python更加灵活的Logger日志详解
用到的4个类:
1、Logger:
打印日志用的对象;
设置日志等级,添加移除handler,添加移除filter,设置下级Logger,使用各种方法打印日志;
创建方式有两种,使用logging.getLogger("mylog")和创建实例logging.Logger("mylog");
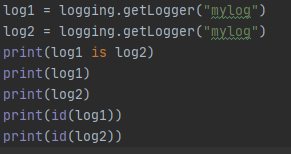
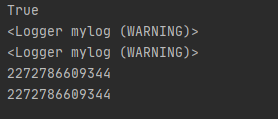
推荐使用getLogger()的方式,不传name参数的获得的Logger为root Logger,传name参数的上级为root Logger;
直接实例化的Logger没有上级,日志等级为NOTSET,并且用该实例创建的下级Logger的上级直接为root Logger;
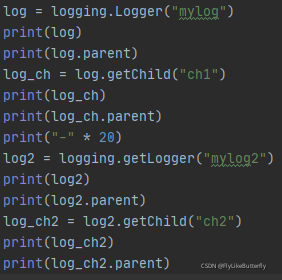

使用getLogger(name)传入相同的名字获得是同一个Logger;
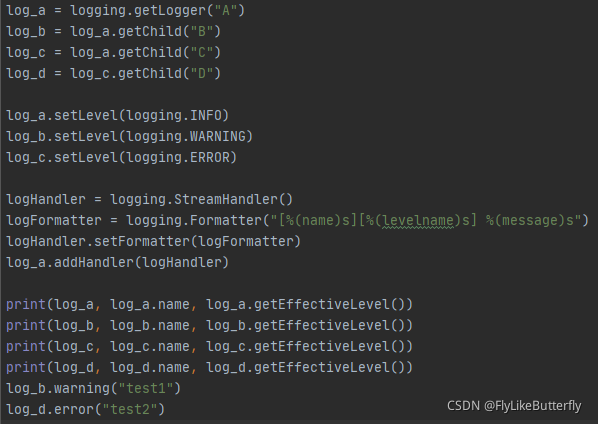
Logger拥有上下级关系,父子记录器名称之间用“.”分割,Logger拥有有效日志等级概念(getEffectiveLevel()方法返回的是日志等级整数值),直接新建实例创建的Logger日志等级为NOTSET,默认的根记录器为WARNING等级,如果NOTSET等级的Logger为根记录器则处理所有消息,否则会委托给父级记录器,遍历父记录器链,直到找到非NOTSET的父记录器并把该等级作为自己的有效等级,如果直到根记录器也是NOTSET则处理所有消息;
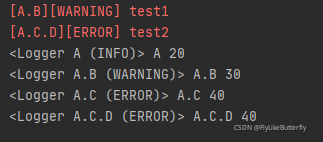
2、Formatter:
日志打印格式;
创建方式为logging.Formatter(fmt=None, datefmt=None, style='%', validate=True)
fmt:格式化日志
datefmt:格式化fmt中的%(asctime)s
style:在3.2版本添加
validate:在3.8版本添加,不正确或不匹配的样式和fmt将引发ValueError;
跟上一篇一致python的logging日志模块
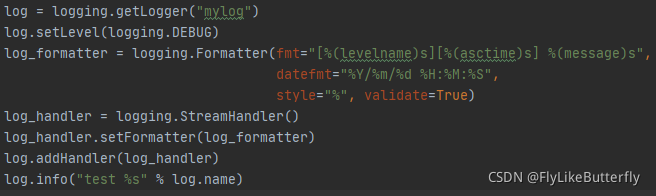
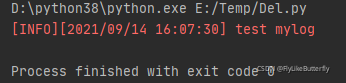
3、Filter:
过滤日志;
通过继承logging.Filter类,并实现 filter(self, record: LogRecord) -> int 方法,返回0或者False表示不通过,返回非0或者True表示可以通过;(from logging import LogRecord)
LogRecord可以操作的属性大概有这么多:
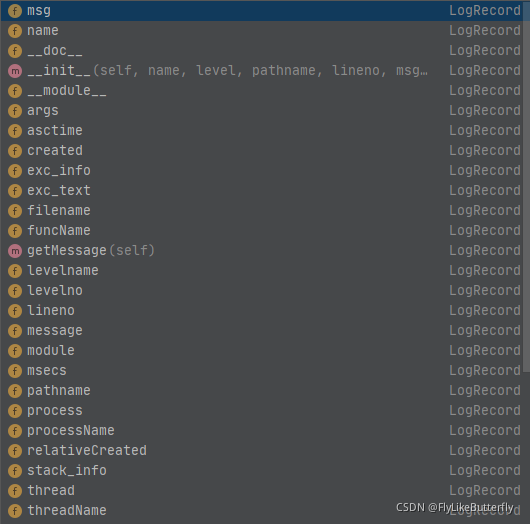
同一个Handler可以添加多个Filter,依次过滤,当前Filter通过后传递给下一个Filter;
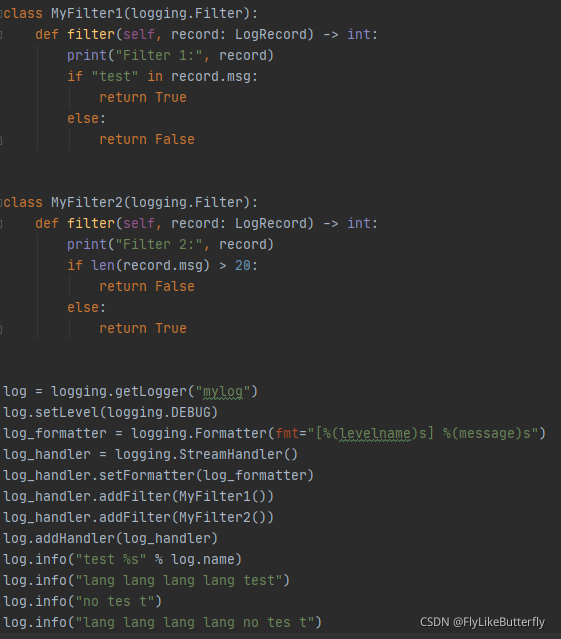
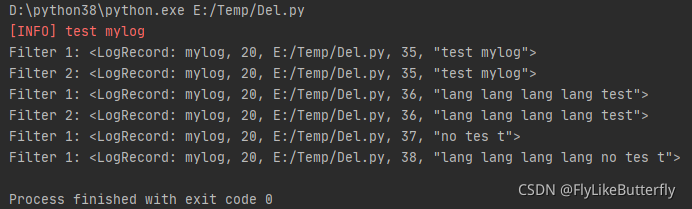
4、Handler:
日志输出方式;
设置日志等级,设置formatter,添加移除filter;
Logger可以添加多个handler,将日志按不同格式和过滤送往不同的地方,同一个Logger只会添加同一个handler一次,多次添加无影响;
子Logger处理完自己的handler后,会将日志传递给父Logger的handler处理,依次向上传递,不要将同一个handler同时添加到父子Logger里,否则父子Logger都会处理会打印多次相同日志;
可以通过设置Logger对象的propagate属性为False关闭传递给父Logger的handler;
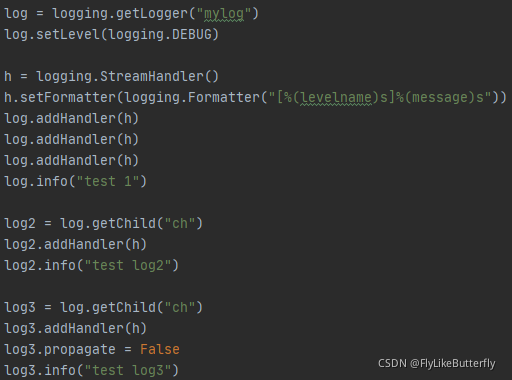
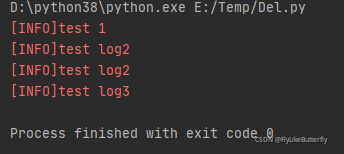
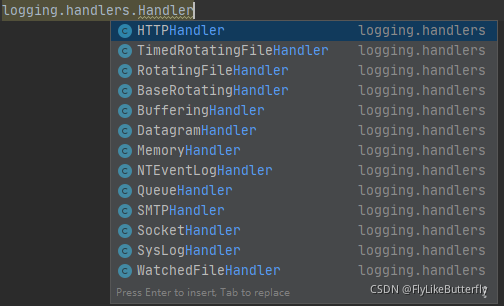
大概有这么多Handler:
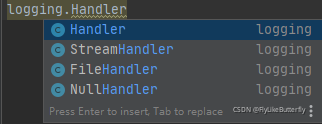
(from logging import handlers)
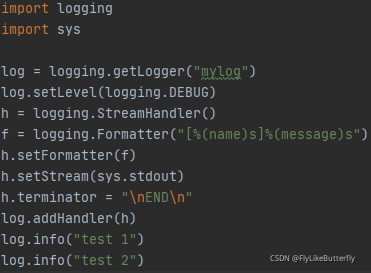
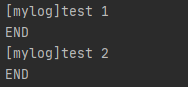
StreamHandler:
构造方法 logging.StreamHandler(stream=None)
