python利用K-Means算法实现对数据的聚类案例详解
目的是为了检测出采集数据中的异常值。所以很明确,这种情况下的簇为2:正常数据和异常数据两大类
1、安装相应的库
import matplotlib.pyplot as plt # 用于可视化 from sklearn.cluster import KMeans # 用于聚类 import pandas as pd # 用于读取文件
2、实现聚类
2.1 读取数据并可视化
# 读取本地数据文件
df = pd.read_excel("../data/output3.xls", header=0)
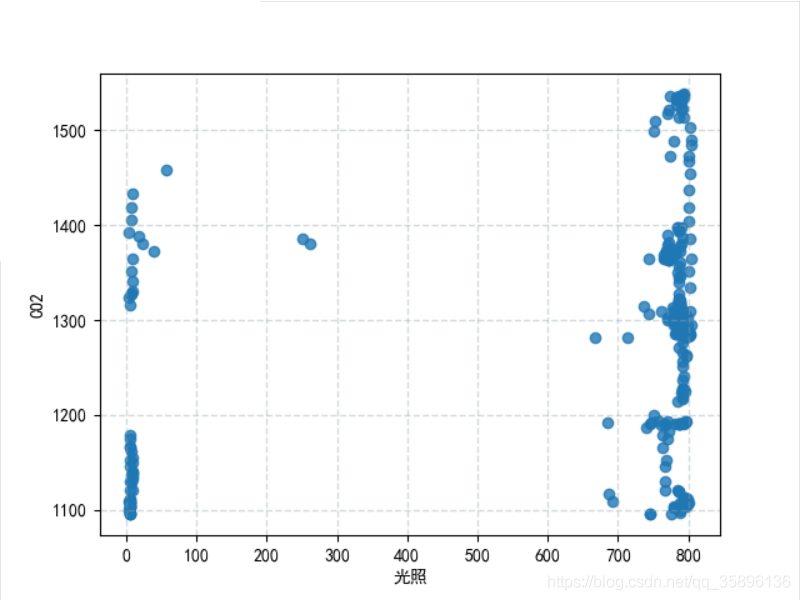
本次实验选择温度和CO2作为二维数据,其中温度含有异常数据。
plt.scatter(df["光照"], df["CO2"], linewidths=1, alpha=0.8)
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签v
plt.xlabel("光照")
plt.ylabel("CO2")
plt.grid(color="#95a5a6", linestyle="--", linewidth=1, alpha=0.4)
plt.show()
2.2 K-means聚类
设置规定要聚的类别个数为2
data = df[["光照","CO2"]] # 从原始数据中选择该两项 estimator = KMeans(n_clusters=2) # 构造聚类器 estimator.fit(data) # 将数据带入聚类模型
获取聚类中心的值和聚类标签
label_pred = estimator.labels_ # 获取聚类标签 centers_ = estimator.cluster_centers_ # 获取聚类中心
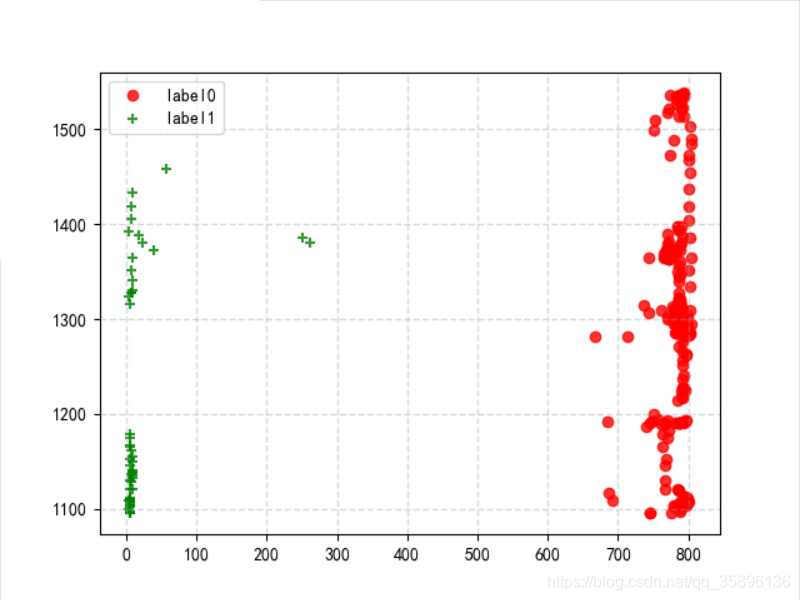
将聚类后的 label0 和 label1 的数据进行输出
x0 = data[label_pred == 0] x1 = data[label_pred == 1] plt.scatter(x0["光照"], x0["CO2"],c="red", linewidths=1, alpha=0.8,marker='o', label='label0') plt.scatter(x1["光照"], x1["CO2"],c="green", linewidths=1, alpha=0.8,marker='+', label='label1') plt.grid(c="#95a5a6", linestyle="--", linewidth=1, alpha=0.4) plt.legend() plt.show()
附上全部代码
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
import pandas as pd
df = pd.read_excel("../data/output3.xls", header=0)
plt.scatter(df["光照"], df["CO2"], linewidths=1, alpha=0.8)
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签v
plt.xlabel("光照")
plt.ylabel("CO2")
plt.grid(color="#95a5a6", linestyle="--", linewidth=1, alpha=0.4)
plt.show()
data = df[["光照","CO2"]]
estimator = KMeans(n_clusters=2) # 构造聚类器
estimator.fit(data) # 聚类
label_pred = estimator.labels_ # 获取聚类标签
centers_ = estimator.cluster_centers_ # 获取聚类结果
