Java 排序算法整合(冒泡,快速,希尔,拓扑,归并)
冒泡排序介绍
冒泡排序(Bubble Sort),又被称为气泡排序或泡沫排序。
它是一种较简单的排序算法。它会遍历若干次要排序的数列,每次遍历时,它都会从前往后依次的比较相邻两个数的大小;如果前者比后者大,则交换它们的位置。这样,一次遍历之后,最大的元素就在数列的末尾! 采用相同的方法再次遍历时,第二大的元素就被排列在最大元素之前。重复此操作,直到整个数列都有序为止!
冒泡排序图文说明

/*
* a -- 待排序的数组
* n -- 数组的长度
*/
public static void bubbleSort(int[] a, int n) {
int i,j;
for (i=n-1; i>0; i--) {
// 将a[0...i]中最大的数据放在末尾
for (j=0; j<i; j++) {
if (a[j] > a[j+1]) {
// 交换a[j]和a[j+1]
int tmp = a[j];
a[j] = a[j+1];
a[j+1] = tmp;
}
}
}
}
运行:
int[] a = {20,40,30,10,60,50,70};
String aa = "冒泡排序";
bubbleSort(a,a.length);
System.out.print(aa);
for (int d : a) {
System.out.print(d+",");
}
快速排序介绍
快速排序(Quick Sort)使用分治法策略。
它的基本思想是:选择一个基准数,通过一趟排序将要排序的数据分割成独立的两部分;其中一部分的所有数据都比另外一部分的所有数据都要小。然后,再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。
快速排序流程:
- 从数列中挑出一个基准值。
- 将所有比基准值小的摆放在基准前面,所有比基准值大的摆在基准的后面(相同的数可以到任一边);在这个分区退出之后,该基准就处于数列的中间位置。
- 递归地把"基准值前面的子数列"和"基准值后面的子数列"进行排序。
- 图文介绍

代码实现:
/**
*
* 参数说明:
* a -- 待排序的数组
* l -- 数组的左边界(例如,从起始位置开始排序,则l=0)
* r -- 数组的右边界(例如,排序截至到数组末尾,则r=a.length-1)
*/
public static void quickSort(int[] a, int l, int r) {
if (l < r) {
int i,j,x;
i = l;
j = r;
x = a[i];
while (i < j) {
while(i < j && a[j] > x)
j--; // 从右向左找第一个小于x的数
if(i < j)
a[i++] = a[j];
while(i < j && a[i] < x)
i++; // 从左向右找第一个大于x的数
if(i < j)
a[j--] = a[i];
}
a[i] = x;
quickSort(a, l, i-1); /* 递归调用 */
quickSort(a, i+1, r); /* 递归调用 */
}
}
运行:
String aa = "快速排序";
quickSort(a,0,a.length-1);
System.out.print(aa);
for (int d : a) {
System.out.print(d+",");
}
直接插入排序介绍
直接插入排序(Straight Insertion Sort)的基本思想是:把n个待排序的元素看成为一个有序表和一个无序表。开始时有序表中只包含1个元素,无序表中包含有n-1个元素,排序过程中每次从无序表中取出第一个元素,将它插入到有序表中的适当位置,使之成为新的有序表,重复n-1次可完成排序过程。
直接插入排序图文说明

代码实现:
/**
