基于Python实现口罩佩戴检测功能
目录
- 口罩佩戴检测
- 一 题目背景
- 1.1 实验介绍
- 1.2 实验要求
- 1.3 实验环境
- 1.4 实验思路
- 二 实验内容
- 2.1 已知文件与数据集
- 2.2 图片尺寸调整
- 2.3 制作训练时需要用到的批量数据集
- 2.4 调用MTCNN
- 2.5 加载预训练模型MobileNet
- 2.6 训练模型
- 2.6.1 加载和保存
- 2.6.2 手动调整学习率
- 2.6.3 早停法
- 2.6.4 乱序训练数据
- 2.6.5 训练模型
- 三 算法描述
- 3.1 MTCNN
- 3.2 MobileNet
- 四 求解结果
- 五 比较分析
- 六 心得与感想
口罩佩戴检测
一 题目背景
1.1 实验介绍
今年一场席卷全球的新型冠状病毒给人们带来了沉重的生命财产的损失。有效防御这种传染病毒的方法就是积极佩戴口罩。我国对此也采取了严肃的措施,在公共场合要求人们必须佩戴口罩。在本次实验中,我们要建立一个目标检测的模型,可以识别图中的人是否佩戴了口罩。
1.2 实验要求
- 建立深度学习模型,检测出图中的人是否佩戴了口罩,并将其尽可能调整到最佳状态。
- 学习经典的模型 MTCNN 和 MobileNet 的结构。
- 学习训练时的方法。
1.3 实验环境
实验使用重要python包:
import cv2 as cv import numpy as np import matplotlib.pyplot as plt from tensorflow.keras.callbacks import ModelCheckpoint, ReduceLROnPlateau, EarlyStopping
由于担心平台GPU时长不够用,所以在自己电脑上搭建了配套实验环境,由于电脑显卡CUDA版本较老,所以最终本地配置如下:
- Python: 3.8
- Tensorflow-GPU: 2.3.0
- Keras: 2.7.0
1.4 实验思路
针对目标检测的任务,可以分为两个部分:目标识别和位置检测。通常情况下,特征提取需要由特有的特征提取神经网络来完成,如 VGG、MobileNet、ResNet 等,这些特征提取网络往往被称为 Backbone 。而在 BackBone 后面接全连接层***(FC)***就可以执行分类任务。但 FC 对目标的位置识别乏力。经过算法的发展,当前主要以特定的功能网络来代替 FC 的作用,如 Mask-Rcnn、SSD、YOLO 等。我们选择充分使用已有的人脸检测的模型,再训练一个识别口罩的模型,从而提高训练的开支、增强模型的准确率。
常规目标检测:
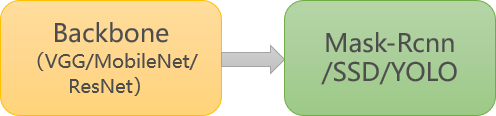
本次案例:
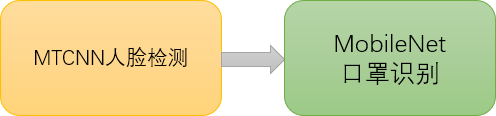
图1 实验口罩佩戴检测流程
二 实验内容
2.1 已知文件与数据集
首先,导入已经写好的python文件并对数据集进行处理。
- image 文件夹:图片分成两类,戴口罩的和没有戴口罩的
- train.txt: 存放的是 image 文件夹下对应图片的标签
- keras_model_data 文件夹:存放 keras 框架相关预训练好的模型
2.2 图片尺寸调整
将图片尺寸调整到网络输入的图片尺寸
2.3 制作训练时需要用到的批量数据集
图片生成器的主要方法:
fit(x, augment=False, rounds=1):计算依赖于数据的变换所需要的统计信息(均值方差等)。flow(self, X, y, batch_size=32, shuffle=True, seed=None, save_to_dir=None, save_prefix='', save_format='png'):接收 Numpy 数组和标签为参数,生成经过数据提升或标准化后的batch数据,并在一个无限循环中不断的返回batch数据。flow_from_directory(directory): 以文件夹路径为参数,会从路径推测label,生成经过数据提升/归一化后的数据,在一个无限循环中无限产生batch数据。
结果:
Found 693 images belonging to 2 classes.
Found 76 images belonging to 2 classes.
