利用Sharding-Jdbc进行分库分表的操作代码
目录
- 1. Sharding-Jdbc介绍
- 2. Sharding-Jdbc引入使用
- 3. 配置广播表
- 4. 配置绑定表
- 5. 读写分离配置
1. Sharding-Jdbc介绍
https://shardingsphere.apache.org/
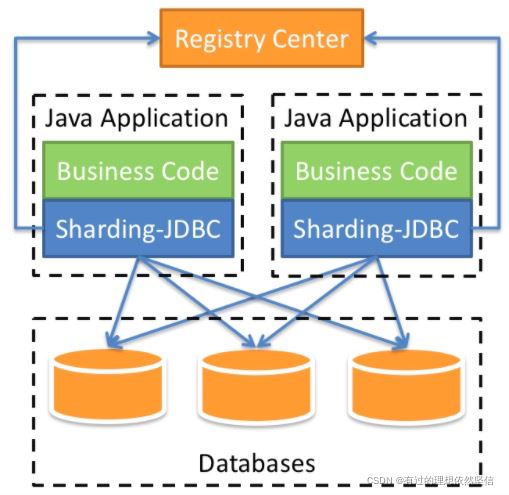
- sharding-jdbc是一个分布式的关系型数据库中间件
- 客户端代理模式,不需要搭建服务器,只需要后端数据库即可,有个IDE就行了
- 定位于轻量级的Java框架,以jar的方式提供服务
- 可以理解为增强版的jdbc驱动
- 完全兼容主流的ORM框架
sharding-jdbc提供了4种配置
- Java API
- yaml
- properties
- spring命名空间
与MyCat的区别
- MyCat是服务端的代理,Sharding-Jdbc是客户端代理
- 实际开发中如果企业有DBA建议使用MyCat,都是开发人员建议使用sharding-jdbc
- MyCat不支持在一个库内进行水平分表,而sharding-jdbc支持在同一个数据库中进行水平分表
名词解释
- 逻辑表:物流的合并表
- 真实表:存放数据的地方
- 数据节点:存储数据的MySQL节点
- 绑定表:相当于MyCat中的子表
- 广播表:相当于MyCat中的全局表
2. Sharding-Jdbc引入使用
# 0.首先在两个MySQL上创建两个数据:shard_order # 1.分表给两个库创建两个表order_info_1,order_info_2 CREATE TABLE `order_info_1` ( `id` int(11) NOT NULL, `order_amount` decimal(10,2) DEFAULT NULL, `order_status` int(255) DEFAULT NULL, `user_id` int(11) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; CREATE TABLE `order_info_2` ( `id` int(11) NOT NULL, `order_amount` decimal(10,2) DEFAULT NULL, `order_status` int(255) DEFAULT NULL, `user_id` int(11) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; # 2.切分规则,按照id的奇偶数切分到两个数据库,在自己的数据库按照user_id进行表切分
代码导入POM依赖
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.0.0-RC2</version>
</dependency>
配置properties
# 给两个数据源命名
spring.shardingsphere.datasource.names=ds0,ds1
# 数据源链接ds0要和命名一致
spring.shardingsphere.datasource.ds0.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.ds0.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.ds0.jdbcUrl=jdbc:mysql://39.103.163.215:3306/shard_order
spring.shardingsphere.datasource.ds0.username=gavin
spring.shardingsphere.datasource.ds0.password=123456
# 数据源链接ds1要和命名一致
spring.shardingsphere.datasource.ds1.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.ds1.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.ds1.jdbcUrl=jdbc:mysql://39.101.221.95:3306/shard_order
spring.shardingsphere.datasource.ds1.username=gavin
spring.shardingsphere.datasource.ds1.password=123456
# 具体的分片规则,基于数据节点
spring.shardingsphere.sharding.tables.order_info.actual-data-nodes=ds$->{0..1}.order_info_$->{1..2}
# 分库的规则
spring.shardingsphere.sharding.tables.order_info.database-strategy.inline.sharding-column=id
spring.shardingsphere.sharding.tables.order_info.database-strategy.inline.algorithm-expression=ds$->{id % 2}
# 分表的规则
spring.shardingsphere.sharding.tables.order_info.table-strategy.inline.sharding-column=user_id
spring.shardingsphere.sharding.tables.order_info.table-strategy.inline.algorithm-expression=order_info_$->{user_id % 2 + 1}
//测试代码
@SpringBootTest
class ShardingjdbcProjectApplicationTests {
@Autowired
JdbcTemplate jdbcTemplate;
