navicat无法连接postgreSQL-11的解决方案
1. 通过find / -name postgresql.conf 和 find / -name pg_hba.conf 找到这两个文件
2. 设置外网访问:
1)修改配置文件 postgresql.conf
listen_addresses = '*'
2)修改pg_hba.conf 在原来的host下面新加一行
# IPv4 local connections: host all all 127.0.0.1/32 trust host all all 0.0.0.0/0 password
3. 重新启动服务:service postgresql-11 restart
补充:navicat链接PostgreSQL出错。
navicat premium 链接PostgreSQL出现: column “rolcatupdate” does not exist ...
错误如图:
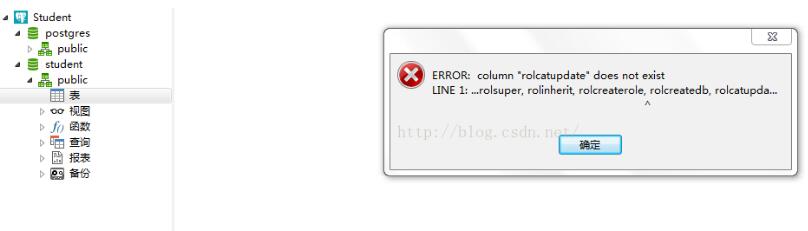
解决方案:
看看你的navicat 是否为最新的(版本为12即可。)
如果不是那就删除你本地的重新下载一个navicat下载最新的即可。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。如有错误或未考虑完全的地方,望不吝赐教。
相关推荐
-
PostgreSQL 设置允许访问IP的操作
PostgreSQL安装后默认只能localhost:5432访问 检验方法: curl localhost:5432 # 访问成功提示 curl: (52) Empty reply from server curl 127.0.0.1:5432 # 访问不成功提示 curl: (7) Failed to connect to 172.17.201.227 port 5432: Connection refused 修改pg_hba.conf pg_hba.conf和postgresql.con
-

sqoop读取postgresql数据库表格导入到hdfs中的实现
最近再学习spark streaming做实时计算这方面内容,过程中需要从后台数据库导出数据到hdfs中,经过调研发现需要使用sqoop进行操作,本次操作环境是Linux下. 首先确保环境安装了Hadoop和sqoop,安装只需要下载 ,解压 以及配置环境变量,这里不多说了,网上教程很多. 一.配置sqoop以及验证是否成功 切换到配置文件下:cd $SQOOP_HOME/conf 创建配置环境文件: cp sqoop-env-template.sh sqoop-env.sh 修改配置文件:co
-
PostgreSQL 流复制异步转同步的操作
非常重要的synchronous_commit参数 流复制的同步方式,有主库配置文件postgresql.conf,中的synchronous_commit控制着.所以理解该参数的配置十分重要. 单实例环境 参数值 说明 优点 缺点 on 或 local 当事务提交时,WAL先写入WAL buffer 再写到 WAL文件(落盘)中.设置为on表示提交事务时需要等待本地WAL最终落盘后,才向客户端返回成功. 非常安全 数据库性能有损耗 off 当事务提交时,不需要等待WAL先写入WAL buffe
-
sqoop 实现将postgresql表导入hive表
使用sqoop导入数据至hive常用语句 直接导入hive表 sqoop import --connect jdbc:postgresql://ip/db_name --username user_name --table table_name --hive-import -m 5 内部执行实际分三部,1.将数据导入hdfs(可在hdfs上找到相应目录),2.创建hive表名相同的表,3,将hdfs上数据传入hive表中 sqoop根据postgresql表创建hive表 sqoop creat
-
PostgreSQL 允许远程访问设置的操作
postgres远程连接方式配置 配置pg_hba.conf文件 目录C:\Program Files\PostgreSQL\9.5\data (QXY)主机 [postgres@qxy data]$ pwd /spark/pgsql/data [postgres@qxy data]$ cat pg_hba.conf # TYPE DATABASE USER ADDRESS METHOD # "local" is for Unix domain socket connections o
-
解决sqoop从postgresql拉数据,报错TCP/IP连接的问题
问题: sqoop从postgresql拉数据,在执行到mapreduce时报错Connection refused. Check that the hostname and port are correct and that the postmaster is accepting TCP/IP connections 问题定位过程: 1.postgresql 5432端口已开放,执行任务的节点能telnet通,并且netcat测试通过 2.sqoop list-tables命令可正常执行,sq
-
postgresql流复制原理以及流复制和逻辑复制的区别说明
流复制的原理: 物理复制也叫流复制,流复制的原理是主库把WAL发送给备库,备库接收WAL后,进行重放. 逻辑复制的原理: 逻辑复制也是基于WAL文件,在逻辑复制中把主库称为源端库,备库称为目标端数据库,源端数据库根据预先指定好的逻辑解析规则对WAL文件进行解析,把DML操作解析成一定的逻辑变化信息(标准SQL语句),源端数据库把标准SQL语句发给目标端数据库,目标端数据库接收到之后进行应用,从而实现数据同步. 流复制和逻辑复制的区别: 流复制主库上的事务提交不需要等待备库接收到WAL文件后的确认
-
navicat无法连接postgreSQL-11的解决方案
