理解深度学习之深度学习简介
机器学习
在吴恩达老师的课程中,有过对机器学习的定义:
ML:<P T E>
P即performance,T即Task,E即Experience,机器学习是对一个Task,根据Experience,去提升Performance;
在机器学习中,神经网络的地位越来越重要,实践发现,非线性的激活函数有助于神经网络拟合分布,效果明显优于线性分类器:
y=Wx+b
常用激活函数有ReLU,sigmoid,tanh;
sigmoid将值映射到(0,1):

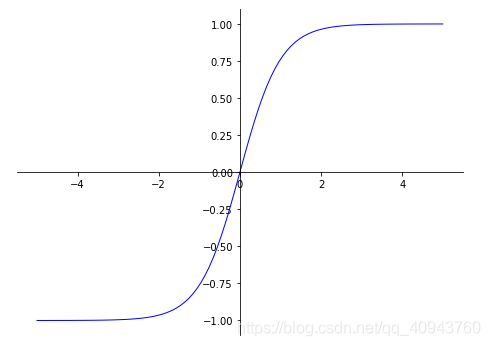
tanh会将输入映射到(-1,1)区间:

#激活函数tanh
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
def tanh(x):
return (np.exp(x)-np.exp(-x))/(np.exp(x)+np.exp(-x))
X=np.linspace(-5,5,100)
plt.figure(figsize=(8,6))
ax=plt.gca()#get current axis:获取当前坐标系
#将该坐标系的右边缘和上边缘设为透明
ax.spines['right'].set_color('none')
ax.spines['top'].set_color('none')
#设置bottom是x轴
ax.xaxis.set_ticks_position('bottom')
ax.spines['bottom'].set_position(('data',0))
#设置left为y轴
ax.yaxis.set_ticks_position('left')
ax.spines['left'].set_position(('data',0))
ax.plot(X,tanh(X),color='blue',linewidth=1.0,linestyle="-")
plt.show()
开源框架
当神经网络层数加深,可以加强捕捉分布的效果,可以简单认为深度学习指深层神经网络的学习;
当前有两大主流的深度学习框架:Pytorch和Tensorflow;
Pytorch支持动态计算图,使用起来更接近Python;
Tensorflow是静态计算图,使用起来就像一门新语言,据说简单易用的keras已经无人维护,合并到tensorflow;
一个深度学习项目的运行流程一般是:
v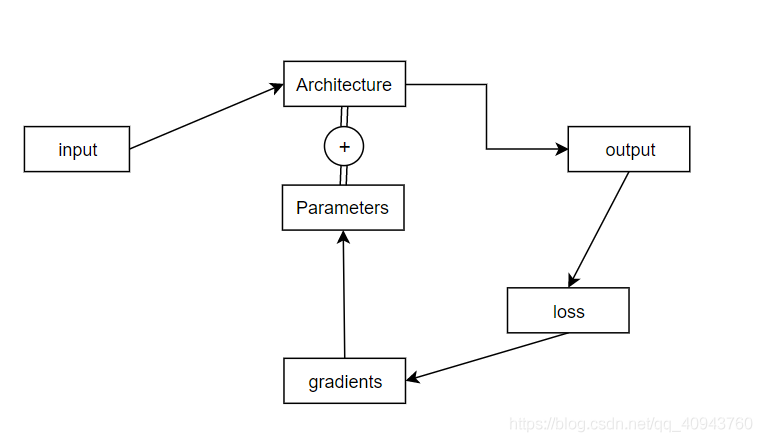
深度学习计算重复且体量巨大,所以需要将模型部署到GPU上,GPU的设计很适合加速深度学习计算,为了便于在GPU上开展深度学习实验,人们开发了CUDA架构,现在大部分DL模型都是基于CUDA加速的
关于CUDA
1.什么是CUDA?
CUDA(ComputeUnified Device Architecture),是显卡厂商NVIDIA推出的运算平台。 CUDA是一种由NVIDIA推出的通用并行计算架构,该架构使GPU能够解决复杂的计算问题。
2.什么是CUDNN?
