MySql中流程控制函数/统计函数/分组查询用法解析
路漫漫其修远兮,吾将上下而求索,又到了周末,我继续带各位看官学习回顾Mysql知识。
上次说到了流程控制函数,那就从流程控制函数来继续学习吧!
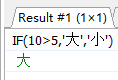
#五.流程控制函数 #1.if函数:if else的效果 IF(条件表达式,成立返回1,不成立返回2) #与Java三元运算相同 SELECT IF(10>5,'大','小');
SELECT last_name,commission_pct,IF(commission_pct IS NULL,'没奖金呵呵','有奖金嘻嘻') AS 备注 FROM employees;

#2.CASE函数的使用一: swirch case的效果【等值判断】
回顾:switch(变量或表达式){
case 常量1:语句1;break;
...
default:语句n;break;
}
mysql中
case 要判断的字段或表达式或变量
when 常量1 then 要显示的值1或者语句1;[语句要加分号,值不用加]
when 常量2 then 要显示的值2或者语句2;
...
slse要显示的值n或者语句n;[默认值]
end[结尾]
case在SELECT后面相当于表达式用,后面不能放语句,只能是值.
在后续的学习中,存储过程与函数内就可以单独,用不搭配SLECT,就用语句.
先是表达式的操作
案例:查询员工的工资,要求
部门号=30,显示的工资为1.1倍
部门号=40,显示的工资为1.2倍
部门号=50,显示的工资为1.3倍
其他部门,显示的工资为原工资
SELECT salary 原始工资,department_id, CASE department_id WHEN 30 THEN salary*1.1 WHEN 40 THEN salary*1.2 WHEN 50 THEN salary*1.3 ELSE salary END AS 新工资 FROM employees;

#2.CASE函数的使用二:类是于多重IF【区间判断】
回顾Java中:if(条件1){
语句1;
}else if(条件2){
语句2;
}...
else{
语句n;
}
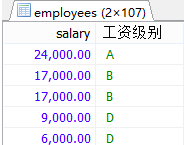
mysql中: case when 条件1 then 要显示的值1或者语句[语句后面要加分号;] when 条件2 then 要显示的值2或者语句[语句后面要加分号;] ... else 要显示的值n或语句n end 案例:查询员工的工资的情况 如果工资>20000,显示A级别 如果工资>15000,显示B级别 如果工资>10000,显示C级别 否则,显示D级别
==============流程函数到此结束,要想熟练运用还需要勤加练习。===============
提供几道习题供读者试试手!
#计算有几种工资。 SELECT COUNT(DISTINCT salary), COUNT(salary) FROM employees;

#5.count 函数的详细介绍 SELECT COUNT(salary) FROM employees;

#COUNT(统计所有列) SELECT COUNT(*) FROM employees;
#把表的行生成一个列每一列都是1。统计1的总数。count里面可以用任意常量值。 SELECT COUNT(1) FROM employees;
#考虑到效率问题: #5.5之前都是MYISAM 下COUNT(*)最高,计数器直接返回 #5.5之后默认都是INNODB下COUNT()与COUNT(1)都差不多, 比COUNT(字段)效率高,如果是字段要判断字段是否为NULL。
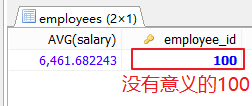
#6.和分组函数一同查询的字段有限制 SELECT AVG(salary),employee_id FROM employees;
#1.查询公司员工工资的最大值,最小值,平均值,总和。 SELECT MAX(salary),MIN(salary),AVG(salary),SUM(salary) FROM employees;

SELECT MAX(salary) AS 最大值,MIN(salary) AS 最小值, ROUND(AVG(salary)) AS 最小值,SUM(salary) AS总和 FROM employees;

