python基于隐马尔可夫模型实现中文拼音输入
在网上看到一篇关于隐马尔科夫模型的介绍,觉得简直不能再神奇,又在网上找到大神的一篇关于如何用隐马尔可夫模型实现中文拼音输入的博客,无奈大神没给可以运行的代码,只能纯手动网上找到了结巴分词的词库,根据此训练得出隐马尔科夫模型,用维特比算法实现了一个简单的拼音输入法。githuh地址:https://github.com/LiuRoy/Pinyin_Demo
原理简介隐马尔科夫模型
抄一段网上的定义:
隐马尔可夫模型 (Hidden Markov Model) 是一种统计模型,用来描述一个含有隐含未知参数的马尔可夫过程。其难点是从可观察的参数中确定该过程的隐含参数,然后利用这些参数来作进一步的分析。
拼音输入法中可观察的参数就是拼音,隐含的参数就是对应的汉字。
viterbi算法
参考https://zh.wikipedia.org/wiki/维特比算法,思想是动态规划,代码比较简单就不赘述。
代码解释
model定义
代码见model/table.py文件,针对隐马尔科夫的三个概率矩阵,分别设计了三个数据表存储。这样的好处很明显,汉字的转移概率矩阵是一个非常大的稀疏矩阵,直接文件存储占用空间很大,并且加载的时候也只能一次性读入内存,不仅内存占用高而且加载速度慢。此外数据库的join操作非常方便viterbi算法中的概率计算。
数据表定义如下:
class Transition(BaseModel): __tablename__ = 'transition' id = Column(Integer, primary_key=True) previous = Column(String(1), nullable=False) behind = Column(String(1), nullable=False) probability = Column(Float, nullable=False) class Emission(BaseModel): __tablename__ = 'emission' id = Column(Integer, primary_key=True) character = Column(String(1), nullable=False) pinyin = Column(String(7), nullable=False) probability = Column(Float, nullable=False) class Starting(BaseModel): __tablename__ = 'starting' id = Column(Integer, primary_key=True) character = Column(String(1), nullable=False) probability = Column(Float, nullable=False)
模型生成
代码见train/main.py文件,里面的initstarting,initemission,init_transition分别对应于生成隐马尔科夫模型中的初始概率矩阵,发射概率矩阵,转移概率矩阵,并把生成的结果写入sqlite文件中。训练用到的数据集是结巴分词里的词库,因为没有训练长句子,最后运行的结果也证明只能适用于短句输入。
初始概率矩阵
统计初始化概率矩阵,就是找出所有出现在词首的汉字,并统计它们出现在词首的次数,最后根据上述数据算出这些汉字出现在词首的概率,没统计的汉字就认为出现在词首的概率是0,不写入数据库。有一点注意的是为了防止概率计算的时候因为越算越小导致计算机无法比较,所有的概率都进行了自然对数运算。统计的结果如下:
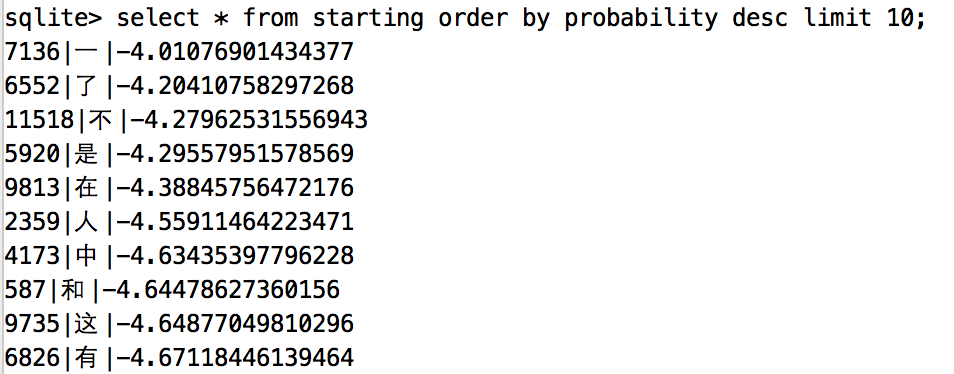
转移概率矩阵
此处用到的是最简单的一阶隐马尔科夫模型,即认为在一个句子里,每个汉字的出现只和它前面的的一个汉字有关,虽然简单粗暴,但已经可以满足大部分情况。统计的过程就是找出字典中每个汉字后面出现的汉字集合,并统计概率。因为这个概率矩阵非常的大,逐条数据写入数据库过慢,后续可以优化为批量写入,提高训练效率。结果如下:

上图展示的一后面出现概率最高的十个字,也挺符合日常习惯。
发射概率矩阵
通俗点就是统计每个汉字对应的拼音以及在日常情况下的使用概率,已暴举例,它有两个读音:bao和pu,难点就是找bao和pu出现的概率。此处统计用到了pypinyin模块,把字典中的短语转换为拼音后进行概率统计,但是某些地方读音也不完全正确,最后运行的输入法会出现和拼音不匹配的结果。统计结果如下:
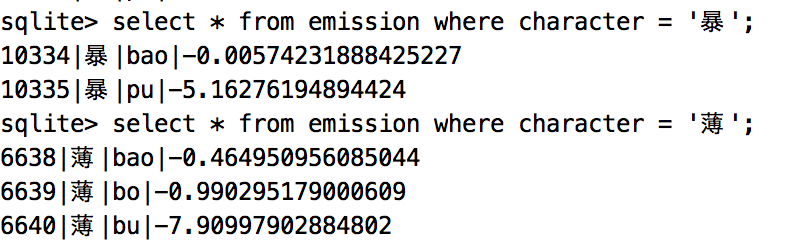
viterbi实现
代码建input_method/viterbi.py文件,此处会找到最多十个局部最优解,注意是十个局部最优解而不是十个全局最优解,但是这十个解中最优的那个是全局最优解,代码如下:
def viterbi(pinyin_list):
"""
viterbi算法实现输入法
Aargs:
pinyin_list (list): 拼音列表
"""
start_char = Emission.join_starting(pinyin_list[0])
V = {char: prob for char, prob in start_char}
for i in range(1, len(pinyin_list)):
pinyin = pinyin_list[i]
prob_map = {}
for phrase, prob in V.iteritems():
character = phrase[-1]
result = Transition.join_emission(pinyin, character)
if not result:
continue
state, new_prob = result
prob_map[phrase + state] = new_prob + prob
if prob_map:
V = prob_map
else:
return V
return V
结果展示
运行input_method/viterbi.py文件,简单的展示一下运行结果:

问题统计:
统计字典生成转移矩阵写入数据库的速度太慢,运行一次要将近十分钟。发射概率矩阵数据不准确,总有一些汉字的拼音不匹配。训练集太小,实现的输入法不适用于长句子。
相关推荐
-
用Python的SimPy库简化复杂的编程模型的介绍
在我遇到 SimPy 包的其中一位创始人 Klaus Miller 时,从他那里知道了这个包.Miller 博士阅读过几篇提出使用 Python 2.2+ 生成器实现半协同例程和"轻便"线程的技术的 可爱的 Python专栏文章.特别是(使我很高兴的是),他发现在用 Python 实现 Simula-67 样式模拟时,这些技术很有用. 结果表明 Tony Vignaux 和 Chang Chui 以前曾创建了另一个 Python 库,它在概念上更接近于 Simscript,而且该库使用
-

理解生产者消费者模型及在Python编程中的运用实例
什么是生产者消费者模型 在 工作中,大家可能会碰到这样一种情况:某个模块负责产生数据,这些数据由另一个模块来负责处理(此处的模块是广义的,可以是类.函数.线程.进程等).产 生数据的模块,就形象地称为生产者:而处理数据的模块,就称为消费者.在生产者与消费者之间在加个缓冲区,我们形象的称之为仓库,生产者负责往仓库了进商 品,而消费者负责从仓库里拿商品,这就构成了生产者消费者模型.结构图如下: 生产者消费者模型的优点: 1.解耦 假设生产者和消费者分别是两个类.如果让生产者直接调用消费者的某个方法,
-
用Python给文本创立向量空间模型的教程
