使用go语言实现查找两个数组的异同操作
最近项目上碰到个小需求,输入是两个数组,一个旧数组一个新数组,要求获取新数组相对旧数组所有新增和删除的元素,例如:
输入:
arr_old: {"1", "2", "4", "5", "7", "9"}
arr_new: {"2", "3", "4", "6", "7"}
返回:
arr_added: {"3", "6"}
arr_deleted: {"1", "5", "9"}
go的标准库中没有类似的直接比较的方法,需要自己具体实现,最简单的方法当然是旧数组的每个元素去新数组,找不到的就是删除的,然后新数组的元素再挨个去旧数组找一遍,找不到就是新增的,但这个方法效率实在太低了。
这里我使用了一种基于集合运算的思想,即分别求两个数组的交集和并集,并集减去交集就是所有发生变化的元素(要么是新增的,要么是删除的),遍历这个集合中的元素去旧数组中查找,如果在旧数组中找到,那么就是删除掉的元素;反之,如果找不到,则一定能在新数组中找到(用不着真的再去遍历一次),那么就是新增的元素。
上代码,这里有个技巧,就是利用go中map键唯一性的特性,用数组的元素作为map的key,通过map来实现快速查找。
package main
import (
"fmt"
)
func main() {
//fmt.Println("Hello World!")
src := []string{"1", "2", "4", "5", "7", "9"}
dest := []string{"2", "3", "4", "6", "7"}
added, removed := Arrcmp(src, dest)
fmt.Printf("add: %v\nrem: %v\n", added, removed)
}
func Arrcmp(src []string, dest []string) ([]string, []string) {
msrc := make(map[string]byte) //按源数组建索引
mall := make(map[string]byte) //源+目所有元素建索引
var set []string //交集
//1.源数组建立map
for _, v := range src {
msrc[v] = 0
mall[v] = 0
}
//2.目数组中,存不进去,即重复元素,所有存不进去的集合就是并集
for _, v := range dest {
l := len(mall)
mall[v] = 1
if l != len(mall) { //长度变化,即可以存
l = len(mall)
} else { //存不了,进并集
set = append(set, v)
}
}
//3.遍历交集,在并集中找,找到就从并集中删,删完后就是补集(即并-交=所有变化的元素)
for _, v := range set {
delete(mall, v)
}
//4.此时,mall是补集,所有元素去源中找,找到就是删除的,找不到的必定能在目数组中找到,即新加的
var added, deleted []string
for v, _ := range mall {
_, exist := msrc[v]
if exist {
deleted = append(deleted, v)
} else {
added = append(added, v)
}
}
return added, deleted
}
运行结果:
add: [6 3]
rem: [1 5 9]
欢迎大家交流效率更高的方法。
补充:go语言教程之浅谈数组和切片的异同
本期的分享我们来讲解一下关于go语言的数组和切片的概念、用法和区别。
在go语言的程序开发过程中,我们避免不了数组和切片。关于他们的用法和区别却使得有的小伙伴感觉困惑。所以小栈君这里也归纳和总结了关于数组和切片的干货帮助小伙伴进行理解。
数组的定义
数组是具有相同唯一类型的一组已编号且长度固定的数据项序列,这种类型可以是任意的原始类型例如整形、字符串或者自定义类型。
相对于去声明 number0, number1, ..., number99 的变量,使用数组形式 numbers[0], numbers[1] ..., numbers[99] 更加方便且易于扩展。
数组元素可以通过索引(位置)来读取(或者修改),索引从 0 开始,第一个元素索引为 0,第二个索引为 1,以此类推。

总体来讲的话数组就是同一种类型的固定长度的序列。
在go语言中数组的定义是很简单的。

如图所示,我们定义了一个长度为2的数组,在数组定义的过程中,系统已经对这个数组进行了初始化并分配了空间。所以我们如果想要进行赋值可以通过数组名加上下标的方式进行赋值。但是值得注意的一点是我们并不能进行数组的超长处理。这一点有别于java的数组定义,java的定长数组添加值后如果对于超出的值会有自动扩容功能。