{'mask': 0, 'nomask': 1}
{0: 'mask', 1: 'nomask'}
2.4 调用MTCNN
通过搭建 MTCNN 网络实现人脸检测
keras_py/mtcnn.py文件是在搭建 MTCNN 网络。keras_py/face_rec.py文件是在绘制人脸检测的矩形框。
这里直接使用现有的表现较好的 MTCNN 的三个权重文件,它们已经保存在
datasets/5f680a696ec9b83bb0037081-momodel/data/keras_model_data文件夹下
2.5 加载预训练模型MobileNet
# 加载 MobileNet 的预训练模型权重 weights_path = basic_path + 'keras_model_data/mobilenet_1_0_224_tf_no_top.h5'
2.6 训练模型
2.6.1 加载和保存
为了避免训练过程中遇到断电等突发事件,导致模型训练成果无法保存。我们可以通过 ModelCheckpoint 规定在固定迭代次数后保存模型。同时,我们设置在下一次重启训练时,会检查是否有上次训练好的模型,如果有,就先加载已有的模型权重。这样就可以在上次训练的基础上继续模型的训练了。
2.6.2 手动调整学习率
学习率的手动设置可以使模型训练更加高效。这里我们设置当模型在三轮迭代后,准确率没有上升,就调整学习率。
# 学习率下降的方式,acc三次不下降就下降学习率继续训练
reduce_lr = ReduceLROnPlateau(
monitor='accuracy', # 检测的指标
factor=0.5, # 当acc不下降时将学习率下调的比例
patience=3, # 检测轮数是每隔三轮
verbose=2 # 信息展示模式
)
2.6.3 早停法
当我们训练深度学习神经网络的时候通常希望能获得最好的泛化性能。但是所有的标准深度学习神经网络结构如全连接多层感知机都很容易过拟合。当网络在训练集上表现越来越好,错误率越来越低的时候,就极有可能出现了过拟合。早停法就是当我们在检测到这一趋势后,就停止训练,这样能避免继续训练导致过拟合的问题。
early_stopping = EarlyStopping(
monitor='val_accuracy', # 检测的指标
min_delta=0.0001, # 增大或减小的阈值
patience=3, # 检测的轮数频率
verbose=1 # 信息展示的模式
)
2.6.4 乱序训练数据
打乱txt的行,这个txt主要用于帮助读取数据来训练,打乱的数据更有利于训练。
np.random.seed(10101)
np.random.shuffle(lines)
np.random.seed(None)
2.6.5 训练模型
一次训练集大小设定为64,优化器使用Adam,初始学习率设定为0.001,优化目标为accuracy,总的学习轮次设定为20轮。(通过多次实验测定,在这些参数条件下,准确率较高)
# 一次的训练集大小
batch_size = 64
# 编译模型
model.compile(loss='binary_crossentropy', # 二分类损失函数
optimizer=Adam(lr=0.001), # 优化器
metrics=['accuracy']) # 优化目标
# 训练模型
history = model.fit(train_generator,
epochs=20, # epochs: 整数,数据的迭代总轮数。
# 一个epoch包含的步数,通常应该等于你的数据集的样本数量除以批量大小。
steps_per_epoch=637 // batch_size,
validation_data=test_generator,
validation_steps=70 // batch_size,
initial_epoch=0, # 整数。开始训练的轮次(有助于恢复之前的训练)。
callbacks=[checkpoint_period, reduce_lr])
三 算法描述
3.1 MTCNN
- 三阶段的级联(cascaded)架构
- coarse-to-fine 的方式
- new online hard sample mining 策略
- 同时进行人脸检测和人脸对齐
- state-of-the-art 性能

