pytorch查看模型weight与grad方式
在用pdb debug的时候,有时候需要看一下特定layer的权重以及相应的梯度信息,如何查看呢?
1. 首先把你的模型打印出来,像这样
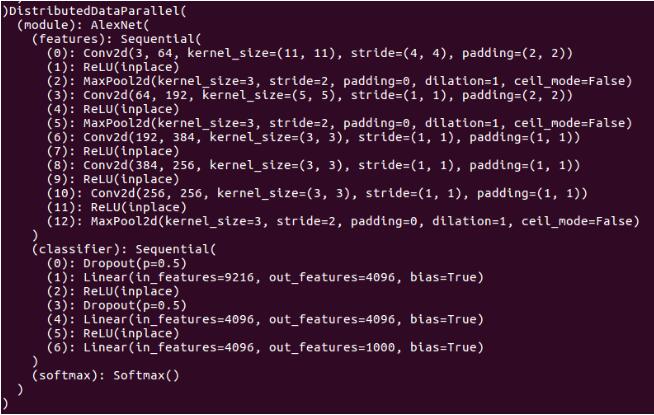
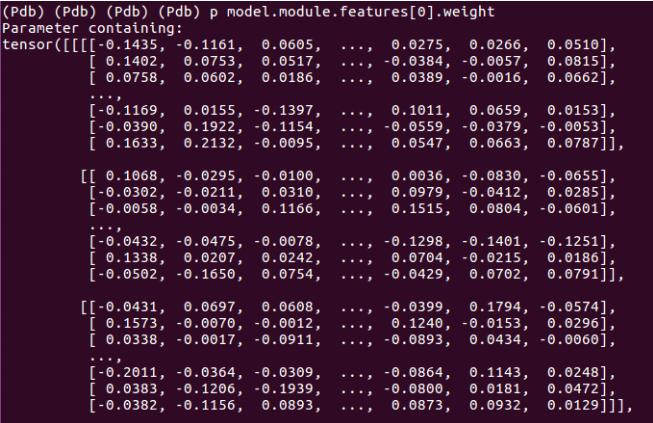
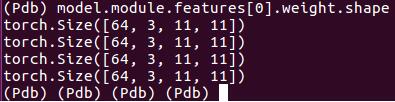
2. 然后观察到model下面有module的key,module下面有features的key, features下面有(0)的key,这样就可以直接打印出weight了,在pdb debug界面输入p model.module.features[0].weight,就可以看到weight,输入 p model.module.features[0].weight.grad就可以查看梯度信息
补充知识:查看Pytorch网络的各层输出(feature map)、权重(weight)、偏置(bias)
BatchNorm2d参数量
torch.nn.BatchNorm2d(num_features, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) # 卷积层中卷积核的数量C num_features – C from an expected input of size (N, C, H, W)
>>> import torch >>> m = torch.nn.BatchNorm2d(100) >>> m.weight.shape torch.Size([100]) >>> m.numel() AttributeError: 'BatchNorm2d' object has no attribute 'numel' >>> m.weight.numel() 100 >>> m.parameters().numel() Traceback (most recent call last): File "<stdin>", line 1, in <module> AttributeError: 'generator' object has no attribute 'numel' >>> [p.numel() for p in m.parameters()] [100, 100]
linear层
>>> import torch >>> m1 = torch.nn.Linear(100,10) # 参数数量= (输入神经元+1)*输出神经元 >>> m1.weight.shape torch.Size([10, 100]) >>> m1.bias.shape torch.Size([10]) >>> m1.bias.numel() 10 >>> m1.weight.numel() 1000 >>> m11 = list(m1.parameters()) >>> m11[0].shape # weight torch.Size([10, 100]) >>> m11[1].shape # bias torch.Size([10])
weight and bias
# Method 1 查看Parameters的方式多样化,直接访问即可 model = alexnet(pretrained=True).to(device) conv1_weight = model.features[0].weight# Method 2 # 这种方式还适合你想自己参考一个预训练模型写一个网络,各层的参数不变,但网络结构上表述有所不同 # 这样你就可以把param迭代出来,赋给你的网络对应层,避免直接load不能匹配的问题! for layer,param in model.state_dict().items(): # param is weight or bias(Tensor) print layer,param
feature map
由于pytorch是动态网络,不存储计算数据,查看各层输出的特征图并不是很方便!分下面两种情况讨论:
1、你想查看的层是独立的,那么你在forward时用变量接收并返回即可!!
