golang并发工具MapReduce降低服务响应时间
目录
- 前言
- 并发处理工具MapReduce
- MapReduce的用法演示
- MapReduce使用注意事项
- 实现原理分析:
- 文末
前言
在微服务中开发中,api网关扮演对外提供restful api的角色,而api的数据往往会依赖其他服务,复杂的api更是会依赖多个甚至数十个服务。虽然单个被依赖服务的耗时一般都比较低,但如果多个服务串行依赖的话那么整个api的耗时将会大大增加。
那么通过什么手段来优化呢?我们首先想到的是通过并发来的方式来处理依赖,这样就能降低整个依赖的耗时,Go基础库中为我们提供了 WaitGroup 工具用来进行并发控制,但实际业务场景中多个依赖如果有一个出错我们期望能立即返回而不是等所有依赖都执行完再返回结果,而且WaitGroup中对变量的赋值往往需要加锁,每个依赖函数都需要添加Add和Done对于新手来说比较容易出错
基于以上的背景,go-zero框架中为我们提供了并发处理工具MapReduce,该工具开箱即用,不需要做什么初始化,我们通过下图看下使用MapReduce和没使用的耗时对比:

相同的依赖,串行处理的话需要200ms,使用MapReduce后的耗时等于所有依赖中最大的耗时为100ms,可见MapReduce可以大大降低服务耗时,而且随着依赖的增加效果就会越明显,减少处理耗时的同时并不会增加服务器压力
并发处理工具MapReduce
MapReduce是Google提出的一个软件架构,用于大规模数据集的并行运算,go-zero中的MapReduce工具正是借鉴了这种架构思想
go-zero框架中的MapReduce工具主要用来对批量数据进行并发的处理,以此来提升服务的性能
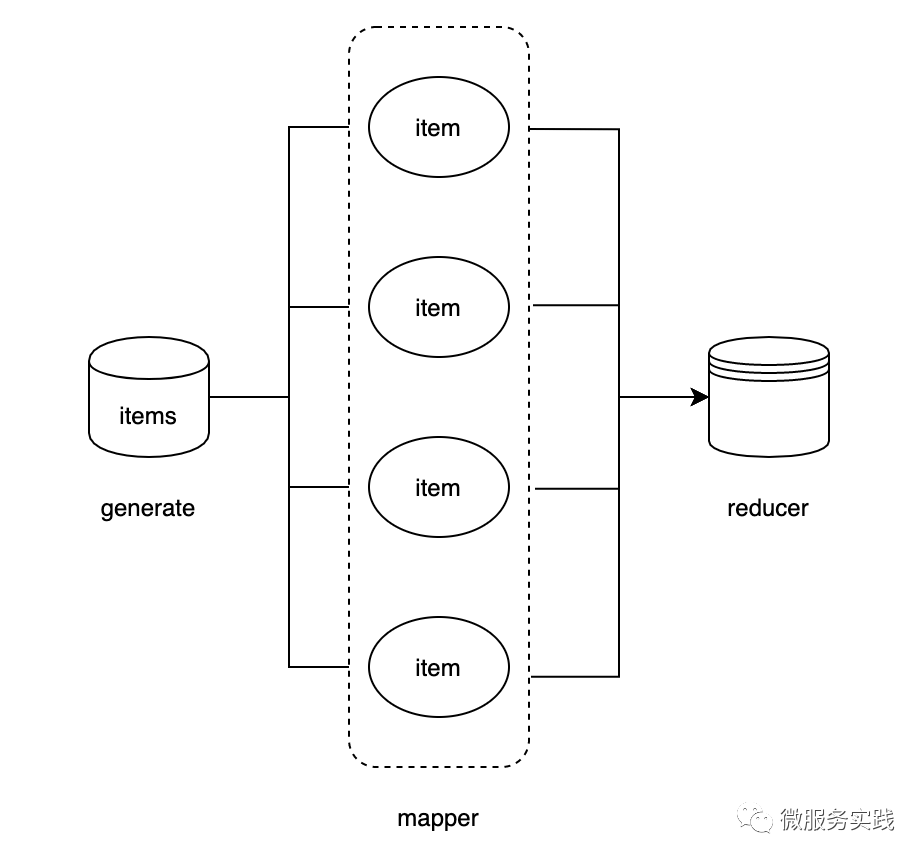
MapReduce的用法演示
MapReduce主要有三个参数,第一个参数为generate用以生产数据,第二个参数为mapper用以对数据进行处理,第三个参数为reducer用以对mapper后的数据做聚合返回,还可以通过opts选项设置并发处理的线程数量
场景一:
某些功能的结果往往需要依赖多个服务,比如商品详情的结果往往会依赖用户服务、库存服务、订单服务等等,一般被依赖的服务都是以rpc的形式对外提供,为了降低依赖的耗时我们往往需要对依赖做并行处理
func productDetail(uid, pid int64) (*ProductDetail, error) {
var pd ProductDetail
err := mr.Finish(func() (err error) {
pd.User, err = userRpc.User(uid)
return
}, func() (err error) {
pd.Store, err = storeRpc.Store(pid)
return
}, func() (err error) {
pd.Order, err = orderRpc.Order(pid)
return
})
if err != nil {
log.Printf("product detail error: %v", err)
return nil, err
}
return &pd, nil
}
该示例中返回商品详情依赖了多个服务获取数据,因此做并发的依赖处理,对接口的性能有很大的提升
场景二:
很多时候我们需要对一批数据进行处理,比如对一批用户id,效验每个用户的合法性并且效验过程中有一个出错就认为效验失败,返回的结果为效验合法的用户id
func checkLegal(uids []int64) ([]int64, error) {
r, err := mr.MapReduce(func(source chan<- interface{}) {
for _, uid := range uids {
source <- uid
}
}, func(item interface{}, writer mr.Writer, cancel func(error)) {
uid := item.(int64)
ok, err := check(uid)
if err != nil {
cancel(err)
}
if ok {
writer.Write(uid)
}
}, func(pipe <-chan interface{}, writer mr.Writer, cancel func(error)) {
var uids []int64
for p := range pipe {
uids = append(uids, p.(int64))
}
writer.Write(uids)
})
if err != nil {
log.Printf("check error: %v", err)
return nil, err
}
return r.([]int64), nil
}
func check(uid int64) (bool, error) {