图2 MTCNN架构
3.2 MobileNet
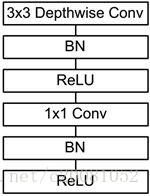
图3 MobileNet架构
MobileNet的网络结构如图3所示。首先是一个3x3的标准卷积,然后后面就是堆积depthwise separable convolution,并且可以看到其中的部分depthwise convolution会通过strides=2进行down sampling。然后采用average pooling将feature变成1x1,根据预测类别大小加上全连接层,最后是一个softmax层。
四 求解结果
最终确定最佳取值为batch_size=64,lr=0.0001,epochs=20,其它参数如下,连续训练两次,可以获得最佳结果。此处仅展示两个参数条件下的结果作为对比
# 一次的训练集大小
batch_size = 64
# 编译模型
model.compile(loss='binary_crossentropy', # 二分类损失函数
optimizer=Adam(lr=0.001), # 优化器
metrics=['accuracy']) # 优化目标
# 训练模型
history = model.fit(train_generator,
epochs=20, # epochs: 整数,数据的迭代总轮数。
# 一个epoch包含的步数,通常应该等于你的数据集的样本数量除以批量大小。
steps_per_epoch=637 // batch_size,
validation_data=test_generator,
validation_steps=70 // batch_size,
initial_epoch=0, # 整数。开始训练的轮次(有助于恢复之前的训练)。
callbacks=[checkpoint_period, reduce_lr])
条件1: 取batch_size=48, lr=0.001,epochs=20,对训练之后的模型进行测试,得到结果如下:

图4 条件1 loss曲线
由loss曲线可以看出,随着训练迭代次数的加深,验证集上的损失在逐渐的减小,最终稳定在0.2左右;而在训练集上loss始终在0附近。

图5 条件1 acc曲线
从验证集和测试集的准确率变化曲线上可以看出,随着训练轮次的增加,验证集的准确率逐渐上升,最终稳定在96%左右,效果还是不错的。

图6 条件1 测试样例1
使用样例照片进行测试,首先人脸识别部分顺利识别到了五张人脸,但是口罩识别部分将一个没有带口罩的人识别成了带着口罩的人,说明还有进步空间,实际错误率达到了20%。

图7 条件1 测试样例2
另一张样例照片的测试结果同样是人脸识别部分没有出现问题,正确识别到了四张人脸,但是同样将一个没有带口罩的人识别成了带有口罩的人。
平台测试:
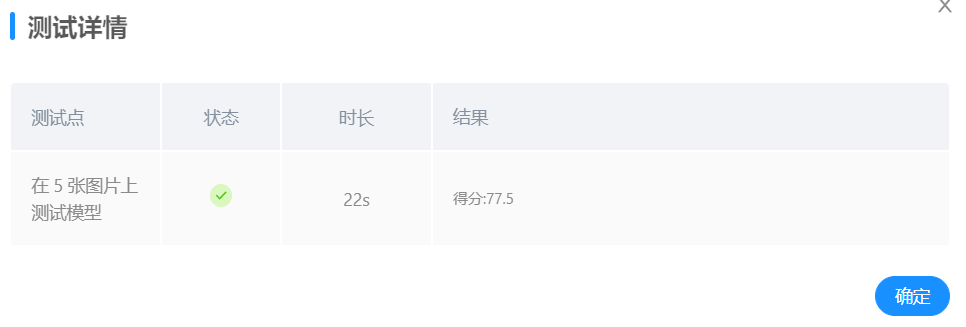
后续通过调整各项参数并打乱测试集和训练集图片顺序来进行了多次实验,最终确定的最佳状态如下:
条件2: 取batch_size=64, lr=0.0001,epochs=20,对训练之后的模型进行测试,得到结果如下:

图8 条件2 loss曲线
观察准确率曲线可以看出,在该条件下,验证集上的准确率最终稳定在98%附近,效果非常的好,说明我们做出的一些优化还是具有一定效果的。

图9 条件2 acc曲线
观察此条件下的loss曲线可以看到最终验证集的loss稳定在0.2左右,训练集的loss非常小,基本趋近于0

图10 条件2 测试样例1
使用两张测试样例对模型进行检测,第一张图片所有检测点均正确,正确识别出了五张人脸并且口罩佩戴检测均正确,识别正确率100%。

图11 条件2 测试样例2
第二章测试样例上,正确识别出了4张人脸并且口罩佩戴检测结果均正确。
两张测试样例上所有检测点检测结果均正确,说明在此参数条件下,模型识别效果较好,达到了口罩佩戴检测的要求。
平台测试:

条件3:
使用更多测试样例发现MTCNN人脸识别部分存在不能正确识别人脸的问题,故通过多次实验和测试,修改了mask_rec()的门限函数权重self.threshold,由原来的self.threshold = [0.5,0.6,0.8] 修改为self.threshold = [0.4,0.15,0.65]
在本地使用更多自选图片进行测试,发现人脸识别准确率有所提升。在条件2训练参数不变的情况下,使用同一模型进行平台测试,结果如下:

平台测试成绩有所提升。
条件4:
继续调整mask_rec()的门限函数权重self.threshold,通过系统测试反馈来决定门限函数的权重,通过多次测试,由原来的self.threshold = [0.4,0.15,0.65] 修改为self.threshold = [0.4,0.6,0.65]
平台测试,结果如下:

