C++中整形与浮点型如何在内存中的存储详解
目录
- 1 数据类型
- 1.1 类型的基本归类
- 2 整形在内存中的存储
- 2.1 二进制的三种形式
- 2.2 大小端字的介绍
- 3 浮点数在内存中的存储
- 3.1 浮点数存储规则
1 数据类型
前面我们已经知道了基本的内置类型:

类型的意义:
1. 使用这个类型开辟内存空间的大小(大小决定了使用范围)。
2. 如何看待内存空间的视角。
1.1 类型的基本归类
整形家族:
char
unsigned char
signed char
short
unsigned short [int]
signed short [int]
int
unsigned int
signed int
long
unsigned long [int]
signed long [int]
char 的类型取决于编译器,在VS编译器中的char是signed char.
浮点数家族:
float
double
其中的float类型精度低,存储范围小。
而double类型精度高,存储范围大。
构造类型:
> 数组类型
> 结构体类型 struct
> 枚举类型 enum
> 联合类型 union
指针类型
int *pi;
char *pc;
float* pf;
void* pv;
空类型:
void 表示空类型(无类型)
通常应用于函数的返回类型、函数的参数、指针类型。
今天我要重点和大家分享的是整形家族和浮点数家族是如何在内存中存储的。
2 整形在内存中的存储
2.1 二进制的三种形式
原码:直接用二进制表示。
反码:原码符号位不变,其他位按位取反。
补码:反码+1。
注意:
1 其中正数的原码、反码和补码相同。负数的二进制变换规则如上。
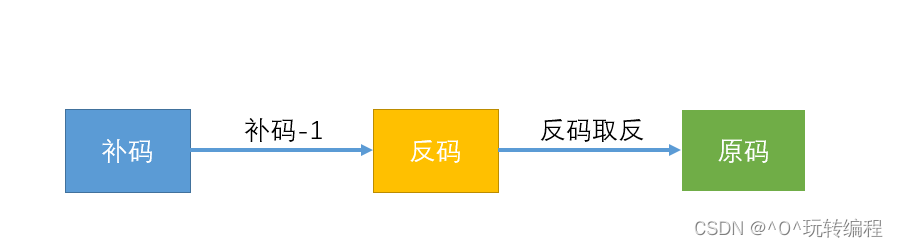
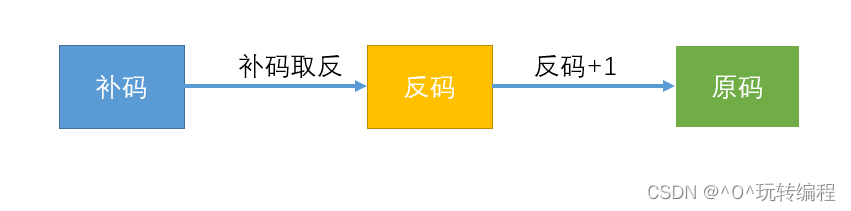
2 补码变为原码有二种办法:
方法1
方法2
那么整形到底是以哪种形式的二进制存储在内存中的呢?
实际是整形是以补码的形式存储在内存中的。
在计算机系统中,数值一律用补码来表示和存储。原因在于,使用补码,可以将符号位和数值域统 一处理;
同时,加法和减法也可以统一处理(CPU只有加法器)此外,补码与原码相互转换,其运算过程 是相同的,不需要额外的硬件电路。
这什么是的啥啊?