// do something check user legal
return true, nil
}
该示例中,如果check过程出现错误则通过cancel方法结束效验过程,并返回error整个效验过程结束,如果某个uid效验结果为false则最终结果不返回该uid
MapReduce使用注意事项
mapper和reducer中都可以调用cancel,参数为error,调用后立即返回,返回结果为nil, error
mapper中如果不调用writer.Write则item最终不会被reducer聚合
reducer中如果不调用writer.Wirte则返回结果为nil, ErrReduceNoOutput
reducer为单线程,所有mapper出来的结果在这里串行聚合
实现原理分析:
MapReduce中首先通过buildSource方法通过执行generate(参数为无缓冲channel)产生数据,并返回无缓冲的channel,mapper会从该channel中读取数据
func buildSource(generate GenerateFunc) chan interface{} {
source := make(chan interface{})
go func() {
defer close(source)
generate(source)
}()
return source
}
在MapReduceWithSource方法中定义了cancel方法,mapper和reducer中都可以调用该方法,调用后主线程收到close信号会立马返回
cancel := once(func(err error) {
if err != nil {
retErr.Set(err)
} else {
// 默认的error
retErr.Set(ErrCancelWithNil)
}
drain(source)
// 调用close(ouput)主线程收到Done信号,立马返回
finish()
})
在mapperDispatcher方法中调用了executeMappers,executeMappers消费buildSource产生的数据,每一个item都会起一个goroutine单独处理,默认最大并发数为16,可以通过WithWorkers进行设置
var wg sync.WaitGroup
defer func() {
wg.Wait() // 保证所有的item都处理完成
close(collector)
}()
pool := make(chan lang.PlaceholderType, workers)
writer := newGuardedWriter(collector, done) // 将mapper处理完的数据写入collector
for {
select {
case <-done: // 当调用了cancel会触发立即返回
return
case pool <- lang.Placeholder: // 控制最大并发数
item, ok := <-input
if !ok {
<-pool
return
}
wg.Add(1)
go func() {
defer func() {
wg.Done()
<-pool
}()
mapper(item, writer) // 对item进行处理,处理完调用writer.Write把结果写入collector对应的channel中
}()
}
}
reducer单goroutine对数mapper写入collector的数据进行处理,如果reducer中没有手动调用writer.Write则最终会执行finish方法对output进行close避免死锁
go func() {
defer func() {
if r := recover(); r != nil {
cancel(fmt.Errorf("%v", r))
} else {
finish()
}
}()
reducer(collector, writer, cancel)
}()
在该工具包中还提供了许多针对不同业务场景的方法,实现原理与MapReduce大同小异,感兴趣的同学可以查看源码学习
MapReduceVoid 功能和MapReduce类似但没有结果返回只返回error
Finish 处理固定数量的依赖,返回error,有一个error立即返回
FinishVoid 和Finish方法功能类似,没有返回值
Map 只做generate和mapper处理,返回channel
MapVoid 和Map功能类似,无返回
文末
项目地址 https://github.com/zeromicro/go-zero
本文主要介绍了go-zero框架中的MapReduce工具,在实际的项目中非常实用。用好工具对于提升服务性能和开发效率都有很大的帮助,希望本篇文章能给大家带来一些收获,更多关于golang并发MapReduce服务响应的资料请关注我们其它相关文章!