@Test
void insertTest(){
String sql = "insert into order_info(id,order_amount,order_status,user_id) values(3,213.88,1,2)";
int i = jdbcTemplate.update(sql);
System.out.println("影响行数:"+i);
}
}
作业:自己练习一下sharding-jdbc的分库分表
3. 配置广播表
先在两个库上创建广播表province_info
CREATE TABLE `province_info` ( `id` int(11) NOT NULL, `name` varchar(255) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
在properties里增加配置
spring.shardingsphere.sharding.broadcast-tables=province_info
测试插入和查询的代码
@Test
void insertBroadcast(){
String sql = "insert into province_info(id,name) values(1,'beijing')";
int i = jdbcTemplate.update(sql);
System.out.println("******* 影响的结果:"+i);
}
@Test
void selectBroadcast(){
String sql = "select * from province_info";
List<Map<String,Object>> result = jdbcTemplate.queryForList(sql);
for (Map<String,Object> val: result) {
System.out.println("=========== "+val.get("id")+" ----- "+val.get("name"));
}
}
4. 配置绑定表
首先按照order_info的建表顺序创建order_item分别在两个库上建立order_item_1,order_item_2
@Test
void insertBroadcast(){
String sql = "insert into province_info(id,name) values(1,'beijing')";
int i = jdbcTemplate.update(sql);
System.out.println("******* 影响的结果:"+i);
}
@Test
void selectBroadcast(){
String sql = "select * from province_info";
List<Map<String,Object>> result = jdbcTemplate.queryForList(sql);
for (Map<String,Object> val: result) {
System.out.println("=========== "+val.get("id")+" ----- "+val.get("name"));
}
}
配置绑定表,将两个表的分表逻辑和order_info保持一致
# 给两个数据源命名
spring.shardingsphere.datasource.names=ds0,ds1
# 数据源链接ds0要和命名一致
spring.shardingsphere.datasource.ds0.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.ds0.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.ds0.jdbcUrl=jdbc:mysql://39.103.163.215:3306/shard_order
spring.shardingsphere.datasource.ds0.username=gavin
spring.shardingsphere.datasource.ds0.password=123456
# 数据源链接ds1要和命名一致
spring.shardingsphere.datasource.ds1.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.ds1.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.ds1.jdbcUrl=jdbc:mysql://39.101.221.95:3306/shard_order
spring.shardingsphere.datasource.ds1.username=gavin
spring.shardingsphere.datasource.ds1.password=123456
# 具体的分片规则,基于数据节点
spring.shardingsphere.sharding.tables.order_info.actual-data-nodes=ds$->{0..1}.order_info_$->{1..2}
# 分库的规则
spring.shardingsphere.sharding.tables.order_info.database-strategy.inline.sharding-column=id
spring.shardingsphere.sharding.tables.order_info.database-strategy.inline.algorithm-expression=ds$->{id % 2}
# 分表的规则
spring.shardingsphere.sharding.tables.order_info.table-strategy.inline.sharding-column=user_id
spring.shardingsphere.sharding.tables.order_info.table-strategy.inline.algorithm-expression=order_info_$->{user_id % 2 + 1}