* @param
* a -- 待排序的数组
* n -- 数组的长度
*/
public static void insertSort(int[] a, int n) {
int i, j, k;
for (i = 1; i < n; i++) {
//为a[i]在前面的a[0...i-1]有序区间中找一个合适的位置
for (j = i - 1; j >= 0; j--)
if (a[j] < a[i])
break;
//如找到了一个合适的位置
if (j != i - 1) {
//将比a[i]大的数据向后移
int temp = a[i];
for (k = i - 1; k > j; k--)
a[k + 1] = a[k];
//将a[i]放到正确位置上
a[k + 1] = temp;
}
}
}
运行和冒泡一样。。。。。
希尔排序:
希尔(Shell)排序又称为缩小增量排序,它是一种插入排序。它是直接插入排序算法的一种威力加强版。该方法因DL.Shell于1959年提出而得名。
希尔排序的基本思想是:
把记录按步长 gap 分组,对每组记录采用直接插入排序方法进行排序。
随着步长逐渐减小,所分成的组包含的记录越来越多,当步长的值减小到 1 时,整个数据合成为一组,构成一组有序记录,则完成排序。
我们来通过演示图,更深入的理解一下这个过程。
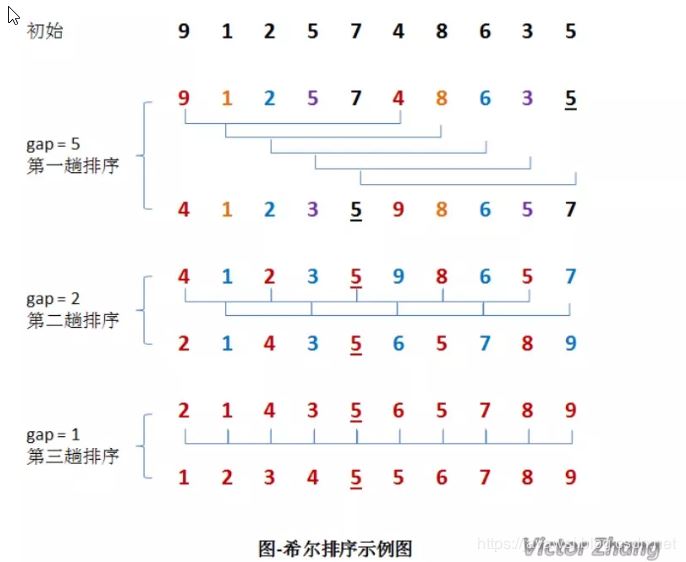
在上面这幅图中:
初始时,有一个大小为 10 的无序序列。
在第一趟排序中,我们不妨设 gap1 = N / 2 = 5,即相隔距离为 5 的元素组成一组,可以分为 5 组。接下来,按照直接插入排序的方法对每个组进行排序。
在第二趟排序中,我们把上次的 gap 缩小一半,即 gap2 = gap1 / 2 = 2 (取整数)。这样每相隔距离为 2 的元素组成一组,可以分为 2 组。按照直接插入排序的方法对每个组进行排序。
在第三趟排序中,再次把 gap 缩小一半,即gap3 = gap2 / 2 = 1。 这样相隔距离为 1 的元素组成一组,即只有一组。按照直接插入排序的方法对每个组进行排序。此时,排序已经结束。
需要注意一下的是,图中有两个相等数值的元素 5 和 5 。我们可以清楚的看到,在排序过程中,两个元素位置交换了。
所以,希尔排序是不稳定的算法。
代码实现:
/**
* 希尔排序
* @param list
*/
public static void shellSort(int[] a) {
int gap = a.length / 2;
while (1 <= gap) {
// 把距离为 gap 的元素编为一个组,扫描所有组
for (int i = gap; i < a.length; i++) {
int j = 0;
int temp = a[i];
// 对距离为 gap 的元素组进行排序
for (j = i - gap; j >= 0 && temp < a[j]; j = j - gap) {
a[j + gap] = a[j];
}
a[j + gap] = temp;
}
System.out.format("gap = %d:\t", gap);
printAll(a);
gap = gap / 2; // 减小增量
}
}
// 打印完整序列
public static void printAll(int[] a) {
for (int value : a) {
System.out.print(value + "\t");
}
System.out.println();
}
运行参考冒泡、、、、、
拓扑排序介绍
拓扑排序(Topological Order)是指,将一个有向无环图(Directed Acyclic Graph简称DAG)进行排序进而得到一个有序的线性序列。
这样说,可能理解起来比较抽象。下面通过简单的例子进行说明!