平台测试成绩有所提升,达到95分。
为了达到条件4所展示的效果,对门限函数的数值进行了大量的尝试,根据提交测试的反馈结果,最终确定数值为条件4时,可以达到最优。由于不知道后台测试图片是什么且没有反馈数据,所以最终再次修改人脸识别的门限函数或者修改参数重新训练口罩识别模型依旧没有提升。
五 比较分析
| 验证集准确率 | 测试样例结果 | 平台成绩 | |
|---|---|---|---|
| 条件1 | 96% | 7/9 | 77.5 |
| 条件2 | 98% | 9/9 | 88.33333334 |
| 条件3 | 98% | 9/9 | 90 |
| 条件4 | 98% | 9/9 | 95 |
最终通过不断调试与优化算法,得到了95分的平台成绩。
六 心得与感想
本次实验过程中主要使用了keras方法进行训练,由于初次使用这些方法,所以前期实现的过程相对困难。最初我想通过调用GPU资源来进行训练,所以给自己的电脑配套安装了tensorflow-gpu、CUDA等等配套的软件和包,由于个人电脑的显卡版本较老,所以安装的过程也是非常的曲折。好在最终安装好了所有的东西,但是由于显卡显存比较小,所以bath_size大小一直上不去,最大只能给到32,不过影响也不大。调整参数的过程花费了很多的时间,优化算法也花费了很多的时间。之后又对门限函数进行了修改,虽然过程非常的辛苦,但最终的结果还是很不错的,最终整体达到95分,在两张给定的测试样例上所有检测点都是正确的,由于不知道平台的五张检测照片是什么,所以不知道到底出错在哪里,希望之后平台可以反馈一些修改意见~。总的来说在过程中收获还是很大的,受益匪浅。
训练源代码:
import warnings
# 忽视警告
warnings.filterwarnings('ignore')
import os
import matplotlib
import cv2 as cv
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.callbacks import ModelCheckpoint, ReduceLROnPlateau, EarlyStopping
from tensorflow.keras.applications.imagenet_utils import preprocess_input
from tensorflow.keras import backend as K
from tensorflow.keras.optimizers import Adam
K.image_data_format() == 'channels_last'
from keras_py.utils import get_random_data
from keras_py.face_rec import mask_rec
from keras_py.face_rec import face_rec
from keras_py.mobileNet import MobileNet
from tensorflow.keras.preprocessing.image import ImageDataGenerator
# 数据集路径
basic_path = "./datasets/5f680a696ec9b83bb0037081-momodel/data/"
def letterbox_image(image, size): # 调整图片尺寸,返回经过调整的照片
new_image = cv.resize(image, size, interpolation=cv.INTER_AREA)
return new_image
read_img = cv.imread("test1.jpg")
print("调整前图片的尺寸:", read_img.shape)
read_img = letterbox_image(image=read_img, size=(50, 50))
print("调整前图片的尺寸:", read_img.shape)
def processing_data(data_path, height, width, batch_size=32, test_split=0.1): # 数据处理,batch_size默认大小为32
train_data = ImageDataGenerator(
# 对图片的每个像素值均乘上这个放缩因子,把像素值放缩到0和1之间有利于模型的收敛
rescale=1. / 255,
# 浮点数,剪切强度(逆时针方向的剪切变换角度)
shear_range=0.1,
# 随机缩放的幅度,若为浮点数,则相当于[lower,upper] = [1 - zoom_range, 1+zoom_range]
zoom_range=0.1,
# 浮点数,图片宽度的某个比例,数据提升时图片水平偏移的幅度
width_shift_range=0.1,
# 浮点数,图片高度的某个比例,数据提升时图片竖直偏移的幅度
height_shift_range=0.1,
# 布尔值,进行随机水平翻转
horizontal_flip=True,
# 布尔值,进行随机竖直翻转
vertical_flip=True,
# 在 0 和 1 之间浮动。用作验证集的训练数据的比例
validation_split=test_split
)
# 接下来生成测试集,可以参考训练集的写法
test_data = ImageDataGenerator(
rescale=1. / 255,
validation_split=test_split)
train_generator = train_data.flow_from_directory(
# 提供的路径下面需要有子目录
data_path,
# 整数元组 (height, width),默认:(256, 256)。 所有的图像将被调整到的尺寸。
target_size=(height, width),
# 一批数据的大小
batch_size=batch_size,
# "categorical", "binary", "sparse", "input" 或 None 之一。
# 默认:"categorical",返回one-hot 编码标签。
class_mode='categorical',
# 数据子集 ("training" 或 "validation")
subset='training',
seed=0)
test_generator = test_data.flow_from_directory(
data_path,
target_size=(height, width),
batch_size=batch_size,
class_mode='categorical',
subset='validation',
seed=0)
return train_generator, test_generator
# 数据路径
data_path = basic_path + 'image'
# 图像数据的行数和列数
height, width = 160, 160