相关推荐
-

Go并发编程实践
前言 并发编程一直是Golang区别与其他语言的很大优势,也是实际工作场景中经常遇到的.近日笔者在组内分享了我们常见的并发场景,及代码示例,以期望大家能在遇到相同场景下,能快速的想到解决方案,或者是拿这些方案与自己实现的比较,取长补短.现整理出来与大家共享. 简单并发场景 很多时候,我们只想并发的做一件事情,比如测试某个接口的是否支持并发.那么我们就可以这么做: func RunScenario1() { count := 10 var wg sync.WaitGroup for i := 0;
-
Go并发编程中使用channel的方法
目录 一.设计原理 二.数据结构 三.创建管道 四. 发送数据 4.1 直接发送 4.2 缓冲区 4.3 阻塞发送 4.4 小结 五. 接收数据 5.1 直接接收 5.2 缓冲区 5.3 阻塞接收 六. 关闭channel 七. 使用场景 7.1 使用channel控制子协程 7.2 通过关闭 channel 实现一对多的通知 7.3 使用 channel 做异步编程 7.4 超时控制 7.5 协程池 八. 参考 一.设计原理 Go 语言中最常见的.也是经常被人提及的设计模式就是: "不要通过共
-
golang如何实现mapreduce单进程版本详解
前言 MapReduce作为hadoop的编程框架,是工程师最常接触的部分,也是除去了网络环境和集群配 置之外对整个Job执行效率影响很大的部分,所以很有必要深入了解整个过程.元旦放假的第一天,在家没事干,用golang实现了一下mapreduce的单进程版本,github地址.处理对大文件统计最高频的10个单词,因为功能比较简单,所以设计没有解耦合. 本文先对mapreduce大体概念进行介绍,然后结合代码介绍一下,如果接下来几天有空,我会实现一下分布式高可用的mapreduce版本.
-
golang 并发安全Map以及分段锁的实现方法
涉及概念 并发安全Map 分段锁 sync.Map CAS ( Compare And Swap ) 双检查 分断锁 type SimpleCache struct { mu sync.RWMutex items map[interface{}]*simpleItem } 在日常开发中, 上述这种数据结构肯定不少见,因为golang的原生map是非并发安全的,所以为了保证map的并发安全,最简单的方式就是给map加锁. 之前使用过两个本地内存缓存的开源库, gcache, cache2go,其中
-
Go并发编程实现数据竞争
目录 1.前言 2.数据竞争 2.1 示例一 2.2 循环中使用goroutine引用临时变量 2.3 引起变量共享 2.4 不受保护的全局变量 2.5 未受保护的成员变量 2.6 接口中存在的数据竞争 3. 总结 4 参考 1.前言 虽然在 go 中,并发编程十分简单, 只需要使用 go func() 就能启动一个 goroutine 去做一些事情,但是正是由于这种简单我们要十分当心,不然很容易出现一些莫名其妙的 bug 或者是你的服务由于不知名的原因就重启了. 而最常见的bug是关于线程安全
-
golang并发工具MapReduce降低服务响应时间
目录 前言 并发处理工具MapReduce MapReduce的用法演示 MapReduce使用注意事项 实现原理分析: 文末 前言 在微服务中开发中,api网关扮演对外提供restful api的角色,而api的数据往往会依赖其他服务,复杂的api更是会依赖多个甚至数十个服务.虽然单个被依赖服务的耗时一般都比较低,但如果多个服务串行依赖的话那么整个api的耗时将会大大增加. 那么通过什么手段来优化呢?我们首先想到的是通过并发来的方式来处理依赖,这样就能降低整个依赖的耗时,Go基础库中为我们提供
-
解决Golang并发工具Singleflight的问题
目录 前言 定义 用途 简单Demo 源码分析 结构 对外暴露的方法 重点方法分析 Do 流程图 Forget doCall 实际使用 弊端与解决方案 参考文章 前言 前段时间在一个项目里使用到了分布式锁进行共享资源的访问限制,后来了解到Golang里还能够使用singleflight对共享资源的访问做限制,于是利用空余时间了解,将知识沉淀下来,并做分享 文章尽量用通俗的语言表达自己的理解,从入门demo开始,结合源码分析singleflight的重点方法,最后分享singleflight的实际
-
Golang编程并发工具库MapReduce使用实践
