个消费者可以使用KafkaConsumer提供的subscribe()方法订阅一个或多个主题,订阅主题集合和正则表达式订阅主题都使用此方法实现的。下面两种方式都可以订阅topic_1120主题。
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
// 订阅主题
consumer.subscribe(Collections.singletonList("topic_1120"));
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
//正则表达式.*代表后续0个或者多个任意字符。
consumer.subscribe(Pattern.compile("topic.*"));
订阅主题在源码中由4个方法重载实现,其中两个带listener的方法是可以自定义Rebalance重平衡的监听类。
@Override
public void subscribe(Collection<String> topics) {
subscribe(topics, new NoOpConsumerRebalanceListener());
}
@Override
public void subscribe(Collection<String> topics, ConsumerRebalanceListener listener) {
//省略源码
}
@Override
public void subscribe(Pattern pattern) {
subscribe(pattern, new NoOpConsumerRebalanceListener());
}
@Override
public void subscribe(Pattern pattern, ConsumerRebalanceListener listener) {
//省略源码
}
2.指定分区消费
消费者指定分区消费是通过KafkaConsumer提供的assign()方法实现的,assign()方法入参为Collection, 其中TopicPartition有2个属性, topic和partition, 分区从0开始编号。使用assign()方法订阅指定主题test_1120分区0的消息。
/订阅指定分区
consumer.assign(Collections.singleton(new TopicPartition("topic_1120", 0)));
3.取消订阅
取消订阅调用unsubscribe()方法。
consumer.unsubscribe();
小结:subscribe()具有自动重平衡的功能,来实现消费负载均衡和故障自动转移,而assign()不具备这种功能。
Kafka概述
定义
Kafka是一个分布式的基于发布/订阅模式的消息队列,主要应用于大数据实时处理领域。
消息队列
1.传统消息队列的应用场景

使用消息队列的好处
1)解耦
允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束。
2)可恢复性
系统的一部分组件失效时,不会影响到整个系统。消息队列降低了进程间的耦合度,所 以即使一个处理消息的进程挂掉,加入队列中的消息仍然可以在系统恢复后被处理。
3)缓冲
有助于控制和优化数据流经过系统的速度,解决生产消息和消费消息的处理速度不一致的情况。
4)灵活性 & 峰值处理能力
