PyTorch 迁移学习实践(几分钟即可训练好自己的模型)
前言
如果你认为深度学习非常的吃GPU,或者说非常的耗时间,训练一个模型要非常久,但是你如果了解了迁移学习那你的模型可能只需要几分钟,而且准确率不比你自己训练的模型准确率低,本节我们将会介绍两种方法来实现迁移学习
迁移学习方法介绍
微调网络的方法实现迁移学习,更改最后一层全连接,并且微调训练网络将模型看成特征提取器,如果一个模型的预训练模型非常的好,那完全就把前面的层看成特征提取器,冻结所有层并且更改最后一层,只训练最后一层,这样我们只训练了最后一层,训练会非常的快速
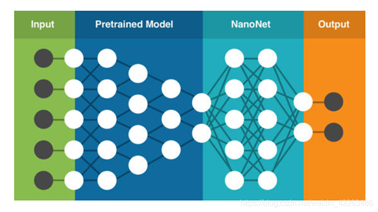
迁移基本步骤
- 数据的准备
- 选择数据增广的方式
- 选择合适的模型
- 更换最后一层全连接
- 冻结层,开始训练
- 选择预测结果最好的模型保存
需要导入的包
import zipfile # 解压文件 import torchvision from torchvision import datasets, transforms, models import torch from torch.utils.data import DataLoader, Dataset import os import cv2 import numpy as np import matplotlib.pyplot as plt from PIL import Image import copy
数据准备
本次实验的数据到这里下载
首先按照上一章节讲的数据读取方法来准备数据
# 解压数据到指定文件
def unzip(filename, dst_dir):
z = zipfile.ZipFile(filename)
z.extractall(dst_dir)
unzip('./data/hymenoptera_data.zip', './data/')
# 实现自己的Dataset方法,主要实现两个方法__len__和__getitem__
class MyDataset(Dataset):
def __init__(self, dirname, transform=None):
super(MyDataset, self).__init__()
self.classes = os.listdir(dirname)
self.images = []
self.transform = transform
for i, classes in enumerate(self.classes):
classes_path = os.path.join(dirname, classes)
for image_name in os.listdir(classes_path):
self.images.append((os.path.join(classes_path, image_name), i))
def __len__(self):
return len(self.images)
def __getitem__(self, idx):
image_name, classes = self.images[idx]
image = Image.open(image_name)
if self.transform:
image = self.transform(image)
return image, classes
def get_claesses(self):
return self.classes
# 分布实现训练和预测的transform
train_transform = transforms.Compose([
transforms.Grayscale(3),
transforms.RandomResizedCrop(224), #随机裁剪一个area然后再resize
transforms.RandomHorizontalFlip(), #随机水平翻转
transforms.Resize(size=(256, 256)),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
val_transform = transforms.Compose([
transforms.Grayscale(3),
transforms.Resize(size=(256, 256)),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
# 分别实现loader
train_dataset = MyDataset('./data/hymenoptera_data/train/', train_transform)
train_loader = DataLoader(train_dataset, shuffle=True, batch_size=32)
val_dataset = MyDataset('./data/hymenoptera_data/val/', val_transform)
val_loader = DataLoader(val_dataset, shuffle=True, batch_size=32)
选择预训练的模型
这里我们选择了resnet18在ImageNet 1000类上进行了预训练的
model = models.resnet18(pretrained=True) # 使用预训练
使用model.buffers查看网络基本结构
<bound method Module.buffers of ResNet(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer2): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer3): Sequential(
(0): BasicBlock(
(conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer4): Sequential(
(0): BasicBlock(
(conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Linear(in_features=512, out_features=1000, bias=True)
