Python selenium把歌词评论做成词云图
目录
- 前言
- 本次目的
- 本次用到的模块和包:
- 驱动安装
- 一、下载歌曲评论
- 1.代码实现
- 2.爬取评论运行效果
- 二、制作词云图
- 总结
前言
一首歌热门了,参与评论的人也很多,这时无论好坏评论都来了,没有人控评得话,指不定乱七八糟
但是自己有喜欢看评论,不想影响好心情,想看看精彩评论,看看歌词立意,那怎么办呢?
那本次咱们就把歌词给自动下载保存到电脑上,做成词云图给它分析分析…
本次目的
用selenium自动把歌词评论下载下来,做成好看的词云图
本次用到的模块和包:
re # 正则表达式 内置模块
selenium # 实现浏览器自动操作的
jieba # 中文分词库
wordcloud # 词云图库
imageio # 图像模块
time # 内置模块
需要安装的模块安装方法:
以 selenium 为例,直接pip install selenium
下载速度慢就用镜像源下载
驱动安装
要实现浏览器自动操作,咱们得安装一个浏览器驱动。
网址我就不发了,网上直接搜谷歌浏览器驱动就可以找到,实在找不到的话私聊我
建议用谷歌浏览器,以谷歌浏览器为例,首先看一下咱们浏览器的的版本。
浏览器右上角三个点,点开后点击设置。

然后点击关于Chrome ,右边的那一串数字就是版本号了。
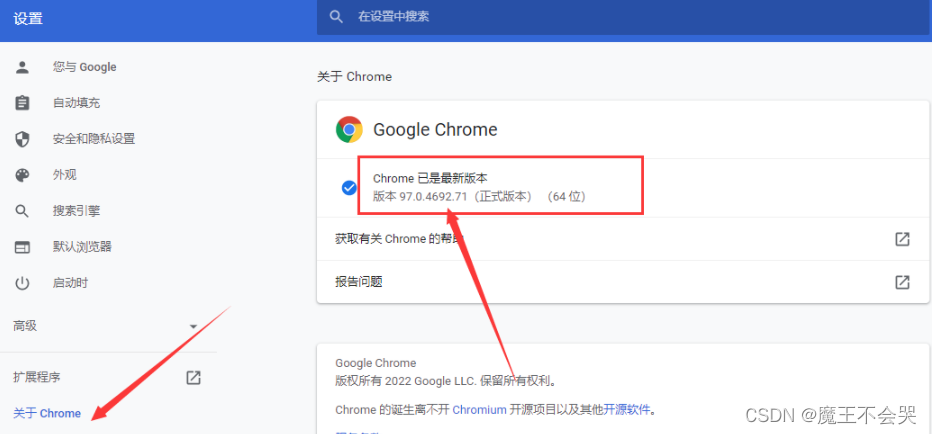
然后找到跟你的版本号相同的版本下载,没有相同的就下载最相近的版本也可以。
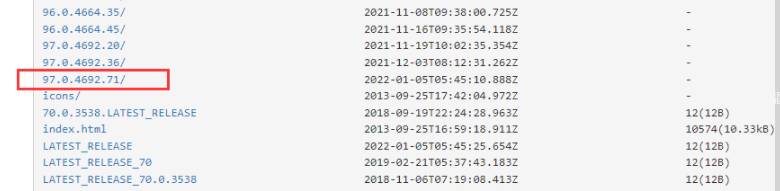
你的代码放到一起,跟代码放一起的话,缺点是你每次要使用,没保存的话都得去下载。
还有一种办法是直接放到你的python目录,这种的优点是一次搞定可以用很多次。缺点是每次版本更新,你还是得去下载新的。
我反正每次都是去下载新的,又不是经常用。
一、下载歌曲评论
1.代码实现
首先导入一下模块
模块是必须要导入的东西哦,没有导入的话,运行时即使你代码正确也是会报错的哦~
from selenium import webdriver import re import time
Python文件名或者包名不要命名为selenium,会导致无法导入。
webdriver可以认为是浏览器的驱动器,要驱动浏览器必须用到webdriver,支持多种浏览器。
创建一个浏览器对象
driver = webdriver.Chrome()
请求页面
driver.get('https://music.163.com/#/song?id=569213220')
driver.implicitly_wait(10) # 隐式等待 浏览器渲染页面 智能化等待
driver.maximize_window() # 最大化浏览器
driver.switch_to.frame(0)
# document.documentElement.scrollTop 指定页面的高度 # document.documentElement.scrollHeight 获取页面的高度 # document.documentElement.scrollTop 指定页面的高度 # document.documentElement.scrollHeight 获取页面的高度 js = 'document.documentElement.scrollTop = document.documentElement.scrollHeight' driver.execute_script(js)
获取评论数据/保存/点击下一页
for click in range(10):
divs = driver.find_elements_by_css_selector('.itm')
for div in divs:
cnt = div.find_element_by_css_selector('.cnt.f-brk').text
cnt = cnt.replace('\n', ' ') # 替换换行符
cnt = re.findall(':(.*)', cnt)[0]
with open('contend.txt', mode='a', encoding='utf-8') as f:
f.write(cnt + '\n')
# 找到下一页标签点击
driver.find_element_by_css_selector('.znxt').click()
time.sleep(1)
input('程序阻塞.')
