使用nodejs下载风景壁纸
需要用到的第三方模块有:
superagent
superagent-charset (手动指定编码,解决GBK中文乱码)
cheerio
express
async (并发控制)
完整的代码,可以在我的github中可以下载。主要的逻辑逻辑在 netbian.js 中。
以彼岸桌面(http://www.netbian.com/)栏目下的风景壁纸(http://www.netbian.com/fengjing/index.htm)为例进行讲解。
1. 分析URL

不难发现:
首页: 栏目/index.htm
分页: 栏目/index_具体页码.htm
知道这个规律,就可以批量下载壁纸了。
2. 分析壁纸缩略图,找到对应壁纸的大图
使用chrome的开发者工具,可以发现,缩略图列表在 class="list"的div里,a标签的href属性的值就是单张壁纸所在的页面。

部分代码:
request
.get(url)
.end(function(err, sres){
var $ = cheerio.load(sres.text);
var pic_url = []; // 中等图片链接数组
$('.list ul', 0).find('li').each(function(index, ele){
var ele = $(ele);
var href = ele.find('a').eq(0).attr('href'); // 中等图片链接
if(href != undefined){
pic_url.push(url_model.resolve(domain, href));
}
});
});
3. 以“http://www.netbian.com/desk/17662.htm”继续分析
打开这个页面,发现此页面显示的壁纸,依旧不是最高的分辨率。
点击“下载壁纸”按钮里的链接,打开新的页面。
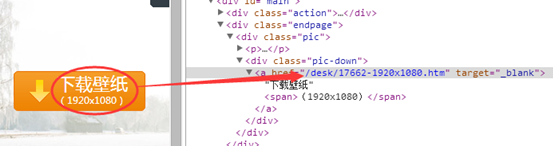
4. 以“http://www.netbian.com/desk/17662-1920x1080.htm”继续分析
打开这个页面,我们最终要下载的壁纸,放在一个table里面。如下图,http://img.netbian.com/file/2017/0203/bb109369a1f2eb2e30e04a435f2be466.jpg
{kind=link}
才是我们最终要下载的图片的URL(幕后BOSS终于现身了(@ ̄ー ̄@))。

下载图片的代码:
request
.get(wallpaper_down_url)
.end(function(err, img_res){
if(img_res.status == 200){
// 保存图片内容
fs.writeFile(dir + '/' + wallpaper_down_title + path.extname(path.basename(wallpaper_down_url)), img_res.body, 'binary', function(err){
if(err) console.log(err);
});
}
});
打开浏览器,访问 http://localhost:1314/fengjing
选择栏目和页面,点击“开始”按钮:

并发请求服务器,下载图片。
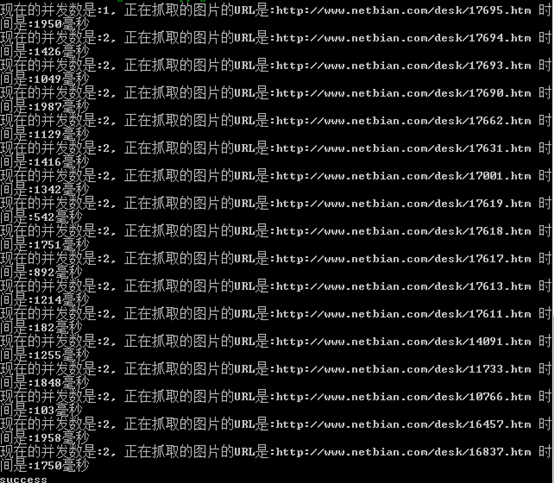
完成~

图片的存放目录按照 栏目+页码 的形式保存。

附上完整的图片下载的代码:
/**
* 下载图片
* @param {[type]} url [图片URL]
* @param {[type]} dir [存储目录]
* @param {[type]} res [description]
* @return {[type]} [description]
*/
var down_pic = function(url, dir, res){
var domain = 'http://www.netbian.com'; // 域名
request
.get(url)
.end(function(err, sres){
var $ = cheerio.load(sres.text);
var pic_url = []; // 中等图片链接数组
$('.list ul', 0).find('li').each(function(index, ele){
var ele = $(ele);
var href = ele.find('a').eq(0).attr('href'); // 中等图片链接
if(href != undefined){
pic_url.push(url_model.resolve(domain, href));
}
});
var count = 0; // 并发计数器
var wallpaper = []; // 壁纸数组
var fetchPic = function(_pic_url, callback){
count++; // 并发加1
var delay = parseInt((Math.random() * 10000000) % 2000);
console.log('现在的并发数是:' + count + ', 正在抓取的图片的URL是:' + _pic_url + ' 时间是:' + delay + '毫秒');
setTimeout(function(){
// 获取大图链接
request
.get(_pic_url)
.end(function(err, ares){
var $$ = cheerio.load(ares.text);
var pic_down = url_model.resolve(domain, $$('.pic-down').find('a').attr('href')); // 大图链接
count--; // 并发减1
// 请求大图链接
request
.get(pic_down)
.charset('gbk') // 设置编码, 网页以GBK的方式获取
.end(function(err, pic_res){
var $$$ = cheerio.load(pic_res.text);
var wallpaper_down_url = $$$('#endimg').find('img').attr('src'); // URL
var wallpaper_down_title = $$$('#endimg').find('img').attr('alt'); // title
// 下载大图
request
.get(wallpaper_down_url)
.end(function(err, img_res){
if(img_res.status == 200){
// 保存图片内容
fs.writeFile(dir + '/' + wallpaper_down_title + path.extname(path.basename(wallpaper_down_url)), img_res.body, 'binary', function(err){
if(err) console.log(err);
});
}
});
wallpaper.push(wallpaper_down_title + '下载完毕<br />');
});
callback(null, wallpaper); // 返回数据
});
}, delay);
};
// 并发为2,下载壁纸
async.mapLimit(pic_url, 2, function(_pic_url, callback){
fetchPic(_pic_url, callback);
}, function (err, result){
console.log('success');
res.send(result[0]); // 取下标为0的元素
});
});
};
特别需要注意的两点:
1. “彼岸桌面”网页的编码是“GBK”的。而nodejs本身只支持“UTF-8”编码。这里我们引入“superagent-charset”模块,用于处理“GBK”的编码。

附上github里的一个例子
https://github.com/magicdawn/superagent-charset

2. nodejs是异步的,同一时间发送大量的请求,有可能被服务器认为是恶意请求而拒绝。 因此这里引入“async”模块,用于并发的处理,使用的方法是:mapLimit。
mapLimit(arr, limit, iterator, callback)
这个方法有4个参数:
第1个参数是数组。
第2个参数是并发请求的数量。
第3个参数是迭代器,通常是一个函数。
第4个参数是并发执行后的回调。
这个方法的作用是将arr中的每个元素同时并发limit次拿给iterator去执行,执行结果传给最后的callback。
后话
至此,便完成了图片的下载。
完整的代码,已经放在github上
以上就是本文的全部内容,希望本文的内容对大家的学习或者工作能带来一定的帮助,同时也希望多多支持我们!
相关推荐
-