class Net(nn.Module):
def __init__(self):
self.conv1 = nn.Conv2d(1, 1, 3)
self.conv2 = nn.Conv2d(1, 1, 3)
self.conv3 = nn.Conv2d(1, 1, 3) def forward(self, x):
out1 = F.relu(self.conv1(x))
out2 = F.relu(self.conv2(out1))
out3 = F.relu(self.conv3(out2))
return out1, out2, out3
2、你的想看的层在nn.Sequential()顺序容器中,这个麻烦些,主要有以下几种思路:
# Method 1 巧用nn.Module.children() # 在模型实例化之后,利用nn.Module.children()删除你查看的那层的后面层 import torch import torch.nn as nn from torchvision import modelsmodel = models.alexnet(pretrained=True)# remove last fully-connected layer new_classifier = nn.Sequential(*list(model.classifier.children())[:-1]) model.classifier = new_classifier # Third convolutional layer new_features = nn.Sequential(*list(model.features.children())[:5]) model.features = new_features
# Method 2 巧用hook,推荐使用这种方式,不用改变原有模型 # torch.nn.Module.register_forward_hook(hook) # hook(module, input, output) -> Nonemodel = models.alexnet(pretrained=True) # 定义 def hook (module,input,output): print output.size() # 注册 handle = model.features[0].register_forward_hook(hook) # 删除句柄 handle.remove()# torch.nn.Module.register_backward_hook(hook) # hook(module, grad_input, grad_output) -> Tensor or None model = alexnet(pretrained=True).to(device) outputs = [] def hook (module,input,output): outputs.append(output) print len(outputs)handle = model.features[0].register_backward_hook(hook)
注:还可以通过定义一个提取特征的类,甚至是重构成各层独立相同模型将问题转化成第一种
计算模型参数数量
def count_parameters(model):
return sum(p.numel() for p in model.parameters() if p.requires_grad)
以上这篇pytorch查看模型weight与grad方式就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
在pytorch中查看可训练参数的例子
pytorch中我们有时候可能需要设定某些变量是参与训练的,这时候就需要查看哪些是可训练参数,以确定这些设置是成功的. pytorch中model.parameters()函数定义如下: def parameters(self): r"""Returns an iterator over module parameters. This is typically passed to an optimizer. Yields: Parameter: module paramete
-
在Pytorch中使用样本权重(sample_weight)的正确方法
step: 1.将标签转换为one-hot形式. 2.将每一个one-hot标签中的1改为预设样本权重的值 即可在Pytorch中使用样本权重. eg: 对于单个样本:loss = - Q * log(P),如下: P = [0.1,0.2,0.4,0.3] Q = [0,0,1,0] loss = -Q * np.log(P) 增加样本权重则为loss = - Q * log(P) *sample_weight P = [0.1,0.2,0.4,0.3] Q = [0,0,sample_wei
-
pytorch获取模型某一层参数名及参数值方式
1.Motivation: I wanna modify the value of some param; I wanna check the value of some param. The needed function: 2.state_dict() #generator type model.modules()#generator type named_parameters()#OrderDict type from torch import nn import torch #creat
-
pytorch查看通道数 维数 尺寸大小方式