其实刚刚学到这里,我也有点懵逼,为什么要用补码存呢?下面我给大家举例
1-1这的运算结果是怎么进行的呢
1的原码(在32位平台上):00000000000000000000000000000001
-1的原码(在32位平台上):10000000000000000000000000000001
-1的反码(在32位平台上):111111111111111111111111111111111110
-1的补码(在32位平台上):111111111111111111111111111111111111
因为CPU只有加法器,所以1-1---->1+(-1)
显然无论是1的原码还是反码和-1的原码或者补码相加都得不到结果。
而补码确可以100000000000000000000000000000000(这里33),而我们是32位平台,所以最终结果为00000000000000000000000000000000(0,看到这里是不是觉的补码很神奇。所以:整数在内存中存的是补码。
虽然我们明白内存中存的是补码,但我们还是不知道补码在内存中是怎么存的,下面我们就要说到大小端字。
2.2 大小端字的介绍
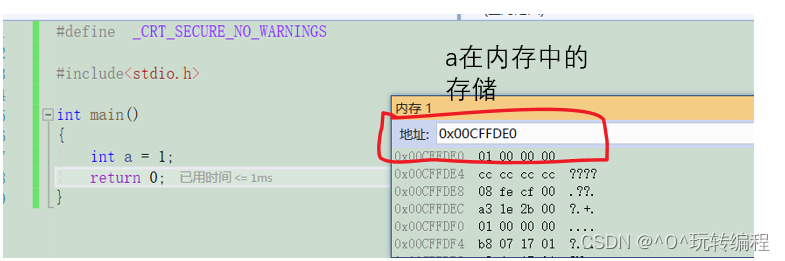
下面我们以整数1来理解
大端字节序存储
就是把一个数据的高位字节序的内容放在低地址处,低位字节序的内容反在高地址处。
我们用16进制表示分布

小端字节序存储
就是把一个数据的高位字节序的内容放在高地址处,低位字节序的内容反在低地址处。
下面是在vs中的存储分布
大小端字节序的存储是和硬件有关,有硬件是小端存储,的有是大端存储。
3 浮点数在内存中的存储
很多人多会想,整形是以补码的形式存储在内存中,存储方式于大小端有关,那么浮点型又是怎么存储的呢?
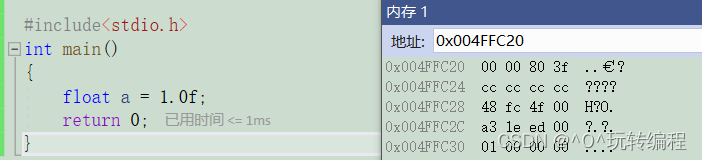
从上面我们可能看出肯定不是和整形的存储方式有关。
3.1 浮点数存储规则
根据国际标准IEEE(电气和电子工程协会) 754,任意一个二进制浮点数V可以表示成下面的形式:
(-1)^S * M * 2^E
(-1)^S表示符号位,当S=0,V为正数;当S=1,V为负数。
M表示有效数字,大于等于1,小于2。
2^E表示指数位。
那么1.0就可以写成
(-1)^0*1.0*2^0(2^n次方是二进制的科学计算法的形式)
其中二点S = 0,M = 1.0,E = 0
那么9.5我们就可以写成
(-1)^0*1.0011*2^3
而9.6呢?