将日志发送到像sys.stdout、sys.stderr或类似文件的对象中(支持write()和flush()方法的对象),默认使用sys.stderr,3.2版本后还有个terminator属性,可以设置终止符(默认“\n”);
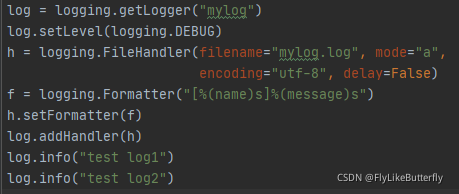
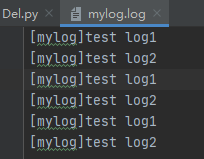
FileHandler:
构造方法 logging.FileHandler(filename, mode='a', encoding=None, delay=False)
将日志记录到文件中,默认文件将无限增长,如果delay为true,打开文件会延迟到第一次调用emit();
3.6版本开始,pathlib.Path也可以作为filename的值

NullHandler:
不做任何格式化和输出,提供给库开发人员使用;
WatchedFileHandler:
这是一个FileHandler,监控正在记录日志的文件,如果文件变动了则关闭文件重新打开;(windows系统不适用)
BaseRotatingHandler:
构造方法 logging.handlers.BaseRotatingHandler(filename, mode, encoding=None, delay=False)
是RotatingFileHandler和TimedRotatingFileHandler的基类,不需要实例化该类;
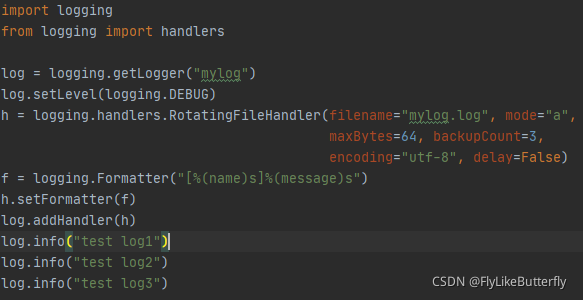
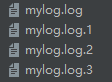
RotatingFileHandler:
构造方法 logging.handlers.RotatingFileHandler(filename, mode='a', maxBytes=0, backupCount=0, encoding=None, delay=False)
按照日志文件大小和备份日志文件数量保存日志到文件;
maxBytes或者backupCount为0则不会滚动日志,当日志大小接近maxBytes时会用“.1”“.2”“.3”...后缀保存旧文件,并保持旧文件数量不超过backupCount,当前日志一直是没有后缀的那个文件;
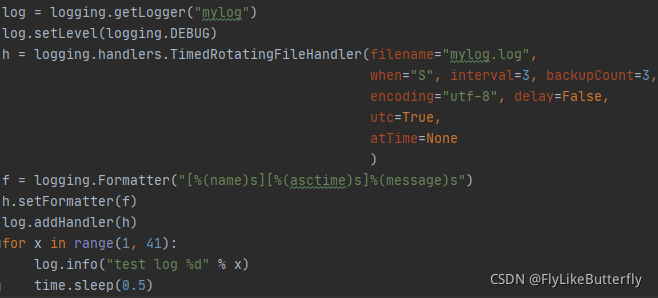
TimedRotatingFileHandler:
构造方法 logging.handlers.TimedRotatingFileHandler(filename, when='h', interval=1, backupCount=0, encoding=None, delay=False, utc=False, atTime=None)
按照时间间隔和备份文件数量保存日志到文件;
when:“S”秒,“M”分钟,“H”小时,“D”天,“W0”-“W6”工作日(W0为周一),“midnight”午夜(不指定atTime的时候午夜12点,否则按照atTime的时间滚动)
interval:时间间隔;
backupCount:保留文件数量上限;
utc:为true时文件名后缀使用UTC时间否则使用本地时间;
atTime:3.4添加,datetime.time类型,指定一天中发生滚动日志的时间,只有when为“midnight”或者“W0”-“W6”时有效;
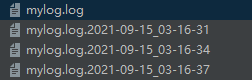
生成的备份文件文件名后缀格式为%Y-%m-%d_%H-%M-%S,第一次计算滚动时间(程序启动后)时会使用现有日志的最后修改时间或者当前时间计算;
SocketHandler:
构造方法 logging.handlers.SocketHandler(host, port)
将日志发送到网络套接字,基类使用的是TCP;
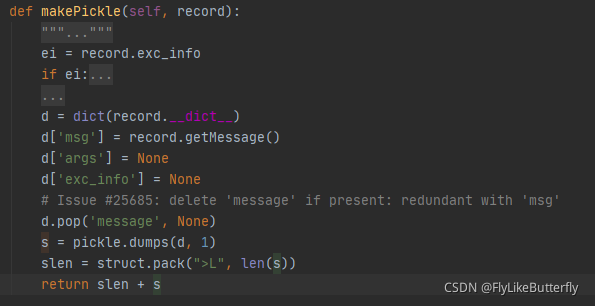
发送的二进制bytes是由编码的,由“内容长度+内容”组成,内容是用pickle序列化的一个dict(LogRecord,可以用logging.makeLogRecord(attrdict)转换),长度是用struct将序列化后的内容打包的一个大端无符号long数值,具体逻辑在SocketHandler类源码的makePickle()方法中有体现:
搞了半天才搞好的小demo(之前没看到编码方式还以为socket的编码,服务端接收数据解不出):
#!/usr/bin/env python3
# coding=utf-8
import logging
from logging import handlers
import time
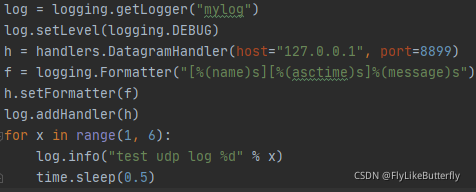