查看tensor x.shape # 尺寸 x.size() # 形状 x.ndim # 维数 例如 import torch parser = argparse.ArgumentParser(description='PyTorch') parser.add_argument('--img_w', default=144, type=int, metavar='imgw', help='img width') parser.add_argument('--img_h', default=288
-
pytorch查看模型weight与grad方式
在用pdb debug的时候,有时候需要看一下特定layer的权重以及相应的梯度信息,如何查看呢? 1. 首先把你的模型打印出来,像这样 2. 然后观察到model下面有module的key,module下面有features的key, features下面有(0)的key,这样就可以直接打印出weight了,在pdb debug界面输入p model.module.features[0].weight,就可以看到weight,输入 p model.module.features[0].weig
-
在pytorch中如何查看模型model参数parameters
目录 pytorch查看模型model参数parameters pytorch查看模型参数总结 1:DNN_printer 2:parameters 3:get_model_complexity_info() 4:torchstat pytorch查看模型model参数parameters 示例1:pytorch自带的faster r-cnn模型 import torch import torchvision model = torchvision.models.detection.faster
-

pytorch查看网络参数显存占用量等操作
1.使用torchstat pip install torchstat from torchstat import stat import torchvision.models as models model = models.resnet152() stat(model, (3, 224, 224)) 关于stat函数的参数,第一个应该是模型,第二个则是输入尺寸,3为通道数.我没有调研该函数的详细参数,也不知道为什么使用的时候并不提示相应的参数. 2.使用torchsummary pip in
-
pytorch 实现模型不同层设置不同的学习率方式
在目标检测的模型训练中, 我们通常都会有一个特征提取网络backbone, 例如YOLO使用的darknet SSD使用的VGG-16. 为了达到比较好的训练效果, 往往会加载预训练的backbone模型参数, 然后在此基础上训练检测网络, 并对backbone进行微调, 这时候就需要为backbone设置一个较小的lr. class net(torch.nn.Module): def __init__(self): super(net, self).__init__() # backbone
-
Pytorch 保存模型生成图片方式
三通道数组转成彩色图片 img=np.array(img1) img=img.reshape(3,img1.shape[2],img1.shape[3]) img=(img+0.5)*255##img做过归一化处理,[-0.5,0.5] img_path='/home/isee/wei/image/imageset/result.jpg' img=cv2.merge(img) cv2.imwrite(img_path,img) 单通道数组转化成灰度图 Img_mask=np.array(img_
-
pytorch 查看cuda 版本方式
由于pytorch的whl 安装包名字都一样,所以我们很难区分到底是基于cuda 的哪个版本. 有一条指令可以查看 import torch print(torch.version.cuda) 补充知识:pytorch:网络定义参数的时候后面不能加".cuda()" pytorch定义网络__init__()的时候,参数不能加"cuda()", 不然参数不包含在state_dict()中,比如下面这种写法是错误的 self.W1 = nn.Parameter(tor
-
使用Pytorch搭建模型的步骤
本来是只用Tenorflow的,但是因为TF有些Numpy特性并不支持,比如对数组使用列表进行切片,所以只能转战Pytorch了(pytorch是支持的).还好Pytorch比较容易上手,几乎完美复制了Numpy的特性(但还有一些特性不支持),怪不得热度上升得这么快. 1 模型定义 和TF很像,Pytorch也通过继承父类来搭建自定义模型,同样也是实现两个方法.在TF中是__init__()和call(),在Pytorch中则是__init__()和forward().功能类似,都分别是初始化
-
关于Pytorch中模型的保存与迁移问题
目录 1 引言 2 模型的保存与复用 2.1 查看网络模型参数 2.2 载入模型进行推断 2.3 载入模型进行训练 2.4 载入模型进行迁移 3 总结 1 引言 各位朋友大家好,欢迎来到月来客栈.今天要和大家介绍的内容是如何在Pytorch框架中对模型进行保存和载入.以及模型的迁移和再训练.一般来说,最常见的场景就是模型完成训练后的推断过程.一个网络模型在完成训练后通常都需要对新样本进行预测,此时就只需要构建模型的前向传播过程,然后载入已训练好的参数初始化网络即可. 第2个场景就是模型的再训练过