但是在go语言中并没有方法来进行增删改查值,只有通过下标的方式,所以我们如果进行了越界处理编译都会进行报错。所以才入门的小伙伴们需要注意一下哦。数组的下标在数组的合法范围之外就会出发访问越界,会有panic出现。所以小栈君也是通过了一个实例给大家说明一下,因为编译可能会不通过,所以我们巧妙的避开编译器的编译进行数组的越界操作说明。

当然需要值得注意的一点是,数组的长度也是数组类型的一部分,因此var a [2]int 和 var b [3] int 是两个不同的类型。
知识点来了,在go语言中的数组是属于值类型传递,当我们传递一个数组到一个方法中,改变副本的值并不会修改到原本数组的值。所以得到的数组还是原来的样子。
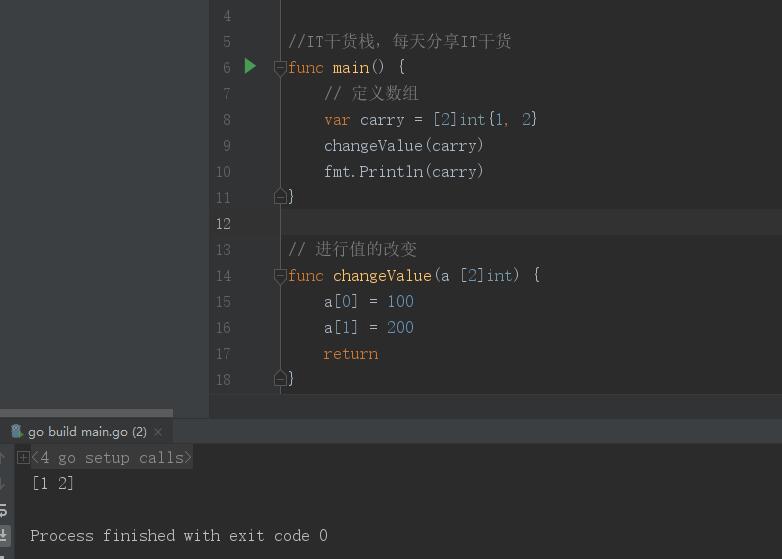
因此如果我们要对数组进行值的修改的话,就只有进行指针操作啦~。

切片的概念
在go语言中数组中长度不可以更改,所以在实际的应用环境中并不是非常实用,所以Go语言衍生出了一种灵活性强和功能更强大的内置类型,即为切片。
与上面所讲的数组相比,切片的长度是不固定的,并且切片是可以进行扩容。切片对象非常小,是因为它是只有3个字段的数据结构:一个是指向底层数组的指针,一个是切片的长度,一个是切片的容量。这3个字段,就是Go语言操作底层数组的元数据,有了它们,我们就可以任意的操作切片了。
当然,切片作为数组的引用,所以切片属于是引用类型,各位小伙伴可千万要记住了哦。在切片的使用过程当中,我们可以通过遍历数组的方式进行对于切片的遍历,我们也可以内置方法len对数组或切片进行长度的计算。
当然我们也可以对切片的容量进行计算,之前有讲过Go语言有丰富的内置库提供给我们使用,所以我们也可以cap内置函数进行容量的计算。多个切片如果表示同一个数组的片段,它们可以共享数据;因此一个切片和相关数组的其他切片是共享存储的,相反,不同的数组总是代表不同的存储。数组实际上是切片的构建块。
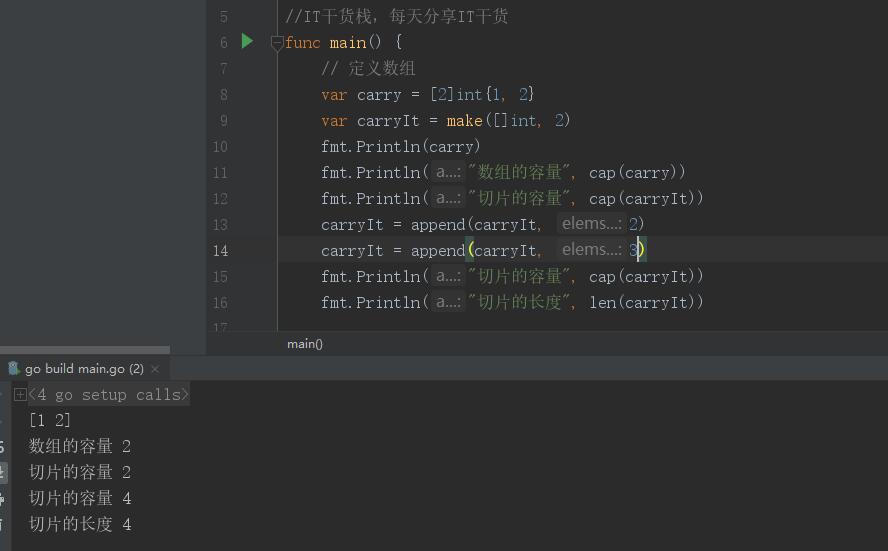

