Pytorch-LSTM输入输出参数方式
目录
- 1.Pytorch中的LSTM中输入输出参数
- 2.输入数据(以batch_first=True,单层单向为例)
- 3.输入数据(以batch_first=True,双层双向)
- Pytorch-LSTM函数参数解释 图解
- torch.nn.LSTM函数
- 图解LSTM函数
1.Pytorch中的LSTM中输入输出参数
nn.lstm是继承nn.RNNBase,初始化的定义如下:
class RNNBase(Module):
...
def __init__(self, mode, input_size, hidden_size,
num_layers=1, bias=True, batch_first=False,
dropout=0., bidirectional=False):
以下是Pytorch中的参数及其含义,解释如下:
input_size– 输入数据的大小,也就是前面例子中每个单词向量的长度hidden_size– 隐藏层的大小(即隐藏层节点数量),输出向量的维度等于隐藏节点数num_layers– recurrent layer的数量,默认等于1。bias– If False, then the layer does not use bias weights b_ih and b_hh. Default: Truebatch_first– 默认为False,也就是说官方不推荐我们把batch放在第一维,这个与之前常见的CNN输入有点不同,此时输入输出的各个维度含义为 (seq_length,batch,feature)。当然如果你想和CNN一样把batch放在第一维,可将该参数设置为True,即 (batch,seq_length,feature),习惯上将batch_first 设置为True。dropout– 如果非0,就在除了最后一层的其它层都插入Dropout层,默认为0。bidirectional– 如果设置为 True, 则表示双向 LSTM,默认为 False
2.输入数据(以batch_first=True,单层单向为例)
假设输入数据信息如下:
- 输入维度 = 28
nn.lstm中的API输入参数如下:
time_steps= 3 batch_first = True batch_size = 10 hidden_size =4 num_layers = 1 bidirectional = False
备注:先以简单的num_layers=1和bidirectional=1为例,后面会讲到num_layers与bidirectional的LSTM网络具体构造。
下在面代码的中:
lstm_input是输入数据,隐层初始输入h_init和记忆单元初始输入c_init的解释如下:
h_init:维度形状为 (num_layers * num_directions, batch, hidden_size):
- 第一个参数的含义num_layers * num_directions, 即LSTM的层数乘以方向数量。这个方向数量是由前面介绍的bidirectional决定,如果为False,则等于1;反之等于2(可以结合下图理解num_layers * num_directions的含义)。
batch:批数据量大小hidden_size: 隐藏层节点数
c_init:维度形状也为(num_layers * num_directions, batch, hidden_size),各参数含义与h_init相同。因为本质上,h_init与c_init只是在不同时刻的不同表达而已。
备注:如果没有传入,h_init和c_init,根据源代码来看,这两个参数会默认为0。
import torch from torch.autograd import Variable from torch import nn input_size = 28 hidden_size = 4 lstm_seq = nn.LSTM(input_size, hidden_size, num_layers=1,batch_first=True) # 构建LSTM网络 lstm_input = Variable(torch.randn(10, 3, 28)) # 构建输入 h_init = Variable(torch.randn(1, lstm_input.size(0), hidden_size)) # 构建h输入参数 -- 每个batch对应一个隐层 c_init = Variable(torch.randn(1, lstm_input.size(0), hidden_size)) # 构建c输出参数 -- 每个batch对应一个隐层 out, (h, c) = lstm_seq(lstm_input, (h_init, c_init)) # 将输入数据和初始化隐层、记忆单元信息传入 print(lstm_seq.weight_ih_l0.shape) # 对应的输入学习参数 print(lstm_seq.weight_hh_l0.shape) # 对应的隐层学习参数 print(out.shape, h.shape, c.shape)
输出结果如下:

输出结果解释如下:
(1)lstm_seq.weight_ih_l0.shape的结果为:torch.Size([16, 28]),表示对应的输入到隐层的学习参数:(4*hidden_size, input_size)。
(2)lstm_seq.weight_hh_l0.shape的结果为:torch.Size([16, 4]),表示对应的隐层到隐层的学习参数:(4*hidden_size, num_directions * hidden_size)
(3)out.shape的输出结果:torch.Size([10,3, 4]),表示隐层到输出层学习参数,即(batch,time_steps, num_directions * hidden_size),维度和输入数据类似,会根据batch_first是否为True进行对应的输出结果,(如果代码中,batch_first=False,则out.shape的结果会变为:torch.Size([3, 10, 4])),
这个输出tensor包含了LSTM模型最后一层每个time_step的输出特征,比如说LSTM有两层,那么最后输出的是 ,表示第二层LSTM每个time step对应的输出;另外如果前面对输入数据使用了torch.nn.utils.rnn.PackedSequence,那么输出也会做同样的操作编程packed sequence;对于unpacked情况,我们可以对输出做如下处理来对方向作分离output.view(seq_len, batch, num_directions, hidden_size), 其中前向和后向分别用0和1表示。
,表示第二层LSTM每个time step对应的输出;另外如果前面对输入数据使用了torch.nn.utils.rnn.PackedSequence,那么输出也会做同样的操作编程packed sequence;对于unpacked情况,我们可以对输出做如下处理来对方向作分离output.view(seq_len, batch, num_directions, hidden_size), 其中前向和后向分别用0和1表示。
h.shape输出结果是: torch.Size([1, 10, 4]),表示隐层到输出层的参数,h_n:(num_layers * num_directions, batch, hidden_size),只会输出最后一个time step的隐状态结果(如下图所示)
c.shape的输出结果是: torch.Size([1, 10, 4]),表示隐层到输出层的参数,c_n :(num_layers * num_directions, batch, hidden_size),同样只会输出最后一个time step的cell状态结果(如下图所示)
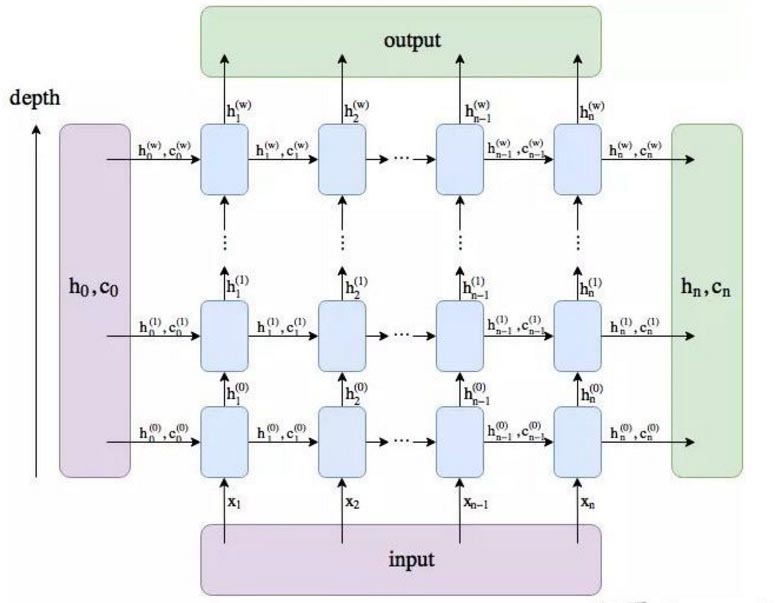
3.输入数据(以batch_first=True,双层双向)
'''
batch_first = True : 输入形式:(batch, seq, feature)
bidirectional = True
num_layers = 2
'''
num_layers = 2
bidirectional_set = True
bidirectional = 2 if bidirectional_set else 1
input_size = 28
hidden_size = 4
lstm_seq = nn.LSTM(input_size, hidden_size, num_layers=num_layers,bidirectional=bidirectional_set,batch_first=True) # 构建LSTM网络
lstm_input = Variable(torch.randn(10, 3, 28)) # 构建输入
h_init = Variable(torch.randn(num_layers*bidirectional, lstm_input.size(0), hidden_size)) # 构建h输入参数
c_init = Variable(torch.randn(num_layers*bidirectional, lstm_input.size(0), hidden_size)) # 构建c输出参数
out, (h, c) = lstm_seq(lstm_input, (h_init, c_init)) # 计算
print(lstm_seq.weight_ih_l0.shape)
print(lstm_seq.weight_hh_l0.shape)
print(out.shape, h.shape, c.shape)
输出结果如下:

Pytorch-LSTM函数参数解释 图解
最近在写有关LSTM的代码,但是对于nn.LSTM函数中的有些参数还是不明白其具体含义,学习过后在此记录。
为了方便说明,我们先解释函数参数的作用,接着对应图片来说明每个参数的具体含义。
torch.nn.LSTM函数
LSTM的函数