#2.查询员工表中最大入职时间和最小入职时间的相差天数。
#DATEDIFF计算天数。DATEIFF(参数1-参数2)
SELECT DATEDIFF(NOW(),('1995-1-1'));
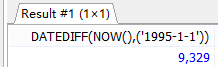
SELECT DATEDIFF(MAX(hiredate),MIN(hiredate)) AS DIFFRENCE FROM employees;
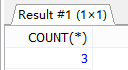
#3.查询部门编号为90的员工个数。 SELECT COUNT(*) AS个数 FROM employees WHERE department_id=90;
#进阶5.分组查询GROUP BY子句语法。 可以使用GROUP BY子句将表中的数据分成若干组。 语法: SELECT 分组函数,列(要求出现在GROUP BY的后面) FROM 表 【WHERE筛选条件】 GROP BY 分组的列表 【ORDER BY 子句】 注意: 查询列表必须特殊,要求是分组函数和GROUP BY后出现的字段 特点: 1.分组查询中的筛选条件分为两类

2.GROUP BY 子句支持单个字段分组,多个字段分组(多个字段之间用逗号隔开没有顺序要求) 也支持表达式或函数分组(用的较少) 3.也可以添加排序(排序放在整个分组查询的最后)
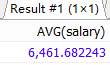
#引入:查询每个部门的平均工资,保留两位小数。 SELECT ROUND(AVG(salary),2) AS 平均工资 FROM employees;
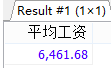
#简单的分组查询,添加分组前的筛选WHERE #案例1:查询每个工种的最高工资。 SELECT MAX(salary) AS 最高工资,job_id AS 工种编号 FROM employees GROUP BY job_id;
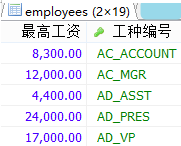
#案例2:查询每个位置上的部门个数。 SELECT COUNT(*) AS 总数,location_id FROM departments GROUP BY location_id;
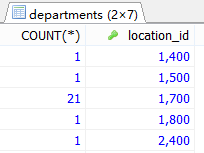
#添加筛选条件 #查询邮箱中包含a字符的,平均工资保留两位小数,每个部门的平均工资 SELECT email,ROUND(AVG(salary),2),department_id FROM employees WHERE email LIKE '%a%' GROUP BY department_id;

#案例2:查询每个领导手下员工有奖金的的最高工资 SELECT MAX(salary),manager_id FROM employees WHERE commission_pct IS NOT NULL GROUP BY manager_id;

添加复杂的筛选,添加分组后的筛选HAVING #案例1:查询哪个部门的员工个数>2 #①查询每个部门的员工个数 SELECT COUNT(*),department_id FROM employees GROUP BY department_id;
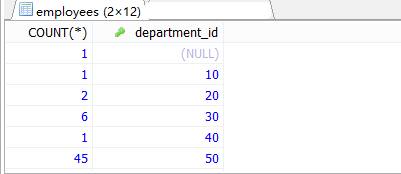
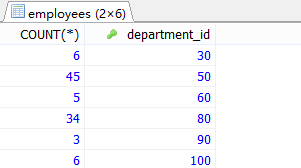
#②根据①的结果,查询哪个部门的员工个数>2 SELECT COUNT(*) AS 总数,department_id AS 部门编号 FROM employees GROUP BY department_id HAVING COUNT(*)>2;
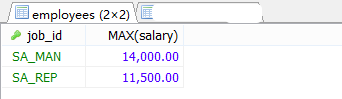
#案例2.查询每个工种有奖金的员工的最高工资>12000的工种编号和最高工资。 #①查询每个工种有奖金的员工的最高工资。 #原始表能筛选的就放在FROM 后面用WHERE。
SELECT job_id AS 员工编号,MAX(salary) AS 最高工资 FROM employees WHERE commission_pct IS NOT NULL GROUP BY job_id;
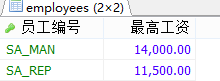
#②根据①结果继续筛选,最高工资>12000。 SELECT job_id AS 员工编号,MAX(salary) AS 最高工资 FROM employees WHERE commission_pct IS NOT NULL GROUP BY job_id HAVING MAX(salary)>12000;
#案例3.查询领导编号>102的每个领导手下的最低工资>5000的领导编号是哪个,以及其最低工资。 #①查询领导编号>102的每个领导手下的最低工资 SELECT MIN(salary) AS 最低工资,manager_id AS 领导编号 FROM employees WHERE manager_id > 102 GROUP BY manager_id;
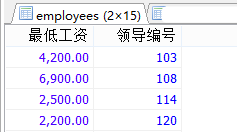
#②最低工资大于5000的。 SELECT MIN(salary) AS 最低工资,manager_id AS 领导编号 FROM employees WHERE manager_id > 102 GROUP BY manager_id HAVING 最低工资 > 5000;

