分享20个Pandas短小精悍的数据操作
目录
- 1. ExcelWriter
- 2. pipe
- 3. factorize
- 4. explode
- 5. squeeze
- 6. between
- 7. T
- 8. pandas styler
- 9. Pandas options
- 10. convert_dtypes
- 11. select_dtypes
- 12. mask
- 13. 列轴的min、max
- 14. nlargest、nsmallest
- 15. idmax、idxmin
- 16. value_counts
- 17. clip
- 18. at_time、between_time
- 19. hasnans
- 20. GroupBy.nth
1. ExcelWriter
很多时候dataframe里面有中文,如果直接输出到csv里,中文将显示乱码。而Excel就不一样了,ExcelWriter是pandas的一个类,可以使dataframe数据框直接输出到excel文件,并可以指定sheets名称。
df1 = pd.DataFrame([["AAA", "BBB"]], columns=["Spam", "Egg"])
df2 = pd.DataFrame([["ABC", "XYZ"]], columns=["Foo", "Bar"])
with ExcelWriter("path_to_file.xlsx") as writer:
df1.to_excel(writer, sheet_name="Sheet1")
df2.to_excel(writer, sheet_name="Sheet2")
如果有时间变量,输出时还可以date_format指定时间的格式。另外,它还可以通过mode设置输出到已有的excel文件中,非常灵活。
with ExcelWriter("path_to_file.xlsx", mode="a", engine="openpyxl") as writer:
df.to_excel(writer, sheet_name="Sheet3")
2. pipe
pipe管道函数可以将多个自定义函数装进同一个操作里,让整个代码更简洁,更紧凑。
比如,我们在做数据清洗的时候,往往代码会很乱,有去重、去异常值、编码转换等等。如果使用pipe,将是这样子的。
diamonds = sns.load_dataset("diamonds")
df_preped = (diamonds.pipe(drop_duplicates).
pipe(remove_outliers, ['price', 'carat', 'depth']).
pipe(encode_categoricals, ['cut', 'color', 'clarity'])
)
两个字,干净!
3. factorize
factorize这个函数类似sklearn中LabelEncoder,可以实现同样的功能。
# Mind the [0] at the end diamonds["cut_enc"] = pd.factorize(diamonds["cut"])[0] >>> diamonds["cut_enc"].sample(5) 52103 2 39813 0 31843 0 10675 0 6634 0 Name: cut_enc, dtype: int64
区别是,factorize返回一个二值元组:编码的列和唯一分类值的列表。
codes, unique = pd.factorize(diamonds["cut"], sort=True) >>> codes[:10] array([0, 1, 3, 1, 3, 2, 2, 2, 4, 2], dtype=int64) >>> unique ['Ideal', 'Premium', 'Very Good', 'Good', 'Fair']
4. explode
explode爆炸功能,可以将array-like的值比如列表,炸开转换成多行。
data = pd.Series([1, 6, 7, [46, 56, 49], 45, [15, 10, 12]]).to_frame("dirty")
data.explode("dirty", ignore_index=True)

5. squeeze
很多时候,我们用.loc筛选想返回一个值,但返回的却是个series。其实,只要使用.squeeze()即可完美解决。比如:
# 没使用squeeze
subset = diamonds.loc[diamonds.index < 1, ["price"]]
# 使用squeeze
subset.squeeze("columns")
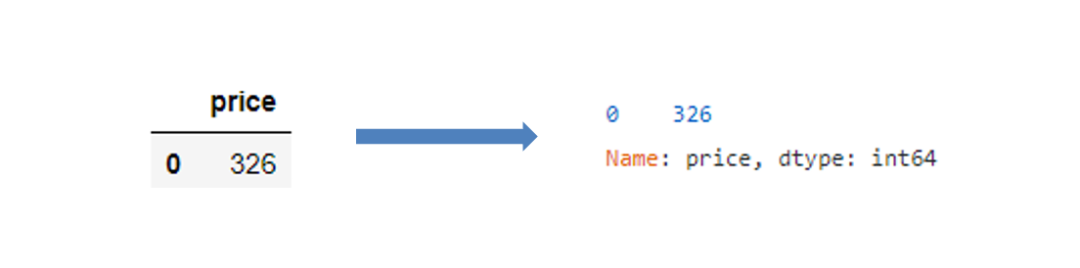
可以看到,压缩完结果已经是int64的格式了,而不再是series。
6. between
dataframe的筛选方法有很多,常见的loc、isin等等,但其实还有个及其简洁的方法,专门筛选数值范围的,就是between,用法很简单。
diamonds[diamonds["price"]\ .between(3500, 3700, inclusive="neither")].sample(5)