NVIDIA cuDNN是用于深度神经网络的GPU加速库。它强调性能、易用性和低内存开销。NVIDIA cuDNN可以集成到更高级别的机器学习框架中。
方向概览
当前计算机视觉的发展相对于自然语言处理更加成熟,NLP的训练比CV更耗费资源,CV模型相对较小;
在CV方向:
1.图像分类(ResNet,DenseNet)
- 目标检测ObjectDetection
- 风格迁移StyleTransfer
- CycleGAN:比如图像中马到斑马,也可以从斑马返回马
- ImageCaptioning:从图像生成描述文本,一般用CNN获得feature,再输入RNN获得文本
2.在NLP方向
- 情感分析:分类影评数据
- QuestionAnswering:一段问题->给出答案
- Translation:可以用OpenNMT-py,OpenNMT-py是开源的seq->seq模型
- ChatBot聊天机器人,基于QuestionAnswering,目前刚起步
另外还有强化学习Deep Reinforcement Learning,从简单的打砖块游戏到著名的阿尔法Go;
以及预训练语言模型:给一段话,让机器继续说下去,比如BERT,GPT2;
迁移学习
在CV中,NN的低层可以提取位置信息(边,角等精细信息),高层提取抽象信息,所以低层的网络可以反复使用,更改高层再训练以适用其他任务
到此这篇关于深度学习简介的文章就结束了,以后还会不断更新深度学习的文章,更多相关深度学习文章请搜索我们以前的文章或继续浏览下面的相关文章,希望大家以后多多支持我们!
相关推荐
-
13个最常用的Python深度学习库介绍
如果你对深度学习和卷积神经网络感兴趣,但是并不知道从哪里开始,也不知道使用哪种库,那么这里就为你提供了许多帮助. 在这篇文章里,我详细解读了9个我最喜欢的Python深度学习库. 这个名单并不详尽,它只是我在计算机视觉的职业生涯中使用并在某个时间段发现特别有用的一个库的列表. 这其中的一些库我比别人用的多很多,尤其是Keras.mxnet和sklearn-theano. 其他的一些我是间接的使用,比如Theano和TensorFlow(库包括Keras.deepy和Blocks等). 另外的我只
-
python glom模块的使用简介
工欲善其事,必先利其器!我们想要更轻松更有效率地开发,必须学会一些"高级"技能.前不久看到一位 Python 高僧的代码,其中使用了一个短小精悍的模块,我认为还蛮有用的,今天分享给大家. 这个模块就叫 glom ,是 Python 处理数据的一个小模块,它具有如下特点: 嵌套结构并基于路径访问 使用轻量级的Pythonic规范进行声明性数据转换 可读.有意义的错误信息 内置数据探测和调试功能 看起来比较抽象,对不对?下面我们用实例来给大家演示一下. 安装 作为 Python 内置模块,
-

深度学习详解之初试机器学习
机器学习可应用在各个方面,本篇将在系统性进入机器学习方向前,初步认识机器学习,利用线性回归预测波士顿房价: 原理简介 利用线性回归最简单的形式预测房价,只需要把它当做是一次线性函数y=kx+b即可.我要做的就是利用已有数据,去学习得到这条直线,有了这条直线,则对于某个特征x(比如住宅平均房间数)的任意取值,都可以找到直线上对应的房价y,也就是模型的预测值. 从上面的问题看出,这应该是一个有监督学习中的回归问题,待学习的参数为实数k和实数b(因为就只有一个特征x),从样本集合sample中取出一对
-
Python 的lru_cache装饰器使用简介
Python 的 lru_cache 装饰器是一个为自定义函数提供缓存功能的装饰器.其内部会在下次以相同参数调用该自定义函数时直接返回计算好的结果.通过缓存计算结果可以很好地提升性能. 1 从示例说起 假设我们有一个计算斐波那契数列的求和函数,其内部采用递归方式实现. from xxx.clock_decorator import clock @clock def fibonacci(n): if n<2: return n return fibonacci(n-2)+fibonacci(n-1
-
深入学习SpringCloud之SpringCloud简介
Spring Cloud是什么? SpringCloud官网:http://spring.io Spring Cloud是一个一站式的开发分布式系统的框架,为开发者提供了一系列的构建分布式系统的工具集.Spring Cloud为开发人员提供了快速构建分布式系统中一些常见模式的工具(比如:配置管理,服务发现,断路器,智能路由.微代理.控制总线.全局锁.决策竞选.分布式会话和集群状态管理等).开发分布式系统都需要解决一系列共同关心的问题,而使用Spring Cloud可以快速地实现这些分布式开发共同
-
C语言入门学习笔记之typedef简介
在单片机和操作系统中 typedef 会经常用到,它可以为某一个类型自定义名称.和#define比较类似.但是又有不同的地方. typedef 创建的符号只能用于数据类型,不能用于值.而#define 创建的符号可以用于值. typedef 是由编译器来解释,而不是预处理器. typedef 使用起来更加灵活. 下面使用typedef定义一个数据类型 int main() { typedef unsigned char BYTE; BYTE c = 10; printf("%d \r\n&quo