1. 通过find / -name postgresql.conf 和 find / -name pg_hba.conf 找到这两个文件 2. 设置外网访问: 1)修改配置文件 postgresql.conf listen_addresses = '*' 2)修改pg_hba.conf 在原来的host下面新加一行 # IPv4 local connections: host all all 127.0.0.1/32 trust host all all 0.0.0.0/0 password 3
-
Oracle导dmp出现文件ORA-12154: TNS: 无法解析指定的连接标识符问题的解决方案
其实TNS无法解析是Oracle操作里经常遇到的问题,原因有二: (1)Oracle服务器没有装好(一般不建议重装,因为Oracle卸载不完全是没法重装的) (2)TNS没有配置 现在本文给出解决方案: 现在先测试一下tns是否可以ping,成功的界面大致如下 (1)在oracle安装路径的tns配置文件里添加如下代码 # tnsnames.ora Network Configuration File: d:\Oracle\product\10.2.0\client_1\NETWORK\ADMI
-
Abp.NHibernate连接PostgreSQl数据库的方法
Abp.NHibernate动态库连接PostgreSQl数据库,供大家参考,具体内容如下 初次接触Abp框架,其框架中封装的操作各类数据的方法还是很好用的,本人还在进一步的学习当中,并将利用abp.NHibernate类库操作PostgreSQL数据的相关方法做一记录,不足之处让评论指点扔砖. 话不多说,直接开干: 1.vs 新建一个项目,(窗体或者控制台程序或者测试程序) 2.NuGet 获取类库(adp.NHibernate) 还需安装一个pgSQl 对应的驱动 3.新建一个继承AbpMo
-
解决Navicat Premium 连接 MySQL 8.0 报错"1251"的问题分析
人闲太久,努力一下就以为是在拼命. 一.问题 Navicat Premium 连接 MySQL 8.0 报错: 1251 - Client does not support authentication protocol requested by server; consider upgrading MySQL client 二.原因 MySQL 8.0 改变了密码认证方式. 在 MySQL 8.0 之前版本的密码认证方式为: mysql_native_password 为了提供更安全的密码加密
-
解决navicat远程连接mysql报错10038的问题
navicat远程连接mysql报错10038一般由以下两个原因: 一:本地防火墙问题 在本地安装了mysql.navicat并打开了mysql服务的情况下,来设置防火墙. 首先右击或者点击入站规则,找到新建规则,点击. 点击端口. 在特定本地端口中填入3306. 一直点击下一步. 这里可以给一个好分别的名称即可. 之前再尝试连接即可,若仍然不可以,可能是服务器方面的问题. 二:服务器3306端口未打开 首先需要在安全组开放端口. 我这里使用的是阿里云服务器.首先需要进入云服务器,找到安全组.
-
使用Navicat Premium连接Oracle的方法步骤
软件环境 本文使用的软件版本为: Windows 10 专业版 64 位(10.0,版本 10586) Navicat Premium 11.0.18 (x64) instantclient-basic-windows.x64-12.2.0.1.0 vcredist_x64.exe (Microsoft Visual C++ 2013 Redistributable (x64) - 12.0.40660) 直接使用 Navicat 连接 Oracle 出现的问题 在安装完 Navicat 之后,
-
VMware workstation16 中Centos7下MySQL8.0安装过程及Navicat远程连接
目录 一.CentOS7+MySQL8.0,yum源安装 二.登录mysql以及修改密码 三.远程登录 1.MySQL yum源安装 2.安装后,首次登录mysql以及密码配置 3.远程登录问题(Navicat15为例) 一.CentOS7+MySQL8.0,yum源安装 1.安装mysql前应卸载原有mysql,如果没有请忽虑 1.1找出原有mysql安装目录 输入命令 rpm -qa | grep mysql 后出现以下几行 1.2用以下命令依次删除上述出现的文件 1.3删除mysl配置文件
-
java连接postgresql数据库代码及maven配置方式
目录 java连接postgresql代码及maven配置 maven依赖 Springboo连接数据库通用代码 创建连接并执行业务逻辑 数据库通用类 maven配置 java连接postgresql代码及maven配置 postgresql数据库有默认数据库用户postgres,密码安装库时自己输入: 当然也可以连接其他用户: maven依赖 db2依赖 <dependency> <groupId>org.apache.commons</groupId>
-
Python连接PostgreSQL数据库的方法
前言 其实在Python中可以用来连接PostgreSQL的模块很多,这里比较推荐psycopg2.psycopg2安装起来非常的简单(pip install psycopg2),这里主要重点介绍下如何使用. 连接数据库: import psycopg2 conn = psycopg2.connect(host="10.100.157.168",user="postgres",password="postgres",database="
-
Java连接postgresql数据库的示例代码
本文介绍了Java连接postgresql数据库的示例代码,分享给大家,具体如下: 1.下载驱动jar 下载地址:https://jdbc.postgresql.org/download.html 2.导入jar包 新建lib文件夹,将下载的jar驱动包拖到文件夹中. 将jar驱动包添加到Libraries 3.程序代码如下:HelloWorld.java package test; import java.sql.Connection; import java.sql.DriverManage