log = logging.getLogger("mylog")
log.setLevel(logging.DEBUG)
h = logging.handlers.SocketHandler(host="127.0.0.1", port=8899)
f = logging.Formatter("[%(name)s][%(asctime)s]%(message)s")
h.setFormatter(f)
log.addHandler(h)
for x in range(1, 6):
log.info("test log %d" % x)
time.sleep(0.5)
服务端demo:
#!/usr/bin/env python3
# coding=utf-8
import socket
import pickle
import struct
import logging
def unPickle(bs: bytes):
data_len_bytes = bs[0:4]
data_len = struct.unpack(">L", data_len_bytes)[0]
pickled_data = bs[4: data_len + 4 + 1]
return pickle.loads(pickled_data)
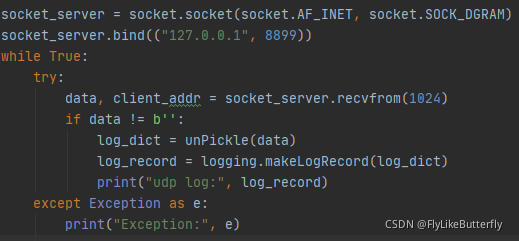
socket_server = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
socket_server.bind(("127.0.0.1", 8899))
socket_server.listen(3)
while True:
try:
client, client_addr = socket_server.accept()
while True:
data = client.recv(1024 * 10)
if data != b'':
log_dict = unPickle(data)
log_record = logging.makeLogRecord(log_dict)
print("recv log:", log_record)
except Exception as e:
print("Exception:", e)
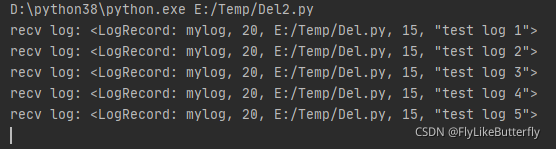
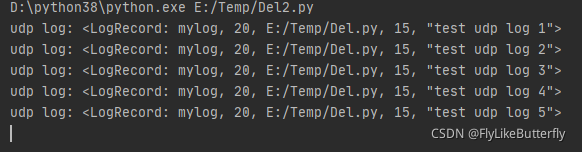
先运行socket服务,再测日志,因为连接不到服务日志会被丢弃,运行结果:
DatagramHandler:
构造方法 logging.handlers.DatagramHandler(host, port)
继承了SocketHandler,使用UDP发送,类似SocketHandler的使用;
SysLogHandler:
构造方法 logging.handlers.SysLogHandler(address=('localhost', SYSLOG_UDP_PORT), facility=LOG_USER, socktype=socket.SOCK_DGRAM)
将日志发送到远程或者本地的Unix系统日志,未指定address则使用('localhost', 514)地址;
NTEventLogHandler:
构造方法 logging.handlers.NTEventLogHandler(appname, dllname=None, logtype='Application')
将日志发送到本地的Windows NT、Windows 2000、Windows XP系统日志,使用时需要Mark Hammond's Win32的python扩展;
SMTPHandler:
构造方法 logging.handlers.SMTPHandler(mailhost, fromaddr, toaddrs, subject, credentials=None, secure=None, timeout=1.0)
将日志发送到电子邮件;
mailhost使用(host, port)元组,toaddrs是一个字符串列表,credentials可以用(username, password)元组指定用户名密码
MemoryHandler:
构造方法 logging.handlers.MemoryHandler(capacity, flushLevel=ERROR, target=None, flushOnClose=True)
支持在内存中缓冲日志,当缓存将满或者出现某种严重情况时把日志发送到目标handler;
是BufferingHandler的子类;
每当向缓冲区添加日志的时候都会调用shouldFlush()判断是否需要刷新,如果需要则会调用flush()刷新;
HTTPHandler:
构造方法 logging.handlers.HTTPHandler(host, url, method='GET', secure=False, credentials=None, context=None)
通过GET或者POST向一个web服务器发送日志;
如果要指定端口,host可以使用host:port值;
secure为true,则使用HTTPS;
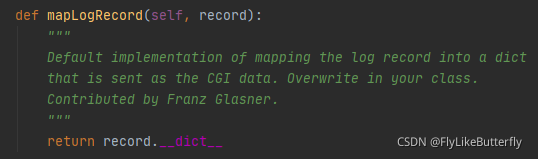
对HTTPHandler使用setFormatter()是无效的,HTTPHandler没有调用format()格式化,而是调用了mapLogRecord()方法然后使用urllib.parse.urlencode()编码的;
mapLogRecord()函数很简单(有需要可以重写):
而LogRecord()里是没有asctime字段的,所以log.asctime是错误的,但是logRecord里有created和msecs字段表时间:
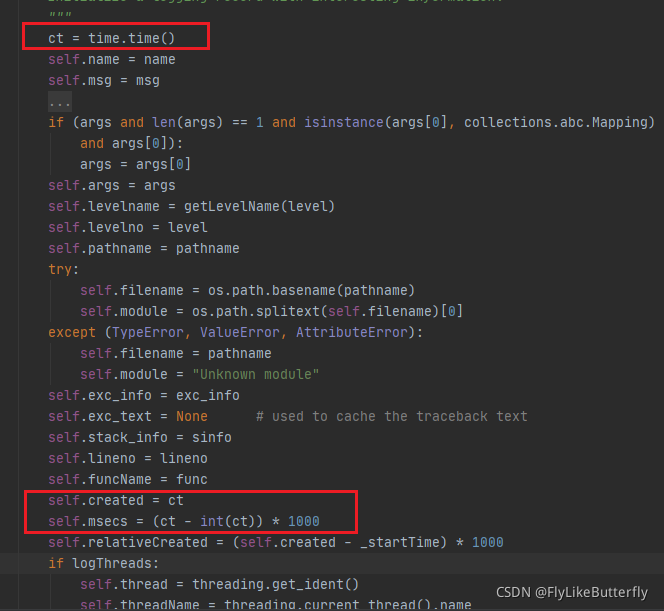
小小的demo:
#!/usr/bin/env python3
# coding=utf-8
import logging
from logging import handlers
import time
log = logging.getLogger("mylog")
log.setLevel(logging.DEBUG)
h_get = handlers.HTTPHandler(host="127.0.0.1:8080", url="test_http_log", method="GET",
secure=False, credentials=None, context=None)
log.addHandler(h_get)
h_post = handlers.HTTPHandler(host="127.0.0.1:8080", url="test_http_log", method="POST",
secure=False, credentials=None, context=None)
log.addHandler(h_post)
h = logging.StreamHandler()
f = logging.Formatter("[%(levelname)s][%(asctime)s]%(message)s")
h.setFormatter(f)
log.addHandler(h)
for x in range(1, 3):
log.info("test HTTP log %d" % x)
time.sleep(0.5)
http服务端:
#!/usr/bin/env python3
# coding=utf-8
from http.server import ThreadingHTTPServer, BaseHTTPRequestHandler
from urllib import parse
import logging
import time
class MyHttpServer(BaseHTTPRequestHandler):
def do_GET(self):
url = parse.urlparse(self.path)
q = parse.parse_qs(url.query)
log = logging.makeLogRecord(q)
log_created = time.localtime(float(log.created[0]))
format_time = time.strftime("%Y/%m/%d %H:%M:%S", log_created)
print("-GET:", log.name, log.levelname, log.msg, format_time+","+str(int(float(log.msecs[0])//1)))
self.send_response(200)
self.end_headers()
self.wfile.flush()
def do_POST(self):
length = int(self.headers["content-length"])
data = self.rfile.read(length)
data = data.decode(encoding="utf-8")
data_dict = parse.parse_qs(data)
data = logging.makeLogRecord(data_dict)
print("=POST:", data)
self.send_response(200)
self.end_headers()
self.wfile.flush()
httpserver = ThreadingHTTPServer(("127.0.0.1", 8080), MyHttpServer)