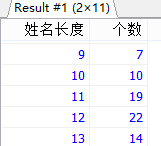
#案例:按员工姓名的长度分组,查询每一组的员工个数,筛选员工个数>5的有哪些 #MYSQL内GROUP BY与HAVING后面支持别名,WHERE不支持别名。但ORACLE数据库的GROUP BY与HAVING是不支持别名的。 SELECT LENGTH(CONCAT(last_name,first_name)) AS 姓名长度, COUNT(*) AS 个数 FROM employees GROUP BY 姓名长度 HAVING 姓名长度 > 5;
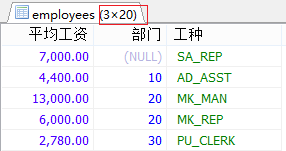
#按多个字段分组 #案例:查询每个部门工种的员工的平均工资(保留两位小数)。 SELECT ROUND(AVG(salary),2) AS 平均工资,department_id AS 部门,job_id AS 工种 FROM employees GROUP BY 部门,工种;
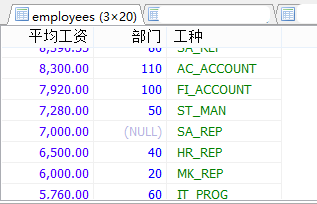
#添加排序 #案例:查询每个部门每个工种的员工的平均工资,并且按平均工资的高低显示。 SELECT ROUND(AVG(salary),2) AS 平均工资,department_id AS 部门,job_id AS 工种 FROM employees GROUP BY 工种,部门 ORDER BY 平均工资 DESC;
#案例:查询部门不能为空的,每个部门每个工种的员工的平均工资,并且按平均工资的高低显示。 SELECT ROUND(AVG(salary),2) AS 平均工资,department_id AS 部门,job_id AS 工种 FROM employees WHERE department_id IS NOT NULL GROUP BY 工种,部门 ORDER BY 平均工资 DESC;
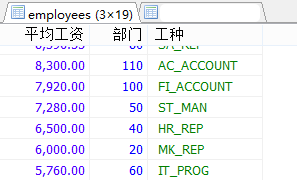
#案例:查询部门不能为空的,每个部门每个工种的员工的平均工资高于10000的,并且按平均工资的高低显示。 SELECT ROUND(AVG(salary),2) AS 平均工资,department_id AS 部门,job_id AS 工种 FROM employees WHERE department_id IS NOT NULL GROUP BY 工种,部门 HAVING 平均工资 > 10000 ORDER BY 平均工资 DESC;
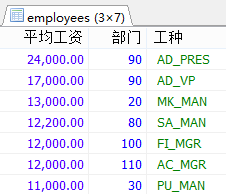
加强练习:
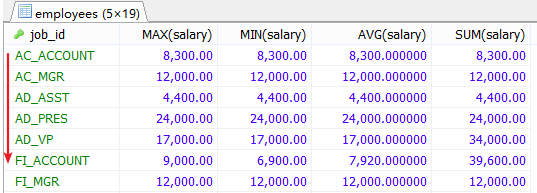
#1.查询各job_id的员工工资的最大值,最小值,平均值,总和,并按job_id升序。 SELECT job_id,MAX(salary),MIN(salary),AVG(salary),SUM(salary) FROM employees GROUP BY job_id ORDER BY job_id ASC;
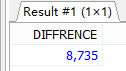
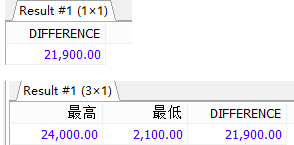
#2.查询员工最高工资和最低工资的差距(DIFFERENCE)。 SELECT MAX(salary) - MIN(salary) AS DIFFERENCE FROM employees; ======================================================= SELECT MAX(salary) AS 最高,MIN(salary) AS 最低,MAX(salary)-MIN(salary) AS DIFFERENCE FROM employees;
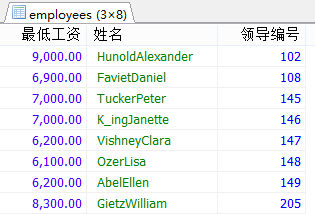
#3.查询各个管理者手下员工的最低工资,其中最低工资不能低于6000,没有管理者的员工不能计算在内。 SELECT MIN(salary),CONCAT(last_name,first_name),manager_id FROM employees WHERE manager_id IS NOT NULL GROUP BY manager_id HAVING MIN(salary)>6000;
到此结束,MySql的统计,分组查询到此结束。如果没有感觉的看官可以自己手动练习一下。
夏天的太阳总是那么亮的刺眼,但多沐浴一下阳光也补钙,想不到吧!o(^▽^)o
到此这篇关于MySql中流程控制函数/统计函数/分组查询用法解析的文章就介绍到这了,更多相关MySql 流程控制函数 统计函数 分组查询内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
MySQL统计函数GROUP_CONCAT使用陷阱分析
本文实例分析了MySQL统计函数GROUP_CONCAT使用中的陷阱.分享给大家供大家参考,具体如下: 最近在用MySQL做一些数据的预处理,经常会用到group_concat函数,比如类似下面一条语句 复制代码 代码如下: mysql>select aid,group_concat(bid) from tbl group by aid limit 1; sql语句比较简单,按照aid分组,并且把相应的bid用逗号串起来.这样的句子大家可能都用过,也可能不会出问题,但是如果bid非常多的话,你就
-