# 具体的分片规则,基于数据节点
spring.shardingsphere.sharding.tables.order_item.actual-data-nodes=ds$->{0..1}.order_item_$->{1..2}
# 分库的规则
spring.shardingsphere.sharding.tables.order_item.database-strategy.inline.sharding-column=order_id
spring.shardingsphere.sharding.tables.order_item.database-strategy.inline.algorithm-expression=ds$->{order_id % 2}
# 分表的规则
spring.shardingsphere.sharding.tables.order_item.table-strategy.inline.sharding-column=user_id
spring.shardingsphere.sharding.tables.order_item.table-strategy.inline.algorithm-expression=order_item_$->{user_id % 2 + 1}
# 绑定表关系
spring.shardingsphere.sharding.binding-tables=order_info,order_item
# 广播表
spring.shardingsphere.sharding.broadcast-tables=province_info
5. 读写分离配置
首先配置properties的数据源,如果有主机配置就必须要有从机配置
# 指定主从的配置节点
spring.shardingsphere.datasource.names=master0,master0slave0,master1,master1slave0
# master0数据源链接配置
spring.shardingsphere.datasource.master0.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.master0.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.master0.jdbcUrl=jdbc:mysql://39.103.163.215:3306/shard_order
spring.shardingsphere.datasource.master0.username=gavin
spring.shardingsphere.datasource.master0.password=123456
# master0slave0数据源链接配置
spring.shardingsphere.datasource.master0slave0.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.master0slave0.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.master0slave0.jdbcUrl=jdbc:mysql://39.99.212.46:3306/shard_order
spring.shardingsphere.datasource.master0slave0.username=gavin
spring.shardingsphere.datasource.master0slave0.password=123456
# master1数据源链接配置
spring.shardingsphere.datasource.master1.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.master1.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.master1.jdbcUrl=jdbc:mysql://39.101.221.95:3306/shard_order
spring.shardingsphere.datasource.master1.username=gavin
spring.shardingsphere.datasource.master1.password=123456
# master1slave0数据源链接配置
spring.shardingsphere.datasource.master1slave0.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.master1slave0.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.master1slave0.jdbcUrl=jdbc:mysql://localhost:3306/shard_order
spring.shardingsphere.datasource.master1slave0.username=root
spring.shardingsphere.datasource.master1slave0.password=gavin
# 具体的分片规则,基于数据节点
spring.shardingsphere.sharding.tables.order_info.actual-data-nodes=ds$->{0..1}.order_info_$->{1..2}
# 分库的规则
spring.shardingsphere.sharding.tables.order_info.database-strategy.inline.sharding-column=id
spring.shardingsphere.sharding.tables.order_info.database-strategy.inline.algorithm-expression=ds$->{id % 2}