# print("聚类标签",label_pred)
# print("聚类结果",centers_)
# predict = estimator.predict([[787.75862069, 1505]]) # 测试新数据聚类结果
# print(predict)
x0 = data[label_pred == 0]
x1 = data[label_pred == 1]
plt.scatter(x0["光照"], x0["CO2"],c="red", linewidths=1, alpha=0.8,marker='o', label='label0')
plt.scatter(x1["光照"], x1["CO2"],c="green", linewidths=1, alpha=0.8,marker='+', label='label1')
plt.grid(c="#95a5a6", linestyle="--", linewidth=1, alpha=0.4)
plt.legend()
plt.show()
到此这篇关于python利用K-Means算法实现对数据的聚类的文章就介绍到这了,更多相关python K-Means算法数据的聚类内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python实现鸢尾花三种聚类算法(K-means,AGNES,DBScan)
一.分散性聚类(kmeans) 算法流程: 1.选择聚类的个数k. 2.任意产生k个聚类,然后确定聚类中心,或者直接生成k个中心. 3.对每个点确定其聚类中心点. 4.再计算其聚类新中心. 5.重复以上步骤直到满足收敛要求.(通常就是确定的中心点不再改变. 优点: 1.是解决聚类问题的一种经典算法,简单.快速 2.对处理大数据集,该算法保持可伸缩性和高效率 3.当结果簇是密集的,它的效果较好 缺点 1.在簇的平均值可被定义的情况下才能使用,可能不适用于某些应用 2.必须事先给出k(要生成的簇的数
-
Python用K-means聚类算法进行客户分群的实现
一.背景 1.项目描述 你拥有一个超市(Supermarket Mall).通过会员卡,你用有一些关于你的客户的基本数据,如客户ID,年龄,性别,年收入和消费分数. 消费分数是根据客户行为和购买数据等定义的参数分配给客户的. 问题陈述:你拥有这个商场.想要了解怎么样的顾客可以很容易地聚集在一起(目标顾客),以便可以给营销团队以灵感并相应地计划策略. 2.数据描述 字段名 描述 CustomerID 客户编号 Gender 性别 Age 年龄 Annual Income (k$) 年收入,单位为千
-

K-means聚类算法介绍与利用python实现的代码示例
聚类 今天说K-means聚类算法,但是必须要先理解聚类和分类的区别,很多业务人员在日常分析时候不是很严谨,混为一谈,其实二者有本质的区别. 分类其实是从特定的数据中挖掘模式,作出判断的过程.比如Gmail邮箱里有垃圾邮件分类器,一开始的时候可能什么都不过滤,在日常使用过程中,我人工对于每一封邮件点选"垃圾"或"不是垃圾",过一段时间,Gmail就体现出一定的智能,能够自动过滤掉一些垃圾邮件了.这是因为在点选的过程中,其实是给每一条邮件打了一个"标签&qu
-
k-means 聚类算法与Python实现代码
k-means 聚类算法思想先随机选择k个聚类中心,把集合里的元素与最近的聚类中心聚为一类,得到一次聚类,再把每一个类的均值作为新的聚类中心重新聚类,迭代n次得到最终结果分步解析 一.初始化聚类中心 首先随机选择集合里的一个元素作为第一个聚类中心放入容器,选择距离第一个聚类中心最远的一个元素作为第二个聚类中心放入容器,第三.四...N个同理,为了优化可以选择距离开方做为评判标准 二.迭代聚类 依次把集合里的元素与距离最近的聚类中心分为一类,放到对应该聚类中心的新的容器,一次聚类完成后求出新容器里
-
python基于K-means聚类算法的图像分割
1 K-means算法 实际上,无论是从算法思想,还是具体实现上,K-means算法是一种很简单的算法.它属于无监督分类,通过按照一定的方式度量样本之间的相似度,通过迭代更新聚类中心,当聚类中心不再移动或移动差值小于阈值时,则就样本分为不同的类别. 1.1 算法思路 随机选取聚类中心 根据当前聚类中心,利用选定的度量方式,分类所有样本点 计算当前每一类的样本点的均值,作为下一次迭代的聚类中心 计算下一次迭代的聚类中心与当前聚类中心的差距 如4中的差距小于给定迭代阈值时,迭代结束.反之,至2继续下