例如,一个项目包括A、B、C、D四个子部分来完成,并且A依赖于B和D,C依赖于D。现在要制定一个计划,写出A、B、C、D的执行顺序。这时,就可以利用到拓扑排序,它就是用来确定事物发生的顺序的。
在拓扑排序中,如果存在一条从顶点A到顶点B的路径,那么在排序结果中B出现在A的后面。
拓扑排序的算法图解
拓扑排序算法的基本步骤:
1. 构造一个队列Q(queue) 和 拓扑排序的结果队列T(topological);
2. 把所有没有依赖顶点的节点放入Q;
3. 当Q还有顶点的时候,执行下面步骤:
3.1 从Q中取出一个顶点n(将n从Q中删掉),并放入T(将n加入到结果集中);
3.2 对n每一个邻接点m(n是起点,m是终点);
3.2.1 去掉边<n,m>;
3.2.2 如果m没有依赖顶点,则把m放入Q;
注:顶点A没有依赖顶点,是指不存在以A为终点的边。

以上图为例,来对拓扑排序进行演示。

第1步:将B和C加入到排序结果中。
顶点B和顶点C都是没有依赖顶点,因此将C和C加入到结果集T中。假设ABCDEFG按顺序存储,因此先访问B,再访问C。访问B之后,去掉边<B,A>和<B,D>,并将A和D加入到队列Q中。同样的,去掉边<C,F>和<C,G>,并将F和G加入到Q中。
将B加入到排序结果中,然后去掉边<B,A>和<B,D>;此时,由于A和D没有依赖顶点,因此并将A和D加入到队列Q中。
将C加入到排序结果中,然后去掉边<C,F>和<C,G>;此时,由于F有依赖顶点D,G有依赖顶点A,因此不对F和G进行处理。
第2步:将A,D依次加入到排序结果中。
第1步访问之后,A,D都是没有依赖顶点的,根据存储顺序,先访问A,然后访问D。访问之后,删除顶点A和顶点D的出边。
第3步:将E,F,G依次加入到排序结果中。
因此访问顺序是:B -> C -> A -> D -> E -> F -> G
拓扑排序的代码说明
拓扑排序是对有向无向图的排序。下面以邻接表实现的有向图来对拓扑排序进行说明。
1. 基本定义
public class ListDG {
// 邻接表中表对应的链表的顶点
private class ENode {
int ivex;
// 该边所指向的顶点的位置
ENode nextEdge;
// 指向下一条弧的指针
}
// 邻接表中表的顶点
private class VNode {
char data;
// 顶点信息
ENode firstEdge;
// 指向第一条依附该顶点的弧
};
private VNode[] mVexs;
// 顶点数组
...
}
- ListDG是邻接表对应的结构体。 mVexs则是保存顶点信息的一维数组。
- VNode是邻接表顶点对应的结构体。 data是顶点所包含的数据,而firstEdge是该顶点所包含链表的表头指针。
- ENode是邻接表顶点所包含的链表的节点对应的结构体。 ivex是该节点所对应的顶点在vexs中的索引,而nextEdge是指向下一个节点的。
2. 拓扑排序
/*
* 拓扑排序
*
* 返回值:
* -1 -- 失败(由于内存不足等原因导致)
* 0 -- 成功排序,并输入结果
* 1 -- 失败(该有向图是有环的)
*/
public int topologicalSort() {
int index = 0;
int num = mVexs.size();
int[] ins;
// 入度数组
char[] tops;
// 拓扑排序结果数组,记录每个节点的排序后的序号。
Queue<Integer> queue;
// 辅组队列
ins = new int[num];
