用python写个颜值评分器筛选最美主播
目录
- 前言
- 一、核心功能设计
- 获取主播直播封面图
- 主播颜值评分
- 二、实现步骤
- 1. 获取主播名称和照片
- 2. 主播颜值评分
前言
晚上回家闲来无事,想打开某直播平台,看看小姐姐直播。看着一个个多才多艺的小姐姐,眼花缭乱,好难抉择。究竟看哪个小姐姐直播好呢?
今天我们就一起来做个颜值评分器,爬取小姐姐们的直播照片,对每位小姐姐的颜值进行打分排序,选出最靓的star。
一、核心功能设计
总体来说,我们需要做的是获取直播颜值区的主播小姐姐的正在直播的全部主播名称和封面图并保存下来,用百度AI提供的人脸识别接口,进行颜值评分排序,选出颜值最高的。
拆解需求,大致可以整理出核心功能如下:
获取主播直播封面图
- 打开直播颜值区模块对页面进行分析
- 发送网络请求,解析数据
- 保存数据
主播颜值评分
- 百度人脸识别接口
- 遍历主播照片,调用颜值检测接口对主播颜值进行打分
- 对评分进行排序
二、实现步骤
1. 获取主播名称和照片
首先我们选择的是某牙直播,进入首页打开颜值区,按F12可以进入开发者模式。
import requests
# 1.找到数据所在url地址(系统分析网页性质)
url = "https://www.huya.com/g/2168"
headers = {
'User-Agent': 'User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 '
'(KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'
}
# 2. 发送网络请求
response = requests.get(url=url, headers=headers)
html_data = response.text
print(html_data)
不难发现所有的小姐姐直播封面对应的都是在li标签里面。我们只要解析获取这些li标签数据就可以了。

接着我们需要拿到直播小姐姐的封面图片,通过分析上面li标签里面的内容,可以发现下面有个a标签,里面的img标签中的data-original不就是我们要的小姐姐图片嘛!

接下来我们想要获取主播小姐姐的名字怎么办呢?点开li标签继续分析,可以看到下面有个span标签,其中的i标签内容就是小姐姐直播的名字。
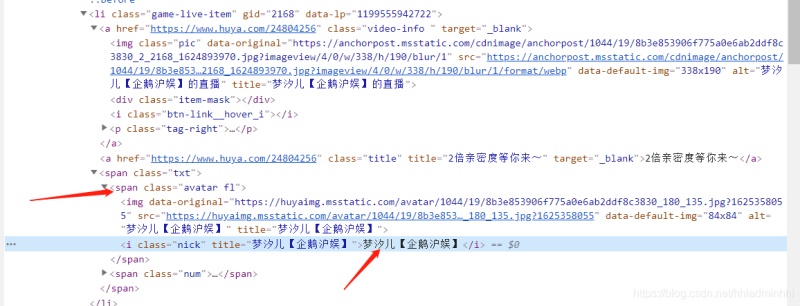
网页结构我们上面已经分析好了,那么我们就可以来动手爬取我们所需要的数据了。获取到所有的数据资源之后,把图片保存下来即可。文件的下载保存的方式比较多,我用的是通过 with open打开文件的方式 ,比较简单。
# 3. 数据解析
selector = parsel.Selector(html_data)
lis = selector.xpath('//li[@class="game-live-item"]') # 所有li标签
for li in lis:
img_name = li.xpath('.//span[@class="avatar fl"]/i/text()').get() # 主播名字
img_url = li.xpath('.//a/img/@data-original').get() # 主播图片地址
# print(img_name, img_url)
# 请求图片数据
img_data = requests.get(url=img_url).content # 图片数据
# 4. 数据保存
# 准备文件名
file_name = img_name + '.jpg'
with open('img\\' + file_name, mode='wb') as f:
f.write(img_data)
print('正在保存:', file_name)
这样小姐姐的直播名称和照片都可以保存下来了,效果如下:

2. 主播颜值评分
我们调用的是百度开放的人脸识别接口 – 百度AI开放平台链接。

这里面我们可以创建一个人脸识别应用,其中的API Key及Secret Key后面我们调用人脸识别检测接口时会用到。

接下来我们可以看看官方提供的API帮助文档,里面介绍的很详细。包括如何调用请求URL数据格式,向API服务地址使用POST发送请求,必须在URL中带上参数access_token,可通过后台的API Key和Secret Key生成。这里面的API Key和Secret Key就是我们上面提到的。