在访问量剧增的情况下,应用仍然需要继续发挥作用,但是这样的突发流量并不常见。 如果为以能处理这类峰值访问为标准来投入资源随时待命无疑是巨大的浪费。使用消息队列 能够使关键组件顶住突发的访问压力,而不会因为突发的超负荷的请求而完全崩溃。
5)异步通信
很多时候,用户不想也不需要立即处理消息。消息队列提供了异步处理机制,允许用户 把一个消息放入队列,但并不立即处理它。想向队列中放入多少消息就放多少,然后在需要 的时候再去处理它们。
2.消息队列的两种模式
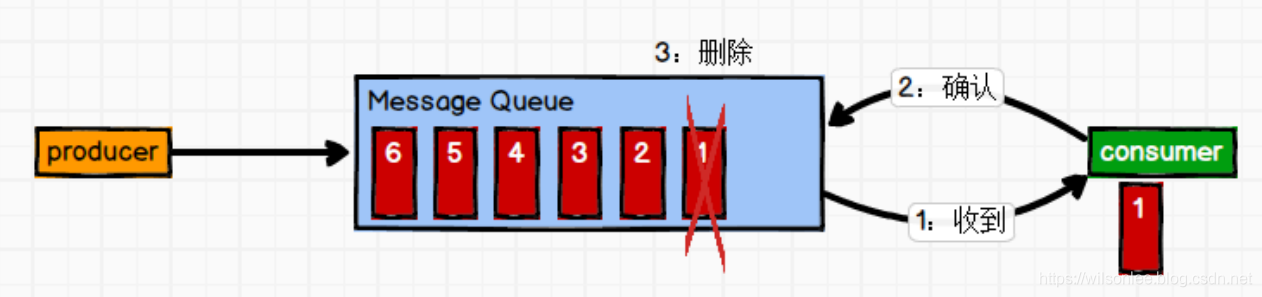
(1)点对点模式(一对一,消费者主动拉取数据,消息收到后消息清除)
消息生产者生产消息发送到Queue中,然后消息消费者从Queue中取出并且消费消息。 消息被消费以后,queue 中不再有存储,所以消息消费者不可能消费到已经被消费的消息。 Queue 支持存在多个消费者,但是对一个消息而言,只会有一个消费者可以消费。
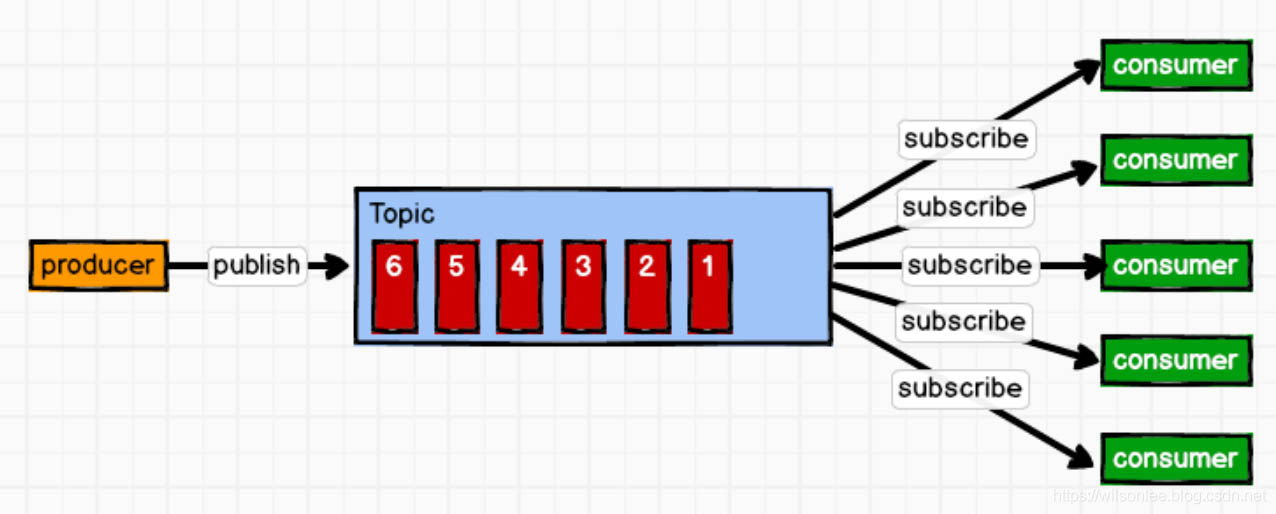
(2)发布/订阅模式(一对多,消费者消费数据之后不会清除消息)
消息生产者(发布)将消息发布到 topic 中,同时有多个消息消费者(订阅)消费该消 息。和点对点方式不同,发布到 topic 的消息会被所有订阅者消费。
Kafka 基础架构
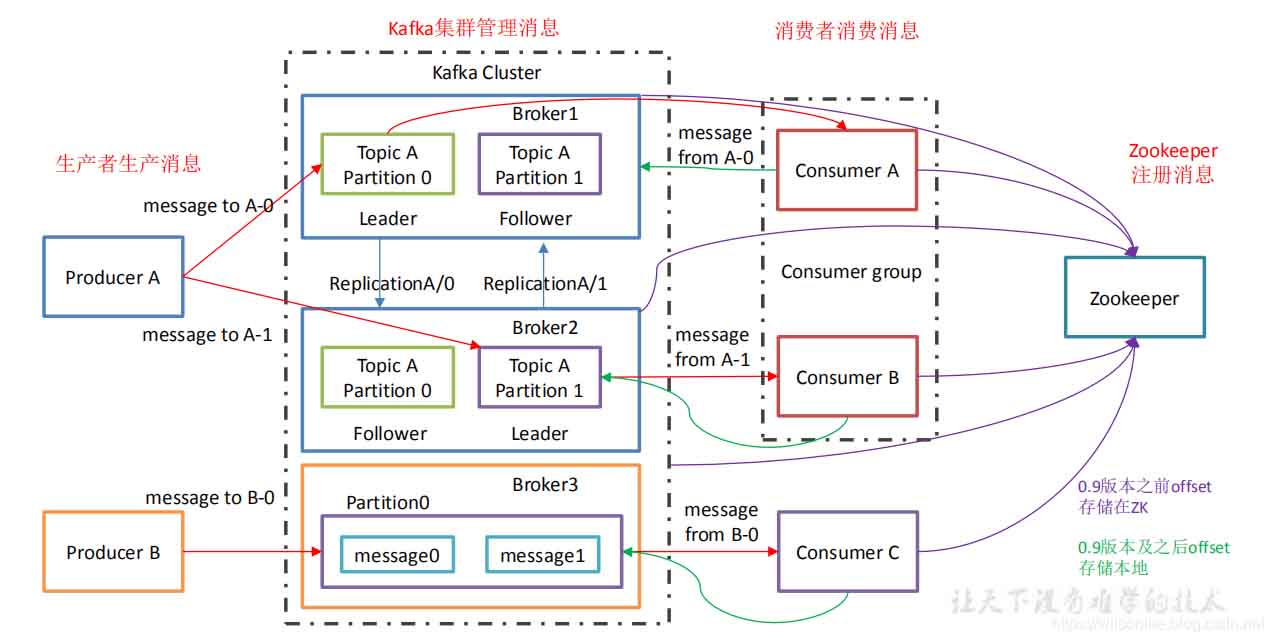
Producer:消息生产者,就是向 kafka broker 发消息的客户端;Consumer:消息消费者,向 kafka broker 取消息的客户端;Consumer Group (CG):消费者组,由多个 consumer 组成。消费者组内每个消费者负 责消费不同分区的数据,一个分区只能由一个组内消费者消费;消费者组之间互不影响。所 有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。Broker:一台 kafka 服务器就是一个 broker。一个集群由多个 broker 组成。一个 broker 可以容纳多个 topic。Topic:可以理解为一个队列,生产者和消费者面向的都是一个 topic;Partition:为了实现扩展性,一个非常大的 topic 可以分布到多个 broker(即服务器)上, 一个 topic 可以分为多个 partition,每个 partition 是一个有序的队列;Replica:副本,为保证集群中的某个节点发生故障时,该节点上的 partition 数据不丢失, 且 kafka 仍然能够继续工作,kafka 提供了副本机制,一个 topic 的每个分区都有若干个副本, 一个 leader 和若干个 follower。leader:每个分区多个副本的“主”,生产者发送数据的对象,以及消费者消费数据的对 象都是 leader。follower:每个分区多个副本中的“从”,实时从 leader 中同步数据,保持和 leader 数据 的同步。leader 发生故障时,某个 follower 会成为新的 follower。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
Java实现Kafka生产者消费者代码实例
