python超详细实现字体反爬流程
目录
- 查策实战场景
- 字体实战解码
- 字体反爬编码时间
查策实战场景
本次要采集的目标站点是查策,该测试站点如下所示。

目标站点网址如下
www.chacewang.com/chanye/news?newstype=sbtz
该站点的新闻资讯类信息很容易采集,通过开发者工具查看了一下,并不存在加密反爬。
但字体反爬还是存在的,案例寻找过程非常简单,只需要开发者工具切换到网络,字体视图,然后预览一下字体文件即可。

可以看到仅数字进行了顺序变换。
接下来就是实战解码的过程,可以通过 FontCreator 查看一下该字体内容。
字体实战解码
随机下载一个字体文件打开之后发现出事情了,字体文件内容如下所示。

其中除了简易的数字外,还存在大量的中文字符,也就是存在一种可能性,网页中的部分中文字符也被替换掉了。
我们拿一个【类】字做一下测试。
结果在页面中检索了一下,发现并没有发生变化,而且通过计算样式查看,得到的字体是平方和微软雅黑?
可能网站升级之后,字体反爬只保留了数字部分。
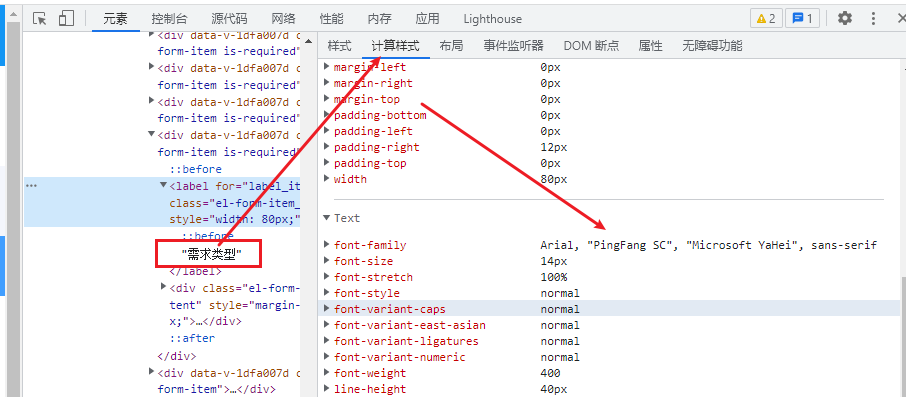
既然这样,那整体的难度就降低了~
我们随机访问一个页面,获取其网页源码内容。
访问公告类信息,需要提前登录,注册一个账号即可
import requests
headers = {
"content-type": "application/json",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) 你的 UA 信息",
"Referer": "https://www.chacewang.com/chanye/news?newstype=sbtz",
"cookie": "cityinfo={%22citycode%22:%22RegisterArea_HBDQ_Hebei_ShiJiaZhuangShi%22%2C%22cityname%22:%22%E7%9F%B3%E5%AE%B6%E5%BA%84%22}; 你的 COOKIES 信息"
}
res = requests.get('https://www.chacewang.com/news/detail?guid=KZwvLqpBVgE5AXB67k4XQY734MnG6ayo', headers=headers)
print(res.text)
结果运行代码之后,返回了一堆乱码。

橡皮擦原以为还有什么加密逻辑存在,结果发现多虑了,只是一个异步加载,真正的数据接口在下面。
web.chace-ai.com/api/gov/news/getDetailById/?id=KZwvLqpBVgE5AXB67k4XQY734MnG6ayo
接口一换,数据就可以获取到了。
import requests
headers = {
"content-type": "application/json",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.54 Safari/537.36",
"Referer": "https://www.chacewang.com/chanye/news?newstype=sbtz",
"authorization": "Bearer eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1Ni 这个值每次登录都会切换"
}
res = requests.get('https://web.chace-ai.com/api/gov/news/getDetailById/?id=KZwvLqpBVgE5AXB67k4XQY734MnG6ayo', headers=headers)
print(res.text)

此时也发现了数据差异,接口返回和页面展现,差异如下所示。

此时字体反爬逻辑已经发现,但是字体文件还存在如下逻辑:
- 每次请求有 2 个字体文件,确定哪一个影响;
- 字体文件每次刷新都会产生变化;
- 字体文件名每次刷新都会产生变化。
解决第一个问题,确定目标字体文件,该操作很简单,只需要通过文件替换规则比对即可,例如下图中响应中的 0 被替换为 2。