我们发现我们始终都无法表示出0.6,只能不断的接近这个数,所以浮点型在内存中的存储是一个精确值而不是一个准确值。
IEEE 754规定:
对于32位的浮点数,最高的1位是符号位s,接着的8位是指数E,剩下的23位为有效数字M。
对于64位的浮点数,最高的1位是符号位S,接着的11位是指数E,剩下的52位为有效数字M。
IEEE 754对有效数字M和指数E,还有一些特别规定。
前面说过, 1≤M<2 ,也就是说,M可以写成 1.xxxxxx 的形式,其中xxxxxx表示小数部分。 IEEE 754规定,在计算机内部保存M时,默认这个数的第一位总是1,因此可以被舍去,只保存后面的 xxxxxx部分。比如保存1.01的时 候,只保存01,等到读取的时候,再把第一位的1加上去。这样做的目的,是节省1位有效数字。以32位 浮点数为例,留给M只有23位, 将第一位的1舍去以后,等于可以保存24位有效数字。
至于指数E,情况就比较复杂。
首先,E为一个无符号整数(unsigned int)
这意味着,如果E为8位,它的取值范围为0~255;如果E为11位,它的取值范围为0~2047。但是,我们 知道,科学计数法中的E是可以出现负数的,所以IEEE 754规定,存入内存时E的真实值必须再加上一个中间数,对于8位的E,这个中间数 是127;对于11位的E,这个中间 数是1023。比如,2^10的E是10,所以保存成32位浮点数时,必须保存成10+127=137,即 10001001。
指数E从内存中取出还可以再分成三种情况:
E不全为0或不全为1
这时,浮点数就采用下面的规则表示,即指数E的计算值减去127(或1023),得到真实值,再将 有效数字M前加上第一位的1。 比如: 0.5(1/2)的二进制形式为0.1,由于规定正数部分必须为1,即将小数点右移1位,则为 1.0*2^(-1),其阶码为-1+127=126,表示为 01111110,而尾数1.0去掉整数部分为0,补齐0到23位00000000000000000000000,则其二进制表示形式为:0 01111110 00000000000000000000000
E全为0
这时,浮点数的指数E等于1-127(或者1-1023)即为真实值, 有效数字M不再加上第一位的1,而是还原为0.xxxxxx的小数。这样做是为了表示±0,以及接近于 0的很小的数字。
E全为1
这时,如果有效数字M全为0,表示±无穷大(正负取决于符号位s);
好了,浮点型的规则就介绍怎么多。
结束语
简单总结一下,整形的存储是通过补码的形式存入(通过大小端的形式),浮点型存储主要存的是一个符号位E的二进制位级M的精确位数。
到此这篇关于C++中整形与浮点型如何在内存中的存储详解的文章就介绍到这了,更多相关C++整形与浮点型内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
C++中字符串与整型及浮点型转换全攻略
目录 一.string 和 char [] 1. string 转 char [] 2. char [] 转 string 二.char [] 与数字互转 1. char [] 转整型和浮点型 2. 整型和浮点型 转char [] 3. 整型转 char [] (特殊函数实现) 首先请出今日主角:stdlib.h (YYDS) 这个库包含有随机数,abs等许多通用函数,当然也有类型的转换 下面我们一点点来看如何完成格式转换 一.string 和 char [] 1. string 转 char
-

C++浮点型的存储方式详解
目录 浮点型及其存储方式 一.IEEE浮点标准 二.存储方式 IEEE 754对有效数字M和指数E的规定. 重点: 根据指数域不同取值分为一下三种情况: 总结 浮点型及其存储方式 有些时候需要变量能存储带小数点的数,或者能存储极大数或极小数.这类数可以用浮点(因小数点是"浮动的"而得名)格式进行存储.C语言提供了3种浮点类型,对应三种不同的浮点格式. 当精度要求不严格时(小数点后少于六位),float类型是很适合的类型.double提供更高的精度, 对绝大多数程序来说够用了.longd
-
C++中整形与浮点型如何在内存中的存储详解
目录 1 数据类型 1.1 类型的基本归类 2 整形在内存中的存储 2.1 二进制的三种形式 2.2 大小端字的介绍 3 浮点数在内存中的存储 3.1 浮点数存储规则 1 数据类型 前面我们已经知道了基本的内置类型: 类型的意义: 1. 使用这个类型开辟内存空间的大小(大小决定了使用范围). 2. 如何看待内存空间的视角. 1.1 类型的基本归类 整形家族: char unsigned char signed char short unsigned short [int] signed shor
-
C语言编程数据在内存中的存储详解
目录 变量在计算机中有三种表示方式,原码反码,补码 原码 反码 补码 总结一下 浮点数在内存的储存 C语言中,有几种基本内置类型. int unsigned int signed int char unsigned char signed char long unsigned long signed long float double 在内存中创建变量,会在内存中开辟空间,并为其赋值. int a=10; 在计算机中,所有数据都是以二进制的形式存储在内存中. 变量在计算机中有三种表示方式,原码反