目录 环境 项目需求 mapReduce使用说明 需求实现 业务逻辑 创建任务队列 运行结果 结论 引申阅读 环境 go version go1.16.4 windows/amd64 Intel(R) Core(TM) i7-7820HK CPU @ 2.90GHz 4核心8线程 项目需求 处理数个约5MB的小文件 从源目录读取文件并拷贝到目标目录 计算源文件MD5和目标文件MD5进行对比,如不相同则报错并终止程序执行 mapReduce使用说明 go get -u github.com/tal
-
详解JUC 常用4大并发工具类
什么是JUC? JUC就是java.util.concurrent包,这个包俗称JUC,里面都是解决并发问题的一些东西 该包的位置位于java下面的rt.jar包下面 4大常用并发工具类: CountDownLatch CyclicBarrier Semaphore ExChanger CountDownLatch: CountDownLatch,俗称闭锁,作用是类似加强版的Join,是让一组线程等待其他的线程完成工作以后才执行 就比如在启动框架服务的时候,我们主线程需要在环境线程初始化完成之后
-
Java并发工具类Exchanger的相关知识总结
一.Exchanger的理解 Exchanger 属于java.util.concurrent包: Exchanger 是 JDK 1.5 开始提供的一个用于两个工作线程之间交换数据的封装工具类; 一个线程在完成一定的事务后想与另一个线程交换数据,则第一个先拿出数据的线程会一直等待第二个线程,直到第二个线程拿着数据到来时才能彼此交换对应数据. 二.Exchanger类中常用方法 public Exchanger() 无参构造方法.表示创建一个新的交换器. public V exchange(V
-
Java线程的并发工具类实现原理解析
目录 一.fork/join 1. Fork-Join原理 2. 工作窃取 3. 代码实现 二.CountDownLatch 三.CyclicBarrier 四.Semaphore 五.Exchange 六.Callable.Future.FutureTask 在JDK的并发包里提供了几个非常有用的并发工具类.CountDownLatch.CyclicBarrier和Semaphore工具类提供了一种并发流程控制的手段,Exchanger工具类则提供了在线程间交换数据的一种手段.本章会配合一些应
-
GoLang并发机制探究goroutine原理详细讲解
目录 1. 进程与线程 2. goroutine原理 3. 并发与并行 3.1 在1个逻辑处理器上运行Go程序 3.2 goroutine的停止与重新调度 3.3 在多个逻辑处理器上运行Go程序 通常程序会被编写为一个顺序执行并完成一个独立任务的代码.如果没有特别的需求,最好总是这样写代码,因为这种类型的程序通常很容易写,也很容易维护.不过也有一些情况下,并行执行多个任务会有更大的好处.一个例子是,Web 服务需要在各自独立的套接字(socket)上同时接收多个数据请求.每个套接字请求都是独立的
-
Golang并发编程重点讲解
目录 1.通过通信共享 2.Goroutines 3.Channels 3.1 Channel都有哪些特性 3.2 channel 的最佳实践 4.Channels of channels 5.并行(Parallelization) 6.漏桶缓冲区(A leaky buffer) 1.通过通信共享 并发编程是一个很大的主题,这里只提供一些特定于go的重点内容. 在许多环境中,实现对共享变量的正确访问所需要的微妙之处使并发编程变得困难.Go鼓励一种不同的方法,在这种方法中,共享值在通道中传递,实际
-
了解JAVA并发工具常用设计套路
前言 在学习JAVA并发工具时,分析JUC下的源码,发现有三个利器:状态.队列.CAS. 状态 一般是state属性,如AQS源码中的状态,是整个工具的核心,一般操作的执行都要看当前状态是什么, 由于状态是多线程共享的,所以都是volatile修饰,保证线程直接内存可见. /** * AbstractQueuedSynchronizer中的状态 */ private volatile int state; /** * Status field, taking on only the values
-
gorm golang 并发连接数据库报错的解决方法
底层报错 error:cannot assign requested address 原因 并发场景下 client 频繁请求端口建立tcp连接导致端口被耗尽 解决方案 root执行即可 sysctl -w net.ipv4.tcp_timestamps=1 开启对于TCP时间戳的支持,若该项设置为0,则下面一项设置不起作用 sysctl -w net.ipv4.tcp_tw_recycle=1 表示开启TCP连接中TIME-WAIT sockets的快速回收 以上这篇gorm golang 并