tops = new char[num];
queue = new LinkedList<Integer>();
// 统计每个顶点的入度数
for(int i = 0; i < num; i++) {
ENode node = mVexs.get(i).firstEdge;
while (node != null) {
ins[node.ivex]++;
node = node.nextEdge;
}
}
// 将所有入度为0的顶点入队列
for(int i = 0; i < num; i ++)
if(ins[i] == 0)
queue.offer(i);
// 入队列
while (!queue.isEmpty()) {
// 队列非空
int j = queue.poll().intValue();
// 出队列。j是顶点的序号
tops[index++] = mVexs.get(j).data;
// 将该顶点添加到tops中,tops是排序结果
ENode node = mVexs.get(j).firstEdge;
// 获取以该顶点为起点的出边队列
// 将与"node"关联的节点的入度减1;
// 若减1之后,该节点的入度为0;则将该节点添加到队列中。
while(node != null) {
// 将节点(序号为node.ivex)的入度减1。
ins[node.ivex]--;
// 若节点的入度为0,则将其"入队列"
if( ins[node.ivex] == 0)
queue.offer(node.ivex);
// 入队列
node = node.nextEdge;
}
}
if(index != num) {
System.out.printf("Graph has a cycle\n");
return 1;
}
// 打印拓扑排序结果
System.out.printf("== TopSort: ");
for(int i = 0; i < num; i ++)
System.out.printf("%c ", tops[i]);
System.out.printf("\n");
return 0;
}
说明:
- queue的作用就是用来存储没有依赖顶点的顶点。它与前面所说的Q相对应。
- tops的作用就是用来存储排序结果。它与前面所说的T相对应。
归并排序
基本思想
归并排序(MERGE-SORT)是利用归并的思想实现的排序方法,该算法采用经典的分治(divide-and-conquer)策略(分治法将问题分(divide)成一些小的问题然后递归求解,而治(conquer)的阶段则将分的阶段得到的各答案"修补"在一起,即分而治之)。
分而治之
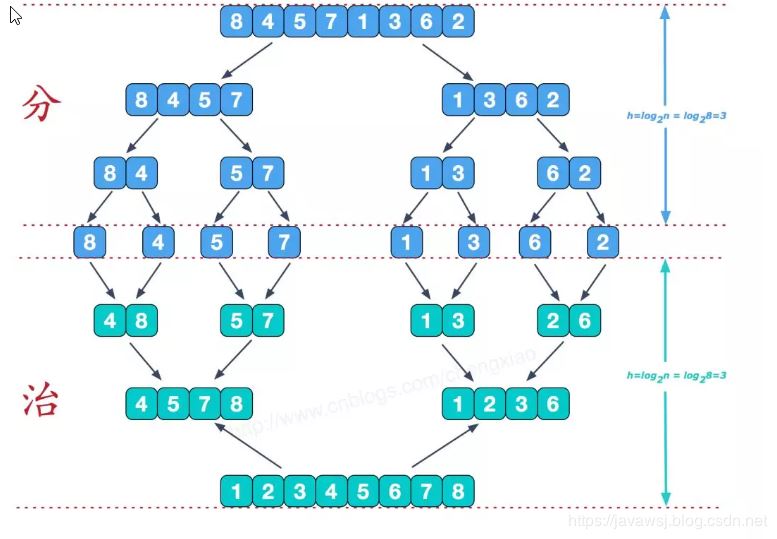
可以看到这种结构很像一棵完全二叉树,本文的归并排序我们采用递归去实现(也可采用迭代的方式去实现)。分阶段可以理解为就是递归拆分子序列的过程,递归深度为log2n。
合并相邻有序子序列
再来看看治阶段,我们需要将两个已经有序的子序列合并成一个有序序列,比如上图中的最后一次合并,要将[4,5,7,8]和[1,2,3,6]两个已经有序的子序列,合并为最终序列[1,2,3,4,5,6,7,8],来看下实现步骤。

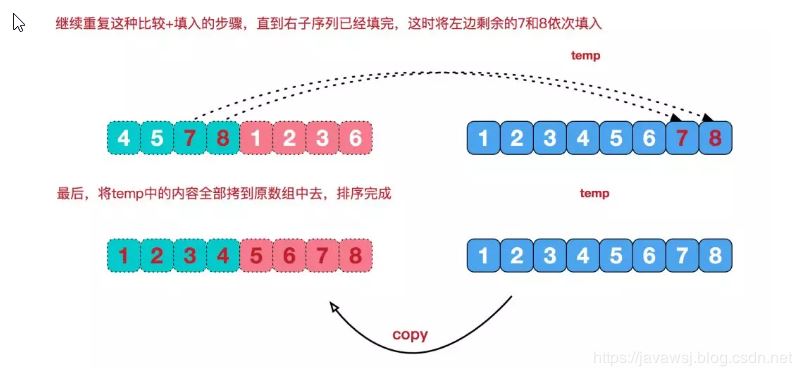
代码实现
package sortdemo;
import java.util.Arrays;
/**
* Created by chengxiao on 2016/12/8.