)>
我们现在需要做的就是将最后一层进行替换
only_train_fc = True
if only_train_fc:
for param in model.parameters():
param.requires_grad_(False)
fc_in_features = model.fc.in_features
model.fc = torch.nn.Linear(fc_in_features, 2, bias=True)
注释:only_train_fc如果我们设置为True那么就只训练最后的fc层
现在观察一下可导的参数有那些(在只训练最后一层的情况下)
for i in model.parameters():
if i.requires_grad:
print(i)
Parameter containing:
tensor([[ 0.0342, -0.0336, 0.0279, ..., -0.0428, 0.0421, 0.0366],
[-0.0162, 0.0286, -0.0379, ..., -0.0203, -0.0016, -0.0440]],
requires_grad=True)
Parameter containing:
tensor([-0.0120, -0.0086], requires_grad=True)
注释:由于最后一层使用了bias因此我们会多加两个参数
训练主体的实现
epochs = 50
loss_fn = torch.nn.CrossEntropyLoss()
opt = torch.optim.SGD(lr=0.01, params=model.parameters())
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
# device = torch.device('cpu')
model.to(device)
opt_step = torch.optim.lr_scheduler.StepLR(opt, step_size=20, gamma=0.1)
max_acc = 0
epoch_acc = []
epoch_loss = []
for epoch in range(epochs):
for type_id, loader in enumerate([train_loader, val_loader]):
mean_loss = []
mean_acc = []
for images, labels in loader:
if type_id == 0:
# opt_step.step()
model.train()
else:
model.eval()
images = images.to(device)
labels = labels.to(device).long()
opt.zero_grad()
with torch.set_grad_enabled(type_id==0):
outputs = model(images)
_, pre_labels = torch.max(outputs, 1)
loss = loss_fn(outputs, labels)
if type_id == 0:
loss.backward()
opt.step()
acc = torch.sum(pre_labels==labels) / torch.tensor(labels.shape[0], dtype=torch.float32)
mean_loss.append(loss.cpu().detach().numpy())
mean_acc.append(acc.cpu().detach().numpy())
if type_id == 1:
epoch_acc.append(np.mean(mean_acc))
epoch_loss.append(np.mean(mean_loss))
if max_acc < np.mean(mean_acc):
max_acc = np.mean(mean_acc)
print(type_id, np.mean(mean_loss),np.mean(mean_acc))
print(max_acc)
在使用cpu训练的情况,也能快速得到较好的结果,这里训练了50次,其实很快的就已经得到了很好的结果了
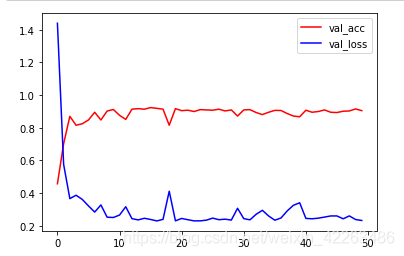
总结
本节我们使用了预训练模型,发现大概10个epoch就可以很快的得到较好的结果了,即使在使用cpu情况下训练,这也是迁移学习为什么这么受欢迎的原因之一了,如果读者有兴趣可以自己试一试在不冻结层的情况下,使用方法一能否得到更好的结果
到此这篇关于PyTorch 迁移学习实践(几分钟即可训练好自己的模型)的文章就介绍到这了,更多相关PyTorch 迁移内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python 如何查看pytorch版本
看代码吧~ import torch print(torch.__version__) 补充:pytorch不同版本安装以及版本查看 一:基于conda安装 conda create --name pytorch_learn python=3.6.7#创建一个名为pytorch_learn的环境 source activate pytorch_learn #进入环境 conda install pytorch=0.3.1 cuda80 -c soumith #安装pytorch0.3.1+ cu
-

解决PyTorch与CUDA版本不匹配的问题
1.CUDA驱动和CUDA Toolkit对应版本 表一:CUDA驱动及CUDA Toolkit最高对应版本 最新可查阅官方文档 注:驱动是向下兼容的,其决定了可安装的CUDA Toolkit的最高版本. 2.CUDA Toolkit版本及其可用PyTorch对应版本(参考官网) 表二:CUDA Toolkit版本及可用PyTorch对应关系 CUDAToolkit版本 可用PyTorch版本 7.5 0.4.1 ,0.3.0, 0.2.0,0.1.12-0.1.6 8.0 1.1.0,1.0.
