利用python数据分析处理进行炒股实战行情
作为一个新手,你需要以下3个步骤:
1、用户注册 > 2、获取token > 3、调取数据
数据内容:
包含股票、基金、期货、债券、外汇、行业大数据,
同时包括了数字货币行情等区块链数据的全数据品类的金融大数据平台,
为各类金融投资和研究人员提供适用的数据和工具。
1、数据采集
我们进行本地化计算,首先要做的,就是将所需的基础数据采集到本地数据库里
本篇的示例源码采用的数据库是MySQL5.5,数据源是xxx pro接口。
我们现在要取一批特定股票的日线行情
部分代码如下:
# 设置xxxxx pro的token并获取连接
# 公众号:信息技术智库
ts.set_token('xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx')
pro = ts.pro_api()
# 设定获取日线行情的初始日期和终止日期,其中终止日期设定为昨天。
start_dt = '20100101'
time_temp = datetime.datetime.now() - datetime.timedelta(days=1)
end_dt = time_temp.strftime('%Y%m%d')
# 建立数据库连接,剔除已入库的部分
db = pymysql.connect(host='127.0.0.1', user='root', passwd='admin', db='stock', charset='utf8')
cursor = db.cursor()
# 设定需要获取数据的股票池
stock_pool = ['603912.SH','300666.SZ','300618.SZ','002049.SZ','300672.SZ']
total = len(stock_pool)
# 循环获取单个股票的日线行情
for i in range(len(stock_pool)):
try:
df = pro.daily(ts_code=stock_pool[i], start_date=start_dt, end_date=end_dt)
# 打印进度
print('Seq: ' + str(i+1) + ' of ' + str(total) + ' Code: ' + str(stock_pool[i]))
上述代码的注释部分已将每行代码的功能解释清楚了,实际上数据采集的程序主要设置三个参数:获取行情的初始日期,终止日期,以及股票代码池。
当我们获取数据后,就要往本地数据库进行写入(存储)操作了,
本篇代码用的是SQL语言,需提前在数据库内建好相应的表,表配置和表结构如下:
库名:stock 表名:stock_all
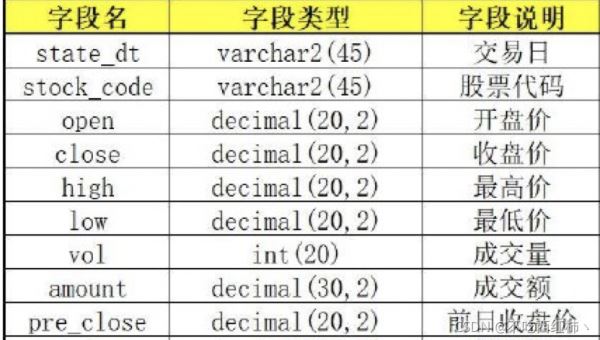
其中 state_dt 和 stock_code 是主键和索引。state_dt 的格式是 ‘yyyy-mm-dd'(例:'2018-06-11')。
这样的日期格式便于查询,且在MySQL内部能够进行大小比较。
2、数据预处理
无论是量化策略还是单纯的机器学习项目,数据预处理都是非常重要的一环。
以机器学习的视角来看,数据预处理主要包括
- 数据清洗
- 排序
- 缺失值或异常值处理
- 统计量分析
- 相关性分析
- 主成分分析(PCA)
- 归一化等
本篇所要介绍的数据预处理比较简单
只是将存在本地数据库的日线行情数据整合成一份训练集数据,
以用于后续的机器学习建模和训练。
在介绍具体的示例代码之前,我们需要先思考一个问题,
应用有监督学习的算法对个股进行建模
- 我们的输入数据有哪些,
- 我们期望得到的输出数据又是什么?