*/
public class MergeSort {
public static void main(String []args){
int []arr = {9,8,7,6,5,4,3,2,1};
sort(arr);
System.out.println(Arrays.toString(arr));
}
public static void sort(int []arr){
int []temp = new int[arr.length];
//在排序前,先建好一个长度等于原数组长度的临时数组,
//避免递归中频繁开辟空间
sort(arr,0,arr.length-1,temp);
}
private static void sort(int[] arr,int left,int right,int []temp){
if(left<right){
int mid = (left+right)/2;
sort(arr,left,mid,temp);
//左边归并排序,使得左子序列有序
sort(arr,mid+1,right,temp);
//右边归并排序,使得右子序列有序
merge(arr,left,mid,right,temp);
//将两个有序子数组合并操作
}
}
private static void merge(int[] arr,int left,int mid,int right,int[] temp){
int i = left;//左序列指针
int j = mid+1;//右序列指针
int t = 0;//临时数组指针
while (i<=mid && j<=right){
if(arr[i]<=arr[j]){
temp[t++] = arr[i++];
}else {
temp[t++] = arr[j++];
}
}
while(i<=mid){//将左边剩余元素填充进temp中
temp[t++] = arr[i++];
}
while(j<=right){//将右序列剩余元素填充进temp中
temp[t++] = arr[j++];
}
t = 0;
//将temp中的元素全部拷贝到原数组中
while(left <= right){
arr[left++] = temp[t++];
}
}
}
最后
归并排序是稳定排序,它也是一种十分高效的排序,能利用完全二叉树特性的排序一般性能都不会太差。java中Arrays.sort()采用了一种名为TimSort的排序算法,就是归并排序的优化版本。从上文的图中可看出,每次合并操作的平均时间复杂度为O(n),而完全二叉树的深度为|log2n|。总的平均时间复杂度为O(nlogn)。而且,归并排序的最好,最坏,平均时间复杂度均为O(nlogn)。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
Java常用排序算法及性能测试集合
现在再回过头理解,结合自己的体会, 选用最佳的方式描述这些算法,以方便理解它们的工作原理和程序设计技巧.本文适合做java面试准备的材料阅读. 先附上一个测试报告: Array length: 20000bubbleSort : 766 msbubbleSortAdvanced : 662 msbubbleSortAdvanced2 : 647 msselectSort : 252 msinsertSort : 218 msinsertSortAdvanced : 127 msinsertSor
-
java冒泡排序算法代码
复制代码 代码如下: /** * 原理: * 进行n次循环,每次循环从后往前对相邻两个元素进行比较,小的往前,大的往后 * * 时间复杂度: * 平均情况:O(n^2) * 最好情况:O(n) * 最坏情况:O(n^2) * * 稳定性:稳定 **/public class 冒泡排序 { public int[] bubbleSort(int[] a, int n) { for (int i = 0; i < n; i++) { int flag = 0;
-

详解堆排序算法原理及Java版的代码实现
概述 堆排序是一种树形选择排序,是对直接选择排序的有效改进. 堆的定义如下:具有n个元素的序列(k1,k2,...,kn), 当且仅当满足: 时称之为堆.由堆的定义可以看出,堆顶元素(即第一个元素)必为最小项(小顶堆)或最大项(大顶堆). 若以一维数组存储一个堆,则堆对应一棵完全二叉树,且所有非叶结点(有子女的结点)的值均不大于(或不小于)其子女的值,根结点(堆顶元素)的值是最小(或最大)的. (a)大顶堆序列:(96, 83, 27, 38, 11, 09) (b)小顶堆序列:(12, 36,
-
用java实现冒泡排序算法
冒泡排序的算法分析与改进 交换排序的基本思想是:两两比较待排序记录的关键字,发现两个记录的次序相反时即进行交换,直到没有反序的记录为止. 应用交换排序基本思想的主要排序方法有:冒泡排序和快速排序. 复制代码 代码如下: public class BubbleSort implements SortUtil.Sort{ public void sort(int[] data) { int temp; for(int i=0;i<data.length;i++){ for(int j=data.le
-
Java实现几种常见排序算法代码