解决第三个问题,如何获取字体文件名。
在网络视图页面,唤醒搜索框,搜索字体文件名,发现其在 2 个请求中出现。第一个是字体文件,第二个是我们上文请求的数据接口。

检索之后发现字体文件名在接口返回的 news_set 参数中,并且是部分字符串,稍后我们截取字符串即可。

字体反爬编码时间
下面我们编写获取字体文件的代码,如下所示,下述代码注意自行获取一下 UA 值和 authorization 值。
import requests
headers = {
"content-type": "application/json",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) ",
"Referer": "https://www.chacewang.com/chanye/news?newstype=sbtz",
"authorization": "Bearer "
}
res = requests.get('https://web.chace-ai.com/api/gov/news/getDetailById/?id=KZwvLqpBVgE5AXB67k4XQY734MnG6ayo', headers=headers)
# 获取字体文件名
font_name = res.json()['data']['news_set'][:16]
res = requests.get(f'https://web.chace-ai.com/media/fonts/{font_name}.woff', headers=headers)
# 保存字体文件
file_woff =f'./fonts/{font_name}.woff'
with open(file_woff, 'wb') as f:
f.write(res.content)
后续逻辑就变得简单了,本文仅展示字体呈现部分逻辑,其安装 fontTools 模块,并使用下述命令行导入相关功能。
from fontTools.ttLib import TTFont
字体文件读取代码如下所示。
# 读取文件
with open(file_woff, 'rb') as font_file:
font = TTFont(io.BytesIO(font_file.read())) # 转换成字体对象
print(font)
# 获取 cmap
font_obj = font['cmap']
# 获取 cmap table
font_tables = font['cmap'].tables
uni_list = font['cmap'].tables[0].ttFont.getGlyphOrder()
print(uni_list[2:12])
查策,查策,就这么简单的解决了站点
到此这篇关于python超详细实现字体反爬流程的文章就介绍到这了,更多相关python字体反爬内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