上面的例子小栈君分别用数组和切片进行了测试,我们可以看到数组的容量一旦确定后就无法进行更改,当我们的切片进行初始化,初始的容量是2,此时切片的容量和长度都是2,但是我通过内置的append方法进行了切片的增加。此时的切片的容量和长度都是4。此时我们并不能确定切片内置扩容的机制,但是隐约猜测是倍增。
言归正传,为了测试一下切片的扩容机制,所以小栈君又进行了切片的增加,此时,细心的小伙伴应该发现,这次小栈君一次性增加了两个元素在一个append里面,因为这是append方法是一个可变长度的传值。这也是一个小知识点哦。
如果切片的底层数组,没有足够的容量时,就会新建一个底层数组,把原来数组的值复制到新底层数组里,再追加新值,这时候就不会影响原来的底层数组了。
append目前的算法是:容量小于1000个时,总是成倍的增长,一旦容量超过1000个,增长因子设为1.25,也就是说每次会增加25%的容量。
之后我们发现切片的容量和长度发生了变化,如果说上次容量的扩张是4是我们猜测的倍数扩容方式,那么这次我们就实锤了他的扩容机制就是倍增。而且在Go语言的容量和长度不一样,所以我们也可以得出结论,就是在 0 <= len(arry) <= cap(slice)。
在我们声明好切片后我们可以使用new或是make方法对切片进行初始化,当然小栈君也试着尝试证明切片如果没有进行初始化是会panic的。结果并没有出现。因为如果slice没有初始化,它仅仅相当于一个nil,长度和容量都为0,并不会panic。

小栈君也考虑到可能是因为没有内置增加方法或是没有报错仅仅只是因为我后面利用对Carry数组的切割进行赋值的缘故。所以不甘心又做了一次尝试,定义好相应的切片后直接使用append方法,结果如下:

我们同样可以通过上述的例子了解到切片的下标是左闭右开区间,因为我们carry数组的内容如上图所示, 我们最终得到的结果是IT干货栈,下标来讲的话是属于1。所以我们得到的结论和事实是一样的。对于切片我们也有很多用法,如下图所示:

下图是Python中对于切片的操作,并且Python中的数组更为灵活,在后面我为大家分享Python教程的时候会详细分享哦。

切片的初始化
对于切片的初始化我们可以make方法和new方法

new(T) 为每个新的类型T分配一片内存,初始化为 0 并且返回类型为*T的内存地址:这种方法 返回一个指向类型为 T,值为 0 的地址的指针,它适用于值类型如数组和结构体;它相当于 &T{}。
make(T) 返回一个类型为 T 的初始值,它只适用于3种内建的引用类型:切片、map 和 channel。
拷贝
因为在go语言的数组是属于值传递,之前的方法也证实了这一点,在方法传递值的时候系统会进行拷贝一份副本进行传递,如果需要改变的值的话就需要使用指针。但是在使用切片处理的时候,因为切片属于引用传递,所以go语言有内置的函数copy方法进行值的拷贝。