Kafka的结构与RabbitMQ类似,消息生产者向Kafka服务器发送消息,Kafka接收消息后,再投递给消费者. 生产者的消费会被发送到Topic中,Topic中保存着各类数据,每一条数据都使用键.值进行保存. 每一个Topic中都包含一个或多个物理分区(Partition),分区维护着消息的内容和索引,它们有可能被保存在不同服务器. 新建一个Maven项目,pom.xml 加入依赖: <dependency> <groupId>org.apache.kafka</gro
-

kafka生产者和消费者的javaAPI的示例代码
写了个kafka的java demo 顺便记录下,仅供参考 1.创建maven项目 目录如下: 2.pom文件: <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://mave
-
Java实现Kafka生产者和消费者的示例
Kafka简介 Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写.Kafka的目标是为处理实时数据提供一个统一.高吞吐.低延迟的平台. 方式一:kafka-clients 引入依赖 在pom.xml文件中,引入kafka-clients依赖: <dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-clients</artifactId
-
使用spring boot 整合kafka,延迟启动消费者
spring boot 整合kafka,延迟启动消费者 spring boot整合kafka的时候一般使用@KafkaListener来设置消费者,但是这种方式在spring启动的时候就会立即开启消费者.如果有需要根据配置信息延迟开启指定的消费者就不能使用这种方式. 参考了类:KafkaListenerAnnotationBeanPostProcessor,我提取了一部分代码.可以根据需要随时动态的开启消费者.还可以很方便的启动多个消费者. 为了方便使用,我自定义了一个注解: import or
-
关于Kafka消费者订阅方式
目录 Kafka消费者订阅方式 1.指定主题消费 2.指定分区消费 3.取消订阅 Kafka概述 定义 消息队列 1.传统消息队列的应用场景 2.消息队列的两种模式 Kafka 基础架构 Kafka消费者订阅方式 Kafka为消费者提供了三种类型的订阅消费方式:订阅主题集合.正则表达式订阅主题.订阅指定主题的分区集合.三种方式只能使用其中一种. 1.指定主题消费 一个消费者可以使用KafkaConsumer提供的subscribe()方法订阅一个或多个主题,订阅主题集合和正则表达式订阅主题都使用
-
kafka消费者kafka-console-consumer接收不到数据的解决
目录 kafka消费者kafka-console-consumer接收不到数据 问题 解决 关于kafka-console-consumer.sh消费者的一些思考 (人物设定初步了解kafka的我) kafka-console-consumer.sh相关知识拓展 总结 kafka消费者kafka-console-consumer接收不到数据 发送端 接收端 问题 采用内置的zookeeper,发送端发送数据,接收端能够接收数据 但是采用外置的zookeeper,发送端发送数据,接收端一直接收不到
-
Kafka利用Java实现数据的生产和消费实例教程
