Python 处理带有 \u 的字符串操作
最近遇到一个头疼的问题,用socket接收到一个字符串
格式如下:
{“trade_status”: {“desc”: “\u30106\u3011 - \u8d22\u52a1\u7ed3\u7b97\u5df2\u5b8c\u6210 “}}/end/
其中含有一段含有\u的编码字串,怎么将其转化为汉字。
decode().encode(‘utf-8') 不行,decode、encode半天搞不定,后来偶然发现,在decode时可以选则unicode-escape
代码如下:
# -*- coding: utf-8 -*-
import socket
if __name__ == '__main__':
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.connect(('192.168.6.63', 10001))
sock.send('[{"action": "trade_status"}]')
rec = sock.recv(1024)
print rec
print rec.decode('unicode-escape').encode('utf-8')
print rec.decode('raw_unicode-escape').encode('utf-8')
sock.close()
输出结果:
{"trade_status": {"desc": "\u30101\u3011 - \u4ea4\u6613\u4e2d "}}/**end**/
{"trade_status": {"desc": "【1】 - 交易中 "}}/**end**/
{"trade_status": {"desc": "【1】 - 交易中 "}}/**end**/
补充:Python3解析【\u】和【\\u】字符
【\u】字符示例
a = '\u5317\u4eac\u5e02' print(a)
北京市
b = '\\u5317\\u4eac\\u5e02' print(b)
\u5317\u4eac\u5e02
json.loads解析
import json a = '\\u5317\\u4eac\\u5e02' b = '"%s"' % a c = json.loads(b) print(a, b, c, sep='\n')
\u5317\u4eac\u5e02
“\u5317\u4eac\u5e02”
北京市
读取文件中\u字符

demjson
from demjson import decode # pip install demjson
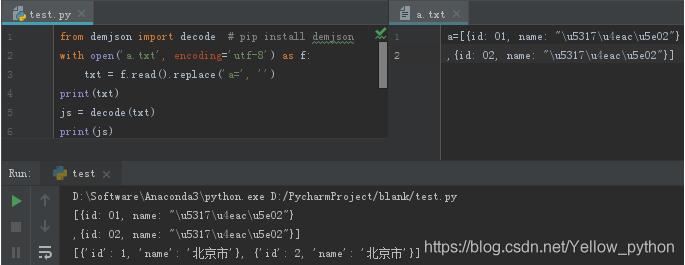
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。如有错误或未考虑完全的地方,望不吝赐教。
相关推荐
-
python去除删除数据中\u0000\u0001等unicode字符串的代码
py文件为utf-8格式 #!/usr/bin/env python # -*- coding:utf-8 -*- a = "system\u0000" b = re.sub(u'\u0000', "", a) print(b) ## b="system" 补充知识:Python中,如何将反斜杠u类型(\uXXXX)的字符串,转换为对应的unicode的字符 [背景] 类似于: \u3232\u6674 的字符串,转换为对应的unicode字符.
-
python str字符串转uuid实例
uuid str int 之间的转换 import uudi #str 转 uuid uuid.UUID('12345678123456781234567812345678') uuid.UUID(hex='12345678123456781234567812345678') uuid.UUID('{12345678-1234-5678-1234-567812345678}') uuid.UUID('urn:uuid:12345678-1234-5678-1234-567812345678')
-
python 工具 字符串转numpy浮点数组的实现
不同的数字之间使用 空格" ","$","*"等隔开,支持带小数点的字符串 NumArray=str2num(LineString,comment='#') 将字符串中的所有非Double类型的字符全部替换成空格 以'#'开头直至行尾的内容被清空 返回一维numpy.array数组 import numpy import scipy def str2num(LineString,comment='#'): from io import Strin
-
关于Python字符串显示u...的解决方式
版本:python2.7 2.7 2.7!!! 症状:比如,我编写了一个字符串number,输出到网页上,变成了u'number' 解决方法: num = "number".encode('utf-8') print(num) 即把它以'utf-8'编码形式编码, 注意encode('utf-8')方法对list和dict类型应该是不支持,如果你想把这些字符串存到list或者dict中, 我的办法是用上面的发放先转换成'utf-8'编码,然后再存到list或者dict中 另外:有人说这
-
浅析python字符串前加r、f、u、l 的区别
先给大家介绍下Python 字符串前面加u,r,b,f的含义(字符串前缀) 1.字符串前加 u 例:u"我是含有中文字符组成的字符串." 作用: 后面字符串以 Unicode 格式 进行编码,一般用在中文字符串前面,防止因为源码储存格式问题,导致再次使用时出现乱码. 2.字符串前加 r 例:r"\n\n\n\n" # 表示一个普通生字符串 \n\n\n\n,而不表示换行了. 作用: 去掉反斜杠的转移机制. (特殊字符:即那些,反斜杠加上对应字母,表示对应的特殊含义的
-
Python判断字符串是否为空和null方法实例
判断python中的一个字符串是否为空,可以使用如下方法 1.使用字符串长度判断 len(s) ==0 则字符串为空 #!/user/local/python/bin/python # coding=utf-8 test1 = '' if len(test1) == 0: print '字符串TEST1为空串' else: print '字符串TEST1不是空串,TEST1:' + test1 2.isspace判断是否字符串全部是空格 Python isspace() 方法检测字符串是否只由空
-
python不相等的两个字符串的 if 条件判断为True详解