httpserver.serve_forever()
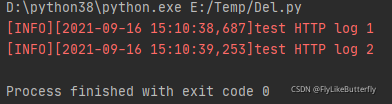
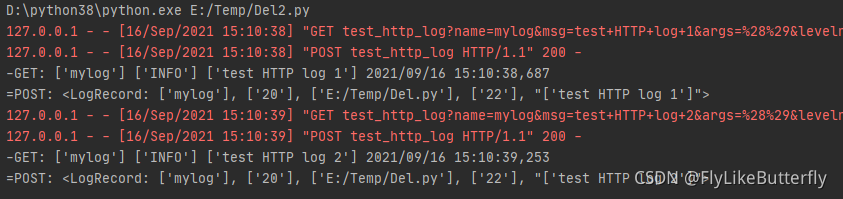
先运行服务端再跑日志demo,运行结果:
QueueHandler/QueueListener:
构造方法 logging.handlers.QueueHandler(queue)
logging.handlers.QueueListener(queue, *handlers, respect_handler_level=False)
将日志发送到队列,用于处理队列或者多线程模块情况;
queue可以是类队列的任何对象(原样传给dequeue()函数),也可以用queue.SimpleQueue代替queue;
QueueHandler的小demo:
#!/usr/bin/env python3
# coding=utf-8
import logging
from logging import handlers
from logging import LogRecord
import queue
class MyLogHandler(logging.Handler):
def handle(self, record: LogRecord) -> None:
print(record)
log = logging.getLogger("mylog")
log.setLevel(logging.DEBUG)
q = queue.SimpleQueue()
h = handlers.QueueHandler(q)
f = logging.Formatter("[%(levelname)s]%(message)s")
h.setFormatter(f)
log.addHandler(h)
listener = handlers.QueueListener(q, MyLogHandler(), respect_handler_level=False)
listener.start()
print("listener started")
log.info("test queue log1 info")
log.error("test queue log2 error")
listener.stop()
print("listener stopted")
log.info("test queue log3 info")
log.error("test queue log4 error")
print("test end")
执行结果:

常用Demo:
#!/usr/bin/env python3
# coding=utf-8
import logging
from logging import LogRecord
from logging import handlers
import sys
# log1 = logging.Logger("a", logging.DEBUG)
log1 = logging.getLogger("a")
_log1 = logging.getLogger("a")
print(log1 is _log1, id(log1), id(_log1))
log1.setLevel(logging.DEBUG)
log2 = log1.getChild("b")
log3 = log1.getChild("c")
print(log1)
print(log2)
print(log3)
h1 = logging.StreamHandler()
format1 = logging.Formatter("[H1] [%(levelname)-8s] %(message)s")
h1.setFormatter(format1)
log1.addHandler(h1)
h2 = logging.StreamHandler()
format2 = logging.Formatter(fmt="[H2][%(levelname)7s][%(asctime)s]%(message)s", datefmt="%c")
h2.setFormatter(format2)
class myFilter(logging.Filter):
def filter(self, record: LogRecord) -> int:
print("record:" + repr(record))
if "HELLO" in record.msg:
return True
else:
return False
h2.addFilter(myFilter())
log2.addHandler(h2)
# log2.addFilter(myFilter())
h3 = logging.StreamHandler()