python起点网月票榜字体反爬案例
目录 前言: 1.解析过程 2.开始敲代码 前言: 字体反爬是什么个意思?就是网站把自己的重要数据不直接的在源代码中呈现出来,而是通过相应字体的编码,与一个字体文件(一般后缀为ttf或woff)把相应的编码转换为自己想要的数据,知道了原理,接下来开始展示才艺 1.解析过程 老规矩哈我们先进入起点月票榜f12调试,找到书名与其对应的月票数据所在,使用xpath尝试提取 可以看到刚刚好20条数据,接下来找月票数据: 这是什么鬼xpath检索出来20条数据但是数据为空,element中数据显示
-
Python爬虫实例之2021猫眼票房字体加密反爬策略(粗略版)
前言: 猫眼票房页面的字体加密是动态的,每次或者每天加载页面的字体文件都会有所变化,本篇内容针对这种加密方式进行分析 字体加密原理:简单来说就是程序员在设计网站的时候使用了自己设计的字体代码对关键字进行编码,在浏览器加载的时会根据这个字体文件对这些字体进行编码,从而显示出正确的字体. 已知的使用了字体加密的一些网站: 58同城,起点,猫眼,大众点评,启信宝,天眼查,实习僧,汽车之家 本篇内容不过多解释字体文件的映射关系,不了解的请自行查找其他资料. 如若还未入门爬虫,请往这走 简单粗暴入门法--
-
python政策网字体反爬实例(附完整代码)
目录 1 字体反爬案例 2 使用环境 3 安装python第三方库 4 查看woff文件 5 woff文件解决字体反爬全过程 5.1 调用第三方库 5.2 请求woff链接下载woff文件到本地 5.3 查看woff文件内容,可以通过以下两种方式 5.5 建立字体反爬后与圆字体间对应关系 5.6 得到结果 6 完整代码如下 总结 字体反爬,也是一种常见的反爬技术,这些网站采用了自定义的字体文件,在浏览器上正常显示,但是爬虫抓取下来的数据要么就是乱码,要么就是变成其他字符.下面我们通过其中一种方式
-
python超详细实现字体反爬流程
目录 查策实战场景 字体实战解码 字体反爬编码时间 查策实战场景 本次要采集的目标站点是查策,该测试站点如下所示. 目标站点网址如下 www.chacewang.com/chanye/news?newstype=sbtz 该站点的新闻资讯类信息很容易采集,通过开发者工具查看了一下,并不存在加密反爬. 但字体反爬还是存在的,案例寻找过程非常简单,只需要开发者工具切换到网络,字体视图,然后预览一下字体文件即可. 可以看到仅数字进行了顺序变换. 接下来就是实战解码的过程,可以通过 FontCreato
-
python政策网字体反爬实例(附完整代码)
目录 1 字体反爬案例 2 使用环境 3 安装python第三方库 4 查看woff文件 5 woff文件解决字体反爬全过程 5.1 调用第三方库 5.2 请求woff链接下载woff文件到本地 5.3 查看woff文件内容,可以通过以下两种方式 5.5 建立字体反爬后与圆字体间对应关系 5.6 得到结果 6 完整代码如下 总结 字体反爬,也是一种常见的反爬技术,这些网站采用了自定义的字体文件,在浏览器上正常显示,但是爬虫抓取下来的数据要么就是乱码,要么就是变成其他字符.下面我们通过其中一种方式
-
Python字体反爬实战案例分享
目录 实战场景 实战编码 实战场景 本篇博客学习字体反爬,涉及的站点是实习 x,目标站点地址直接百度搜索即可. 可以看到右侧源码中出现了很多“乱码”,这其中就包含了关键信息. 接下来按照常规的套路,在开发者工具中检索字体相关信息,但是筛选之后,并没有得到反爬的字体,只有一个 file? 有些许的可能性. 这里就是一种新鲜的场景了,如果判断不准,那只能用字体样式和字体标签名进行判断了.在网页源码中检索 @font-face 和 myFont,得到下图内容,这里发现 file 字体又出现了,看来解决
-
Python音乐爬虫完美绕过反爬
目录 前言 开始 分析(x0) 分析(x1) 分析(x2) 分析(x3) 分析(x4) 通过分析获取到音乐 JavaScript绕过之参数冗余 CSRF攻击与防御 总结 代码 前言 大家好,我叫善念. 这是我的第二篇博客,也是第一篇技术博客,希望大家多多支持,让我更加有动力去更新一些python爬虫类的案例教程. 开始 确立目标网址:点击进入 进入到跳转页面: 可以看到出现了咱们需要的一些音乐 分析(x0) 这些音乐的源文件地址是否在咱们的网页元素中,然后再查看网页源代码中是否有咱们需要的内容.
-
windows安装python超详细图文教程
一.下载安装包 官网下载:python 3.6.0 打开链接滑到页面最下方 二. 开始安装 1.双击下载好的安装文件python-3.6.0-amd64.exe Install Now :默认安装 Customize Installation:自定义安装 Add Python 3.6 to PATH: 将python 加入环境变量 2.勾选Add Python 3.6 to PATH后,选择Customize Installation自定义安装 3.点击Next进行下一步 Install for
-
python超详细实现完整学生成绩管理系统
目录 学生成绩管理系统简介 源代码 students.txt main.py Login.py db.py MenuPage.py view.py 学生成绩管理系统简介 一个带有登录界面具有增减改查功能的学生成绩管理系统(面向对象思想,利用tkinter库进行制作,利用.txt文件进行存储数据) 源代码 仅供学习参考,最好还是自己多敲多练习(实践是检验真理的唯一标准) students.txt 用于存储数据 main.py from tkinter import * from Login imp
-
Python超详细分步解析随机漫步
创建RandomWalk类 为模拟随机漫步,我们将创建一个RandomWalk类,随机选择前进方向,这个类有三个属性,一个存储随机漫步的次数,另外两个存储随机漫步的每个点的x,y坐标,每次漫步都从点(0,0)出发 from random import choice class RandomWalk(): '''一个生成随机漫步数据的类''' def __init__(self,num_points=5000): '''初始化随机漫步的属性''' self.num_points = num_poi
-
Python超详细讲解内存管理机制
目录 什么是内存管理机制 一.引用计数机制 二.数据池和缓存 什么是内存管理机制 python中创建的对象的时候,首先会去申请内存地址,然后对对象进行初始化,所有对象都会维护在一 个叫做refchain的双向循环链表中,每个数据都保存如下信息: 1. 链表中数据前后数据的指针 2. 数据的类型 3. 数据值 4. 数据的引用计数 5. 数据的长度(list,dict..) 一.引用计数机制 引用计数增加: 1.1 对象被创建 1.2 对象被别的变量引用(另外起了个名字) 1.3 对象被作为元素,