这个问题的答案因人而异,因策略而异。
这个问题本身是将市场问题转化为数学问题的一个过程。
依赖的是量化宽客自己的知识体系和对市场的理解。
回到正题,本篇示例我们将以最简单的数据进行分析,
我们输入端的数据是个股每日基础行情,输出端数据是股价相较前一交易日的涨跌状态。
简单点说就是,我们向模型输入今天的基础行情,让模型预测明天股价是涨还是跌。
在代码实现方式上,
- 采用面向对象的思想,
- 将整个数据预处理过程和结果,封装成一个类,每次创建一个类实例,
- 就得到了特定条件下的一份训练集。
示例代码如下:
class data_collect(object):
def __init__(self, in_code,start_dt,end_dt):
ans = self.collectDATA(in_code,start_dt,end_dt)
def collectDATA(self,in_code,start_dt,end_dt):
# 建立数据库连接,获取日线基础行情(开盘价,收盘价,最高价,最低价,成交量,成交额)
db = pymysql.connect(host='127.0.0.1', user='root', passwd='admin', db='stock', charset='utf8')
cursor = db.cursor()
sql_done_set = "SELECT * FROM stock_all a where stock_code = '%s' and state_dt >= '%s' and state_dt <= '%s' order by state_dt asc" % (in_code, start_dt, end_dt)
cursor.execute(sql_done_set)
done_set = cursor.fetchall()
if len(done_set) == 0:
raise Exception
self.date_seq = []
self.open_list = []
self.close_list = []
self.high_list = []
self.low_list = []
self.vol_list = []
self.amount_list = []
for i in range(len(done_set)):
self.date_seq.append(done_set[i][0])
self.open_list.append(float(done_set[i][2]))
self.close_list.append(float(done_set[i][3]))
self.high_list.append(float(done_set[i][4]))
self.low_list.append(float(done_set[i][5]))
self.vol_list.append(float(done_set[i][6]))
self.amount_list.append(float(done_set[i][7]))
cursor.close()
db.close()
# 将日线行情整合为训练集(其中self.train是输入集,self.target是输出集,self.test_case是end_dt那天的单条测试输入)
self.data_train = []
self.data_target = []
最终这个类实例化后是要整合出三个数据:
1. self.train :训练集中的输入端数据,本例中是每日基础行情。
2. self.target :训练集中的输出数据,本例中相较于前一天股价的涨跌,涨为1,不涨为0。并且在排序上,每条 t 交易日的self.train里的数据对应的是 t+1 天股价的涨跌状态。
3. self.test_case :在 t 末交易日的基础行情数据,作为输入端,用于模型训练完成后,对第二天的涨跌进行预测。
3、SVM建模
机器学习中有诸多有监督学习算法
SVM是比较常见的一种,本例采用SVM算法进行建模。
关于SVM的理论原理本篇不做详述,以下仅从实践角度进行建模介绍。
先贴一段建模、训练并进行预测的代码大家感受一下:)
model = svm.SVC() # 建模 model.fit(train, target) # 训练 ans2 = model.predict(test_case) # 预测
三行代码,让人想起了把大象装冰箱分几步的冷笑话……
不过这侧面也说明Python在数据挖掘方面的强大之处:简单,方便,好用。
本例用的机器学习框架是scikit-learn是个非常强大的算法库。
熟悉算法原理的朋友可以查阅官方API文档,可修改模型参数,进一步调优模型;
亦可尝试其他算法比如决策树,逻辑回归,朴素贝叶斯等。
以上就是利用python数据分析进行炒股实战行情的详细内容,更多关于python数据分析的资料请关注我们其它相关文章!
相关推荐
-
基于Python爬取股票数据过程详解
基本环境配置 python 3.6 pycharm requests csv time 相关模块pip安装即可 目标网页 分析网页 一切的一切都在图里 找到数据了,直接请求网页,解析数据,保存数据 请求网页 import requests url = 'https://xueqiu.com/service/v5/stock/screener/quote/list' response = requests.get(url=url, params=params, headers=headers, c
-

python实现股票历史数据可视化分析案例
投资有风险,选择需谨慎. 股票交易数据分析可直观股市走向,对于如何把握股票行情,快速解读股票交易数据有不可替代的作用! 1 数据预处理 1.1 股票历史数据csv文件读取 import pandas as pd import csv df = pd.read_csv("/home/kesci/input/maotai4154/maotai.csv") 1.2 关键数据--在csv文件中选择性提取"列" df_high_low = df[['date','high',
-
Python爬取股票信息,并可视化数据的示例
前言 截止2019年年底我国股票投资者数量为15975.24万户, 如此多的股民热衷于炒股,首先抛开炒股技术不说, 那么多股票数据是不是非常难找, 找到之后是不是看着密密麻麻的数据是不是头都大了? 今天带大家爬取雪球平台的股票数据, 并且实现数据可视化 先看下效果图 基本环境配置 python 3.6 pycharm requests csv time 目标地址 https://xueqiu.com/hq 爬虫代码 请求网页 import requests url = 'https://xueq
-
使用Python画股票的K线图的方法步骤