format3 = logging.Formatter("[H3]{%(levelname)s}{%(name)s}%(message)s")
h3.setFormatter(format3)
h3.setStream(sys.stdout)
h3.setLevel(logging.INFO)
log3.addHandler(h3)
#
h3_file = logging.FileHandler(filename="test_Logging2.log", mode="w")
h3_file.setFormatter(logging.Formatter("[H3File][%(levelname)8s][%(asctime)s]%(message)s"))
log3.addHandler(h3_file)
#
h3_rotatingfile = handlers.RotatingFileHandler(filename="test_Logging2_rotating.log", mode="a",
maxBytes=256, backupCount=3,
encoding="utf-8", delay=False)
h3_rotatingfile.setFormatter(logging.Formatter("[h3_rotating][%(levelname)s] %(message)s"))
log3.addHandler(h3_rotatingfile)
#
h3_timedrotationgfile = handlers.TimedRotatingFileHandler(filename="test_Logging2_timedrotating.log",
when="S", interval=5,
backupCount=5, encoding="utf-8",
delay=False, utc=False,
# atTime=
)
h3_timedrotationgfile.setFormatter(logging.Formatter("[H3timed][%(levelname)s]%(message)s"))
log3.addHandler(h3_timedrotationgfile)
log3.propagate = False
log1.debug("test log1")
log1.warning("warn log1")
log2.debug("test log2 HELLO")
log2.info("info log2")
log2.warning("warn log2 HELLO")
log2.error("error log2")
log3.debug("test log3")
log3.warning("warn log3")
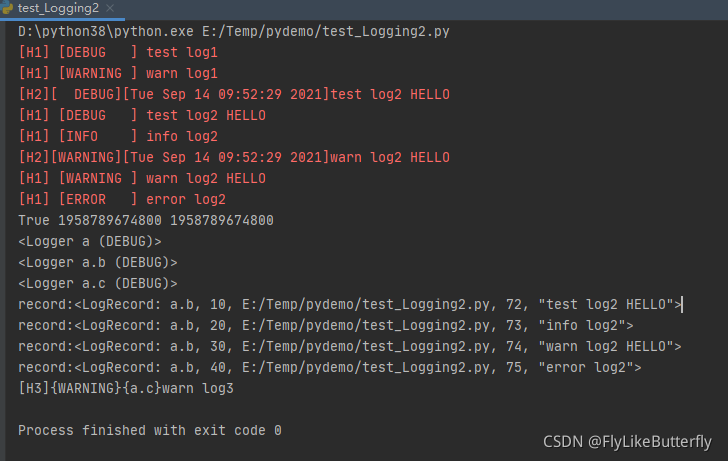
多次执行结果中的一次:
生成的日志文件:

参考:
logging — Logging facility for Python — Python 3.8.12 documentation
logging.handlers — Logging handlers — Python 3.8.12 documentation
Python3 日志(内置logging模块) - 天马行宇 - 博客园
到此这篇关于python更加灵活的Logger日志的文章就介绍到这了,更多相关python更加灵活的Logger日志内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
对python中的logger模块全面讲解
logging模块介绍 Python的logging模块提供了通用的日志系统,熟练使用logging模块可以方便开发者开发第三方模块或者是自己的Python应用.同样这个模块提供不同的日志级别,并可以采用不同的方式记录日志,比如文件,HTTP.GET/POST,SMTP,Socket等,甚至可以自己实现具体的日志记录方式.下文我将主要介绍如何使用文件方式记录log. logging模块包括logger,handler,filter,formatter这四个基本概念. logging模块与log4
-
Python日志打印里logging.getLogger源码分析详解
实践环境 WIN 10 Python 3.6.5 函数说明 logging.getLogger(name=None) getLogger函数位于logging/__init__.py脚本 源码分析 _loggerClass = Logger # ...略 root = RootLogger(WARNING) Logger.root = root Logger.manager = Manager(Logger.root) # ...略 def getLogger(name=None): "&quo
