Python爬虫程序架构和运行流程原理解析
1 前言
Python开发网络爬虫获取网页数据的基本流程为:
发起请求
通过URL向服务器发起request请求,请求可以包含额外的header信息。
获取响应内容
服务器正常响应,将会收到一个response,即为所请求的网页内容,或许包含HTML,Json字符串或者二进制的数据(视频、图片)等。
解析内容
如果是HTML代码,则可以使用网页解析器进行解析,如果是Json数据,则可以转换成Json对象进行解析,如果是二进制的数据,则可以保存到文件做进一步处理。
保存数据
可以保存到本地文件,也可以保存到数据库(MySQL,Redis,MongoDB等)。

2 爬虫程序架构及运行流程
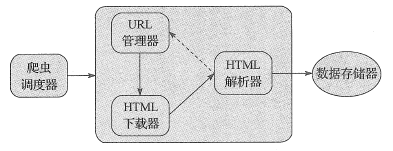
网络爬虫程序框架主要包括以下五大模块:
- 爬虫调度器
- URL管理器
- HTML下载器
- HTML解析器
- 数据存储器
五大模块功能如下所示:
- 爬虫调度器:主要负责统筹其它四个模块的协调工作。
- URL管理器:负责管理URL链接,维护已经爬取的URL集合和未爬取的URL集合,提供获取新URL链接的接口。
- HTML下载器:用于从URL管理器中获取未爬取的URL链接并下载HTML网页。
- HTML解析器:用于从HTML下载器中获取已经下载的HTML网页,并从中解析出新的URL链接交给URL管理器,解析出有效数据交给数据存储器。
- 数据存储器:用于将HTML解析器解析出来的数据通过文件或者数据库的形式存储起来。
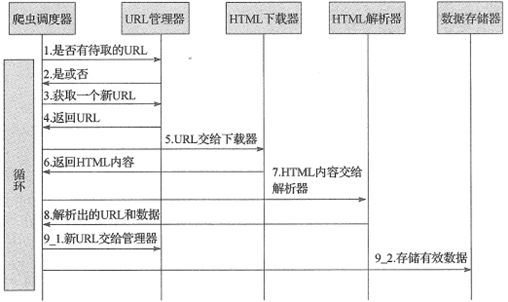
网络爬虫程序框架的动态运行流程如下所示:
3 小结
本文简要介绍了Python开发网络爬虫的程序框架,将网络爬虫运行流程按照具体功能划分为不同模块,以便各司其职、协同运作。搭建好网络爬虫框架后,能够有效地提高我们开发网络爬虫项目的效率,避免一些重复造车轮的工作。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
基于Python爬取爱奇艺资源过程解析
像iqiyi这种视频网站,现在下载视频都需要下载相应的客户端.那么如何不用下载客户端,直接下载非vip视频? 选择你想要爬取的内容 该安装的程序以及运行环境都配置好 下面这段代码就是我在爱奇艺里搜素"英文名",然后出来的视频,共有20页,那么我们便从第一页开始,解析网页,然后分析 分析每一页网址,找出规律就可以直接得到所有页面 然后根据每一个视频的URL的标签,如'class' 'div' 'href'......通过bs4库进行爬取 而其他的信息则是直接循环所爬取到的URL,在每一个
-
Python通过正则库爬取淘宝商品信息代码实例
使用正则库爬取淘宝商品的商品信息,首先我们需要确定想要爬取的对象 我们在淘宝里搜索"python",出来的结果 从url连接中可以得到搜索商品的关键字是"q=",所以我们要用的起始url为:https://s.taobao.com/search?q=python 然后翻页,经过对比发现,翻页后,变化的关键字是s,每次翻页,s便以44的倍数增长(可以数一下每页显示的商品数量,刚好是44) 所以可以根据关键字"s=",来设置爬取的深度(爬取多少页)
-
python爬虫开发之Beautiful Soup模块从安装到详细使用方法与实例
python爬虫模块Beautiful Soup简介 简单来说,Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据.官方解释如下: Beautiful Soup提供一些简单的.python式的函数用来处理导航.搜索.修改分析树等功能.它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简单,所以不需要多少代码就可以写出一个完整的应用程序.Beautiful Soup自动将输入文档转换为Unicode编码,输出文档转换为utf-8编码.你不需要考虑编码方式,除非
-
Python爬虫实现模拟点击动态页面
动态页面的模拟点击: 以斗鱼直播为例:http://www.douyu.com/directory/all 爬取每页的房间名.直播类型.主播名称.在线人数等数据,然后模拟点击下一页,继续爬取 代码如下 #!/usr/bin/python3 # -*- coding:utf-8 -*- __author__ = 'mayi' """ 动态页面的模拟点击: 模拟点击斗鱼直播:http://www.douyu.com/directory/all 爬取每页房间名.直播类型.主播名称.