那我们要的打分颜值分数是哪个呢?提供返回结果参数,可以看到里面有个beauty就是我们要的颜值分数。

这样颜值检测的接口流程基本就已经清楚了,可以进行代码实现了。
其中获取token的时候,需要用到client_id 和 client_secret ,这两个就是上面创建人脸识别应用时提供的。
import base64
import requests
# import pprint
# 获取token
def get_token():
# client_id 为官网获取的AK, client_secret 为官网获取的SK
host = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=【官网获取的AK】&client_secret=【官网获取的SK】'
response = requests.get(host)
if response:
# print(response.json())
return response.json()['access_token']
# 颜值检测接口
def face_input(file_path):
with open(file_path, 'rb') as file:
data = base64.b64encode(file.read())
img = data.decode()
request_url = "https://aip.baidubce.com/rest/2.0/face/v3/detect"
params = "{\"image\":\"%s\",\"image_type\":\"BASE64\",\"face_field\":\"beauty\"}" % img
access_token = get_token()
request_url = request_url + "?access_token=" + access_token
headers = {'content-type': 'application/json'}
response = requests.post(request_url, data=params, headers=headers)
if response:
beauty = response.json()['result']['face_list'][0]['beauty']
# pprint.pprint(response.json())
return beauty
可以看到result字段里面的beauty就是代表对小姐姐的颜值评分。效果如下:

调用颜值检测接口已经写好了,下面我们要遍历之前保存的所有小姐姐直播照片,对每个进行颜值打分。
path = './img'
img_list = os.listdir(path)
# print(img_list)
score_dict ={}
for img in img_list:
try:
# 提取主播名字
name = img.split('.')[0]
# 构建图片路径
img_path = path + '//' + img
# 调用颜值检测接口
face_score = face_input(img_path)
# print(face_score)
score_dict[name] = face_score
except:
print(f'正在检测{name}| 检测失败')
else:
print(f'正在检测{name}| \t\t 颜值打分为:{face_score}')
最后我们就只需要按照颜值分数进行降序排列,就可以选出颜值最高的小姐姐啦~
sorted_score = sorted(score_dict.items(), key=lambda x: x[1], reverse=True)
# print(sorted_score)
for i, j in enumerate(sorted_score):
print(f'小姐姐名字是:{sorted_score[i][0]} | 颜值名次是:第{i+1}名 | 颜值分数是:{sorted_score[i][1]}')
通过颜值检测,这样就可以找到颜值最高的小姐姐了,颜值打分有90分以上。今天我们就到这里,明天继续努力!不说了,赶紧看直播去~



如果本篇博客有任何错误,请批评指教,不胜感激 !
到此这篇关于用python写个颜值评分器筛选最美主播的文章就介绍到这了,更多相关python颜值评分器内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