最后退出浏览器
driver.quit()
2.爬取评论运行效果
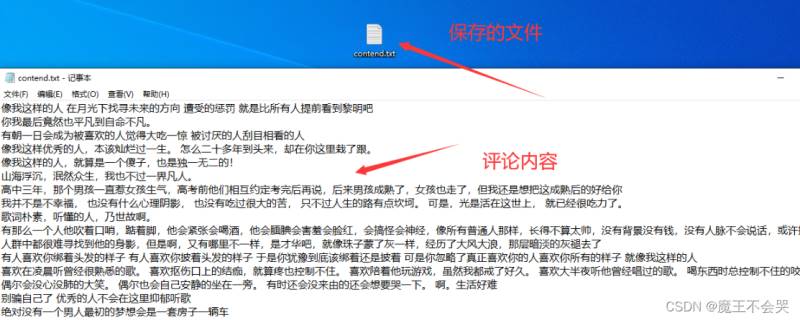
二、制作词云图
代码实现
绘制词云图/大小设置,词云图图案可以自己去挑选喜欢的哦
import jieba # 中文分词库
import wordcloud # 词云图库
import imageio # 图像模块
file = open('contend.txt', mode='r', encoding='utf-8')
txt = file.read()
# print(txt)
txt_list = jieba.lcut(txt)
print('分词结果',txt_list)
string = ' '.join(txt_list)
print('合并分词:', string)
"""制作词云图"""
# 读取图像
img = imageio.imread('音乐.png')
# 设置词云图
wc = wordcloud.WordCloud(
width=1000, # 词云图的宽
height=700, # 图片的高
background_color= 'black', # 词云图背景颜色
font_path='msyh.ttc', # 词云字体, 微软雅黑, 系统自带
scale=10, # 字体大小
# mask=img,
stopwords=set([line.strip() for line in open('cn_stopwords.txt', mode='r',
encoding='utf-8').readlines()])
)
print('正在绘制词云图')
wc.generate(string)
wc.to_file('output2.png')
print('词云图制作成功...')
效果展示

总结
到此这篇关于Python selenium把歌词评论做成词云图的文章就介绍到这了,更多相关Python selenium词云图内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python控制浏览器自动下载歌词评论并生成词云图
目录 一.前言 二.准备工作 1.需要用的模块 2.驱动安装 三.下载歌词 四.词云图 一.前言 一首歌热门了,参与评论的人也很多,那我们有时候想看看评论,也只能看看热门的评论,大部分人都说的什么,咱也不知道呀~ 那本次咱们就把歌词给自动下载保存到电脑上,做成词云图给它分析分析… 二.准备工作 1.需要用的模块 本次用到的模块和包: re # 正则表达式 内置模块 selenium # 实现浏览器自动操作的 jieba # 中文分词库 wordcloud # 词云图库 imageio
-
Python selenium把歌词评论做成词云图
目录 前言 本次目的 本次用到的模块和包: 驱动安装 一.下载歌曲评论 1.代码实现 2.爬取评论运行效果 二.制作词云图 总结 前言 一首歌热门了,参与评论的人也很多,这时无论好坏评论都来了,没有人控评得话,指不定乱七八糟 但是自己有喜欢看评论,不想影响好心情,想看看精彩评论,看看歌词立意,那怎么办呢? 那本次咱们就把歌词给自动下载保存到电脑上,做成词云图给它分析分析… 本次目的 用selenium自动把歌词评论下载下来,做成好看的词云图 本次用到的模块和包: re # 正则表达式 内置模块
-
Python采集电视剧《开端》弹幕做成词云图
目录 知识点介绍 环境介绍 网站分析 完整爬虫代码实现 结果展示 总结 知识点介绍 爬虫基本思路流程 requests模块的使用 pandas保存表格数据 pyecharts做词云图可视化 环境介绍 python 3.8 pycharm requests >>> pip install requests pyecharts >>> pip install pyecharts 网站分析 打开X讯视频的网页,点开<开端>,播放视频,弹幕随之出现再屏幕之上. 首先
-
Python爬取网易云歌曲评论实现词云图
