Python实现Excel自动分组合并单元格
大家好,我们经常会有这样的需求。比如下图
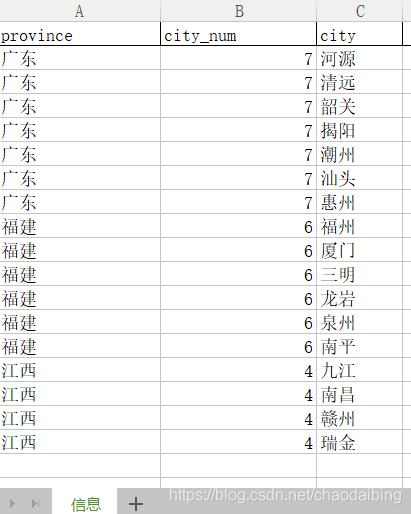
我们需要把同一个省份的合并起来,如下图的效果

如何实现呢,这是原有的df

直观的操作是这样的:
df.to_excel('test.xlsx',index=False)
from openpyxl import load_workbook
wb=load_workbook('test.xlsx')
ws=wb.active()
ws.merge_cells(start_row=2,end_row=8,start_column=1,end_column=1)
ws.merge_cells(start_row=2,end_row=8,start_column=2,end_column=2)
ws.merge_cells(start_row=9,end_row=14,start_column=1,end_column=1)
ws.merge_cells(start_row=9,end_row=14,start_column=2,end_column=2)
ws.merge_cells(start_row=15,end_row=18,start_column=1,end_column=1)
ws.merge_cells(start_row=15,end_row=18,start_column=2,end_column=2)
wb.save()
只是问题在于我们不能总是人工判断start_row和end_row,如何能使程序自动获取row的起始点呢?其实我们使用一个groupby就发现了方法了!大家看到了吗?

真是柳暗花明又一村啊,完整解决方案已经有了,我封装到了tkinter里面,请看!
#-*- coding:utf-8 -*-
import tkinter as tk #使用Tkinter前需要先导入
from tkinter import filedialog,messagebox,ttk
from openpyxl import load_workbook
from openpyxl.styles import Alignment
import os
import pandas as pd
#建立窗口window
window = tk.Tk()
window.title('Excel合并单元格工具')
w_width=630
w_height=600
scn_width=window.maxsize()[0]
x_point=(scn_width-w_width)//2
window.geometry('%dx%d+%d+%d' %(w_width,w_height,x_point,100))
window.wm_attributes('-topmost',True)
window.tk_focusFollowsMouse()
window.bind("<Escape>",lambda event:window.iconify())
path_tar=tk.StringVar()
sheetvar=tk.StringVar() #目标工作表
#打开目标文件
def getmergefile():
file_path=filedialog.askopenfilename(title=u'选择文件',filetype=[('Excel','.xlsx')])
path_tar.set(file_path)
alldata=pd.read_excel(file_path,None)
ttk.Label(frame1,text="请选择目标工作表:").grid(row=1,column=0,sticky='w')
global sheetvar
chosen_sheet=ttk.Combobox(frame1,width=16,textvariable=sheetvar)
chosen_sheet['values']=list(alldata)
chosen_sheet.grid(row=1,column=1,sticky='w')
chosen_sheet.bind("<<ComboboxSelected>>",lambda event:getmergeseg(event,alldata,sheetvar.get()))
#勾选目标字段
def getmergeseg(event,alldata,sheet):
global frame2,segvars
segvars=[]
try:
frame2.destroy()
except:
pass
frame2=tk.Frame(window,padx=15,pady=6)
frame2.grid(row=1,column=0,sticky='w')
ttk.Label(frame2,text="请勾选分组合并的目标字段(第一个勾选框为分组合并依据,必须事先进行排序:").grid(row=0,column=0,columnspan=4,sticky='w')
data=alldata[sheet]
for index,item in enumerate(data.columns):
segvars.append(tk.StringVar())
ttk.Checkbutton(frame2,text=item,variable=segvars[-1],onvalue=item,offvalue='').grid(row=(index//4+1),column=index%4,sticky='w')
#合并字段单元格
def merging(file,sheet,segvars):
selected=[i.get() for i in segvars if i.get()]
df=pd.read_excel(file,sheet)
wb=load_workbook(file)
ws=wb[sheet]
mergecells(ws,df,selected)
try:
wb.save(file)
messagebox.showinfo('提示',file+'-'+sheet+'指定单元格合并完成')
os.system('start '+os.path.dirname(file))
except Exception as e:
messagebox.showerror('警告',str(e))
#合并单元格函数
def mergecells(ws,df,cols):
col=cols[0]
gdic=df.groupby(col).groups
aligncenter=Alignment(horizontal='center',vertical='center')
for gname in gdic:
indexs=gdic[gname]+2
indexs=indexs.sort_values()
for col in cols: #每一个要合并的字段
colindex=df.columns.tolist().index(col)+1
ws.merge_cells(start_row=indexs[0],end_row=indexs[-1],start_column=colindex,end_column=colindex) #合并
for i in range(1,ws.max_row+1): #实现居中
ws.cell(row=i,column=colindex).alignment=aligncenter
def manual(): #使用说明
info="""
作用是合并单元格,把同样内容的单元格合并到一起,所以必须实现对目标字段进行排序,否则无法实现合并
"""
messagebox.showinfo('提示',info)
frame1=tk.Frame(window,pady=6,padx=15)
frame1.grid(row=0,column=0,sticky='w')
ttk.Button(frame1,text="打开目标文件",command=getmergefile).grid(row=0,column=0,sticky='w')
ttk.Entry(frame1,textvariable=path_tar,width=40).grid(row=0,column=1)
frame3=tk.Frame(window,pady=10,padx=15)
frame3.grid(row=2,column=0,sticky='w')
ttk.Button(frame3,text="点击合并单元格",command=lambda:merging(path_tar.get(),sheetvar.get(),segvars)).grid(row=0,column=0,sticky='w')
ttk.Button(frame3,text="使用说明",command=manual).grid(row=0,column=1)
window.mainloop()
效果如图:

以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
python 实现读取一个excel多个sheet表并合并的方法
如下所示: import xlrd import pandas as pd from pandas import DataFrame DATA_DIR = 'E:/' excel_name = '%s2017.xls' % DATA_DIR wb = xlrd.open_workbook(excel_name) # print(wb) # 获取workbook中所有的表格 sheets = wb.sheet_names() # print(sheets) # 循环遍历所有sheet df_28
-
Python DataFrame.groupby()聚合函数,分组级运算
pandas提供了一个灵活高效的groupby功能,它使你能以一种自然的方式对数据集进行切片.切块.摘要等操作.根据一个或多个键(可以是函数.数组或DataFrame列名)拆分pandas对象.计算分组摘要统计,如计数.平均值.标准差,或用户自定义函数.对DataFrame的列应用各种各样的函数.应用组内转换或其他运算,如规格化.线性回归.排名或选取子集等.计算透视表或交叉表.执行分位数分析以及其他分组分析. groupby分组函数: 返回值:返回重构格式的DataFrame,特别注意,grou
-

使用python将多个excel文件合并到同一个文件的方法
应用场景:使用pandas把多个相同结构的Excel文件合并为一个. 原始数据: 相关代码: import os import pandas as pd # 将文件读取出来放一个列表里面 pwd = 'test' # 获取文件目录 # 新建列表,存放文件名 file_list = [] # 新建列表存放每个文件数据(依次读取多个相同结构的Excel文件并创建DataFrame) dfs = [] for root,dirs,files in os.walk(pwd): # 第一个为起始路径,第二
-
Python批量合并有合并单元格的Excel文件详解
合并单元格 合并单元格相信大家都会,比如下面这段简单的代码就可以实现: app='Word' word=win32.gencache.EnsureDispatch('%s.Application' % app) doc=word.Documents.Add() word.Visible=False #Title begin sel =word.Selection sel.Font.Name = u"微软雅黑" sel.Font.Size = 8 sel.Font.Bold = Fals
-
Python Pandas实现数据分组求平均值并填充nan的示例
Python实现按某一列关键字分组,并计算各列的平均值,并用该值填充该分类该列的nan值. DataFrame数据格式 fillna方式实现 groupby方式实现 DataFrame数据格式 以下是数据存储形式: fillna方式实现 1.按照industryName1列,筛选出业绩 2.筛选出相同行业的Series 3.计算平均值mean,采用fillna函数填充 4.append到新DataFrame中 5.循环遍历行业名称,完成2,3,4步骤 factordatafillna = pd.
-
python之DataFrame实现excel合并单元格
在工作中经常遇到需要将数据输出到excel,且需要对其中一些单元格进行合并,比如如下表表格,需要根据A列的值,合并B.C列的对应单元格 pandas中的to_excel方法只能对索引进行合并,而xlsxwriter中,虽然提供有merge_range方法,但是这只是一个和基础的方法,每次都需要编写繁琐的测试才能最终调好,而且不能很好的重用.所以想自己写一个方法,结合dataframe和merge_range.大概思路是: 1.定义一个MY_DataFrame类,继承DataFrame类,这样能很
-
Python将多个excel表格合并为一个表格
生活中经常会碰到多个excel表格汇总成一个表格的情况,比如你发放了一份表格让班级所有同学填写,而你负责将大家的结果合并成一个.诸如此类的问题有很多.除了人工将所有表格的内容一个一个复制到汇总表格里,那么如何用Python自动实现这些工作呢~ 我不知道有没有其他更方便的合并方法,先用Python实现这个功能,自己用就很方便了. 比如,在文件夹下有如下7个表格(想象一下有100个或更多的表格需要合并) 作为样例,每个表格的内容均为 运行程序,将7个表格合并成了test.xls 打开test.xls
-
Python合并多个Excel数据的方法
安装模块 1.找到对应的模块 http://www.python-excel.org/ 2.用pip install 安装 pip install xlrd pip install XlsxWriter pip list查看 XlsxWriter示例 import xlsxwriter # 创建一个工作簿并添加一个工作表 workbook = xlsxwriter.Workbook("demo.xlsx") worksheet = workbook.add_worksheet()
-
Python正则表达式分组概念与用法详解
本文实例讲述了Python正则表达式分组概念与用法.分享给大家供大家参考,具体如下: 正则表达式分组 分组就是用一对圆括号"()"括起来的正则表达式,匹配出的内容就表示一个分组.从正则表达式的左边开始看,看到的第一个左括号"("表示第一个分组,第二个表示第二个分组,依次类推,需要注意的是,有一个隐含的全局分组(就是0),就是整个正则表达式. 分完组以后,要想获得某个分组的内容,直接使用group(num)和groups()函数去直接提取就行. 例如:提取代码中的超链
-
Python在groupby分组后提取指定位置记录方法
在进行数据分析.数据建模时,我们首先要做的就是对数据进行处理,提取我们需要的信息.下面为大家介绍一些groupby的用法,以便能够更加方便地进行数据处理. 我们往往在使用groupby进行信息提取时,往往是求分组后样本的一些统计量(max.min,var等).如果现在我们希望取一下分组后样本的第二条记录,倒数第三条记录,这个该如何操作呢?我们可以通过first.last来提取分组后第一条和最后一条样本.但如果我们要取指定位置的样本,就没有现成的函数.需要我们自己去写了.下面我就为大家介绍如何实现