# 获取训练数据和验证数据集
train_generator, test_generator = processing_data(data_path, height, width)
# 通过属性class_indices可获得文件夹名与类的序号的对应字典。
labels = train_generator.class_indices
print(labels)
# 转换为类的序号与文件夹名对应的字典
labels = dict((v, k) for k, v in labels.items())
print(labels)
pnet_path = "./datasets/5f680a696ec9b83bb0037081-momodel/data/keras_model_data/pnet.h5"
rnet_path = "./datasets/5f680a696ec9b83bb0037081-momodel/data/keras_model_data/rnet.h5"
onet_path = "./datasets/5f680a696ec9b83bb0037081-momodel/data/keras_model_data/onet.h5"
# 加载 MobileNet 的预训练模型权重
weights_path = basic_path + 'keras_model_data/mobilenet_1_0_224_tf_no_top.h5'
# 图像数据的行数和列数
height, width = 160, 160
model = MobileNet(input_shape=[height,width,3],classes=2)
model.load_weights(weights_path,by_name=True)
print('加载完成...')
def save_model(model, checkpoint_save_path, model_dir): # 保存模型
if os.path.exists(checkpoint_save_path):
print("模型加载中")
model.load_weights(checkpoint_save_path)
print("模型加载完毕")
checkpoint_period = ModelCheckpoint(
# 模型存储路径
model_dir + 'ep{epoch:03d}-loss{loss:.3f}-val_loss{val_loss:.3f}.h5',
# 检测的指标
monitor='val_acc',
# ‘auto',‘min',‘max'中选择
mode='max',
# 是否只存储模型权重
save_weights_only=False,
# 是否只保存最优的模型
save_best_only=True,
# 检测的轮数是每隔2轮
period=2
)
return checkpoint_period
checkpoint_save_path = "./results/last_one88.h5"
model_dir = "./results/"
checkpoint_period = save_model(model, checkpoint_save_path, model_dir)
# 学习率下降的方式,acc三次不下降就下降学习率继续训练
reduce_lr = ReduceLROnPlateau(
monitor='accuracy', # 检测的指标
factor=0.5, # 当acc不下降时将学习率下调的比例
patience=3, # 检测轮数是每隔三轮
verbose=2 # 信息展示模式
)
early_stopping = EarlyStopping(
monitor='val_accuracy', # 检测的指标
min_delta=0.0001, # 增大或减小的阈值
patience=3, # 检测的轮数频率
verbose=1 # 信息展示的模式
)
# 一次的训练集大小
batch_size = 64
# 图片数据路径
data_path = basic_path + 'image'
# 图片处理
train_generator, test_generator = processing_data(data_path, height=160, width=160, batch_size=batch_size, test_split=0.1)
# 编译模型
model.compile(loss='binary_crossentropy', # 二分类损失函数
optimizer=Adam(lr=0.001), # 优化器
metrics=['accuracy']) # 优化目标
# 训练模型
history = model.fit(train_generator,
epochs=20, # epochs: 整数,数据的迭代总轮数。
# 一个epoch包含的步数,通常应该等于你的数据集的样本数量除以批量大小。
steps_per_epoch=637 // batch_size,
validation_data=test_generator,
validation_steps=70 // batch_size,
initial_epoch=0, # 整数。开始训练的轮次(有助于恢复之前的训练)。
callbacks=[checkpoint_period, reduce_lr])
# 保存模型
model.save_weights(model_dir + 'temp.h5')
plt.plot(history.history['loss'],label = 'train_loss')
plt.plot(history.history['val_loss'],'r',label = 'val_loss')
plt.legend()
plt.show()
plt.plot(history.history['accuracy'],label = 'acc')
plt.plot(history.history['val_accuracy'],'r',label = 'val_acc')
plt.legend()
plt.show()
到此这篇关于基于Python实现的口罩佩戴检测的文章就介绍到这了,更多相关python口罩佩戴检测内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
使用 Python 在京东上抢口罩的思路详解
全国抗"疫"这么久终于见到曙光,在家待了将近一个月,现在终于可以去上班了,可是却发现出门必备的口罩却一直买不到.最近看到京东上每天都会有口罩的秒杀活动,试了几次却怎么也抢不到,到了抢购的时间,浏览器的页面根本就刷新不出来,等刷出来秒杀也结束了.现在每天只放出一万个,却有几百万人在抢,很想知道别人是怎么抢到的,于是就在网上找了大神公开出来的抢购代码.看了下代码并不复杂,现在我们就报着学习的态度一起看看. 使用模块 首先打开项目中 requirements.txt 文件,看下它都需要哪些模
-