-
python实现k-means聚类算法
k-means聚类算法 k-means是发现给定数据集的k个簇的算法,也就是将数据集聚合为k类的算法. 算法过程如下: 1)从N个文档随机选取K个文档作为质心 2)对剩余的每个文档测量其到每个质心的距离,并把它归到最近的质心的类,我们一般取欧几里得距离 3)重新计算已经得到的各个类的质心 4)迭代步骤(2).(3)直至新的质心与原质心相等或迭代次数大于指定阈值,算法结束 算法实现 随机初始化k个质心,用dict保存质心的值以及被聚类到该簇中的所有data. def initCent(dataSe
-
Python机器学习算法之k均值聚类(k-means)
一开始的目的是学习十大挖掘算法(机器学习算法),并用编码实现一遍,但越往后学习,越往后实现编码,越发现自己的编码水平低下,学习能力低.这一个k-means算法用Python实现竟用了三天时间,可见编码水平之低,而且在编码的过程中看了别人的编码,才发现自己对numpy认识和运用的不足,在自己的代码中有很多可以优化的地方,比如求均值的地方可以用mean直接对数组求均值,再比如去最小值的下标,我用的是argsort排序再取列表第一个,但是有argmin可以直接用啊.下面的代码中这些可以优化的并没有改,
-
python中实现k-means聚类算法详解
算法优缺点: 优点:容易实现 缺点:可能收敛到局部最小值,在大规模数据集上收敛较慢 使用数据类型:数值型数据 算法思想 k-means算法实际上就是通过计算不同样本间的距离来判断他们的相近关系的,相近的就会放到同一个类别中去. 1.首先我们需要选择一个k值,也就是我们希望把数据分成多少类,这里k值的选择对结果的影响很大,Ng的课说的选择方法有两种一种是elbow method,简单的说就是根据聚类的结果和k的函数关系判断k为多少的时候效果最好.另一种则是根据具体的需求确定,比如说进行衬衫尺寸的聚
-
python利用K-Means算法实现对数据的聚类案例详解
目的是为了检测出采集数据中的异常值.所以很明确,这种情况下的簇为2:正常数据和异常数据两大类 1.安装相应的库 import matplotlib.pyplot as plt # 用于可视化 from sklearn.cluster import KMeans # 用于聚类 import pandas as pd # 用于读取文件 2.实现聚类 2.1 读取数据并可视化 # 读取本地数据文件 df = pd.read_excel("../data/output3.xls", heade
-
python数据XPath使用案例详解
目录 XPath XPath使用方法 xpath解析原理: 安装lxml 案例-58二手房 XPath XPath即为XML路径语言(XML Path Language),它是一种用来确定XML文档中某部分位置的语言. XPath使用方法 xpath解析原理: 1.实例化一个etree的对象,且需要将被解析的页面源代码数据加载到该对象中 2.调用etree对象中的xpath方法结合着xpath表达式实现标签的定位和内容的捕获 安装lxml pip install -i https://mirro
-
PHP结合Redis+MySQL实现冷热数据交换应用案例详解
本文实例讲述了PHP结合Redis+MySQL实现冷热数据交换应用案例.分享给大家供大家参考,具体如下: 场景:某网站需要对其项目做一个投票系统,投票项目上线后一小时之内预计有100万用户进行投票,希望用户投票完就能看到实时的投票情况 这个场景可以使用redis+mysql冷热数据交换来解决. 何为冷热数据交换? 冷数据:之前使用的数据,热数据:当前使用的数据. 交换:将Redis中的数据周期的存储到MySQL中 业务流程 用户进行投票后,首先将投票数据保存到Redis中,这些数据就是热数据,然
-
Python实现K-means聚类算法并可视化生成动图步骤详解