目录 前言 环境使用 代码实现 先是安装.导入所需模块 1. 创建一个浏览器对象 2. 执行自动化 下拉页面, 直接下拉到页面的底部 3.解析数据 保存数据 翻页 保存为txt文件 运行代码得到结果 再做个词云 导入相关模块 读取文件数据 词云图 分词<中文(词语)> 基于结果 合并 创建词云图 最后效果 前言 emmmm 没什么说的,想说的都在代码里 环境使用 Python 3.8 解释器 3.10 Pycharm 2021.2 专业版 selenium 3.141.0 本次要用到selen
-
利用Python爬取微博数据生成词云图片实例代码
前言 在很早之前写过一篇怎么利用微博数据制作词云图片出来,之前的写得不完整,而且只能使用自己的数据,现在重新整理了一下,任何的微博数据都可以制作出来,一年一度的虐汪节,是继续蹲在角落默默吃狗粮还是主动出击告别单身汪加入散狗粮的行列就看你啦,七夕送什么才有心意,程序猿可以试试用一种特别的方式来表达你对女神的心意.有一个创意是把她过往发的微博整理后用词云展示出来.本文教你怎么用Python快速创建出有心意词云,即使是Python小白也能分分钟做出来.下面话不多说了,来一起看看详细的介绍吧. 准备工作
-
Python通过文本和图片生成词云图
使用现有的txt文本和图片,就可以用wordcloud包生成词云图.大致步骤是: 1.读取txt文本并简单处理: 2.读取图片,以用作背景: 3.生成词云对象,保存为文件. 需要用到3个库:jieba(用于分割文本为词语).imageio(用于读取图片).wordcloud(功能核心,用于生成词云). 我用简历和我的照片,生成了一个词云图: 代码如下: import jieba import imageio import wordcloud # 读取txt文本 with open('resume
-
Python爬取哆啦A梦-伴我同行2豆瓣影评并生成词云图
一.前言 通过这篇文章,你将会收货: ① 豆瓣电影数据的爬取: ② 手把手教你学会词云图的绘制: 二.豆瓣爬虫步骤 当然,豆瓣上面有很多其他的数据,值得我们爬取后做分析.但是本文我们仅仅爬取评论信息. 待爬取网址: https://movie.douban.com/subject/34913671/comments?status=P 由于只有一个字段,我们直接使用re正则表达式,解决该问题. 那些爬虫小白看过来,这又是一个你们练手的好机会. 下面直接为大家讲述爬虫步骤: # 1. 导入相关库,用
-
Python实现爬取某站视频弹幕并绘制词云图
目录 前言 爬取弹幕 爬虫基本思路流程 导入模块 代码 制作词云图 导入模块 读取弹幕数据 前言 [课 题]: Python爬取某站视频弹幕或者腾讯视频弹幕,绘制词云图 [知识点]: 1. 爬虫基本流程 2. 正则 3. requests >>> pip install requests 4. jieba >>> pip install jieba 5. imageio >>> pip install imageio 6. wordcloud >
-
Python爬取英雄联盟MSI直播间弹幕并生成词云图
一.环境准备 安装相关第三方库 pip install jieba pip install wordcloud 二.数据准备 爬取对象:2021年5月23号,RNG夺冠直播间的弹幕信息 爬取对象路径: 方式1.根据开发者工具(F12),获取请求url.请求头.cookie等信息: 方式2:根据直播地址url,前+字符i 我们这里演示的是,采用方式2. 三.代码如下 import requests, re import jieba, wordcloud """ # 以下是练习代
-
用Python爬取QQ音乐评论并制成词云图的实例
环境:Ubuntu16.4 python版本:3.6.4 库:wordcloud 这次我们要讲的是爬取QQ音乐的评论并制成云词图,我们这里拿周杰伦的等你下课来举例. 第一步:获取评论 我们先打开QQ音乐,搜索周杰伦的<等你下课>,直接拉到底部,发现有5000多页的评论. 这时候我们要研究的就是怎样获取每页的评论,这时候我们可以先按下F12,选择NetWork,我们可以先点击小红点清空数据,然后再点击一次,开始监控,然后点击下一页,看每次获取评论的时候访问获取的是哪几条数据.最后我们就能看到下图