MySQL分组查询Group By实现原理详解
由于GROUP BY 实际上也同样会进行排序操作,而且与ORDER BY 相比,GROUP BY 主要只是多了排序之后的分组操作.当然,如果在分组的时候还使用了其他的一些聚合函数,那么还需要一些聚合函数的计算.所以,在GROUP BY 的实现过程中,与 ORDER BY 一样也可以利用到索引. 在MySQL 中,GROUP BY 的实现同样有多种(三种)方式,其中有两种方式会利用现有的索引信息来完成 GROUP BY,另外一种为完全无法使用索引的场景下使用.下面我们分别针对这三种实现方式做一个分
-
详解MySQL中的分组查询与连接查询语句
分组查询 group by group by 属性名 [having 条件表达式][ with rollup] "属性名 "指按照该字段值进行分组:"having 条件表达式 "用来限制分组后的显示,满足条件的结果将被显示:with rollup 将会在所有记录的最后加上一条记录,该记录是上面所有记录的总和. 1)单独使用 group by 单独使用,查询结果只显示一个分组的一条记录. 实例: select * from employee group by sex;
-
MySql中流程控制函数/统计函数/分组查询用法解析
路漫漫其修远兮,吾将上下而求索,又到了周末,我继续带各位看官学习回顾Mysql知识. 上次说到了流程控制函数,那就从流程控制函数来继续学习吧! #五.流程控制函数 #1.if函数:if else的效果 IF(条件表达式,成立返回1,不成立返回2) #与Java三元运算相同 SELECT IF(10>5,'大','小'); SELECT last_name,commission_pct,IF(commission_pct IS NULL,'没奖金呵呵','有奖金嘻嘻') AS 备注 FROM em
-
mysql中json类型字段的基本用法实例
目录 前言 基本环境 JSON类型字段常用操作 插入JSON类型数据 查询JSON类型数据 更新JSON类型数据中的特定字段 匹配JSON类型数据中的特定字段 结语 前言 mysql从5.7.8版本开始原生支持了JSON类型数据,同时可以对JSON类型字段中的特定的值进行查询和更新等操作,通过增加JSON类型的属性可以大大的提高我们在mysql表中存储的数据的拓展性,无需每次新增字段时都进行表结构的调整,下面我们不深入讲解底层的实现原理,我们主要来梳理一下我们在日常工作中使用实践 基本环境 my
-
mysql中使用instr进行模糊查询方法介绍
在mysql中使用内部函数instr,可代替传统的like方式查询,并且速度更快. instr 函数,第一个参数是字段,第二个参数是要查询的串,返回串的位置,第一个是1,如果没找到就是0. 例如,查询字段name中带"军"的名字,传统的方法是: select name from 用户表 where name like `%军%'; 用instr的方法: select name from 用户表 where instr('name','军'); 或: select name from 用
-
浅谈mysql中多表不关联查询的实现方法
大家在使用MySQL查询时正常是直接一个表的查询,要不然也就是多表的关联查询,使用到了左联结(left join).右联结(right join).内联结(inner join).外联结(outer join).这种都是两个表之间有一定关联,也就是我们常常说的有一个外键对应关系,可以使用到 a.id = b.aId这种语句去写的关系了.这种是大家常常使用的,可是有时候我们会需要去同时查询两个或者是多个表的时候,这些表又是没有互相关联的,比如要查user表和user_history表中的某一些数据
-
mysql多个left join连接查询用法分析