我们需要开始思考如何将文本集合转化为可量化的东西.最简单的方法是考虑词频. 我将尽量尝试不使用NLTK和Scikits-Learn包.我们首先使用Python讲解一些基本概念. 基本词频 首先,我们回顾一下如何得到每篇文档中的词的个数:一个词频向量. #examples taken from here: http://stackoverflow.com/a/1750187 mydoclist = ['Julie loves me more than Linda loves me', 'Jane
-
基于python yield机制的异步操作同步化编程模型
本文总结下如何在编写python代码时对异步操作进行同步化模拟,从而提高代码的可读性和可扩展性. 游戏引擎一般都采用分布式框架,通过一定的策略来均衡服务器集群的资源负载,从而保证服务器运算的高并发性和CPU高利用率,最终提高游戏的性能和负载.由于引擎的逻辑层调用是非抢占式的,服务器之间都是通过异步调用来进行通讯,导致游戏逻辑无法同步执行,所以在代码层不得不人为地添加很多回调函数,使一个原本完整的功能碎片化地分布在各个回调函数中. 异步逻辑 以游戏中的副本评分逻辑为例,在副本结束时副本管理进程需要
-
Python探索之pLSA实现代码
pLSA(probabilistic Latent Semantic Analysis),概率潜在语义分析模型,是1999年Hoffman提出的一个被称为第一个能解决一词多义问题的模型,通过在文档与单词之间建立一层主题(Topic),将文档与单词的直接关联转化为文档与主题的关联以及主题与单词的关联.这里采用EM算法进行估计,可能存在差错,望积极批评指正. # -*- coding: utf-8 -*- import math import random import jieba import c
-
python基于隐马尔可夫模型实现中文拼音输入
在网上看到一篇关于隐马尔科夫模型的介绍,觉得简直不能再神奇,又在网上找到大神的一篇关于如何用隐马尔可夫模型实现中文拼音输入的博客,无奈大神没给可以运行的代码,只能纯手动网上找到了结巴分词的词库,根据此训练得出隐马尔科夫模型,用维特比算法实现了一个简单的拼音输入法.githuh地址:https://github.com/LiuRoy/Pinyin_Demo 原理简介隐马尔科夫模型 抄一段网上的定义: 隐马尔可夫模型 (Hidden Markov Model) 是一种统计模型,用来描述一个含有隐含未
-
python实现隐马尔科夫模型HMM
一份完全按照李航<<统计学习方法>>介绍的HMM代码,供大家参考,具体内容如下 #coding=utf8 ''''' Created on 2017-8-5 里面的代码许多地方可以精简,但为了百分百还原公式,就没有精简了. @author: adzhua ''' import numpy as np class HMM(object): def __init__(self, A, B, pi): ''''' A: 状态转移概率矩阵 B: 输出观察概率矩阵 pi: 初始化状态向量 '
-
Python实现隐马尔可夫模型的前向后向算法的示例代码
本篇文章对隐马尔可夫模型的前向和后向算法进行了Python实现,并且每种算法都给出了循环和递归两种方式的实现. 前向算法Python实现 循环方式 import numpy as np def hmm_forward(Q, V, A, B, pi, T, O, p): """ :param Q: 状态集合 :param V: 观测集合 :param A: 状态转移概率矩阵 :param B: 观测概率矩阵 :param pi: 初始概率分布 :param T: 观测序列和状态
-
Python一阶马尔科夫链生成随机DNA序列实现示例
目录 1. 原理 2. 代码实现 3. 运行结果 1. 原理 对于DNA序列,一阶马尔科夫链可以理解为当前碱基的类型仅取决于上一位碱基类型.如图1所示,一条序列的开端(由B开始)可能是A.T.G.C四种碱基(且可能性相同,均为0.25),若序列的某一位是A,则下一位碱基是A.T.G.C的概率分别为0.25.0.20.0.20.0.20,下一位无碱基(即序列结束,状态为E)的概率为0.15. 图1 DNA序列的一阶马尔科夫链 2. 代码实现 以下代码运行于Jupyter Notebook (Pyt