今天遇到一个非常基础的问题,结果搞了好久好久.....赶快写一篇博客记录一下: 本来两个不一样的字符串,在if 的条件判断中被判定为True,下面是错误的代码: test_str = 'happy' if test_str == 'good' or 'happy': #这样if判断永远是True,写法错误 print('aa') else: print('bbbb') 这是正确的代码: test_str = 'happy' if test_str == 'good' or test_str ==
-

Python 处理带有 \u 的字符串操作
最近遇到一个头疼的问题,用socket接收到一个字符串 格式如下: {"trade_status": {"desc": "\u30106\u3011 - \u8d22\u52a1\u7ed3\u7b97\u5df2\u5b8c\u6210 "}}/end/ 其中含有一段含有\u的编码字串,怎么将其转化为汉字. decode().encode('utf-8') 不行,decode.encode半天搞不定,后来偶然发现,在decode时可以选则uni
-
Python中的字符串操作和编码Unicode详解
本文主要给大家介绍了关于 Python中的字符串操作和编码Unicode的一些知识,下面话不多说,需要的朋友们下面来一起学习吧. 字符串类型 str:Unicode字符串.采用''或者r''构造的字符串均为str,单引号可以用双引号或者三引号来代替.无论用哪种方式进行制定,在Python内部存储时没有区别. bytes:二进制字符串.由于jpg等其他格式的文件不能用str进行显示,所以才用bytes来表示,bytes的每个字节为一个0-255的数字.如果打印的时候,Python会把能够用ASCI
-
Python常见字符串操作函数小结【split()、join()、strip()】
本文实例讲述了Python常见字符串操作函数.分享给大家供大家参考,具体如下: str.split(' ') 1.按某一个字符分割,如'.' >>> s = ('www.google.com') >>> print(s) www.google.com >>> s.split('.') ['www', 'google', 'com'] 2.按某一个字符分割,且分割n次.如按'.'分割1次:参数maxsplit位切割的次数 >>> s =
-
Python cookbook(字符串与文本)针对任意多的分隔符拆分字符串操作示例
本文实例讲述了Python针对任意多的分隔符拆分字符串操作.分享给大家供大家参考,具体如下: 问题:将分隔符(以及分隔符之间的空格)不一致的字符串拆分为不同的字段: 解决方案:使用更为灵活的re.split()方法,该方法可以为分隔符指定多个模式. 说明:字符串对象的split()只能处理简单的情况,而且不支持多个分隔符,对分隔符周围可能存在的空格也无能为力. # example.py # # Example of splitting a string on multiple delimiter
-
Python使用MD5加密算法对字符串进行加密操作示例
本文实例讲述了Python使用MD5加密算法对字符串进行加密操作.分享给大家供大家参考,具体如下: # encoding: utf-8 from __future__ import division import time import sys reload(sys) time1=time.time() sys.setdefaultencoding('utf-8') #######Md5实现方式1 import hashlib # 创建md5对象 hl = hashlib.md5() passw
-
Python 字符串操作详情
目录 1.字符串的定义 2.转义字符串和原始字符串 4.字符串的运算 4.1 拼接运算符 4.2 成员运算 5.获取字符串长度 6.索引和切片 7.字符串的方法 7.1 转换大小写 7.2 查找操作 7.3性质判断 7.4格式化字符串 8.修剪操作 1.字符串的定义 所谓字符串,就是由0个或者多个字符组成的有限序列. 在Python程序中,如果我们把单个或多个字符用单引号''或者双引号""包裹起来,就可以表示一个字符串,也可以用三个单引号或者双引号进行折行.字符串的字符可以是特殊符号.
-
python字符串操作
目录 一.字符串方法 1.字符串的分割 2.字符串的查找,替换 3.字符串的判断 二.切片操作(列表,元组也可以) 1.索引 2.切片有三个参数[start:end :step] 一.字符串方法 1.字符串的分割 s.split() 默认是按照空格分割 s.split(',') 按照逗号分割(返回的是一个列表,并没有改变原来的字符串) >>> s= "如今最好,别说来日方长,时光难留,只有一去不返" >>> print(s.split(",
-
python字符串操作详析
目录 一.5种字符串检索方法 二.join字符串拼接方法 [列表/元组 --> 字符串] 三.3种字符串分割方法 [字符串 --> 列表/元组] 四.5种大小写转换方法 五.3种字符串修剪方法 字符串是不可变类型,可以重新赋值,但不可以索引改变其中一个值,只能拼接字符串建立新变量 索引和切片索引:越界会报错 切片: 越界会自动修改不包含右端索引需重小到大的写,否则返回空字符串 motto = '积善有家,必有余庆.' # 索引 print(motto[0]) # print(motto[10]
-
Python入门之字符串操作详解
目录 字符串 字符串常用操作 拼接字符串 字符串复制 计算字符串的长度 截取字符串和获取单个字符 字符串包含判断 常用字符串方法 把字符串的第一个字符大写 统计字符串出现的次数 检查字符串开头 检查字符串结尾 大写转小写 小写转大写 大小写翻转 标题化字符串 空格删除 合并字符串 分割字符串 将字符串按照行分割 判断字符串只是数字 判断是空字符 字符串填充 字符串搜索 字符串替换 格式化字符串 字符串编码转换 字符串 字符串常用操作 拼接字符串 拼接字符串需要使用‘+’运算符可完成对多个字符串的
-
python生成带有表格的图片实例
因为工作中需要,需要生成一个带表格的图片 例如: 直接在html中写一个table标签,然后单独把表格部分保存成图片 或者是直接将excel中的内容保存成一个图片 刚开始的思路,是直接生成一个带有table标签的html文件,然后将这个文件转成图片,经过查找资料发现需要安装webkit2png,而这个库又依赖其他的东西,遂放弃. 当初的目标是直接生成一个图片,并且是只需要安装python依赖库就行,而不需要在系统层面安装相应的依赖包 后来考虑使用Python的图片处理库Pillow,和生成表格式