本文实例讲述了mysql多个left join连接查询用法.分享给大家供大家参考,具体如下: mysql查询时需要连接多个表时,比如查询订单的商品表,需要查询商品的其他信息,其他信息不在订单的商品表,需要连接其他库的表,但是连接的条件基本都是商品ID就可以了,先给一个错误语句(查询之间的嵌套,效率很低): SELECT A.order_id, A.wid, A.work_name, A.supply_price, A.sell_price, A.total_num, A.sell_profit,
-
Mysql中replace与replace into的用法讲解
Mysql replace与replace into都是经常会用到的功能:replace其实是做了一次update操作,而不是先delete再insert:而replace into其实与insert into很相像,但对于replace into,假如表中的一个旧记录与一个用于PRIMARY KEY或一个UNIQUE索引的新记录具有相同的值,则在新记录被插入之前,旧记录被删除. replace是mysql 里面处理字符串比较常用的函数,可以替换字符串中的内容.类似的处理字符串的还有trim截取
-
MySQL中order by排序语句的原理解析
order by 是怎么工作的? 表定义 CREATE TABLE `t1` ( `id` int(11) NOT NULL, `city` varchar(16) NOT NULL, `name` varchar(16) NOT NULL, `age` int(11) NOT NULL, `addr` varchar(128) DEFAULT NULL, PRIMARY KEY (`id`), KEY `city` (`city`)) ENGINE=InnoDB; SQL语句可以这样写: se
-
asp.net中的check与uncheck关键字用法解析
本文实例讲述了asp.net中的check与uncheck关键字用法.分享给大家供大家参考.具体分析如下: checked和unchecked是两个不常用的关键字,但是确是非常有用的关键字,对此,建议测试时开启全局checked编译器选项. 1. 一段编译没经由过程的代码 复制代码 代码如下: int a = int.MaxValue * 2; 以上代码段编译没有经由过程,在VS2010中会有一条红色的波浪线指出这段代码有题目:"The operation overflows at compil
-
MySQL中给自定义的字段查询结果添加排名的方法
我正在用 MySQL 客户端的时候,突然想到如果可以给查询结果添加排名该多好啊,然后就找到了一个简单的解决办法. 下面是一个示例表的数据: 然后我们要根据 Roll_No 字段进行排序并给出排名,我们首先必须定义一个初始值为0的变量,然后在查询结果中使用这个变量. 如下面的代码: SET @counter=0; SELECT @counter:=@counter+1 AS Rank,LastName,Roll_no as Roll FROM Students ORDER BY Roll_ 执行
-
MySQL中几种数据统计查询的基本使用教程
统计平均数 SELECT AVG() FROM 语法用于从数据表中统计数据平均数. 语法: SELECT AVG(column) FROM tb_name 该 SQL 语法用于统计某一数值类型字段的平均数,AVG() 内不能是多个字段,字符串等类型虽然可以执行,但无意义. 例子: SELECT AVG(uid) FROM user 得到查询结果: 2.5000 当然在此统计 uid 的平均数是无实际生产意义的,只是为了演示 AVG() 语法的用法. 统计数据之和 SELECT SUM() FRO