-
理解深度学习之深度学习简介
机器学习 在吴恩达老师的课程中,有过对机器学习的定义: ML:<P T E> P即performance,T即Task,E即Experience,机器学习是对一个Task,根据Experience,去提升Performance: 在机器学习中,神经网络的地位越来越重要,实践发现,非线性的激活函数有助于神经网络拟合分布,效果明显优于线性分类器: y=Wx+b 常用激活函数有ReLU,sigmoid,tanh: sigmoid将值映射到(0,1): tanh会将输入映射到(-1,1)区间: #激活
-
Java 并发编程学习笔记之Synchronized简介
一.Synchronized的基本使用 Synchronized是Java中解决并发问题的一种最常用的方法,也是最简单的一种方法.Synchronized的作用主要有三个:(1)确保线程互斥的访问同步代码(2)保证共享变量的修改能够及时可见(3)有效解决重排序问题.从语法上讲,Synchronized总共有三种用法: (1)修饰普通方法 (2)修饰静态方法 (3)修饰代码块 接下来我就通过几个例子程序来说明一下这三种使用方式(为了便于比较,三段代码除了Synchronized的使用方式不同以外,
-
Smarty模板学习笔记之Smarty简介
1.简介 Smarty是一个使用PHP写出来的模板PHP模板引擎,是目前业界最著名的PHP模板引擎之一.它分离了逻辑代码和外在的内容,提供了一种易于管理和使用的方法,用来将原本与HTML代码混杂在一起PHP代码逻辑分离.简单的讲,目的就是要使PHP程序员同前端分离,使PHP程序员改变程序的逻辑内容不会影响到前端的页面设计,前端重新修改页面不会影响到程序的程序逻辑,这在多人合作的项目中显的尤为重要. 2.那么smarty有什么优点呢? a.速度:采用Smarty编写的程序可以获得最大速度的提高,这
-
《Python学习手册》学习总结
本篇文章是作者关于在学习了<Python学习手册>以后,分享的学习心得,在此之前,我们先给大家分享一下这本书: 下载地址:Python学习手册第4版 之前为了编写一个svm分词的程序而简单学了下Python,觉得Python很好用,想深入并系统学习一下,了解一些机制,因此开始阅读<Python学习手册>. 在前两章节都是对基本的信息做了概述,我们从第三章开始. 第三章 如何运行程序 import进行模块导入只能运行一次,多次运行需使用reload. 模块往往是变量名的封装,被认为是
-
JavaScript该如何学习 怎样轻松学习JavaScript
js给初学者的印象总是那么的"杂而乱",相信很多初学者都在找轻松学习js的途径.我试着总结自己学习多年js的经验,希望能给后来的学习者探索出一条"轻松学习js之路".js给人那种感觉的原因多半是因为它如下的特点: A:本身知识很抽象.晦涩难懂,如:闭包.内置对象.DOM. B:本身内容很多,如函数库.对象库就一大堆. C:混合多种编程思想.它里面不但牵涉面向过程编程思想,又有面向对象编程思想,同时,它的面向对象还和别的编程语言(如:C++,JAVA,PHP)不大一样
-
2020版Python学习路线图(附学习资料)
python应该是近几年比较火的语言之一,很多人刚学python不知道该如何学习,尤其是没有编程基础想要从事程序员工作的小白,想必应该都会有此疑惑,包括我刚学python的时候也是通过从网上查找相关资料以及从学校课程学习才确定python学习的方向,为了帮助想从事python工作的小白,所以我把python学习的大致路线图以及每个阶段需要学习的具体内容都整理出来,希望能帮助零基础的小白少走一些弯路. Python 类库(模块)极其丰富,这使得 Python 几乎无所不能,不管是传统的 Web 开
-
Prototype 学习 工具函数学习($w,$F方法)
$w方法 Splits a string into an Array, treating all whitespace as delimiters. Equivalent to Ruby's %w{foo bar} or Perl's qw(foo bar). 复制代码 代码如下: function $w(string) { if (!Object.isString(string)) return []; string = string.strip(); return string ? stri
-
Prototype 学习 工具函数学习($A方法)
$A方法: Accepts an array-like collection (anything with numeric indices) and returns its equivalent as an actual Array object. This method is a convenience alias of Array.from, but is the preferred way of casting to an Array. 复制代码 代码如下: function $A(ite