python实现层次聚类的方法
层次聚类算法
顾名思义,层次聚类就是一层一层的进行聚类,可以由上向下把大的类别(cluster)分割,叫作分裂法;也可以由下向上对小的类别进行聚合,叫作凝聚法;但是一般用的比较多的是由下向上的凝聚方法。
分裂法:
分裂法指的是初始时将所有的样本归为一个类簇,然后依据某种准则进行逐渐的分裂,直到达到某种条件或者达到设定的分类数目。用算法描述:
输入:样本集合D,聚类数目或者某个条件(一般是样本距离的阈值,这样就可不设置聚类数目)
输出:聚类结果
1.将样本集中的所有的样本归为一个类簇;
repeat:
2.在同一个类簇(计为c)中计算两两样本之间的距离,找出距离最远的两个样本a,b;
3.将样本a,b分配到不同的类簇c1和c2中;
4.计算原类簇(c)中剩余的其他样本点和a,b的距离,若是dis(a)<dis(b),则将样本点归到c1中,否则归到c2中;
util: 达到聚类的数目或者达到设定的条件
凝聚法:
凝聚法指的是初始时将每个样本点当做一个类簇,所以原始类簇的大小等于样本点的个数,然后依据某种准则合并这些初始的类簇,直到达到某种条件或者达到设定的分类数目。用算法描述:
输入:样本集合D,聚类数目或者某个条件(一般是样本距离的阈值,这样就可不设置聚类数目)
输出:聚类结果
1.将样本集中的所有的样本点都当做一个独立的类簇;
repeat:
2.计算两两类簇之间的距离(后边会做介绍),找到距离最小的两个类簇c1和c2;
3.合并类簇c1和c2为一个类簇;
util: 达到聚类的数目或者达到设定的条件
例图:

欧式距离的计算公式
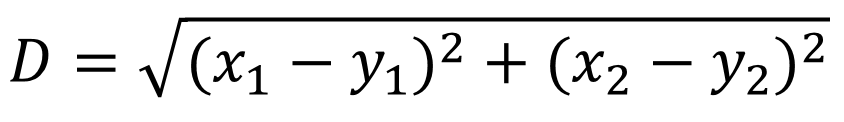
类簇间距离的计算方法有许多种:
(1)就是取两个类中距离最近的两个样本的距离作为这两个集合的距离,也就是说,最近两个样本之间的距离越小,这两个类之间的相似度就越大
(2)取两个集合中距离最远的两个点的距离作为两个集合的距离
(3)把两个集合中的点两两的距离全部放在一起求一个平均值,相对也能得到合适一点的结果。
e.g.下面是计算组合数据点(A,F)到(B,C)的距离,这里分别计算了(A,F)和(B,C)两两间距离的均值。

(4)取两两距离的中值,与取均值相比更加能够解除个别偏离样本对结果的干扰。
(5)求每个集合的中心点(就是将集合中的所有元素的对应维度相加然后再除以元素个数得到的一个向量),然后用中心点代替集合再去就集合间的距离
实现
接下来以世界银行样本数据集进行简单实现。该数据集以标准格式存储在名为WBClust2013.csv的CSV格式的文件中。其有80行数据和14个变量。数据来源
为了使得结果可视化更加方便,我将最后一栏人口数据删除了。并且在实现层次聚类之后加入PCA降维与原始结果进行对比。
from scipy.cluster.hierarchy import linkage, dendrogram, fcluster
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
data = pd.read_csv('data/WBClust2013.csv')
data.pop('Pop')
# data.pop('RuralWater')
# data.pop('CellPhone')
# data.pop('LifeExp')
data = data[:20]
country = list(data['Country'])
data.pop('Country')
# 以下代码为仅使用层次聚类
plt.figure(figsize=(9, 7))
plt.title("original data")