-
PyTorch数据读取的实现示例
前言 PyTorch作为一款深度学习框架,已经帮助我们实现了很多很多的功能了,包括数据的读取和转换了,那么这一章节就介绍一下PyTorch内置的数据读取模块吧 模块介绍 pandas 用于方便操作含有字符串的表文件,如csv zipfile python内置的文件解压包 cv2 用于图片处理的模块,读入的图片模块为BGR,N H W C torchvision.transforms 用于图片的操作库,比如随机裁剪.缩放.模糊等等,可用于数据的增广,但也不仅限于内置的图片操作,也可以自行进行图片数
-
PyTorch 检查GPU版本是否安装成功的操作
anaconda命令行下检查: (base) PS C:\Users\chenxuqi> conda deactivate PS C:\Users\chenxuqi> conda activate ssd (ssd) PS C:\Users\chenxuqi> python Python 3.6.12 |Anaconda, Inc.| (default, Sep 9 2020, 00:29:25) [MSC v.1916 64 bit (AMD64)] on win32 Type &qu
-
超详细PyTorch实现手写数字识别器的示例代码
前言 深度学习中有很多玩具数据,mnist就是其中一个,一个人能否入门深度学习往往就是以能否玩转mnist数据来判断的,在前面很多基础介绍后我们就可以来实现一个简单的手写数字识别的网络了 数据的处理 我们使用pytorch自带的包进行数据的预处理 import torch import torchvision import torchvision.transforms as transforms import numpy as np import matplotlib.pyplot as plt
-
Pytorch BertModel的使用说明
基本介绍 环境: Python 3.5+, Pytorch 0.4.1/1.0.0 安装: pip install pytorch-pretrained-bert 必需参数: --data_dir: "str": 数据根目录.目录下放着,train.xxx/dev.xxx/test.xxx三个数据文件. --vocab_dir: "str": 词库文件地址. --bert_model: "str": 存放着bert预训练好的模型. 需要是一个gz
-
PyTorch 迁移学习实践(几分钟即可训练好自己的模型)
前言 如果你认为深度学习非常的吃GPU,或者说非常的耗时间,训练一个模型要非常久,但是你如果了解了迁移学习那你的模型可能只需要几分钟,而且准确率不比你自己训练的模型准确率低,本节我们将会介绍两种方法来实现迁移学习 迁移学习方法介绍 微调网络的方法实现迁移学习,更改最后一层全连接,并且微调训练网络 将模型看成特征提取器,如果一个模型的预训练模型非常的好,那完全就把前面的层看成特征提取器,冻结所有层并且更改最后一层,只训练最后一层,这样我们只训练了最后一层,训练会非常的快速 迁移基本步骤 数据的准备
-
PyTorch一小时掌握之迁移学习篇
目录 概述 为什么使用迁移学习 更好的结果 节省时间 加载模型 ResNet152 冻层实现 模型初始化 获取需更新参数 训练模型 获取数据 完整代码 概述 迁移学习 (Transfer Learning) 是把已学训练好的模型参数用作新训练模型的起始参数. 迁移学习是深度学习中非常重要和常用的一个策略. 为什么使用迁移学习 更好的结果 迁移学习 (Transfer Learning) 可以帮助我们得到更好的结果. 当我们手上的数据比较少的时候, 训练非常容易造成过拟合的现象. 使用迁移学习可以
-
Pytorch卷积神经网络迁移学习的目标及好处
目录 前言 一.经典的卷积神经网络 二.迁移学习的目标 三.好处 四.步骤 五.代码 前言 在深度学习训练的过程中,随着网络层数的提升,我们训练的次数,参数都会提高,训练时间相应就会增加,我们今天来了解迁移学习 一.经典的卷积神经网络 在pytorch官网中,我们可以看到许多经典的卷积神经网络. 附官网链接:https://pytorch.org/ 这里简单介绍一下经典的卷积神经发展历程 1.首先可以说是卷积神经网络的开山之作Alexnet(12年的夺冠之作)这里简单说一下缺点 卷积核大,步长大