7. T
这是所有的dataframe都有的一个简单属性,实现转置功能。它在显示describe时可以很好的搭配。
boston.describe().T.head(10)

8. pandas styler
pandas也可以像excel一样,设置表格的可视化条件格式,而且只需要一行代码即可(可能需要一丢丢的前端HTML和CSS基础知识)。
>>> diabetes.describe().T.drop("count", axis=1)\
.style.highlight_max(color="darkred")
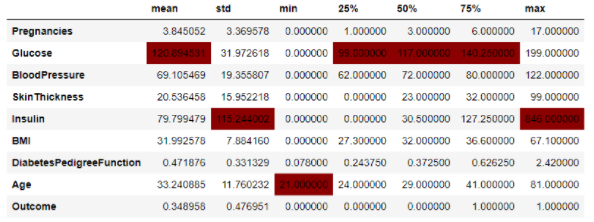
当然了,条件格式有非常多种。
9. Pandas options
pandas里提供了很多宏设置选项,被分为下面5大类。
dir(pd.options) ['compute', 'display', 'io', 'mode', 'plotting']
一般情况下使用display会多一点,比如最大、最小显示行数,画图方法,显示精度等等。
pd.options.display.max_columns = None pd.options.display.precision = 5
10. convert_dtypes
经常使用pandas的都知道,pandas对于经常会将变量类型直接变成object,导致后续无法正常操作。这种情况可以用convert_dtypes进行批量的转换,它会自动推断数据原来的类型,并实现转换。
sample = pd.read_csv( "data/station_day.csv", usecols=["StationId", "CO", "O3", "AQI_Bucket"], ) >>> sample.dtypes StationId object CO float64 O3 float64 AQI_Bucket object dtype: object >>> sample.convert_dtypes().dtypes StationId string CO float64 O3 float64 AQI_Bucket string dtype: object
11. select_dtypes
在需要筛选变量类型的时候,可以直接用selec _dtypes,通过include和exclude筛选和排除变量的类型。
# 选择数值型的变量 diamonds.select_dtypes(include=np.number).head() # 排除数值型的变量 diamonds.select_dtypes(exclude=np.number).head()
12. mask
mask可以在自定义条件下快速替换单元值,在很多三方库的源码中经常见到。比如下面我们想让age为50-60以外的单元为空,只需要在con和ohter写好自定义的条件即可。
ages = pd.Series([55, 52, 50, 66, 57, 59, 49, 60]).to_frame("ages")
ages.mask(cond=~ages["ages"].between(50, 60), other=np.nan)

13. 列轴的min、max
虽然大家都知道min和max的功能,但应用在列上的应该不多见。这对函数其实还可以这么用:
index = ["Diamonds", "Titanic", "Iris", "Heart Disease", "Loan Default"]
libraries = ["XGBoost", "CatBoost", "LightGBM", "Sklearn GB"]
df = pd.DataFrame(
{lib: np.random.uniform(90, 100, 5) for lib in libraries}, index=index
)
>>> df
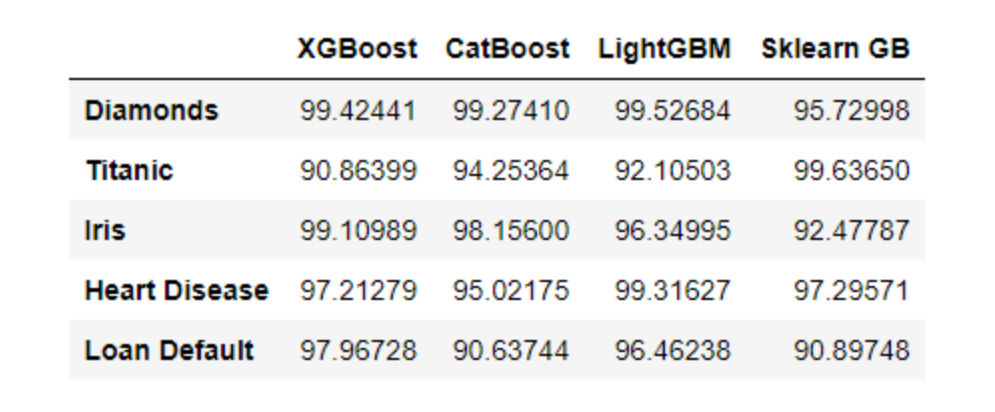
>>> df.max(axis=1) Diamonds 99.52684 Titanic 99.63650 Iris 99.10989 Heart Disease 99.31627 Loan Default 97.96728 dtype: float64
14. nlargest、nsmallest
有时我们不仅想要列的最小值/最大值,还想看变量的前 N 个或 ~(top N) 个值。这时nlargest和nsmallest就派上用场了。
diamonds.nlargest(5, "price")