mergings = linkage(data, method='average')
# print(mergings)
dendrogram(mergings, labels=country, leaf_rotation=45, leaf_font_size=8)
plt.show()
Z = linkage(data, method='average')
print(Z)
cluster_assignments = fcluster(Z, t=3.0, criterion='maxclust')
print(cluster_assignments)
for i in range(1, 4):
print('cluster', i, ':')
num = 1
for index, value in enumerate(cluster_assignments):
if value == i:
if num % 5 == 0:
print()
num += 1
print(country[index], end=' ')
print()
# 以下代码为加入PCA进行对比
class myPCA():
def __init__(self, X, d=2):
self.X = X
self.d = d
def mean_center(self, data):
"""
去中心化
:param data: data sets
:return:
"""
n, m = data.shape
for i in range(m):
aver = np.sum(self.X[:, i])/n
x = np.tile(aver, (1, n))
self.X[:, i] = self.X[:, i]-x
def runPCA(self):
# 计算协方差矩阵,得到特征值,特征向量
S = np.dot(self.X.T, self.X)
S_val, S_victors = np.linalg.eig(S)
index = np.argsort(-S_val)[0:self.d]
Y = S_victors[:, index]
# 得到输出样本集
Y = np.dot(self.X, Y)
return Y
# data_for_pca = np.array(data)
# pcaObject=myPCA(data_for_pca,d=2)
# pcaObject.mean_center(data_for_pca)
# res=pcaObject.runPCA()
# plt.figure(figsize=(9, 7))
# plt.title("after pca")
# mergings = linkage(res,method='average')
# print(mergings)
# dendrogram(mergings,labels=country,leaf_rotation=45,leaf_font_size=8)
# plt.show()
# Z = linkage(res, method='average')
# print(Z)
# cluster_assignments = fcluster(Z, t=3.0, criterion='maxclust')
# print(cluster_assignments)
# for i in range(1,4):
# print('cluster', i, ':')
# num = 1
# for index, value in enumerate(cluster_assignments):
# if value == i:
# if num % 5 ==0:
# print()
# num+=1
# print(country[index],end=' ')
# print()
两次分类结果都是一样的:
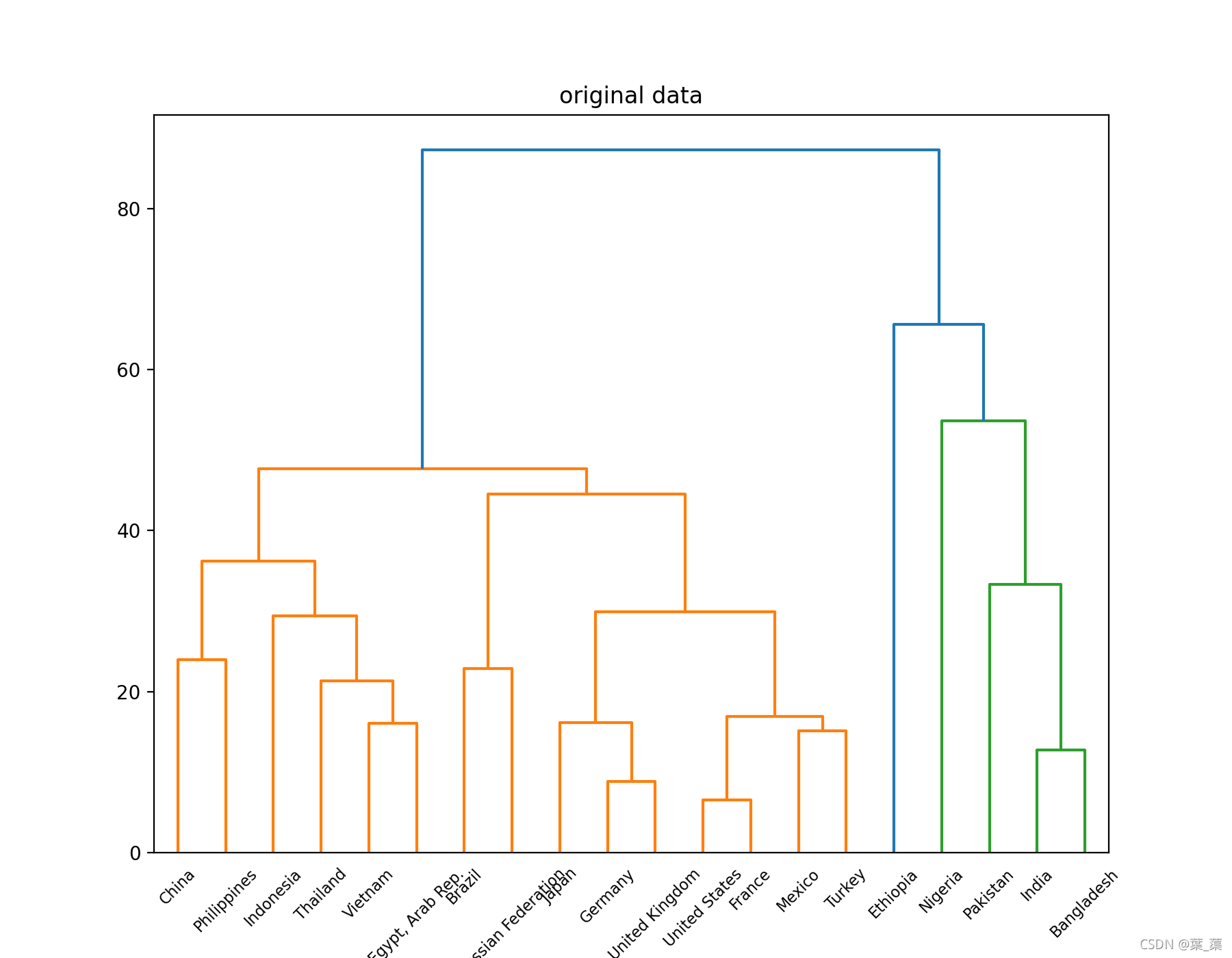
cluster 1 : China United States Indonesia Brazil Russian Federation Japan Mexico Philippines Vietnam Egypt, Arab Rep. Germany Turkey Thailand France United Kingdom cluster 2 : India Pakistan Nigeria Bangladesh cluster 3 : Ethiopia
通过树状图对结果进行可视化
原始树状图:
PCA降维后的结果:

到此这篇关于python实现层次聚类的文章就介绍到这了,更多相关python层次聚类内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python聚类算法之凝聚层次聚类实例分析
本文实例讲述了Python聚类算法之凝聚层次聚类.分享给大家供大家参考,具体如下: 凝聚层次聚类:所谓凝聚的,指的是该算法初始时,将每个点作为一个簇,每一步合并两个最接近的簇.另外即使到最后,对于噪音点或是离群点也往往还是各占一簇的,除非过度合并.对于这里的"最接近",有下面三种定义.我在实现是使用了MIN,该方法在合并时,只要依次取当前最近的点对,如果这个点对当前不在一个簇中,将所在的两个簇合并就行: 单链(MIN):定义簇的邻近度为不同两个簇的两个最近的点之间的距离. 全链(MAX
-
Python实现简单层次聚类算法以及可视化
本文实例为大家分享了Python实现简单层次聚类算法,以及可视化,供大家参考,具体内容如下 基本的算法思路就是:把当前组间距离最小的两组合并成一组. 算法的差异在算法如何确定组件的距离,一般有最大距离,最小距离,平均距离,马氏距离等等. 代码如下: import numpy as np import data_helper np.random.seed(1) def get_raw_data(n): _data=np.random.rand(n,2) #生成数据的格式是n个(x,y) _grou
-
python实现层次聚类的方法
层次聚类算法 顾名思义,层次聚类就是一层一层的进行聚类,可以由上向下把大的类别(cluster)分割,叫作分裂法:也可以由下向上对小的类别进行聚合,叫作凝聚法:但是一般用的比较多的是由下向上的凝聚方法. 分裂法: 分裂法指的是初始时将所有的样本归为一个类簇,然后依据某种准则进行逐渐的分裂,直到达到某种条件或者达到设定的分类数目.用算法描述: 输入:样本集合D,聚类数目或者某个条件(一般是样本距离的阈值,这样就可不设置聚类数目) 输出:聚类结果 1.将样本集中的所有的样本归为一个类簇: repea
-
利用Python实现K-Means聚类的方法实例(案例:用户分类)
目录 K-Means聚类算法介绍 K-Means聚类算法基础原理 K-Means聚类算法实现流程 开始做一个简单的聚类 数据导入 数据探索 开始聚类 查看输出结果 聚类质心 K-Means聚类算法的评估指标 真实标签已知 真实标签未知 实用案例:基于轮廓系数来选择最佳的n_clusters 结果对比 优化方案选择 K-Means聚类算法介绍 K-Means又称为K均值聚类算法,属于聚类算法中的一种,而聚类算法在机器学习算法中属于无监督学习,在业务中常常会结合实际需求与业务逻辑理解来完成建模: 无
-
Python sklearn中的K-Means聚类使用方法浅析