上述的一个例子可以综合说明几点问题了,最开始我们定义了一个切片并且容量是2,内容是1和2,我们同样定义了切片b但是并没有做初始化处理。直接使用copy操作。使用copy操作的时候,小栈君也复制了源码出来,第一个是我们的数据源,第二个参数传递我们的目标源。直接使用的话我们可以从结果看出并没有成功。
所以接下来小栈君又进行了初始化操作。这里举例的目的是提醒各位,在操作切片的时候没有初始化就相当于nil,最好是进行切片的初始化操作。在早期go语言的版本中,没有初始化切片会直接报错。接下来我又进行了再一次的复制操作并且打印出他们的地址和容量、长度。可以看出进行切片的拷贝是不会进行切片的扩容处理。而且他们分别指向了不同的地址说明拷贝成功。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。如有错误或未考虑完全的地方,望不吝赐教。
相关推荐
-
浅谈Go语言中字符串和数组
go语言里边的字符串处理和PHP还有java 的处理是不一样的,首先申明字符串和修改字符串 复制代码 代码如下: package main import "fmt" var name string //申明一个字符串 var emptyname string = "" //申明一个空字符串 func main() { //申明多个字符串并且赋值 a, b, v := "hello", "word", &
-

go for range遍历二维数组的示例
go for range 遍历二维数组 var arry [2][3] int for index,_ := range arry { fmt.Print(index) } 运行结果: 0 1 没有遍历所有的6个元素. 二维数组 arry 可以理解为:拥有两个 一维数组元素 的一维数组,所以以上只是遍历了其的两个元素,index分别是0 1,value是两个 拥有三个int类型元素 的一维数组. var arry [2][3] int for index,value := range arr
-
简单谈谈Golang中的字符串与字节数组
前言 字符串是 Go 语言中最常用的基础数据类型之一,虽然字符串往往都被看做是一个整体,但是实际上字符串是一片连续的内存空间,我们也可以将它理解成一个由字符组成的数组,Go 语言中另外一个与字符串关系非常密切的类型就是字节(Byte)了,相信各位读者也都非常了解,这里也就不展开介绍. 我们在这一节中就会详细介绍这两种基本类型的实现原理以及它们的转换关系,但是这里还是会将介绍的重点主要放在字符串上,因为这是我们接触最多的一种基本类型并且后者就是一个简单的 uint8 类型,所以会给予 string
-
详解go 动态数组 二维动态数组
go使用动态数组还有点麻烦,比python麻烦一点,需要先定义. 动态数组申明 var dynaArr []string 动态数组添加成员 dynaArr = append(dynaArr, "one") ```go # 结构体数组 ```go package main import ( "fmt" ) type A struct{ Path string Length int } func main() { var dynaArr []A t := A{"
-
go特性之数组与切片的问题
数组: 复制传递(不要按照c/c++的方式去理解,c/c++中数组是引用传递),定长 切片: 引用传递,底层实现是3个字段 array(数组) + len(长度) +cap(容量) go/src/runtime/slice.go slice结构定义: type slice struct { array unsafe.Pointer len int cap int } 要特别注意的是,切片的引用传递指的是切片传递时,切片的array字段是引用传递的,len和cap字段依然是赋值传递. 写个伪代码:
-
使用go语言实现查找两个数组的异同操作
最近项目上碰到个小需求,输入是两个数组,一个旧数组一个新数组,要求获取新数组相对旧数组所有新增和删除的元素,例如: 输入: arr_old: {"1", "2", "4", "5", "7", "9"} arr_new: {"2", "3", "4", "6", "7"} 返回: arr_
-
php实现对两个数组进行减法操作的方法
本文实例讲述了php实现对两个数组进行减法操作的技巧.分享给大家供大家参考.具体如下: 本代码传入两个数组A和B,返回A-B的结果,即挑选出存在于A,但不存在于B的元素 <?php function RestaDeArrays($vectorA,$vectorB) { $cantA=count($vectorA); $cantB=count($vectorB); $No_saca=0; for($i=0;$i<$cantA;$i++) { for($j=0;$j<$cantB;$j++)
-
C语言怎么连接两个数组的内容你知道吗