15. idmax、idxmin
我们用列轴使用max或min时,pandas 会返回最大/最小的值。但我现在不需要具体的值了,我需要这个最大值的位置。因为很多时候要锁定位置之后对整个行进行操作,比如单提出来或者删除等,所以这种需求还是很常见的。
使用idxmax和idxmin即可解决。
>>> diamonds.price.idxmax() 27749 >>> diamonds.carat.idxmin() 14
16. value_counts
在数据探索的时候,value_counts是使用很频繁的函数,它默认是不统计空值的,但空值往往也是我们很关心的。如果想统计空值,可以将参数dropna设置为False。
ames_housing = pd.read_csv("data/train.csv")
>>> ames_housing["FireplaceQu"].value_counts(dropna=False, normalize=True)
NaN 0.47260
Gd 0.26027
TA 0.21438
Fa 0.02260
Ex 0.01644
Po 0.01370
Name: FireplaceQu, dtype: float64
17. clip
异常值检测是数据分析中常见的操作。使用clip函数可以很容易地找到变量范围之外的异常值,并替换它们。
>>> age.clip(50, 60)

18. at_time、between_time
在有时间粒度比较细的时候,这两个函数超级有用。因为它们可以进行更细化的操作,比如筛选某个时点,或者某个范围时间等,可以细化到小时分钟。
>>> data.at_time("15:00")

from datetime import datetime
>>> data.between_time("09:45", "12:00")

19. hasnans
pandas提供了一种快速方法hasnans来检查给定series是否包含空值。
series = pd.Series([2, 4, 6, "sadf", np.nan]) >>> series.hasnans True
该方法只适用于series的结构。
20. GroupBy.nth
此功能仅适用于GroupBy对象。具体来说,分组后,nth返回每组的第n行:
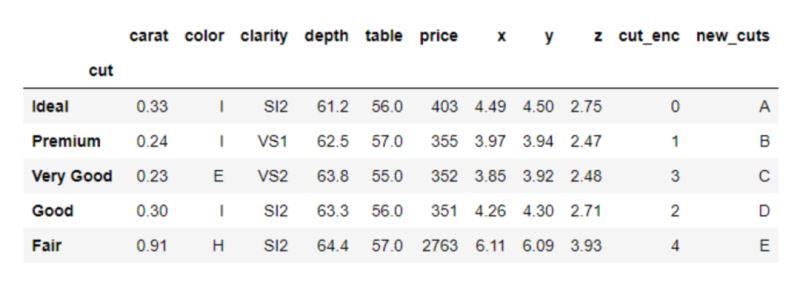
>>> diamonds.groupby("cut").nth(5)
到此这篇关于分享20个Pandas短小精悍的数据操作的文章就介绍到这了,更多相关Pandas数据操作内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