-

Python logging设置和logger解析
一.logging模块讲解 1.函数:logging.basicConfig() 参数讲解: (1)level代表高于或者等于这个值时,那么我们才会记录这条日志 (2)filename代表日志会写在这个文件之中,如果没有这个字段则会显示在控制台上 (3)format代表我们的日志显示的格式自定义,如果字段为空,那么默认格式为:level:log_name:content import logging LOG_FORMAT = "%(asctime)s======%(levelname)s++++
-
Python实现Logger打印功能的方法详解
前言 众所周知在Python中有专门用于logger打印的套件叫logging,但是该套件logger仅接收一个字符串类型的logger打印信息.因此,我们在使用是需要先提前将要打印的信息拼接成一个字符串之后才行,这样对于代码的整洁性并不好. 我在logging的基础上实现了一个类似于Java的logback的logger打印工具,实现比较简单,能够应对一些简单的logger打印需求,希望对大家能有帮助.下面话不多说了,来一起看看详细的介绍: LoggerFactory 该类用作生成其他调用类的
-
Python中logger日志模块详解
1 logging模块简介 logging模块是Python内置的标准模块,主要用于输出运行日志,可以设置输出日志的等级.日志保存路径.日志文件回滚等:相比print,具备如下优点: 可以通过设置不同的日志等级,在release版本中只输出重要信息,而不必显示大量的调试信息: print将所有信息都输出到标准输出中,严重影响开发者从标准输出中查看其它数据:logging则可以由开发者决定将信息输出到什么地方,以及怎么输出: Logger从来不直接实例化,经常通过logging模块级方法(Modu
-
在python中logger setlevel没有生效的解决
在logging中,Logger's level 的默认等级为warning 所以虽然在handler中setlervel了,Logger's level 和Handler's Level 但是level取较高的那个(待校验) 所以日志的level 为warning 解决此问题可以采用 logging.root.setLevel(logging.NOTSET) 完整源码如下图: import logging class loggerr(object): def __init__(self,log
-
详解Python logging调用Logger.info方法的处理过程
本次分析一下Logger.info的流程 1. Logger.info源码: def info(self, msg, *args, **kwargs): """ Log 'msg % args' with severity 'INFO'. To pass exception information, use the keyword argument exc_info with a true value, e.g. logger.info("Houston, we h
-
python更加灵活的Logger日志详解
用到的4个类: 1.Logger: 打印日志用的对象: 设置日志等级,添加移除handler,添加移除filter,设置下级Logger,使用各种方法打印日志: 创建方式有两种,使用logging.getLogger("mylog")和创建实例logging.Logger("mylog"): 推荐使用getLogger()的方式,不传name参数的获得的Logger为root Logger,传name参数的上级为root Logger: 直接实例化的Logger没有
-
python对于requests的封装方法详解
由于requests是http类接口的核心,因此封装前考虑问题比较多: 1. 对多种接口类型的支持: 2. 连接异常时能够重连: 3. 并发处理的选择: 4. 使用方便,容易维护: 当前并未全部实现,后期会不断完善.重点提一下并发处理的选择:python的并发处理机制由于存在GIL的原因,实现起来并不是很理想,综合考虑多进程.多线程.协程,在不考虑大并发性能测试的前提下使用了多线程-线程池的形式实现.使用的是 concurrent.futures模块.当前仅方便支持webservice接口. #
-
Python探索之URL Dispatcher实例详解