前言 在上一篇中讲述如何搭建kafka集群,本篇则讲述如何简单的使用 kafka .不过在使用kafka的时候,还是应该简单的了解下kafka. Kafka的介绍 Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据. Kafka 有如下特性: 以时间复杂度为O(1)的方式提供消息持久化能力,即使对TB级以上数据也能保证常数时间复杂度的访问性能. 高吞吐率.即使在非常廉价的商用机器上也能做到单机支持每秒100K条以上消息的传输. 支持Kafka Serv
-
深入解析kafka 架构原理
kafka 架构原理 大数据时代来临,如果你还不知道Kafka那就真的out了!据统计,有三分之一的世界财富500强企业正在使用Kafka,包括所有TOP10旅游公司,7家TOP10银行,8家TOP10保险公司,9家TOP10电信公司等等.LinkedIn.Microsoft和Netflix每天都用Kafka处理万亿级的信息.本文就让我们一起来大白话kafka的架构原理. kafka官网:http://kafka.apache.org/ 01 kafka简介 Kafka最初由Linkedin公
-
流式图表拒绝增删改查之kafka核心消费逻辑下篇
目录 前篇回顾 kafka消费者线程 任务提交 前篇回顾 流式图表框架搭建 kafka核心消费逻辑线程池搭建 kafka消费者线程 突击检查八股文,实现线程的方法有哪些?嗯?没复习是吧,行没关系,那感谢参加本次面试哈. 常用的几种方式分别是: 继承Thread类,重写run方法 实现Runbale接口,重写run方法 实现Callable接口,重写call方法 这里我们直接创捷出一个任务类实现Runable方法,重写run方法,一个线程当作一个kafka client,所以要在任务类中声明一个K
-
python操作kafka实践的示例代码
1.先看最简单的场景,生产者生产消息,消费者接收消息,下面是生产者的简单代码. #!/usr/bin/env python # -*- coding: utf-8 -*- import json from kafka import KafkaProducer producer = KafkaProducer(bootstrap_servers='xxxx:x') msg_dict = { "sleep_time": 10, "db_config": { "
-
解决kafka消息堆积及分区不均匀的问题
目录 kafka消息堆积及分区不均匀的解决 1.先在kafka消息中创建 2.添加配置文件application.properties 3.创建kafka工厂 4.展示kafka消费者 kafka出现若干分区不消费的现象 定位过程 验证 解决方法 kafka消息堆积及分区不均匀的解决 我在环境中发现代码里面的kafka有所延迟,查看kafka消息发现堆积严重,经过检查发现是kafka消息分区不均匀造成的,消费速度过慢.这里由自己在虚拟机上演示相关问题,给大家提供相应问题的参考思路. 这篇文章有点
-
springboot分布式整合dubbo的方式
Dubbo是Alibaba开源的分布式服务框架,它最大的特点是按照分层的方式来架构,使用这种方式可以使各个层之间解耦合(或者最大限度地松耦合).从服务模型的角度来看,Dubbo采用的是一种非常简单的模型,要么是提供方提供服务,要么是消费方消费服务,所以基于这一点可以抽象出服务提供方(Provider)和服务消费方(Consumer)两个角色. 1.服务提供者配置 //需要额外引入的jar包 提供者 <dependency> <groupId>com.alibaba.boot<