MySQL常用分库分表方案汇总
目录
- 一、数据库瓶颈
- 二、分库分表
- 2、水平分表
- 3、垂直分库
- 4、垂直分表
- 三、分库分表工具
- 四、分库分表步骤
- 五、分库分表问题
- 1、非partition key的查询问题
- 2、非partition key跨库跨表分页查询问题
- 3、扩容问题
- 六、分库分表总结
一、数据库瓶颈
不管是IO瓶颈,还是CPU瓶颈,最终都会导致数据库的活跃连接数增加,进而逼近甚至达到数据库可承载活跃连接数的阈值。在业务Service来看就是,可用数据库连接少甚至无连接可用。接下来就可以想象了吧(并发量、吞吐量、崩溃)。
1、IO瓶颈
第一种:磁盘读IO瓶颈,热点数据太多,数据库缓存放不下,每次查询时会产生大量的IO,降低查询速度 -> 分库和垂直分表。
第二种:网络IO瓶颈,请求的数据太多,网络带宽不够 -> 分库。
2、CPU瓶颈
第一种:SQL问题,如SQL中包含join,group by,order by,非索引字段条件查询等,增加CPU运算的操作 -> SQL优化,建立合适的索引,在业务Service层进行业务计算。
第二种:单表数据量太大,查询时扫描的行太多,SQL效率低,CPU率先出现瓶颈 -> 水平分表。
二、分库分表
1、水平分库
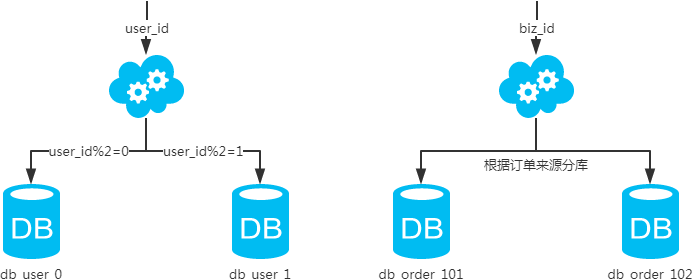
概念:以字段为依据,按照一定策略(hash、range等),将一个库中的数据拆分到多个库中。
结果:
- 每个库的结构都一样;
- 每个库的数据都不一样,没有交集;
- 所有库的并集是全量数据;
场景:系统绝对并发量上来了,分表难以根本上解决问题,并且还没有明显的业务归属来垂直分库。
分析:库多了,io和cpu的压力自然可以成倍缓解。
2、水平分表
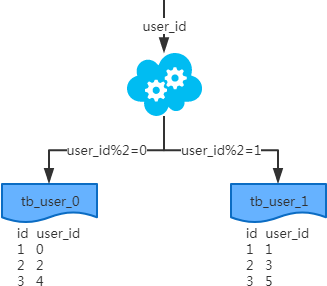
概念:以字段为依据,按照一定策略(hash、range等),将一个表中的数据拆分到多个表中。
结果:
- 每个表的结构都一样;
- 每个表的数据都不一样,没有交集;
- 所有表的并集是全量数据;
场景:系统绝对并发量并没有上来,只是单表的数据量太多,影响了SQL效率,加重了CPU负担,以至于成为瓶颈。推荐:一次SQL查询优化原理分析
分析:表的数据量少了,单次SQL执行效率高,自然减轻了CPU的负担。
3、垂直分库
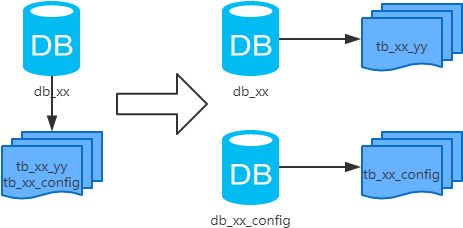
概念:以表为依据,按照业务归属不同,将不同的表拆分到不同的库中。
结果:
- 每个库的结构都不一样;
- 每个库的数据也不一样,没有交集;
- 所有库的并集是全量数据;
场景:系统绝对并发量上来了,并且可以抽象出单独的业务模块。
分析:到这一步,基本上就可以服务化了。