用Python的pandas框架操作Excel文件中的数据教程
引言 本文的目的,是向您展示如何使用pandas来执行一些常见的Excel任务.有些例子比较琐碎,但我觉得展示这些简单的东西与那些你可以在其他地方找到的复杂功能同等重要.作为额外的福利,我将会进行一些模糊字符串匹配,以此来展示一些小花样,以及展示pandas是如何利用完整的Python模块系统去做一些在Python中是简单,但在Excel中却很复杂的事情的. 有道理吧?让我们开始吧. 为某行添加求和项 我要介绍的第一项任务是把某几列相加然后添加一个总和栏. 首先我们将excel 数据 导入到pa
-
Python Pandas数据中对时间的操作
Pandas中对 时间 这个属性的处理有非常非常多的操作. 而本文对其中一个大家可能比较陌生的方法进行讲解.其他的我会陆续上传. 应用情景是这样的:考虑到有一个数据集,数据集中有用户注册账号的时间(年-月-日),如下图格式. 如果我们希望对用户账号注册时间转为具体的天数,我们可以用如下代码. import pandas as pd td=data['user_reg_tm'] Time=pd.to_datetime(td) Start=pd.datetime(2016,4,16) day=Sta
-
pandas数据筛选和csv操作的实现方法
1. 数据筛选 a b c 0 0 2 4 1 6 8 10 2 12 14 16 3 18 20 22 4 24 26 28 5 30 32 34 6 36 38 40 7 42 44 46 8 48 50 52 9 54 56 58 (1)单条件筛选 df[df['a']>30] # 如果想筛选a列的取值大于30的记录,但是之显示满足条件的b,c列的值可以这么写 df[['b','c']][df['a']>30] # 使用isin函数根据特定值筛选记录.筛选a值等于30或者54的记录 df
-
Python Pandas学习之基本数据操作详解
目录 1索引操作 1.1直接使用行列索引(先列后行) 1.2结合loc或者iloc使用索引 1.3使用ix组合索引 2赋值操作 3排序 3.1DataFrame排序 3.2Series排序 为了更好的理解这些基本操作,下面会通过读取一个股票数据,来进行Pandas基本数据操作的语法介绍. # 读取文件(读取保存文件后面会专门进行讲解,这里先直接调用下api) data = pd.read_csv("./data/stock_day.csv") # 读取当前目录下一个csv文件 # 删
-
Python数据分析之pandas比较操作
一.比较运算符和比较方法 比较运算符用于判断是否相等和比较大小,Python中的比较运算符有==.!=.<.>.<=.>=六个,Pandas中也一样. 在Pandas中,DataFrame和Series还支持6个比较方法,详见下表. 方法 英文全称 用途 eq equal to 等于 ne not equal to 不等于 lt less than 小于 gt greater than 大于 le less than or equal to 小于等于 ge greater than
-
Pandas实现数据拼接的操作方法详解
目录 merge 操作 merge 拼接方式 merge 举例 join 操作 join 举例 concat 操作 concat 举例 append 举例 数据科学领域日常使用 Python 处理大规模数据集的时候经常需要使用到合并.链接的方式进行数据集的整合,其中应用的数据类型包括 Series 和 DataFrame,可以使用的方法也很多,比如本文中介绍的 .merge(). .join() 和 .concat() 三种方法,进行拼接处理后的数据集可以发挥最大的用途. merge 操作 .m
-
Python数据分析库pandas基本操作方法
pandas是什么? 是它吗? ....很显然pandas没有这个家伙那么可爱.... 我们来看看pandas的官网是怎么来定义自己的: pandas is an open source, easy-to-use data structures and data analysis tools for the Python programming language. 很显然,pandas是python的一个非常强大的数据分析库! 让我们来学习一下它吧! 1.pandas序列 import nump
-
五个Pandas 实战案例带你分析操作数据
目录 构建数据 分析维度1:时间 2019-2021年每月销量走势 2019-2021销售额走势 年度销量.销售额和平均销售额 分析维度2:商品 水果年度销量占比 各水果年度销售金额对比 商品月度销量变化 分析维度3:地区 不同地区的销量 分析维度4:用户 用户订单量.金额对比 用户水果喜好 用户分层—RFM模型 用户复购周期分析 大家好,之前分享过很多关于 Pandas 的文章,今天我给大家分享5个小而美的 Pandas 实战案例. 内容主要分为: 如何自行模拟数据 多种数据处理方式 数据统计
-
分享20个Pandas短小精悍的数据操作
目录 1. ExcelWriter 2. pipe 3. factorize 4. explode 5. squeeze 6. between 7. T 8. pandas styler 9. Pandas options 10. convert_dtypes 11. select_dtypes 12. mask 13. 列轴的min.max 14. nlargest.nsmallest 15. idmax.idxmin 16. value_counts 17. clip 18. at_time