目录 初步认识 初值选取 小批 初步认识 k-means翻译过来就是K均值聚类算法,其目的是将样本分割为k个簇,而这个k则是KMeans中最重要的参数:n_clusters,默认为8. 下面做一个最简单的聚类 import numpy as np import matplotlib.pyplot as plt from sklearn.cluster import KMeans from sklearn.datasets import make_blobs X, y = make_blobs(1
-
Python实现Kmeans聚类算法
本节内容:本节内容是根据上学期所上的模式识别课程的作业整理而来,第一道题目是Kmeans聚类算法,数据集是Iris(鸢尾花的数据集),分类数k是3,数据维数是4. 关于聚类 聚类算法是这样的一种算法:给定样本数据Sample,要求将样本Sample中相似的数据聚到一类.有了这个认识之后,就应该了解了聚类算法要干什么了吧.说白了,就是归类. 首先,我们需要考虑的是,如何衡量数据之间的相似程度?比如说,有一群说不同语言的人,我们一般是根据他们的方言来聚类的(当然,你也可以指定以身高来聚类).
-
python实现k-means聚类算法
k-means聚类算法 k-means是发现给定数据集的k个簇的算法,也就是将数据集聚合为k类的算法. 算法过程如下: 1)从N个文档随机选取K个文档作为质心 2)对剩余的每个文档测量其到每个质心的距离,并把它归到最近的质心的类,我们一般取欧几里得距离 3)重新计算已经得到的各个类的质心 4)迭代步骤(2).(3)直至新的质心与原质心相等或迭代次数大于指定阈值,算法结束 算法实现 随机初始化k个质心,用dict保存质心的值以及被聚类到该簇中的所有data. def initCent(dataSe
-
Python二叉树定义与遍历方法实例分析
本文实例讲述了Python二叉树定义与遍历方法.分享给大家供大家参考,具体如下: 二叉树基本概述: 二叉树是有限个元素的几个,如果为空则为空二叉树,或者有一个结点称之为根节点,分列根节点两侧的为二叉树的左右子节点,二叉树有如下的性质: 1. 二叉树的每个结点不存在度大于2的结点 2. 二叉树的第i层至多有2^{i-1}个结点 3. 深度为k的二叉树至多有2^k - 1个结点 4. 二叉树中,度为0的结点数N0比度为2的结点数N2大1,即存在N2 + 1 = N0 Python代码: #codin
-
Python构建图像分类识别器的方法
机器学习用在图像识别是非常有趣的话题. 我们可以利用OpenCV强大的功能结合机器学习算法实现图像识别系统. 首先,输入若干图像,加入分类标记.利用向量量化方法将特征点进行聚类,并得出中心点,这些中心点就是视觉码本的元素. 其次,利用图像分类器将图像分到已知的类别中,ERF(极端随机森林)算法非常流行,因为ERF具有较快的速度和比较精确的准确度.我们利用决策树进行正确决策. 最后,利用训练好的ERF模型后,创建目标识别器,可以识别未知图像的内容. 当然,这只是雏形,存在很多问题: 界面不友好.
-
python实现密度聚类(模板代码+sklearn代码)
本人在此就不搬运书上关于密度聚类的理论知识了,仅仅实现密度聚类的模板代码和调用skelarn的密度聚类算法. 有人好奇,为什么有sklearn库了还要自己去实现呢?其实,库的代码是比自己写的高效且容易,但自己实现代码会对自己对算法的理解更上一层楼. #调用科学计算包与绘图包 import numpy as np import random import matplotlib.pyplot as plt # 获取数据 def loadDataSet(filename): dataSet=np.lo