稳定度(稳定性)一个排序算法是稳定的,就是当有两个相等记录的关键字R和S,且在原本的列表中R出现在S之前,在排序过的列表中R也将会是在S之前. 排序算法分类 常见的有插入(插入排序/希尔排序).交换(冒泡排序/快速排序).选择(选择排序).合并(归并排序)等. 一.插入排序 插入排序(Insertion Sort),它的工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入.插入排序在实现上,通常采用in-place排序(即只需用到O(1)的额外空间的排序),
-
Java实现冒泡排序算法及对其的简单优化示例
原理 冒泡排序大概是所有程序员都会用的算法,也是最熟悉的算法之一. 它的思路并不复杂: 设现在要给数组arr[]排序,它有n个元素. 1.如果n=1:显然不用排了.(实际上这个讨论似乎没什么必要) 2.如果n>1: (1)我们从第一个元素开始,把每两个相邻元素进行比较,如果前面的元素比后面的大,那么在最后的结果里面前者肯定排在后面.所以,我们把这两个元素交换.然后进行下两个相邻的元素的比较.如此直到最后一对元素比较完毕,则第一轮排序完成.可以肯定,最后一个元素一定是数组中最大的(因为每次都把相对
-
快速排序算法原理及java递归实现
快速排序 对冒泡排序的一种改进,若初始记录序列按关键字有序或基本有序,蜕化为冒泡排序.使用的是递归原理,在所有同数量级O(n longn) 的排序方法中,其平均性能最好.就平均时间而言,是目前被认为最好的一种内部排序方法 基本思想是:通过一躺排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列. 三个指针: 第一个指针称为pivotkey指针(枢轴),第二个指
-
Java中常用的6种排序算法详细分解
排序算法很多地方都会用到,近期又重新看了一遍算法,并自己简单地实现了一遍,特此记录下来,为以后复习留点材料. 废话不多说,下面逐一看看经典的排序算法: 1. 选择排序 选择排序的基本思想是遍历数组的过程中,以 i 代表当前需要排序的序号,则需要在剩余的 [i-n-1] 中找出其中的最小值,然后将找到的最小值与 i 指向的值进行交换.因为每一趟确定元素的过程中都会有一个选择最大值的子流程,所以人们形象地称之为选择排序.举个实例来看看: 初始: [38, 17, 16, 16, 7, 31, 39,
-
Java经典排序算法之二分插入排序详解
一.折半插入排序(二分插入排序) 将直接插入排序中寻找A[i]的插入位置的方法改为采用折半比较,即可得到折半插入排序算法.在处理A[i]时,A[0]--A[i-1]已经按关键码值排好序.所谓折半比较,就是在插入A[i]时,取A[i-1/2]的关键码值与A[i]的关键码值进行比较,如果A[i]的关键码值小于A[i-1/2]的关键码值,则说明A[i]只能插入A[0]到A[i-1/2]之间,故可以在A[0]到A[i-1/2-1]之间继续使用折半比较:否则只能插入A[i-1/2]到A[i-1]之间,故可
-
堆排序算法的讲解及Java版实现
堆是数据结构中的一种重要结构,了解了"堆"的概念和操作,可以快速掌握堆排序. 堆的概念 堆是一种特殊的完全二叉树(complete binary tree).如果一棵完全二叉树的所有节点的值都不小于其子节点,称之为大根堆(或大顶堆):所有节点的值都不大于其子节点,称之为小根堆(或小顶堆). 在数组(在0号下标存储根节点)中,容易得到下面的式子(这两个式子很重要): 1.下标为i的节点,父节点坐标为(i-1)/2: 2.下标为i的节点,左子节点坐标为2*i+1,右子节点为2*i+2. 堆
-
Java经典排序算法之归并排序详解
一.归并排序 归并排序是建立在归并操作上的一种有效的排序算法,该算法是采用分治法(Divide and Conquer)的一个非常典型的应用.将已有序的子序列合并,得到完全有序的序列:即先使每个子序列有序,再使子序列段间有序.若将两个有序表合并成一个有序表,称为二路归并. 归并过程为:比较a[i]和a[j]的大小,若a[i]≤a[j],则将第一个有序表中的元素a[i]复制到r[k]中,并令i和k分别加上1:否则将第二个有序表中的元素a[j]复制到r[k]中,并令j和k分别加上1,如此循环下去,直
-
java 合并排序算法、冒泡排序算法、选择排序算法、插入排序算法、快速排序算法的描述
算法是在有限步骤内求解某一问题所使用的一组定义明确的规则.通俗点说,就是计算机解题的过程.在这个过程中,无论是形成解题思路还是编写程序,都是在实施某种算法.前者是推理实现的算法,后者是操作实现的算法. 一个算法应该具有以下五个重要的特征: 1.有穷性: 一个算法必须保证执行有限步之后结束: 2.确切性: 算法的每一步骤必须有确切的定义: 3.输入:一个算法有0个或多个输入,以刻画运算对象的初始情况: 4.输出:一个算法有一个或多个输出,以反映对输入数据加工后的结果.没有输出的算法是毫无意义的:
-
十种JAVA排序算法实例
排序算法有很多,所以在特定情景中使用哪一种算法很重要.为了选择合适的算法,可以按照建议的顺序考虑以下标准: (1)执行时间 (2)存储空间 (3)编程工作 对于数据量较小的情形,(1)(2)差别不大,主要考虑(3):而对于数据量大的,(1)为首要. 一.冒泡(Bubble)排序 复制代码 代码如下: void BubbleSortArray() { for(int i=1;i<n;i++) { for(int j=0;i<n-i;j++)