# 分表的规则
spring.shardingsphere.sharding.tables.order_info.table-strategy.inline.sharding-column=user_id
spring.shardingsphere.sharding.tables.order_info.table-strategy.inline.algorithm-expression=order_info_$->{user_id % 2 + 1}
# 具体的分片规则,基于数据节点
spring.shardingsphere.sharding.tables.order_item.actual-data-nodes=ds$->{0..1}.order_item_$->{1..2}
# 分库的规则
spring.shardingsphere.sharding.tables.order_item.database-strategy.inline.sharding-column=order_id
spring.shardingsphere.sharding.tables.order_item.database-strategy.inline.algorithm-expression=ds$->{order_id % 2}
# 分表的规则
spring.shardingsphere.sharding.tables.order_item.table-strategy.inline.sharding-column=user_id
spring.shardingsphere.sharding.tables.order_item.table-strategy.inline.algorithm-expression=order_item_$->{user_id % 2 + 1}
# 绑定表关系
spring.shardingsphere.sharding.binding-tables=order_info,order_item
# 广播表
spring.shardingsphere.sharding.broadcast-tables=province_info
# 读写分离主从关系绑定
spring.shardingsphere.sharding.master-slave-rules.ds0.master-data-source-name=master0
spring.shardingsphere.sharding.master-slave-rules.ds0.slave-data-source-names=master0slave0
spring.shardingsphere.sharding.master-slave-rules.ds0.load-balance-algorithm-type=round_robin
spring.shardingsphere.sharding.master-slave-rules.ds1.master-data-source-name=master1
spring.shardingsphere.sharding.master-slave-rules.ds1.slave-data-source-names=master1slave0
spring.shardingsphere.sharding.master-slave-rules.ds1.load-balance-algorithm-type=random
到此这篇关于Sharding-Jdbc进行分库分表的文章就介绍到这了,更多相关Sharding-Jdbc分库分表内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Sharding-Jdbc 自定义复合分片的实现(分库分表)
目录 Sharding-JDBC的数据分片策略 分片键 分片算法 分片策略 SQL Hint 实战–自定义复合分片策略 小结 Sharding-JDBC中的分片策略有两个维度,分别是: 数据源分片策略(DatabaseShardingStrategy) 表分片策略(TableShardingStrategy) 其中,数据源分片策略表示:数据路由到的物理目标数据源,表分片策略表示数据被路由到的目标表. 特别的,表分片策略是依赖于数据源分片策略的,也就是说要先分库再分表,当然也可以只分表. Shar
-
SpringBoot整合sharding-jdbc实现分库分表与读写分离的示例
目录 一.前言 二.数据库表准备 三.整合 四.docker-compose部署mysql主从 五.本文案例demo源码 一.前言 本文将基于以下环境整合sharding-jdbc实现分库分表与读写分离 springboot2.4.0 mybatis-plus3.4.3.1 mysql5.7主从 https://github.com/apache/shardingsphere 二.数据库表准备 温馨小提示:此sql执行时,如果之前有存在相应库和表会进行自动删除后再创建! DROP DATABAS
-
springboot整合shardingjdbc实现分库分表最简单demo
一.概览 1.1 简介 ShardingSphere-JDBC定位为轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务. 它使用客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架. 适用于任何基于 JDBC 的 ORM 框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template 或直接使用 JDBC. 支持任何第三方的数据库连接池,如:DBCP,
-
SpringBoot整合sharding-jdbc实现自定义分库分表的实践
目录 一.前言 二.简介 1.分片键 2.分片算法 三.程序实现 一.前言 SpringBoot整合sharding-jdbc实现分库分表与读写分离 本文将通过自定义算法来实现定制化的分库分表来扩展相应业务 二.简介 1.分片键 用于数据库/表拆分的关键字段 ex: 用户表根据user_id取模拆分到不同的数据库中 2.分片算法 可参考:https://shardingsphere.apache.org/document/current/cn/user-manual/shardingsphere