-
Pytorch模型迁移和迁移学习,导入部分模型参数的操作
1. 利用resnet18做迁移学习 import torch from torchvision import models if __name__ == "__main__": # device = torch.device("cuda" if torch.cuda.is_available() else "cpu") device = 'cpu' print("-----device:{}".format(device))
-
Pytorch深度学习经典卷积神经网络resnet模块训练
目录 前言 一.resnet 二.resnet网络结构 三.resnet18 1.导包 2.残差模块 2.通道数翻倍残差模块 3.rensnet18模块 4.数据测试 5.损失函数,优化器 6.加载数据集,数据增强 7.训练数据 8.保存模型 9.加载测试集数据,进行模型测试 四.resnet深层对比 前言 随着深度学习的不断发展,从开山之作Alexnet到VGG,网络结构不断优化,但是在VGG网络研究过程中,人们发现随着网络深度的不断提高,准确率却没有得到提高,如图所示: 人们觉得深度学习到此
-
聊聊基于pytorch实现Resnet对本地数据集的训练问题
目录 1.dataset.py(先看代码的总体流程再看介绍) 2.network.py 3.train.py 4.结果与总结 本文是使用pycharm下的pytorch框架编写一个训练本地数据集的Resnet深度学习模型,其一共有两百行代码左右,分成mian.py.network.py.dataset.py以及train.py文件,功能是对本地的数据集进行分类.本文介绍逻辑是总分形式,即首先对总流程进行一个概括,然后分别介绍每个流程中的实现过程(代码+流程图+文字的介绍). 对于整个项目的流程首
-
pytorch 如何使用amp进行混合精度训练
简介 AMP:Automatic mixed precision,自动混合精度,可以在神经网络推理过程中,针对不同的层,采用不同的数据精度进行计算,从而实现节省显存和加快速度的目的. 在Pytorch 1.5版本及以前,通过NVIDIA提供的apex库可以实现amp功能.但是在使用过程中会伴随着一些版本兼容和奇怪的报错问题. 从1.6版本开始,Pytorch原生支持自动混合精度训练,并已进入稳定阶段,AMP 训练能在 Tensor Core GPU 上实现更高的性能并节省多达 50% 的内存.
-
详解tensorflow实现迁移学习实例
本文主要是总结利用tensorflow实现迁移学习的基本步骤. 所谓迁移学习,就是将上一个问题上训练好的模型通过简单的调整使其适用于一个新的问题.比如说,我们可以保留训练好的Inception-v3模型中所有的参数,只替换最后一层全连接层.在最后一层全连接层之前的网络称之为瓶颈层(bottleneck). 持久化 首先需要简单介绍下tensorflow中的持久化:在tensorflow中提供了一个非常简单的API来保存和还原一个神经网络模型,这个API就是tf.train.Saver类.当采用该
-
浅谈迁移学习
目录 一.背景 二.定义及分类 2.1.目标 2.2.主要思想 2.3.迁移学习的形式定义及一种分类方式 三.关键点 四.基于实例的迁移 五.基于特征的迁移 5.1.特征选择 5.2.特征映射 六.基于共享参数的迁移 七.深度学习和迁移学习结合 八.Pre-training+Fine-tuning 九.DANN (Domain-Adversarial Neural Network) 一.背景 随着越来越多的机器学习应用场景的出现,而现有表现比较好的监督学习需要大量的标注数据,标注数据是一项枯燥无
-
pyTorch深度学习softmax实现解析
目录 用PyTorch实现linear模型 模拟数据集 定义模型 加载数据集 optimizer 模型训练 softmax回归模型 Fashion-MNIST cross_entropy 模型的实现 利用PyTorch简易实现softmax 用PyTorch实现linear模型 模拟数据集 num_inputs = 2 #feature number num_examples = 1000 #训练样本个数 true_w = torch.tensor([[2],[-3.4]]) #真实的权重值 t