例如,随着业务的发展一些公用的配置表、字典表等越来越多,这时可以将这些表拆到单独的库中,甚至可以服务化。再有,随着业务的发展孵化出了一套业务模式,这时可以将相关的表拆到单独的库中,甚至可以服务化。
4、垂直分表

概念:以字段为依据,按照字段的活跃性,将表中字段拆到不同的表(主表和扩展表)中。
结果:
- 每个表的结构都不一样;
- 每个表的数据也不一样,一般来说,每个表的字段至少有一列交集,一般是主键,用于关联数据;
- 所有表的并集是全量数据;
场景:系统绝对并发量并没有上来,表的记录并不多,但是字段多,并且热点数据和非热点数据在一起,单行数据所需的存储空间较大。以至于数据库缓存的数据行减少,查询时会去读磁盘数据产生大量的随机读IO,产生IO瓶颈。
分析:可以用列表页和详情页来帮助理解。垂直分表的拆分原则是将热点数据(可能会冗余经常一起查询的数据)放在一起作为主表,非热点数据放在一起作为扩展表。这样更多的热点数据就能被缓存下来,进而减少了随机读IO。拆了之后,要想获得全部数据就需要关联两个表来取数据。
但记住,千万别用join,因为join不仅会增加CPU负担并且会讲两个表耦合在一起(必须在一个数据库实例上)。关联数据,应该在业务Service层做文章,分别获取主表和扩展表数据然后用关联字段关联得到全部数据。
三、分库分表工具
- sharding-sphere:jar,前身是sharding-jdbc;
- TDDL:jar,Taobao Distribute Data Layer;
- Mycat:中间件。
注:工具的利弊,请自行调研,官网和社区优先。
四、分库分表步骤
根据容量(当前容量和增长量)评估分库或分表个数 -> 选key(均匀)-> 分表规则(hash或range等)-> 执行(一般双写)-> 扩容问题(尽量减少数据的移动)。
五、分库分表问题
1、非partition key的查询问题
基于水平分库分表,拆分策略为常用的hash法。
端上除了partition key只有一个非partition key作为条件查询
映射法
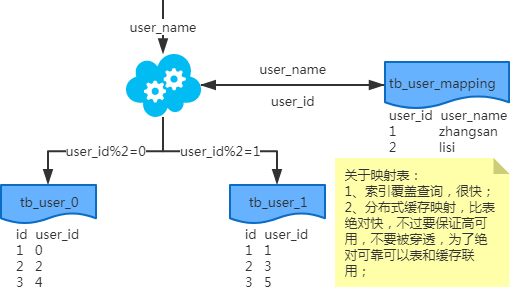
基因法
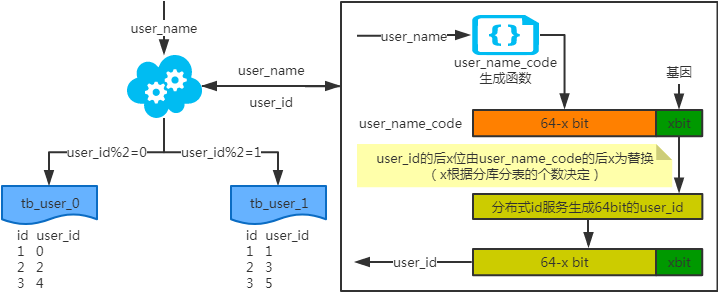
注:写入时,基因法生成user_id,如图。关于xbit基因,例如要分8张表,23=8,故x取3,即3bit基因。根据user_id查询时可直接取模路由到对应的分库或分表。
根据user_name查询时,先通过user_name_code生成函数生成user_name_code再对其取模路由到对应的分库或分表。id生成常用snowflake算法。
端上除了partition key不止一个非partition key作为条件查询
映射法

冗余法

注:按照order_id或buyer_id查询时路由到db_o_buyer库中,按照seller_id查询时路由到db_o_seller库中。感觉有点本末倒置!有其他好的办法吗?改变技术栈呢?