class torch.nn.LSTM(args, *kwargs) # 主要参数 # input_size – 输入的特征维度 # hidden_size – 隐状态的特征维度 # num_layers – 层数(和时序展开要区分开) # bias – 如果为False,那么LSTM将不会使用偏置,默认为True。 # batch_first – 如果为True,那么输入和输出Tensor的形状为(batch, seq_len, input_size) # dropout – 如果非零的话,将会在RNN的输出上加个dropout,最后一层除外。 # bidirectional – 如果为True,将会变成一个双向RNN,默认为False。
LSTM的输入维度为 (seq_len, batch, input_size) 如果batch_first为True,则输入形状为(batch, seq_len, input_size)
seq_len是文本的长度;batch是批次的大小;input_size是每个输入的特征纬度(一般是每个字/单词的向量表示;
LSTM的输出维度为 (seq_len, batch, hidden_size * num_directions)
seq_len是文本的长度;batch是批次的大小;hidden_size是定义的隐藏层长度num_directions指的则是如果是普通LSTM该值为1; Bi-LSTM该值为2
当然,仅仅用文本来说明则让人感到很懵逼,所以我们使用图片来说明。
图解LSTM函数
我们常见的LSTM的图示是这样的:

但是这张图很具有迷惑性,让我们不易理解LSTM各个参数的意义。具体将上图中每个单元展开则为下图所示:

input_size: 图1中 xi与图2中绿色节点对应,而绿色节点的长度等于input_size(一般是每个字/单词的向量表示)。
hidden_size: 图2中黄色节点的数量
num_layers: 图2中黄色节点的层数(该图为1)
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
基于pytorch的lstm参数使用详解
lstm(*input, **kwargs) 将多层长短时记忆(LSTM)神经网络应用于输入序列. 参数: input_size:输入'x'中预期特性的数量 hidden_size:隐藏状态'h'中的特性数量 num_layers:循环层的数量.例如,设置' ' num_layers=2 ' '意味着将两个LSTM堆叠在一起,形成一个'堆叠的LSTM ',第二个LSTM接收第一个LSTM的输出并计算最终结果.默认值:1 bias:如果' False',则该层不使用偏置权重' b_ih '和' b
-

Pytorch 如何实现LSTM时间序列预测
开发环境说明: Python 35 Pytorch 0.2 CPU/GPU均可 1.LSTM简介 人类在进行学习时,往往不总是零开始,学习物理你会有数学基础.学习英语你会有中文基础等等. 于是对于机器而言,神经网络的学习亦可不再从零开始,于是出现了Transfer Learning,就是把一个领域已训练好的网络用于初始化另一个领域的任务,例如会下棋的神经网络可以用于打德州扑克. 我们这讲的是另一种不从零开始学习的神经网络--循环神经网络(Recurrent Neural Network, RNN
-
python神经网络Keras实现LSTM及其参数量详解
目录 什么是LSTM 1.LSTM的结构 2.LSTM独特的门结构 3.LSTM参数量计算 在Keras中实现LSTM 实现代码 什么是LSTM 1.LSTM的结构 我们可以看出,在n时刻,LSTM的输入有三个: 当前时刻网络的输入值Xt: 上一时刻LSTM的输出值ht-1: 上一时刻的单元状态Ct-1. LSTM的输出有两个: 当前时刻LSTM输出值ht: 当前时刻的单元状态Ct. 2.LSTM独特的门结构 LSTM用两个门来控制单元状态cn的内容: 遗忘门(forget gate),它决定了
-
PyTorch深度学习LSTM从input输入到Linear输出
目录 LSTM介绍 LSTM参数 Inputs Outputs batch_first 案例 LSTM介绍 关于LSTM的具体原理,可以参考: https://www.jb51.net/article/178582.htm https://www.jb51.net/article/178423.htm 系列文章: PyTorch搭建双向LSTM实现时间序列负荷预测 PyTorch搭建LSTM实现多变量多步长时序负荷预测 PyTorch搭建LSTM实现多变量时序负荷预测 PyTorch搭建LSTM
-
Pytorch-LSTM输入输出参数方式
目录 1.Pytorch中的LSTM中输入输出参数 2.输入数据(以batch_first=True,单层单向为例) 3.输入数据(以batch_first=True,双层双向) Pytorch-LSTM函数参数解释 图解 torch.nn.LSTM函数 图解LSTM函数 1.Pytorch中的LSTM中输入输出参数 nn.lstm是继承nn.RNNBase,初始化的定义如下: class RNNBase(Module): ... def __init__(self, mode, input_s
-
pytorch+lstm实现的pos示例