-
SpringBoot 如何使用sharding jdbc进行分库分表
目录 基于4.0版本,Springboot2.1 在pom里确保有如下引用 里面我profiles.active了另一个 之后手工把表都建好 写个测试代码 需要注意一个坑 基于4.0版本,Springboot2.1 之前写过一篇使用sharding-jdbc进行分库分表的文章,不过当时的版本还比较早,现在已经不能用了.这一篇是基于最新版来写的. 新版已经变成了shardingsphere了,https://shardingsphere.apache.org/. 有点不同的是,这一篇,我们是采用多
-
利用Sharding-Jdbc进行分库分表的操作代码
目录 1. Sharding-Jdbc介绍 2. Sharding-Jdbc引入使用 3. 配置广播表 4. 配置绑定表 5. 读写分离配置 1. Sharding-Jdbc介绍 https://shardingsphere.apache.org/ sharding-jdbc是一个分布式的关系型数据库中间件 客户端代理模式,不需要搭建服务器,只需要后端数据库即可,有个IDE就行了 定位于轻量级的Java框架,以jar的方式提供服务 可以理解为增强版的jdbc驱动 完全兼容主流的ORM框架 sha
-
Springboot2.x+ShardingSphere实现分库分表的示例代码
之前一篇文章中我们讲了基于Mysql8的读写分离(文末有链接),这次来说说分库分表的实现过程. 概念解析 垂直分片 按照业务拆分的方式称为垂直分片,又称为纵向拆分,它的核心理念是专库专用. 在拆分之前,一个数据库由多个数据表构成,每个表对应着不同的业务.而拆分之后,则是按照业务将表进行归类,分布到不同的数据库中,从而将压力分散至不同的数据库. 下图展示了根据业务需要,将用户表和订单表垂直分片到不同的数据库的方案. 垂直分片往往需要对架构和设计进行调整.通常来讲,是来不及应对互联网业务需求快速变化
-
Java使用Sharding-JDBC分库分表进行操作
目录 主从库搭建 Compose File Master 配置 Slave 配置 主从配置 创建分库分表 Order 1 库 Order 2 库 User 库 Sharding-JDBC 引入 Sharding-JDBC 配置 可选配置 数据源配置 主从复制配置 数据节点配置 Demo 程序 Sharding-JDBC 是无侵入式的 MySQL 分库分表操作工具,所有库表设置仅需要在配置文件中配置即可,无须修改任何代码. 本文写了一个 Demo,使用的是 SpringBoot 框架,通过 Doc
-
Java中ShardingSphere分库分表实战
目录 一. 项目需求 二. 简介sharding-sphere 三. 项目实战 四. 测试 一. 项目需求 我们做项目的时候,数据量比较大,单表千万级别的,需要分库分表,于是在网上搜索这方面的开源框架,最常见的就是mycat,sharding-sphere,最终我选择后者,用它来做分库分表比较容易上手. 二. 简介sharding-sphere 官网地址: https://shardingsphere.apache.org/ ShardingSphere是一套开源的分布式数据库中间件解决方案组成
-
Java基于ShardingSphere实现分库分表的实例详解
目录 一.简介 二.项目使用 1.引入依赖 2.数据库 3.实体类 4.mapper 5.yml配置 6.测试类 7.数据 一.简介 Apache ShardingSphere 是一套开源的分布式数据库解决方案组成的生态圈,它由 JDBC.Proxy 和 Sidecar(规划中)这 3 款既能够独立部署,又支持混合部署配合使用的产品组成. 它们均提供标准化的数据水平扩展.分布式事务和分布式治理等功能,可适用于如 Java 同构.异构语言.云原生等各种多样化的应用场景. Apache Sh
-
springboot jpa分库分表项目实现过程详解
这篇文章主要介绍了springboot jpa分库分表项目实现过程详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 分库分表场景 关系型数据库本身比较容易成为系统瓶颈,单机存储容量.连接数.处理能力都有限.当单表的数据量达到1000W或100G以后,由于查询维度较多,即使添加从库.优化索引,做很多操作时性能仍下降严重.此时就要考虑对其进行切分了,切分的目的就在于减少数据库的负担,缩短查询时间. 分库分表用于应对当前互联网常见的两个场景--大数
-
Spring Boot 集成 Sharding-JDBC + Mybatis-Plus 实现分库分表功能
一. Sharding-jdbc简介 " Sharding-jdbc是开源的数据库操作中间件:定位为轻量级Java框架,在Java的JDBC层提供的额外服务.它使用客户端直连数据库,以jar包形式提供服务,无需额外部署和依赖,可理解为增强版的JDBC驱动,完全兼容JDBC和各种ORM框架. 官方文档地址:https://shardingsphere.apache.org/document/current/cn/overview/ 本文demo实现了分库分表功能.如有错误,欢迎各位在评论中指出.不
-
MySQL分库分表与分区的入门指南
前言 关系型数据库比较容易成为系统瓶颈,单机存储容量.连接数.处理能力都有限,当数据量和并发量起来之后,就必须对数据库进行切分了. 数据切分(sharding)的手段就是分库分表.分库分表有两方面,可能是光分库不分表,也可能是光分表不分库. 数据库分布式的核心内容无非就是数据切分,以及切分后对数据的定位.整合. 为什么要分库分表 分表 单表数据量太大时,会严重影响sql执行的性能.一般单表到达几百万的时候,性能就会相对差一些了,这时就得分表了. 分表就是把一个表的数据放到多个表中,然后查询的时候