后台除了partition key还有各种非partition key组合条件查询
NoSQL法
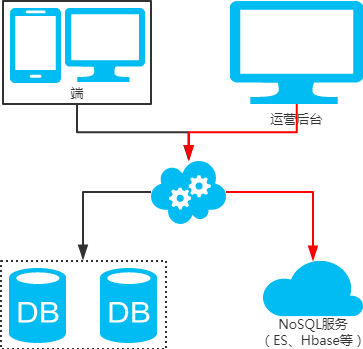
冗余法

2、非partition key跨库跨表分页查询问题
基于水平分库分表,拆分策略为常用的hash法。
注:用NoSQL法解决(ES等)。
3、扩容问题
基于水平分库分表,拆分策略为常用的hash法。
水平扩容库(升级从库法)

注:扩容是成倍的。
水平扩容表(双写迁移法)
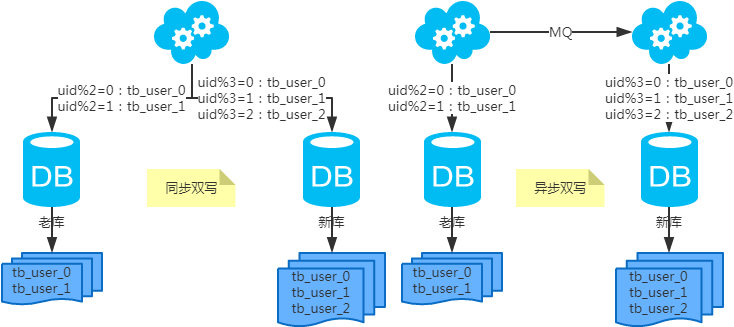
第一步:(同步双写)修改应用配置和代码,加上双写,部署;
第二步:(同步双写)将老库中的老数据复制到新库中;
第三步:(同步双写)以老库为准校对新库中的老数据;
第四步:(同步双写)修改应用配置和代码,去掉双写,部署;
注:双写是通用方案。
六、分库分表总结
分库分表,首先得知道瓶颈在哪里,然后才能合理地拆分(分库还是分表?水平还是垂直?分几个?)。且不可为了分库分表而拆分。
选key很重要,既要考虑到拆分均匀,也要考虑到非partition key的查询。
只要能满足需求,拆分规则越简单越好。
到此这篇关于MySQL常用分库分表方案汇总的文章就介绍到这了,更多相关MySQL 分库分表内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Mysql数据库分库和分表方式(常用)
本文主要给大家介绍Mysql数据库分库和分表方式(常用),涉及到mysql数据库相关知识,对mysql数据库分库分表相关知识感兴趣的朋友一起学习吧 1 分库 1.1 按照功能分库 按照功能进行分库.常见的分成6大库: 1 用户类库:用于保存了用户的相关信息.例如:db_user,db_system,db_company等. 2 业务类库:用于保存主要业务的信息.比如主要业务是笑话,用这个库保存笑话业务.例如:db_joke,db_temp_joke等. 3 内存类库:主要用Mysql的内存引擎.
-
mysql分表分库的应用场景和设计方式
很多朋友在论坛和留言区域问mysql在什么情况下才需要进行分库分表,以及采用何种设计方式才是最优的选择,根据这些问题,小编为大家整理了关于MySQL分库分表的应用场景和最优的设计方式举例. 一. 分表 场景:对于大型的互联网应用来说,数据库单表的记录行数可能达到千万级甚至是亿级,并且数据库面临着极高的并发访问.采用Master-Slave复制模式的MySQL架构, 只能够对数据库的读进行扩展,而对数据库的写入操作还是集中在Master上,并且单个Master挂载的Slave也不可能无限制多,Sl
-
MYSQL性能优化分享(分库分表)
1.分库分表 很明显,一个主表(也就是很重要的表,例如用户表)无限制的增长势必严重影响性能,分库与分表是一个很不错的解决途径,也就是性能优化途径,现在的案例是我们有一个1000多万条记录的用户表members,查询起来非常之慢,同事的做法是将其散列到100个表中,分别从members0到members99,然后根据mid分发记录到这些表中,牛逼的代码大概是这样子: 复制代码 代码如下: <?php for($i=0;$i< 100; $i++ ){ //echo "CREATE TA
-
MySQL分库分表总结讲解
项目开发中,我们的数据库数据越来越大,随之而来的是单个表中数据太多.以至于查询变慢,而且由于表的锁机制导致应用操作也受到严重影响,出现了数据库性能瓶颈. 当出现这种情况时,我们可以考虑分库分表,即将单个数据库或表进行拆分,拆分成多个库和多个数据表,然后用户访问的时候,根据一定的算法与逻辑,让用户访问不同的库.不同的表,这样数据分散到多个数据表中,减少了单个数据表的访问压力.提升了数据库访问性能. 下面是对项目中分库分表的一些总结: 单库单表 单库单表是最常见的数据库设计,例如,有一张用户(use