学了几天终于大概明白pytorch怎么用了 这个是直接搬运的官方文档的代码 之后会自己试着实现其他nlp的任务 # Author: Robert Guthrie import torch import torch.autograd as autograd import torch.nn as nn import torch.nn.functional as F import torch.optim as optim torch.manual_seed(1) lstm = nn.LSTM(3, 3
-
使用Pytorch来拟合函数方式
其实各大深度学习框架背后的原理都可以理解为拟合一个参数数量特别庞大的函数,所以各框架都能用来拟合任意函数,Pytorch也能. 在这篇博客中,就以拟合y = ax + b为例(a和b为需要拟合的参数),说明在Pytorch中如何拟合一个函数. 一.定义拟合网络 1.观察普通的神经网络的优化流程 # 定义网络 net = ... # 定义优化器 optimizer = torch.optim.Adam(net.parameters(), lr=0.001, weight_decay=0.0005)
-
pytorch 查看cuda 版本方式
由于pytorch的whl 安装包名字都一样,所以我们很难区分到底是基于cuda 的哪个版本. 有一条指令可以查看 import torch print(torch.version.cuda) 补充知识:pytorch:网络定义参数的时候后面不能加".cuda()" pytorch定义网络__init__()的时候,参数不能加"cuda()", 不然参数不包含在state_dict()中,比如下面这种写法是错误的 self.W1 = nn.Parameter(tor
-
pytorch lstm gru rnn 得到每个state输出的操作
默认只返回最后一个state,所以一次输入一个step的input # coding=UTF-8 import torch import torch.autograd as autograd # torch中自动计算梯度模块 import torch.nn as nn # 神经网络模块 torch.manual_seed(1) # lstm单元输入和输出维度都是3 lstm = nn.LSTM(input_size=3, hidden_size=3) # 生成一个长度为5,每一个元素为1*3的序
-
python传递参数方式小结
本文实例总结了python传递参数方式.分享给大家供大家参考.具体分析如下: 当形参如*arg时表示传入数组,当形参如**args时表示传入字典. def myprint(*commends,**map): for comm in commends: print comm for key in map.keys(): print key,map[key] myprint("hello","word",username="tian",name=&q
-
Pytorch 实现自定义参数层的例子
注意,一般官方接口都带有可导功能,如果你实现的层不具有可导功能,就需要自己实现梯度的反向传递. 官方Linear层: class Linear(Module): def __init__(self, in_features, out_features, bias=True): super(Linear, self).__init__() self.in_features = in_features self.out_features = out_features self.weight = Pa
-
pytorch 求网络模型参数实例
用pytorch训练一个神经网络时,我们通常会很关心模型的参数总量.下面分别介绍来两种方法求模型参数 一 .求得每一层的模型参数,然后自然的可以计算出总的参数. 1.先初始化一个网络模型model 比如我这里是 model=cliqueNet(里面是些初始化的参数) 2.调用model的Parameters类获取参数列表 一个典型的操作就是将参数列表传入优化器里.如下 optimizer = optim.Adam(model.parameters(), lr=opt.lr) 言归正传,继续回到参
-
Pytorch 保存模型生成图片方式
三通道数组转成彩色图片 img=np.array(img1) img=img.reshape(3,img1.shape[2],img1.shape[3]) img=(img+0.5)*255##img做过归一化处理,[-0.5,0.5] img_path='/home/isee/wei/image/imageset/result.jpg' img=cv2.merge(img) cv2.imwrite(img_path,img) 单通道数组转化成灰度图 Img_mask=np.array(img_
-
pytorch实现线性拟合方式
一维线性拟合 数据为y=4x+5加上噪音 结果: import numpy as np from mpl_toolkits.mplot3d import Axes3D from matplotlib import pyplot as plt from torch.autograd import Variable import torch from torch import nn X = torch.unsqueeze(torch.linspace(-1, 1, 100), dim=1) Y =