URL dispatcher简单点理解就是根据URL,将请求分发到相应的方法中去处理,它是对URL和View的一个映射,它的实现其实也很简单,就是一个正则匹配的过程,事先定义好正则表达式和该正则表达式对应的view方法,如果请求的URL符合这个正则表达式,那么就分发这个请求到这个view方法中. 有了这个base,我们先抛出几个问题,提前思考一下: 这个映射定义在哪里?当映射很多时,如果有效的组织? URL中的参数怎么获取,怎么传给view方法? 如何在view或者是template中反解出UR
-
Python selenium 三种等待方式详解(必会)
很多人在群里问,这个下拉框定位不到.那个弹出框定位不到-各种定位不到,其实大多数情况下就是两种问题:1 有frame,2 没有加等待.殊不知,你的代码运行速度是什么量级的,而浏览器加载渲染速度又是什么量级的,就好比闪电侠和凹凸曼约好去打怪兽,然后闪电侠打完回来之后问凹凸曼你为啥还在穿鞋没出门?凹凸曼分分中内心一万只羊驼飞过,欺负哥速度慢,哥不跟你玩了,抛个异常撂挑子了. 那么怎么才能照顾到凹凸曼缓慢的加载速度呢?只有一个办法,那就是等喽.说到等,又有三种等法,且听博主一一道来: 1. 强制等待
-
对Python强大的可变参数传递机制详解
今天模拟定义map函数.写着写着就发现Python可变长度参数的机制真是灵活而强大. 假设有一个元组t,包含n个成员: t=(arg1,...,argn) 而一个函数f恰好能接受n个参数: f(arg1,...,argn) f(t)这种做法显然是错的,那么如何把t的各成员作为独立的参数传给f,以便达到f(arg1,...,argn)的效果? 我一开始想到的是很原始的解法,先把t的各个成员变为字符串的形式,再用英文逗号把它们串联起来,形成一个"标准参数字符串": str_t=(str(x
-
Python定时任务APScheduler的实例实例详解
APScheduler 支持三种调度任务:固定时间间隔,固定时间点(日期),Linux 下的 Crontab 命令.同时,它还支持异步执行.后台执行调度任务. 一.基本架构 触发器 triggers:设定触发任务的条件 描述一个任务何时被触发,按日期或按时间间隔或按 cronjob 表达式三种方式触发 任务存储器 job stores:存放任务,可以放内存(默认)或数据库 注:调度器之间不能共享任务存储器 执行器 executors:用于执行任务,可设定执行模式 将指定的作业提交到线程池或者进程
-
对Python subprocess.Popen子进程管道阻塞详解
问题产生描述 使用子进程处理一个大的日志文件,并对文件进行分析查询,需要等待子进程执行的输出结果,进行下一步处理. 出问题的代码 # 启用子进程执行外部shell命令 def __subprocess(self,cmd): try: # 执行外部shell命令, 输出结果输出管道 p = subprocess.Popen(cmd, shell=True, stdout=subprocess.PIPE, stderr=subprocess.STDOUT) p.wait() # 从标准输出读出she
-
对python多线程SSH登录并发脚本详解
测试系统中有一项记录ssh登录日志,需要对此进行并发压力测试. 于是用多线程进行python并发记录 因为需要安装的一些依赖和模块比较麻烦,脚本完成后再用pyinstaller打成exe包分发给其他测试人员一起使用. 1.脚本编写 # -*- coding: utf-8 -*- import paramiko import threading import time lt = [] def ssh(a,xh,sp): count = 0 for i in range(0,xh): try: ss
-
python scrapy重复执行实现代码详解
这篇文章主要介绍了python scrapy重复执行实现代码详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,我们只需要实现少量的代码,就能够快速的抓取 Scrapy模块: 1.scheduler:用来存放url队列 2.downloader:发送请求 3.spiders:提取数据和url 4.itemPipeline:数据保存 from twisted.internet i
-
python 引用传递和值传递详解(实参,形参)
python中函数参数是引用传递(不是值传递).对于不可变类型,因变量不能被修改,所以运算时不会影响到变量本身:而对于可变类型来说,函数体中的运算有可能会更改传入的参数变量. 形参: 函数需要传递的参数 实参:调用函数时传递的参数 补充知识:python函数方法实参给形参传值时候的隐形'陷阱' 众所周知,在python函数里面参数分为形参,实参两种.形参当然了就是形式参数,而实参是我们需要给这个函数传入的变量,在我们给实参传入变量之后,调用函数,实参则自动会把数值或则变量赋予形参,从而通过函数得