-
Python基于requests库爬取网站信息
requests库是一个简介且简单的处理HTTP请求的第三方库 get()是获取网页最常用的方式,其基本使用方式如下 使用requests库获取HTML页面并将其转换成字符串后,需要进一步解析HTML页面格式,这里我们常用的就是beautifulsoup4库,用于解析和处理HTML和XML 下面这段代码便是爬取百度的信息并简单输出百度的界面信息 import requests from bs4 import BeautifulSoup r=requests.get('http://www.bai
-
Python网络爬虫信息提取mooc代码实例
实例一--爬取页面 import requests url="https//itemjd.com/2646846.html" try: r=requests.get(url) r.raise_for_status() r.encoding=r.apparent_encoding print(r.text[:1000]) except: print("爬取失败") 正常页面爬取 实例二--爬取页面 import requests url="https://w
-
Python使用requests xpath 并开启多线程爬取西刺代理ip实例
我就废话不多说啦,大家还是直接看代码吧! import requests,random from lxml import etree import threading import time angents = [ "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; .NET CLR 1.1.4322; .NET CLR 2.0.50727)", "Mozilla/4.0 (compati
-
Python爬虫程序架构和运行流程原理解析
1 前言 Python开发网络爬虫获取网页数据的基本流程为: 发起请求 通过URL向服务器发起request请求,请求可以包含额外的header信息. 获取响应内容 服务器正常响应,将会收到一个response,即为所请求的网页内容,或许包含HTML,Json字符串或者二进制的数据(视频.图片)等. 解析内容 如果是HTML代码,则可以使用网页解析器进行解析,如果是Json数据,则可以转换成Json对象进行解析,如果是二进制的数据,则可以保存到文件做进一步处理. 保存数据 可以保存到本地文件,也
-
Python爬虫程序中使用生产者与消费者模式时进程过早退出的问题
之前写爬虫程序的时候,采用生产者和消费者的模式,利用Queue作为生产者进程和消费者进程之间的同步队列. 执行程序时,总是秒退,加了断点也无法中断,加打印也无法输出,我知道肯定是进程退出了,但还是百思不得解,为什么会这么快就退出. 一开始以为是我的进程代码写的有问题,在某个地方崩溃导致程序提前退出,排查了一遍又一遍,并没有发现什么明显的问题,后来走读代码,看到主模块中消费者和生产者进程的启动后,发现了问题,原因是我通过start()方法启动进程后,使用join()的方式有问题.消费者进程必须执行
-

一个简单的python爬虫程序 爬取豆瓣热度Top100以内的电影信息
概述 这是一个简单的python爬虫程序,仅用作技术学习与交流,主要是通过一个简单的实际案例来对网络爬虫有个基础的认识. 什么是网络爬虫 简单的讲,网络爬虫就是模拟人访问web站点的行为来获取有价值的数据.专业的解释:百度百科 分析爬虫需求 确定目标 爬取豆瓣热度在Top100以内的电影的一些信息,包括电影的名称.豆瓣评分.导演.编剧.主演.类型.制片国家/地区.语言.上映日期.片长.IMDb链接等信息. 分析目标 1.借助工具分析目标网页 首先,我们打开豆瓣电影·热门电影,会发现页面总共20部
-
使用Python检测文章抄袭及去重算法原理解析