-
Python基于HOG+SVM/RF/DT等模型实现目标人行检测功能
当下基本所有的目标检测类的任务都会选择基于深度学习的方式,诸如:YOLO.SSD.RCNN等等,这一领域不乏有很多出色的模型,而且还在持续地推陈出新,模型的迭代速度很快,其实最早实现检测的时候还是基于机器学习去做的,HOG+SVM就是非常经典有效的一套框架,今天这里并不是说要做出怎样的效果,而是基于HOG+SVM来实践机器学习检测的流程. 这里为了方便处理,我是从网上找的一个数据集,主要是行人检测方向的,当然了这个用车辆检测.火焰检测等等的数据集都是可以的,本质都是一样的. 首先看下数据集,数据
-
用Python从0开始实现一个中文拼音输入法的思路详解
众所周知,中文输入法是一个历史悠久的问题,但也实在是个繁琐的活,不知道这是不是网上很少有人分享中文拼音输入法的原因,接着这次NLP Project的机会,我觉得实现一发中文拼音输入法,看看水有多深,结果发现还挺深的,但是基本效果还是能出来的,而且看别的组都做得挺好的,这次就分 享一下我们做的结果吧. (注:此文假设读者已经具备一些隐马尔可夫模型的知识) 任务描述 实现一个中文拼音输入法. 经过分析,分为以下几个模块来对中文拼音输入法进行实现: 核心功能包括拼音切分(SplitPinyin.py)
-
python实现马耳可夫链算法实例分析
本文实例讲述了python实现马耳可夫链算法的方法.分享给大家供大家参考.具体分析如下: 在<程序设计实践>(英文名<The Practice of Programming>)的书中,第三章分别用C语言,C++,AWK和Perl分别实现了马耳可夫链算法,来通过输入的文本,"随机"的生成一些有用的文本. 说明: 1. 程序使用了字典,字典和散列可不是一个东西,字典是键值对的集合,而散列是一种能够常数阶插入,删除,不过可以用散列来实现字典. 2. 字典的setdef
-
Python基于回溯法子集树模板解决马踏棋盘问题示例
本文实例讲述了Python基于回溯法子集树模板解决马踏棋盘问题.分享给大家供大家参考,具体如下: 问题 将马放到国际象棋的8*8棋盘board上的某个方格中,马按走棋规则进行移动,走遍棋盘上的64个方格,要求每个方格进入且只进入一次,找出一种可行的方案. 分析 说明:这个图是5*5的棋盘. 类似于迷宫问题,只不过此问题的解长度固定为64 每到一格,就有[(-2,1),(-1,2),(1,2),(2,1),(2,-1),(1,-2),(-1,-2),(-2,-1)]顺时针8个方向可以选择. 走到一
-
基于Python获取亚马逊的评论信息的处理
目录 一.分析亚马逊的评论请求 二.获取亚马逊评论的内容 三.亚马逊评论信息的处理 四.代码整合 4.1代理设置 4.2while循环翻页 总结 上次亚马逊的商品信息都获取到了,自然要看一下评论的部分.用户的评论能直观的反映当前商品值不值得购买,亚马逊的评分信息也能获取到做一个评分的权重. 亚马逊的评论区由用户ID,评分及评论标题,地区时间,评论正文这几个部分组成,本次获取的内容就是这些. 测试链接:https://www.amazon.it/product-reviews/B08GHGTGQ2
-
python 基于空间相似度的K-means轨迹聚类的实现
这里分享一些轨迹聚类的基本方法,涉及轨迹距离的定义.kmeans聚类应用. 需要使用的python库如下 import pandas as pd import numpy as np import random import os import matplotlib.pyplot as plt import seaborn as sns from scipy.spatial.distance import cdist from itertools import combinations from