Python实现笑脸检测+人脸口罩检测功能
目录 一.人脸图像特征提取方法 二.对笑脸数据集genki4k进行训练和测试(包括SVM.CNN),输出模型训练精度和测试精度(F1-score和ROC),实现检测图片笑脸和实时视频笑脸检测 (一)环境.数据集准备 (二)训练笑脸数据集genki4k (三)图片笑脸检测 (四)实时视频笑脸检测 三.将笑脸数据集换成人脸口罩数据集,并对口罩数据集进行训练,编写程序实现人脸口罩检测 (一)训练人脸口罩数据集 (二)编程实现人脸口罩检测 一.人脸图像特征提取方法 https://www.jb51.ne
-
基于Python实现人脸自动戴口罩系统
1.项目背景 2019年新型冠状病毒感染的肺炎疫情发生以来,牵动人心,举国哀痛,口罩.酒精.消毒液奇货可居. 抢不到口罩,怎么办?作为技术人今天分享如何使用Python实现自动戴口罩系统,来安慰自己,系统效果如下所示: 本系统的实现原理是借助 Dlib模块的Landmark人脸68个关键点检测库轻松识别出人脸五官数据,根据这些数据,确定嘴唇部分的位置数据(48点~67点位置),根据检测到嘴部的尺寸和方向,借助PLL模块调整口罩的尺寸和方向,实现将口罩放在图像的适当位置. 2.页面设计 基于tki
-
python基于Opencv实现人脸口罩检测
一.开发环境 python 3.6.6 opencv-python 4.5.1 二.设计要求 1.使用opencv-python对人脸口罩进行检测 三.设计原理 设计流程图如图3-1所示, 图3-1 口罩检测流程图 首先进行图片的读取,使用opencv的haar鼻子特征分类器,如果检测到鼻子,则证明没有戴口罩.如果检测到鼻子,接着使用opencv的haar眼睛特征分类器,如果没有检测到眼睛,则结束.如果检测到眼睛,则把RGB颜色空间转为HSV颜色空间.进行口罩区域的检测.口罩区域检测流程是首先把
-
基于Python实现口罩佩戴检测功能
目录 口罩佩戴检测 一 题目背景 1.1 实验介绍 1.2 实验要求 1.3 实验环境 1.4 实验思路 二 实验内容 2.1 已知文件与数据集 2.2 图片尺寸调整 2.3 制作训练时需要用到的批量数据集 2.4 调用MTCNN 2.5 加载预训练模型MobileNet 2.6 训练模型 2.6.1 加载和保存 2.6.2 手动调整学习率 2.6.3 早停法 2.6.4 乱序训练数据 2.6.5 训练模型 三 算法描述 3.1 MTCNN 3.2 MobileNet 四 求解结果 五 比较分析
-
50行Python代码实现人脸检测功能
现在的人脸识别技术已经得到了非常广泛的应用,支付领域.身份验证.美颜相机里都有它的应用.用iPhone的同学们应该对下面的功能比较熟悉 iPhone的照片中有一个"人物"的功能,能够将照片里的人脸识别出来并分类,背后的原理也是人脸识别技术. 这篇文章主要介绍怎样用Python实现人脸检测.人脸检测是人脸识别的基础.人脸检测的目的是识别出照片里的人脸并定位面部特征点,人脸识别是在人脸检测的基础上进一步告诉你这个人是谁. 好了,介绍就到这里.接下来,开始准备我们的环境. 准备工作 本文的人
-
基于Python实现的ID3决策树功能示例
本文实例讲述了基于Python实现的ID3决策树功能.分享给大家供大家参考,具体如下: ID3算法是决策树的一种,它是基于奥卡姆剃刀原理的,即用尽量用较少的东西做更多的事.ID3算法,即Iterative Dichotomiser 3,迭代二叉树3代,是Ross Quinlan发明的一种决策树算法,这个算法的基础就是上面提到的奥卡姆剃刀原理,越是小型的决策树越优于大的决策树,尽管如此,也不总是生成最小的树型结构,而是一个启发式算法. 如下示例是一个判断海洋生物数据是否是鱼类而构建的基于ID3思想
-
基于Python打造账号共享浏览器功能
本篇文章介绍的内容会涉及到以下知识: PyQt5的使用; Selenium的使用; 代理服务器的架设和使用: 一.账号限制之痛 在如今的互联网中,免费的信息和资源占据了很大一部分,各类互联网应用提供了各行各业的资讯和资源.这是互联网能够不断繁荣和扩大的重要原因之一. 与此同时,一些收费或不公开的互联网应用则构成了互联网世界中更有价值和意义的部分. 一些限制性较低的网站,可能仅仅需要进行用户登录即可使用服务: 一些限制性中等的网站,则可能会出于账户安全或是其他方面的因素考虑,限制账号在一定时间一定
-
OpenCV+python实现实时目标检测功能
环境安装 安装Anaconda,官网链接Anaconda 使用conda创建py3.6的虚拟环境,并激活使用 conda create -n py3.6 python=3.6 //创建 conda activate py3.6 //激活 3.安装依赖numpy和imutils //用镜像安装 pip install -i https://pypi.tuna.tsinghua.edu.cn/simple numpy pip install -i https://pypi.tuna.tsinghua
-
基于Python实现天天酷跑功能
感觉上次写的植物大战僵尸与俄罗斯方块的反应还不错,这次这个文章就更有动力了 这次就写一个天天酷跑吧 写出来的效果图就是这样了 下面就更新一下全部的代码吧 还是老样子先定义 import pygame,sys import random 写一下游戏配置 width = 1200 #窗口宽度 height = 508 #窗口高度 size = width, height score=None #分数 myFont=myFont1=None #字体 surObject=None #障碍物图片 surG
-
基于Python实现评论区抽奖功能详解
目录 1. 分析评论接口 2. 获取评论数据 3. 筛选评论用户 4. 抽取幸运观众 5. 完整源码 5.1 字符串截取的方式 5.2 正则匹配方式 5.3 执行结果 1. 分析评论接口 首先,我们需要找到评论数据的「接口」,也就是网站获取评论数据的请求. 打开一个需要抽奖的文章,进入「开发者模式」(按F12 或 右键检查),选中 Network 选项,同时「刷新」文章页面,使其重新发送请求,在右侧工具栏中观察页面发送的请求,逐个分析请求,根据响应内容判断出获取评论的请求 在 Headers 栏
-
基于Python实现打哈欠检测详解
目录 效果图 基本思路 部分源码 效果图 基本思路 在 OpenCV 中使用VideoCapture方法初始化视频渲染对象 创建灰度图像 导入预训练模型,识别脸部和人脸标志 计算上唇和下唇距离(其它类似) 创建唇边距离的If条件,满足则是打哈欠,不满足则只是简单的张嘴 显示帧/图像 部分源码 suc, frame = cam.read() # 读取不到退出 if not suc: break # ---------FPS------------# ctime = time.time() fps
-
基于Mediapipe+Opencv实现手势检测功能
目录 一.前言 二.环境配置 软件: 环境: 三.全部源码 MediapipeHandTracking.py程序结构: MediapipeHandTracking.py源码与注释 四.环境配置 1.在Anaconda3上新建环境Gesture 2.激活Gesture环境并下载opencv-python包 3.下载mediapipe包 4.打开Pycharm完成环境导入项目 五.运行程序: 六.程序应用扩展 1.手部的关键点的位置和次序我们全部已知的特点 2.和其他AL结合 3.全身检测源码 一.
-
基于Python实现通过微信搜索功能查看谁把你删除了
场景:查找who删了我,直接copy代码保存到一个python文件who.py,在python环境下运行此文件 代码如下,copy保存到who.py文件在python环境直接运行: #!/usr/bin/env python # coding=utf-8 from __future__ import print_function import os try: from urllib import urlencode, quote_plus except ImportError: from url