-
Pandas处理时间序列数据操作详解
目录 前言 一.获取时间 二.时间索引 三.时间推移 前言 一般从数据库或者是从日志文件读出的数据均带有时间序列,做时序数据处理或者实时分析都需要对其时间序列进行归类归档.而Pandas是处理这些数据很好用的工具包.此篇博客基于Jupyter之上进行演示,本篇博客的愿景是希望我或者读者通过阅读这篇博客能够学会方法并能实际运用.希望读者看完能够提出问题或者看法,博主会长期维护博客做及时更新.纯分享,希望大家喜欢. 一.获取时间 python自带datetime库,通过调用此库可以获取本地时间 fr
-
使用pandas实现连续数据的离散化处理方式(分箱操作)
Python实现连续数据的离散化处理主要基于两个函数,pandas.cut和pandas.qcut,前者根据指定分界点对连续数据进行分箱处理,后者则可以根据指定箱子的数量对连续数据进行等宽分箱处理,所谓等宽指的是每个箱子中的数据量是相同的. 下面简单介绍一下这两个函数的用法: # 导入pandas包 import pandas as pd ages = [20, 22, 25, 27, 21, 23, 37, 31, 61, 45, 41, 32] # 待分箱数据 bins = [18, 25,
-
python pandas中DataFrame类型数据操作函数的方法
python数据分析工具pandas中DataFrame和Series作为主要的数据结构. 本文主要是介绍如何对DataFrame数据进行操作并结合一个实例测试操作函数. 1)查看DataFrame数据及属性 df_obj = DataFrame() #创建DataFrame对象 df_obj.dtypes #查看各行的数据格式 df_obj['列名'].astype(int)#转换某列的数据类型 df_obj.head() #查看前几行的数据,默认前5行 df_obj.tail() #查看后几
-
Pandas读存JSON数据操作示例详解
目录 引言 读取json数据 模拟数据 参数orident orident="split" orient="records" orient="index" orient="columns" orient="values" to_json 引言 本文介绍的如何使用Pandas来读取各种json格式的数据,以及对json数据的保存 读取json数据 使用的是pd.read_json函数,见官网:pandas.p
-
Python使用matplotlib和pandas实现的画图操作【经典示例】
本文实例讲述了Python使用matplotlib和pandas实现的画图操作.分享给大家供大家参考,具体如下: 画图在工作再所难免,尤其在做数据探索时候,下面总结了一些关于python画图的例子 #encoding:utf-8 ''''' Created on 2015年9月11日 @author: ZHOUMEIXU204 ''' # pylab 是 matplotlib 面向对象绘图库的一个接口.它的语法和 Matlab 十分相近 import pandas as pd #from ggp
-
python3 pandas 读取MySQL数据和插入的实例
python 代码如下: # -*- coding:utf-8 -*- import pandas as pd import pymysql import sys from sqlalchemy import create_engine def read_mysql_and_insert(): try: conn = pymysql.connect(host='localhost',user='user1',password='123456',db='test',charset='utf8')
-
vue.js前后端数据交互之提交数据操作详解
本文实例讲述了vue.js前后端数据交互之提交数据操作.分享给大家供大家参考,具体如下: 前端小白刚开始做页面的时候,我们的前端页面中经常会用到表单,所以学会提交表单也是一个基本技能,其实用ajax就能实现,但他的原始语法有点...额 ...复杂,所以这里给大家提供一种用vue-resource向后端提交数据. (1)第一步,先在template中写一个表单: <el-form :model="ruleForm" :rules="rules" ref=&quo
-
将pandas.dataframe的数据写入到文件中的方法
导入实验常用的python包.如图2所示. [import pandas as pd]pandas用来做数据处理.[import numpy as np]numpy用来做高维度矩阵运算.[import matplotlib.pyplot as plt]matplotlib用来做数据可视化. pandas数据写入到csv文件中: [names = ['Bob','Jessica','Mary','John','Mel']]创建一个names列表[ births = [968,155,77,578,
-
Python利用pandas处理Excel数据的应用详解
最近迷上了高效处理数据的pandas,其实这个是用来做数据分析的,如果你是做大数据分析和测试的,那么这个是非常的有用的!!但是其实我们平时在做自动化测试的时候,如果涉及到数据的读取和存储,那么而利用pandas就会非常高效,基本上3行代码可以搞定你20行代码的操作!该教程仅仅限于结合柠檬班的全栈自动化测试课程来讲解下pandas在项目中的应用,这仅仅只是冰山一角,希望大家可以踊跃的去尝试和探索! 一.安装环境: 1:pandas依赖处理Excel的xlrd模块,所以我们需要提前安装这个,安装命令