在互联网出现之前,"抄"很不方便,一是"源"少,而是发布渠道少:而在互联网出现之后,"抄"变得很简单,铺天盖地的"源"源源不断,发布渠道也数不胜数,博客论坛甚至是自建网站,而爬虫还可以让"抄"完全自动化不费劲.这就导致了互联网上的"文章"重复性很高.这里的"文章"只新闻.博客等文字占据绝大部分内容的网页. 中文新闻网站的"转载"(其实就是抄)现象非
-
Python 中 -m 的典型用法、原理解析与发展演变
在命令行中使用 Python 时,它可以接收大约 20 个选项(option),语法格式如下: python [-bBdEhiIOqsSuvVWx?] [-c command | -m module-name | script | - ] [args] 本文想要聊聊比较特殊的"-m"选项: 关于它的典型用法.原理解析与发展演变的过程. 首先,让我们用"--help"来看看它的解释: -m mod run library module as a script (ter
-
python中的函数递归和迭代原理解析
这篇文章主要介绍了python中的函数递归和迭代原理解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 一.递归 1.递归的介绍 什么是递归? 程序调用自身的编程技巧称为递归( recursion).递归做为一种算法在程序设计语言中广泛应用. 一个过程或函数在其定义或说明中有直接或间接调用自身的一种方法,它通常把一个大型复杂的问题层层转化为一个与原问题相似的规模较小的问题来求解,递归策略只需少量的程序就可描述出解题过程所需要的多次重复计算,大大
-
Python While循环语句实例演示及原理解析
这篇文章主要介绍了Python While循环语句实例演示及原理解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 Python 编程中 while 语句用于循环执行程序,即在某条件下,循环执行某段程序,以处理需要重复处理的相同任务.其基本形式为: while 判断条件: 执行语句-- 执行语句可以是单个语句或语句块.判断条件可以是任何表达式,任何非零.或非空(null)的值均为true. 当判断条件假false时,循环结束. 执行流程图如下:
-
python爬虫实战steam加密逆向RSA登录解析
目录 采集目标 工具准备 项目思路解析 采集目标 网址:steam 工具准备 开发工具:pycharm 开发环境:python3.7, Windows10 使用工具包:requests 项目思路解析 访问登录页面重登录页面获取登录接口, 先输入错误的账户密码去测试登录接口. 获取到登录的接口地址,请求方法是post请求,找到需要传递的参数,可以看到密码数据是加密的第一个数据是时间戳密码加密字段应该用的base64,rsatimestamp字段目前还不清楚是什么,其他的都是固定数据. 找到pass
-
微信小程序button标签open-type属性原理解析
这篇文章主要介绍了微信小程序button标签open-type属性原理解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 open-type (微信开放能力):合法值中的其中之一: getUserInfo说明:引导用户授权 而获取用户信息,可以从bindgetuserinfo回调中获取到用户信息 而按钮的bindgetuserinfo属性 说明:用户点击该按钮时,会返回获取到的用户信息,回调的detail数据与wx.getUserInfo返回的
-
python爬虫模块URL管理器模块用法解析
这篇文章主要介绍了python爬虫模块URL管理器模块用法解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 URL管理器模块 一般是用来维护爬取的url和未爬取的url已经新添加的url的,如果队列中已经存在了当前爬取的url了就不需要再重复爬取了,另外防止造成一个死循环.举个例子 我爬www.baidu.com 其中我抓取的列表中有music.baidu.om,然后我再继续抓取该页面的所有链接,但是其中含有www.baidu.com,可以想