目录 要求: 源代码如下: 运行效果图如下: 总结 要求: 定义两个数组,并用指针将两个数组的内容连接到一起 源代码如下: #include<stdio.h> void main() { char str1[100],str2[100],*p1,*p2; p1=str1; p2=str2; printf("请输入str1的内容:\n"); gets(str1); printf("请输入str2的内容:\n"); gets(str2); while(*p1
-
C语言面试C++二维数组中的查找示例
目录 二维数组中的查找 面试题3: 暴力遍历 动态基点操作 二维数组中的查找 面试题3: 似题: 我做过这个类似的有杨氏矩阵为背景的,实际上是一样的 暴力遍历 二维数组暴力遍历的话时间复杂度为O(n2) 虽然暴力但是应付学校考试这个就是一把好手 #include<stdio.h> //const 就是因为二维数组是定死的 int search(const int arr[4][4], int num,unsigned int* prow,unsigned int* pcol) { int i
-
C语言中判断两数组中是否有相同的元素
思路: 首先创建两个数组,分别为a[ ]和b[ ]先拿a数组里的第一个元素和b数组的所有元素比较是否相同,再拿a数组里的第二个元素与b数组所有元素进行比较,以此类推.运用两次for循环来完成,用i循环生成a数组的各个下标,在循环体中用j循环生成b数组下标,j循环中判断a[ i ]是否等于b[ j ],如果条件成立即相同元素.flag用来标记程序运行到某一刻的状态,来加以判断if中的语句是否执行. system函数的作用是运行以字符串参数的形式传递给他的命令,并且等待该命令的完成,形式:#incl
-
C语言静态动态两版本通讯录实战源码
目录 正片开始 静态版本 头文件( phonebook.h) 接口(test.c) 功能板块(phonebook.c) 1. 初始化: 2. 增添: 3.查找 4.删除 5.修改 6.排序 7.全览 静态版全部代码 test.c(接口) phonebook.h(头文件) phonebook.c(功能) 动态版 动态初始化: 扩容函数 动态版全部代码 test.c phonebook.h 正片开始 这里为了方便对照,我搬出整个程序的前后修改版本,并分别作为静态和动态版本,实际差距并不大,提供出来只
-
C语言详细讲解树状数组与线段树
目录 树状数组 动态求连续区间和 数星星 线段树 动态求连续区间和 数列区间最大值 树状数组 动态求连续区间和 给定 n 个数组成的一个数列,规定有两种操作,一是修改某个元素,二是求子数列 [a,b] 的连续和. 输入格式第一行包含两个整数 n 和 m,分别表示数的个数和操作次数. 第二行包含 n 个整数,表示完整数列. 接下来 m 行,每行包含三个整数 k,a,b (k=0,表示求子数列[a,b]的和:k=1,表示第 a 个数加 b). 数列从 1 开始计数. 输出格式输出若干行数字,表示 k
-
C语言折半查找法的由来及使用详解
目录 引入二分查找 分析二分查找 计算中间下标的两种方法 第一种 第二种 代码实现 总结 引入二分查找 本文带着大家学习一个简单的**二分查找算法,也叫折半查找算法** 先给大家提出一个问题 额,大家应该都会碰到这种情况,那大家怎么猜呢? 我想一定是会说1000,他说太少了,你又猜1500… 这其实就是二分查找的应用. 接下来我们来看一个问题 如何在一个有序数组中查找一个数字? 有一部分帅气的观众可能会说: 直接遍历数组,一个一个对比就找到了啊 但是大家有没有想过一个问题,数组中如果只有几十个数
-
C语言实现手写Map(数组+链表+红黑树)的示例代码
目录 要求 结构 红黑树和链表转换策略 hash 使用 要求 需要准备数组集合(List) 数据结构 需要准备单向链表(Linked) 数据结构 需要准备红黑树(Rbtree)数据结构 需要准备红黑树和链表适配策略(文章内部提供,可以自行参考) 建议先去阅读我博客这篇文章C语言-手写Map(数组+链表)(全功能)有助于理解 hashmap使用红黑树的原因是: 当某个节点值过多的时候那么链表就会非常长,这样搜索的时候查询速度就是O(N) 线性查询了,为了避免这个问题我们使用了红黑树,当链表长度大于
-
详解C语言中的函数、数组与指针
1.函数:当程序很小的时候,我们可以使用一个main函数就能搞定,但当程序变大的时候,就超出了人的大脑承受范围,逻辑不清了,这时候就需要把一个大程序分成许多小的模块来组织,于是就出现了函数概念: 函数是C语言代码的基本组成部分,它是一个小的模块,整个程序由很多个功能独立的模块(函数)组成.这就是程序设计的基本分化方法: (1) 写一个函数的关键: 函数定义:函数的定义是这个函数的实现,函数定义中包含了函数体,函数体中的代码段决定了这个函数的功能: 函数声明:函数声明也称函数原型声明,函数的原