导言 本文简单介绍了如何从网易财经获取某支股票的价格数据,并根据价格数据画出相应的日K线图.有助于新手了解并使用Python的相关功能.包括列表.自定义函数.for循环.if函数以及如何使用matplotlib进行作图等内容. 第一步:从网易财经获取股票的价格数据 我一般是在网易财经查看某支股票的价格和成交数据,网易财经可以查到任意沪深的股票,我们使用招商银行的数据作为参考. 1.构建爬虫获取股票价格数据 这里不对Python做介绍了,如果需要了解什么是Python,可以自行百度或者访问Pyth
-
利用python数据分析处理进行炒股实战行情
作为一个新手,你需要以下3个步骤: 1.用户注册 > 2.获取token > 3.调取数据 数据内容: 包含股票.基金.期货.债券.外汇.行业大数据, 同时包括了数字货币行情等区块链数据的全数据品类的金融大数据平台, 为各类金融投资和研究人员提供适用的数据和工具. 1.数据采集 我们进行本地化计算,首先要做的,就是将所需的基础数据采集到本地数据库里 本篇的示例源码采用的数据库是MySQL5.5,数据源是xxx pro接口. 我们现在要取一批特定股票的日线行情 部分代码如下: # 设置xxxxx
-
python数据分析实战指南之异常值处理
目录 异常值 1.异常值定义 2.异常值处理方式 2.1 均方差 2.2 箱形图 3.实战 3.1 加载数据 3.2 检测异常值数据 3.3 显示异常值的索引位置 总结 异常值 异常值是指样本中的个别值,其数值明显偏离其余的观测值.异常值也称离群点,异常值的分析也称为离群点的分析. 常用的异常值分析方法为3σ原则.箱型图分析.机器学习算法检测,一般情况下对异常值的处理都是删除和修正填补,即默认为异常值对整个项目的作用不大,只有当我们的目的是要求准确找出离群点,并对离群点进行分析时有必要用到机器学
-
利用python开发app实战的方法
我很早之前就想开发一款app玩玩,无奈对java不够熟悉,之前也没有开发app的经验,因此一直耽搁了.最近想到尝试用python开发一款app,google搜索了一番后,发现确实有路可寻,目前也有了一些相对成熟的模块,于是便开始了动手实战,过程中发现这其中有很多坑,好在最终依靠google解决了,因此小记一番. 说在前面的话 python语言虽然很万能,但用它来开发app还是显得有点不对路,因此用python开发的app应当是作为编码练习.或者自娱自乐所用,加上目前这方面的模块还不是特别成熟,b
-
利用Python+Selenium破解春秋航空网滑块验证码的实战过程
目录 前言 开发工具 环境搭建 实战记录 一. 验证码简介 二.破解滑块验证码 2.1 计算滑块到缺口的距离 2.2 将滑块拖到缺口位置 前言 记录一次利用Python+Selenium破解滑块验证码的实战过程. 让我们愉快地开始吧~ 开发工具 Python版本: 3.6.4 相关模块: pillow模块: selenium模块: numpy模块: 以及一些Python自带的模块. 其他: chromedriver 环境搭建 安装Python并添加到环境变量,pip安装需要的相关模块即可. 实战
-
利用python写api接口实战指南
目录 一.操作步骤 二.源码举例 总结 一.操作步骤 导入:import flask,json 实例化:api = flask.Flask(name) 定义接口访问路径及访问方式:@api.route(’/index’,methods=[‘get/post/PUT/DELETE’]) 定义函数,注意需与路径的名称一致,设置返回类型并支持中文:def index(): return json.dumps(ren,ensure_ascii=False) 三种格式入参访问接口:5.1 url格式入参:
-
利用Python自制网页并实现一键自动生成探索性数据分析报告
目录 前言 上传文件以及变量的筛选 前言 今天小编带领大家用Python自制一个自动生成探索性数据分析报告这样的一个工具,大家只需要在浏览器中输入url便可以轻松的访问,如下所示: 第一步 首先我们导入所要用到的模块,设置网页的标题.工具栏以及logo的导入,代码如下: from st_aggrid import AgGrid import streamlit as st import pandas as pd import pandas_profiling from streamlit_pan
-
利用Python实现自动生成图文并茂的数据分析
目录 前言 1.一行命令,安装这个库 2.核心代码模块导入 ①提前导入相关内容,并且注册字体 ②注册字体 ③生成报告 前言 reportlab是Python的一个标准库,可以画图.画表格.编辑文字,最后可以输出PDF格式.它的逻辑和编辑一个word文档或者PPT很像.有两种方法: 建立一个空白文档,然后在上面写文字.画图等: 建立一个空白list,以填充表格的形式插入各种文本框.图片等,最后生成PDF文档. 因为需要产生一份给用户看的报告,里面需要插入图片.表格等,所以采用的是第二种方法. 1.
-
利用Python+PyQt5实现简易浏览器的实战记录
目录 实验环境 依赖项安装 编程实现 浏览器有一个可以用于展示网页的窗口 代码 总结 实验环境 操作系统:Linux Mint 编辑器:vim 编程语言:python3 依赖项安装 安装PyQt5 Qt是一个跨平台的C++应用程序开发框架 sudo apt-get install python3-pyqt5 安装完成后进入python命令行界面测试是否安装正确 python3 >>>import PyQt5 执行命令后如果没有任何提示,说明安装成功 编程实现 Qt为开发者提供了QtWeb
-
Python数据分析之双色球统计两个红和蓝球哪组合比例高的方法
本文实例讲述了Python数据分析之双色球统计两个红和蓝球哪组合比例高的方法.分享给大家供大家参考,具体如下: 统计两个红球和蓝球,哪个组合最多,显示前19组数据 #!/usr/bin/python # -*- coding:UTF-8 -*- import pandas as pd import numpy as np import matplotlib.pyplot as plt import operator #导入数据 df = pd.read_table('newdata.txt',h
-
Python数据分析之双色球统计单个红和蓝球哪个比例高的方法
本文实例讲述了Python数据分析之双色球统计单个红和蓝球哪个比例高的方法.分享给大家供大家参考,具体如下: 统计单个红球和蓝球,哪个组合最多,显示前19组数据 #!/usr/bin/python # -*- coding:UTF-8 -*- import pandas as pd import numpy as np import matplotlib.pyplot as plt import operator df = pd.read_table('newdata.txt',header=N