-
C++浮点数在内存中的存储详解
目录 前言: 浮点数的表示形式 浮点数存储模型 有效数字M 指数E 例题讲解 总结 前言: 我们在码代码的时候,经常遇到过以整数形式存入,浮点数形式输出:或者浮点数形式存入整数形式输出.输出的结果往往让人意想不到,那么,为什么会发生这样的变化,又是什么导致发生变化,接下来,就让我们从存储内部结构出发,带你深度解刨! 我们以一个例子来说明一切 #include<stdio.h> int main() { int n = 9; float *pFloat = (float *)&n; pr
-
Numpy中ndim、shape、dtype、astype的用法详解
本文介绍numpy数组中这四个方法的区别ndim.shape.dtype.astype. 1.ndim ndim返回的是数组的维度,返回的只有一个数,该数即表示数组的维度. 2.shape shape:表示各位维度大小的元组.返回的是一个元组. 对于一维数组:有疑问的是为什么不是(1,6),因为arr1.ndim维度为1,元组内只返回一个数. 对于二维数组:前面的是行,后面的是列,他的ndim为2,所以返回两个数. 对于三维数组:很难看出,下面打印arr3,看下它是什么结构. 先看最外面的中括号
-
Java 中的vector和list的区别和使用实例详解
要了解vector,list,deque.我们先来了解一下STL. STL是Standard Template Library的简称,中文名是标准模板库.从根本上说,STL是一些容器和算法的集合.STL可分为容器(containers).迭代器(iterators).空间配置器(allocator).配接器(adapters).算法(algorithms).仿函数(functors)六个部分.指针被封装成迭代器,这里vector,list就是所谓的容器. 我们常常在实现链表,栈,队列或者数组时,
-
java中重写equals()方法的同时要重写hashcode()方法(详解)
object对象中的 public boolean equals(Object obj),对于任何非空引用值 x 和 y,当且仅当 x 和 y 引用同一个对象时,此方法才返回 true: 注意:当此方法被重写时,通常有必要重写 hashCode 方法,以维护 hashCode 方法的常规协定,该协定声明相等对象必须具有相等的哈希码.如下: (1) 当obj1.equals(obj2)为true时,obj1.hashCode() == obj2.hashCode()必须为true (2) 当obj
-
关于Java变量的声明、内存分配及初始化详解
实例如下: class Person { String name; int age; void talk() { System.out.println("我是: "+name+", 今年: "+age+"岁"); } } public class TestJava2_1 { public static void main(String args[]) { Person p; if (p == null) { p = new Person(); }
-
Linux共享内存实现机制的详解
Linux共享内存实现机制的详解 内存共享: 两个不同进程A.B共享内存的意思是,同一块物理内存被映射到进程A.B各自的进程地址空间.进程A可以即时看到进程B对共享内存中数据的更新,反之亦然.由于多个进程共享同一块内存区域,必然需要某种同步机制,互斥锁和信号量都可以. 效率: 采用共享内存通信的一个显而易见的好处是效率高,因为进程可以直接读写内存,而不需要任何数据的拷贝.对于像管道和消息队列等通信方式,则需要在内核和用户空间进行四次的数据拷贝,而共享内存则只拷贝两次数据[1]: 一次从输入文件到
-
Java中==运算符与equals方法的区别及intern方法详解
Java中==运算符与equals方法的区别及intern方法详解 1. ==运算符与equals()方法 2. hashCode()方法的应用 3. intern()方法 /* Come from xixifeng.com Author: 习习风(StellAah) */ public class AboutString2 { public static void main(String[]arsgs) { String myName="xixifeng.com"; String
-
对python中list的拷贝与numpy的array的拷贝详解
1.python中列表list的拷贝,会有什么需要注意的呢? python变量名相当于标签名. list2=list1 ,直接赋值,实质上指向的是同一个内存值.任意一个变量list1(或list2)发生改变,都会影响另一个list2(或list1). eg: >>> list1=[1,2,3,4,5,6] >>> list2=list1 >>> list1[2]=88 >>> list1 [1, 2, 88, 4, 5, 6] >