K-means算法介绍 简单来说,K-means算法是一种无监督算法,不需要事先对数据集打上标签,即ground-truth,也可以对数据集进行分类,并且可以指定类别数目 牧师-村民模型 K-means 有一个著名的解释:牧师-村民模型: 有四个牧师去郊区布道,一开始牧师们随意选了几个布道点,并且把这几个布道点的情况公告给了郊区所有的村民,于是每个村民到离自己家最近的布道点去听课. 听课之后,大家觉得距离太远了,于是每个牧师统计了一下自己的课上所有的村民的地址,搬到了所有地址的中心地带,并且在海
-
Python 经典贪心算法之Prim算法案例详解
最小生成树的Prim算法也是贪心算法的一大经典应用.Prim算法的特点是时刻维护一棵树,算法不断加边,加的过程始终是一棵树. Prim算法过程: 一条边一条边地加, 维护一棵树. 初始 E = {}空集合, V = {任选的一个起始节点} 循环(n – 1)次,每次选择一条边(v1,v2), 满足:v1属于V , v2不属于V.且(v1,v2)权值最小. E = E + (v1,v2) V = V + v2 最终E中的边是一棵最小生成树, V包含了全部节点. 以下图为例介绍Prim算法的执行过程
-
Python统计学一数据的概括性度量详解
一.数据的概括性度量 1.统计学概括: 统计学是应用数学的一个分支,主要通过利用概率论建立数学模型,收集所观察系统的数据,进行量化的分析.总结,并进而进行推断和预测,为相关决策提供依据和参考.统计学主要又分为描述统计学和推断统计学.给定一组数据,统计学可以摘要并且描述这份数据,这个用法称作为描述统计学.另外,观察者以数据的形态建立出一个用以解释其随机性和不确定性的数学模型,以之来推论研究中的步骤及母体,这种用法被称做推论统计学. 2.数据的概括性度量: 1)集中趋势的度量: 众数:众数(Mode
-
Python数据可视化绘图实例详解
目录 利用可视化探索图表 1.数据可视化与探索图 2.常见的图表实例 数据探索实战分享 1.2013年美国社区调查 2.波士顿房屋数据集 利用可视化探索图表 1.数据可视化与探索图 数据可视化是指用图形或表格的方式来呈现数据.图表能够清楚地呈现数据性质, 以及数据间或属性间的关系,可以轻易地让人看图释义.用户通过探索图(Exploratory Graph)可以了解数据的特性.寻找数据的趋势.降低数据的理解门槛. 2.常见的图表实例 本章主要采用 Pandas 的方式来画图,而不是使用 Matpl
-
Python Matplotlib数据可视化模块使用详解
目录 前言 1 matplotlib 开发环境搭建 2 绘制基础 2.1 绘制直线 2.2 绘制折线 2.3 设置标签文字和线条粗细 2.4 绘制一元二次方程的曲线 y=x^2 2.5 绘制正弦曲线和余弦曲线 3 绘制散点图 4 绘制柱状图 5 绘制饼状图 6 绘制直方图 7 绘制等高线图 8 绘制三维图 总结 本文主要介绍python 数据可视化模块 Matplotlib,并试图对其进行一个详尽的介绍. 通过阅读本文,你可以: 了解什么是 Matplotlib 掌握如何用 Matplotlib
-
Python数据存储之 h5py详解
1.Python数据存储(压缩) (1)numpy.save , numpy.savez , scipy.io.savemat numpy和scipy内建的数据存储方式. (2)cPickle + gzip cPickle是pickle内建的数据存储方式,gzip是常用的文件压缩模块. (3)h5py h5py是对HDF5文件格式进行读写的python包,关于h5py更多介绍与安装,参考官方网站 关于HDF5,参考官方网站.: 一个HDF5文件就是一个由两种基本数据对象(groups and d
-
Python Pandas学习之数据离散化与合并详解
目录 1数据离散化 1.1为什么要离散化 1.2什么是数据的离散化 1.3举例股票的涨跌幅离散化 2数据合并 2.1pd.concat实现数据合并 2.2pd.merge 1 数据离散化 1.1 为什么要离散化 连续属性离散化的目的是为了简化数据结构,数据离散化技术可以用来减少给定连续属性值的个数.离散化方法经常作为数据挖掘的工具. 1.2 什么是数据的离散化 连续属性的离散化就是在连续属性的值域上,将值域划分为若干个离散的区间,最后用不同的符号或整数 值代表落在每个子区间中的属性值. 离散化有