Windows系统下nodejs、npm、express的下载和安装教程详解
1. node.js下载 首先进入http://nodejs.org/dist/,这里面的版本呢,几乎每个月都出几个新的,建议大家下载最新版本,看看自己的电脑是多少位的,别下错了. 下载完解压到你想放的位置就好了,解压后你会发现里面有node.exe.我解压到了D:\software_install文件夹. 接下来去命令行,即点击电脑左下角的开始-->运行-->cmd. 进入node.exe所在的目录,输入node -v,查看你的node版本.我的路径如下图所示: 如果你获得以上输出结果,说明
-
Nodejs实现批量下载妹纸图
听说最近下载妹子图很火? Nodejs (javascrpt)自然不能落后~ 虽然从没写过像样的Nodejs程序,但作为至少翻过书的前端同学来说,Nodejs用得还蛮顺手的哈~ 花了一点事件学习了下Nodejs的网页获取和文件下载方法,没事乱捣腾就写了这个半成品的下载器 使用方法: 1)新建一个download目录 2)新建download.js(其实名字随便取),并复制到download目录下 3)复制两段代码到download.js中 4)打开命令行工具,并将当前目录转到与download目
-
nodejs通过phantomjs实现下载网页
功能其实很见简单,通过 phantomjs.exe 采集 url 加载的资源,通过子进程的方式,启动nodejs 加载所有的资源,对于css的资源,匹配css内容,下载里面的url资源 当然功能还是很简单的,在响应式设计和异步加载的情况下,还是有很多资源没有能够下载,需要根据实际情况处理下 首先当然是下载 nodejs 和 phantomjs 下面是 phantomjs.exe 执行的 down.js var page = require('webpage').create(), system
-
使用nodejs下载风景壁纸
需要用到的第三方模块有: superagent superagent-charset (手动指定编码,解决GBK中文乱码) cheerio express async (并发控制) 完整的代码,可以在我的github中可以下载.主要的逻辑逻辑在 netbian.js 中. 以彼岸桌面(http://www.netbian.com/)栏目下的风景壁纸(http://www.netbian.com/fengjing/index.htm)为例进行讲解. 1. 分析URL 不难发现: 首页: 栏目/i
-
Python 下载Bing壁纸的示例
这个示例使用的Python版本为3.7版本, 一.bing壁纸接口 访问bing的官网,通过浏览器开发者工具,查看网络可以找到一个请求壁纸的接口,至于怎么判断的,我是发现当我把鼠标放在切换壁纸的左右箭头时,发现发送了一个请求,查看请求里面是有当前的壁纸信息的,链接.描述等等-- 于是乎得到了这个接口,这个接口似乎就是获取壁纸信息的接口了 https://cn.bing.com/HPImageArchive.aspx?format=js&idx=0&n=1&nc=1600743189
-
编写Python脚本批量下载DesktopNexus壁纸的教程
DesktopNexus 是我最喜爱的一个壁纸下载网站,上面有许多高质量的壁纸,几乎每天必上, 每月也必会坚持分享我这个月来收集的壁纸 但是 DesktopNexus 壁纸的下载很麻烦,而且因为壁纸会通过浏览器检测你当前分辨率来展示 合适你当前分辨率的壁纸,再加上是国外的网站,速度上很不乐观. 于是我写了个脚本,检测输入的页面中壁纸页面的链接,然后批量下载到指定文件夹中. 脚本使用 python 写的,所以需要机器上安装有 python . 用法: $ python desktop_nexus.
-
python实现壁纸批量下载代码实例
项目地址:https://github.com/jrainlau/wallpaper-downloader 前言 好久没有写文章了,因为最近都在适应新的岗位,以及利用闲暇时间学习python.这篇文章是最近的一个python学习阶段性总结,开发了一个爬虫批量下载某壁纸网站的高清壁纸. 注意:本文所属项目仅用于python学习,严禁作为其他用途使用! 初始化项目 项目使用了virtualenv来创建一个虚拟环境,避免污染全局.使用pip3直接下载即可: pip3 install virtualen
-
Python实现壁纸下载与轮换
准备 下载安装Python3 官网下载即可,选择合适的版本:https://www.python.org/downloads/ 安装一直下一步即可,记得勾选添加到环境变量. 安装pypiwin32 执行设置壁纸操作需要调用Windows系统的API,需要安装pypiwin32,控制台执行如下命令: pip install pypiwin32 工作原理 两个线程,一个用来下载壁纸,一个用来轮换壁纸.每个线程内部均做定时处理,通过在配置文件中配置的等待时间来实现定时执行的功能. 壁纸下载线程 简易的
-
nodejs实现生成文件并在前端下载
目录 nodejs生成文件并在前端下载 前端 后端 nodejs下载文件问题 第一种方式:使用原生的http模块 第二种方式:使用Express+Axios下载文件 总结 nodejs生成文件并在前端下载 最近遇到一个小需求,前端要下载一个json文件,内容是对应数据的json对象. 看网上写的都太复杂了,只是下载一个小文件,只需要用到res.end()就够了. 前端 在a标签上加上download属性就可以点击下载文件了,download可以赋值,值为下载之后的文件名.也可以留空,用原有的文件
-
python爬虫 爬取超清壁纸代码实例
简介 壁纸的选择其实很大程度上能看出电脑主人的内心世界,有的人喜欢风景,有的人喜欢星空,有的人喜欢美女,有的人喜欢动物.然而,终究有一天你已经产生审美疲劳了,但你下定决定要换壁纸的时候,又发现网上的壁纸要么分辨率低,要么带有水印. 壁纸的选择其实很大程度上能看出电脑主人的内心世界,有的人喜欢风景,有的人喜欢星空,有的人喜欢美女,有的人喜欢动物.然而,终究有一天你已经产生审美疲劳了,但你下定决定要换壁纸的时候,又发现网上的壁纸要么分辨率低,要么带有水印. 演示图片 完整源代码 ''' 在学习过程中
-
windows 下安装nodejs 环境变量设置
要设置两个东西,一个是PATH上增加node.exe的目录C:\Program Files\nodejs,一个是增加环境变量NODE_PATH,值为C:\Program Files\nodejs\node_modules 一.下载 去nodejs下载node.msi安装文件包,里面包含了node.js和npm: 双击node.msi就行了,选择安装路径和npm: 二.设置环境变量 [新版本都不需要设计环境变量了,软件会自动写入环境变量] 计算机(或者我的电脑)右击属性->高级系统设置->环境
-
windows系统下简单nodejs安装及环境配置
相信对于很多关注javascript发展的同学来说,nodejs已经不是一个陌生的词眼.有关nodejs的相关资料网上已经铺天盖地.由于它的高并发特性,造就了其特殊的应用地位. 国内目前关注最高,维护最好的一个关于nodejs的网站应该是http://www.cnodejs.org/ 这里不想谈太多的nodejs的相关信息.只说一下,windows系统下简单nodejs环境配置. 第一步:下载安装文件 下载地址:官网http://www.nodejs.org/download/ 这里用的是
-
win系统下nodejs环境安装配置
win系统下nodejs安装及环境配置,具体内容如下 第一步:下载安装文件 下载nodejs,官网:http://nodejs.org/download/,我这里下载的是node-v0.10.28-x86.msi,如下图: 第二步:安装nodejs 下载完成之后,双击"node-v0.10.28-x86.msi",开始安装nodejs,自定义安装在D:\dev\nodejs下面. 在cmd控制台输入:node -v,控制台将打印出:v0.10.28,出现版本提示表示安装成功. 该引导步