-
MySQL 分表分库怎么进行数据切分
关系型数据库本身比较容易成为系统瓶颈,单机存储容量.连接数.处理能力都有限.当单表的数据量达到1000W或100G以后,由于查询维度较多,即使添加从库.优化索引,做很多操作时性能仍下降严重.此时就要考虑对其进行切分了,切分的目的就在于减少数据库的负担,缩短查询时间. 数据库分布式核心内容无非就是数据切分(Sharding)以及切分后对数据的定位.整合.数据切分就是将数据分散存储到多个数据库中,使得单一数据库中的数据量变小,通过扩充主机的数量缓解单一数据库的性能问题,从而达到提升数据库操作性能的目
-
MySql分表、分库、分片和分区知识深入详解
一.前言 数据库的数据量达到一定程度之后,为避免带来系统性能上的瓶颈.需要进行数据的处理,采用的手段是分区.分片.分库.分表. 二.分片(类似分库) 分片是把数据库横向扩展(Scale Out)到多个物理节点上的一种有效的方式,其主要目的是为突破单节点数据库服务器的 I/O 能力限制,解决数据库扩展性问题.Shard这个词的意思是"碎片".如果将一个数据库当作一块大玻璃,将这块玻璃打碎,那么每一小块都称为数据库的碎片(DatabaseShard).将整个数据库打碎的过程就叫做分片,可以
-
MySQL分库分表详情
一.业务场景介绍 假设目前有一个电商系统使用的是MySQL,要设计大数据量存储.高并发.高性能可扩展的方案,数据库中有用户表.用户会非常多,并且要实现高扩展性,你会怎么去设计? OK咱们先看传统的分库分表方式 当然还有些小伙伴知道按照省份/地区或一定的业务关系进行数据库拆分 OK,问题来了,如何保证合理的让数据存储在不同的库不同的表里呢?让库减少并发压力?应该怎么去制定分库分表的规则?不用急,这不就来了 二.水平分库分表方法 1.RANGE 第一种方法们可以指定一个数据范围来进行分表,例如从1~
-
mysql数据库分表分库的策略
一.先说一下为什么要分表: 当一张的数据达到几百万时,你查询一次所花的时间会变多,如果有联合查询的话,有可能会死在那儿了.分表的目的就在于此,减小数据库的负担,缩短查询时间.日常开发中我们经常会遇到大表的情况,所谓的大表是指存储了百万级乃至千万级条记录的表.这样的表过于庞大,导致数据库在查询和插入的时候耗时太长,性能低下,如果涉及联合查询的情况,性能会更加糟糕.分表和表分区的目的就是减少数据库的负担,提高数据库的效率,通常点来讲就是提高表的增删改查效率.数据库中的数据量不一定是可控的,在未进行分
-
MySql分表、分库、分片和分区知识点介绍
一.前言 数据库的数据量达到一定程度之后,为避免带来系统性能上的瓶颈.需要进行数据的处理,采用的手段是分区.分片.分库.分表. 二.分片(类似分库) 分片是把数据库横向扩展(Scale Out)到多个物理节点上的一种有效的方式,其主要目的是为突破单节点数据库服务器的 I/O 能力限制,解决数据库扩展性问题.Shard这个词的意思是"碎片".如果将一个数据库当作一块大玻璃,将这块玻璃打碎,那么每一小块都称为数据库的碎片(DatabaseShard).将整个数据库打碎的过程就叫做分片,可以
-
MySQL分库分表与分区的入门指南
前言 关系型数据库比较容易成为系统瓶颈,单机存储容量.连接数.处理能力都有限,当数据量和并发量起来之后,就必须对数据库进行切分了. 数据切分(sharding)的手段就是分库分表.分库分表有两方面,可能是光分库不分表,也可能是光分表不分库. 数据库分布式的核心内容无非就是数据切分,以及切分后对数据的定位.整合. 为什么要分库分表 分表 单表数据量太大时,会严重影响sql执行的性能.一般单表到达几百万的时候,性能就会相对差一些了,这时就得分表了. 分表就是把一个表的数据放到多个表中,然后查询的时候