用基于python的appium爬取b站直播消费记录
基于python的Appium进行b站直播消费记录爬取 之前看文章说fiddler也可以进行爬取,但尝试了一下没成功,这次选择appium进行爬取.类似的,可以运用爬取微信朋友圈和抖音等手机app相关数据 正文 #环境配置参考 前期工作准备,需要安装python.jdk.PyCharm.Appium-windows-x.x.Appium_Python_Client.Android SDK,pycharm可以用anaconda的jupyter来替代 具体可以参考这篇博客,讲的算是很清楚啦 http
-
python如何在word中存储本地图片
想要利用Python来操作word文档可以使用docx模块. 安装: pip install python-docx from docx import Document from docx.shared import Inches string = '文字内容' images = '1.jpg' # 保存在本地的图片 doc = Document() # doc对象 doc.add_paragraph(string) # 添加文字 doc.add_picture(images, width=In
-
用python做个代码版的小仙女蹦迪视频
目录 前言 一.核心功能设计 二.实现步骤 1. 下载视频 2. 截取GIF并转换成ASCII字符 3. GIF重命名 4. gif转换为图片jpg 5. 合成代码舞视频 6. 添加背景音乐 前言 最近在B站上看到一个漂亮的仙女姐姐跳舞视频,循环看了亿遍又亿遍,久久不能离开! 看着仙紫小姐姐的蹦迪视频,除了一键三连还能做什么?突发奇想,能不能把小仙女的蹦迪视频转成代码舞呢? 说干就干,今天就手把手教大家如何把跳舞视频转成代码舞,跟着仙女姐姐一起蹦起来~ 视频来源:[紫颜]见过仙女蹦迪吗 [千盏]
-
用python写个颜值评分器筛选最美主播
目录 前言 一.核心功能设计 获取主播直播封面图 主播颜值评分 二.实现步骤 1. 获取主播名称和照片 2. 主播颜值评分 前言 晚上回家闲来无事,想打开某直播平台,看看小姐姐直播.看着一个个多才多艺的小姐姐,眼花缭乱,好难抉择.究竟看哪个小姐姐直播好呢? 今天我们就一起来做个颜值评分器,爬取小姐姐们的直播照片,对每位小姐姐的颜值进行打分排序,选出最靓的star. 一.核心功能设计 总体来说,我们需要做的是获取直播颜值区的主播小姐姐的正在直播的全部主播名称和封面图并保存下来,用百度AI提供的人脸
-
Python调用百度AI实现颜值评分功能
目录 一.调用百度接口进行人脸属性识别 二.根据年龄和性别对颜值进行评价 三.批量识别人脸属性 四.自定义窗口语音播报颜值得分 五.明星颜值评价 一.调用百度接口进行人脸属性识别 安装好baidu-aip模块,获取了百度AI接口密钥后,即可调用百度接口进行人脸属性识别了.首先以杨紫的图片为例进行年龄.性别.颜值的识别. 具体python代码如下: import os import base64 from aip import AipFace os.chdir(r'F:\公众号\28.人脸识别'
-
Python单元测试_使用装饰器实现测试跳过和预期故障的方法
Python单元测试unittest中提供了一下四种装饰器实现测试跳过和预期故障.(使用Python 2.7.13) 请查考Python手册中: https://docs.python.org/dev/library/unittest.html The following decorators implement test skipping and expected failures: #以下装饰器实施测试跳过和预期故障: @unittest.skip(原因) Unconditionally s
-
12步入门Python中的decorator装饰器使用方法
装饰器(decorator)是一种高级Python语法.装饰器可以对一个函数.方法或者类进行加工.在Python中,我们有多种方法对函数和类进行加工,比如在Python闭包中,我们见到函数对象作为某一个函数的返回结果.相对于其它方式,装饰器语法简单,代码可读性高.因此,装饰器在Python项目中有广泛的应用. 装饰器最早在Python 2.5中出现,它最初被用于加工函数和方法这样的可调用对象(callable object,这样的对象定义有call方法).在Python 2.6以及之后的Pyth
-
python实现12306火车票查询器
12306火车票购票软件大家都用过,怎么用Python写一个命令行的火车票查看器,要求在命令行敲一行命令来获得你想要的火车票信息,下面通过本文学习吧. Python火车票查询器 接口设置 先给这个小应用起个名字吧,既然及查询票务信息,那就叫它tickets 我们希望用户只要输入出发站,到达站以及日期就让就能获得想要的信息,所以tickets应该这样被使用: $ tickets from to date 最终 $ tickets [-gdtkz] from to date 开发环境 用virtua
-
Python合并多个装饰器小技巧
django程序,需要写很多api,每个函数都需要几个装饰器,例如 复制代码 代码如下: @csrf_exempt @require_POST def foo(request): pass 既然那么多个方法都需要写2个装饰器,或者多个,有啥办法把多个合并成一行呢? 上面的函数执行过程应该是 复制代码 代码如下: csrf_exempt(require_POST(foo)) 修改成 复制代码 代码如下: def compose(*funs): def deco(f):
-
Python实现多线程HTTP下载器示例
本文将介绍使用Python编写多线程HTTP下载器,并生成.exe可执行文件. 环境:windows/Linux + Python2.7.x 单线程 在介绍多线程之前首先介绍单线程.编写单线程的思路为: 1.解析url: 2.连接web服务器: 3.构造http请求包: 4.下载文件. 接下来通过代码进行说明. 解析url 通过用户输入url进行解析.如果解析的路径为空,则赋值为'/':如果端口号为空,则赋值为"80":下载文件的文件名可根据用户的意愿进行更改(输入'y'表示更改,输入
-
十行代码使用Python写一个USB病毒
大家好,我又回来了. 昨天在上厕所的时候突发奇想,当你把usb插进去的时候,能不能自动执行usb上的程序.查了一下,发现只有windows上可以,具体的大家也可以搜索(搜索关键词usb autorun)到.但是,如果我想,比如,当一个usb插入时,在后台自动把usb里的重要文件神不知鬼不觉地拷贝到本地或者上传到某个服务器,就需要特殊的软件辅助. 于是我心想,能不能用python写一个程序,让它在后台运行.每当有u盘插入的时候,就自动拷贝其中重要文件. 如何判断U盘的插入与否? 首先我们打开电脑终
-
选择Python写网络爬虫的优势和理由
什么是网络爬虫? 网络爬虫是一个自动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成.传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件 爬虫有什么用? 做为通用搜索引擎网页收集器.(google,baidu) 做垂直搜索引擎. 科学研究:在线人类行为,在线社群演化,人类动力学研究,计量社会学,复杂网络,数据挖掘,等领域的实证研究都需要大量数据,网络爬虫是收集相关数据的利器.
-
使用Python写一个量化股票提醒系统
大家在没有阅读本文之前先看下python的基本概念, Python是一种解释型.面向对象.动态数据类型的高级程序设计语言. Python由Guido van Rossum于1989年底发明,第一个公开发行版发行于1991年. 像Perl语言一样, Python 源代码同样遵循 GPL(GNU General Public License)协议. 本文是小兵使用万能的Python写一个量化股票系统!下面是一个小马的迷你量化系统. 这个小迷小量化系统,麻雀虽小但是五脏俱全,我们今天先从实时提醒这个模