SQL中distinct 和 row_number() over() 的区别及用法
1 前言
在咱们编写 SQL 语句操作数据库中的数据的时候,有可能会遇到一些不太爽的问题,例如对于同一字段拥有相同名称的记录,我们只需要显示一条,但实际上数据库中可能含有多条拥有相同名称的记录,从而在检索的时候,显示多条记录,这就有违咱们的初衷啦!因此,为了避免这种情况的发生,咱们就需要进行“去重”处理啦,那么何为“去重”呢?说白了,就是对同一字段让拥有相同内容的记录只显示一条记录。
那么,如何实现“去重”的功能呢?对此,咱们有两种方式可以实现该功能。
第一种,在编写 select 语句的时候,添加 distinct 关键词;
第二种,在编写 select 语句的时候,调用 row_number() over() 函数。
以上两种方式都可以实现“去重”功能,那两者之间有何异同呢?接下来,作者将给出详细的说明。
2 distinct
在 SQL 中,关键字 distinct 用于返回唯一不同的值。其语法格式为:
SELECT DISTINCT 列名称 FROM 表名称
假设有一个表“CESHIDEMO”,包含两个字段,分别 NAME 和 AGE,具体格式如下:
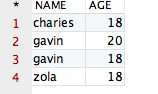
观察以上的表,咱们会发现:拥有相同 NAME 的记录有两条,拥有相同 AGE 的记录有三条。如果咱们运行下面这条 SQL 语句,
/** * 其中 PPPRDER 为 Schema 的名字,即表 CESHIDEMO 在 PPPRDER 中 */ select name from PPPRDER.CESHIDEMO
将会得到如下结果:
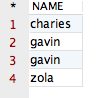
观察该结果,咱们会发现在以上的四条记录中,包含两条 NAME 值相同的记录,即第 2 条记录和第 3 条记录的值都为“gavin”。那么,如果咱们想让拥有相同 NAME 的记录只显示一条该如何实现呢?这时,就需要用到 distinct 关键字啦!接下来,运行如下 SQL 语句,
select distinct name from PPPRDER.CESHIDEMO
将会得到如下结果:

观察该结果,显然咱们的要求得到实现啦!但是,咱们不禁会想到,如果将 distinct 关键字同时作用在两个字段上将会产生什么效果呢?既然想到了,咱们就试试呗,运行如下 SQL 语句,
select distinct name, age from PPPRDER.CESHIDEMO
得到的结果如下所示:
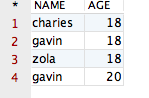
观察该结果,哎呀,貌似没有作用啊?她将全部的记录都显示出来了啊!其中 NAME 值相同的记录有两条,AGE 值相同的记录有三条,完全没有变化啊!但事实上,结果就应该是这样的。因为当 distinct 作用在多个字段的时候,她只会将所有字段值都相同的记录“去重”掉,显然咱们“可怜”的四条记录并不满足该条件,因此 distinct 会认为上面四条记录并不相同。空口无凭,接下来,咱们再向表“CESHIDEMO”中添加一条完全相同的记录,验证一下即可。添加一条记录后的表如下所示:
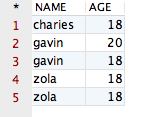
再运行如下的 SQL 语句,
select distinct name, age from PPPRDER.CESHIDEMO
得到的结果如下所示:
观察该结果,完美的验证了咱们上面的结论。
此外,有一点需要大家特别注意,即:关键字 distinct 只能放在 SQL 语句中所有字段的最前面才能起作用,如果放错位置,SQL 不会报错,但也不会起到任何效果。
3 row_number() over()
在 SQL Server 数据库中,为咱们提供了一个函数 row_number() 用于给数据库表中的记录进行标号,在使用的时候,其后还跟着一个函数 over(),而函数 over() 的作用是将表中的记录进行分组和排序。两者使用的语法为:
ROW_NUMBER() OVER(PARTITION BY COLUMN1 ORDER BY COLUMN2)
意为:将表中的记录按字段 COLUMN1进行分组,按字段 COLUMN2 进行排序,其中
PARTITION BY:表示分组ORDER BY:表示排序
接下来,咱们还用表“CESHIDEMO”中的数据进行测试。首先,给出没有使用 row_number() over() 函数时查询的结果,如下所示:
然后,运行如下 SQL 语句,
select PPPRDER.CESHIDEMO.*, row_number() over(partition by age order by name desc) from PPPRDER.CESHIDEMO
得到的结果如下所示:
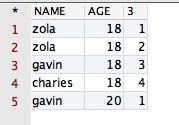
从上面的结果可以看出,其在原表的基础上,多了一列标有数字排序的列。那么反过来分析咱们运行的 SQL 语句,发现其确实按字段 AGE 的值进行分组了,也按字段 NAME 的值进行排序啦!因此,函数的功能得到了验证。
接下来,咱们就研究如何用 row_number() over() 函数实现“去重”的功能。通过观察上面的结果,咱们可以发现,如果以 NAME 分组,以 AGE 排序,然后再取每组的第一个记录或许就可以实现“去重”的功能啊!那么试试看,运行如下 SQL 语句,
/* * 其中 rn 表示最后添加的那一列 */ select * from (select PPPRDER.CESHIDEMO.*, row_number() over(partition by name order by age desc) rn from PPPRDER.CESHIDEMO) where rn = 1
运行后,得到的结果如下所示:

观察以上的结果,我们发现,哎呀,数据“去重”的功能一不小心就被咱们实现了啊!不过很遗憾,如果咱们细心的话,会发现一个很不爽的事情,那就是在执行以上 SQL 语句进行“去重”的时候,有一条 NAME 值为“gavin”、AGE 值为“18”的记录被过滤掉了,但是在现实生活会中,同名不同年龄的事情太正常了。
4 总结
通过阅读及实践以上内容,咱们已经知道了,无论是用关键字 distinct 还是用函数 row_number() over() 都可以实现数据“去重”的功能。但是在实现使用的过程中,咱们要特别注意两者的用法特点以及区别。
在使用关键字 distinct 的时候,咱们要知道其作用于单个字段和多个字段的时候是有区别的,作用于单个字段时,其“去重”的是表中所有该字段值重复的数据;作用于多个字段的时候,其“去重”的表中所有字段(即 distinct 具体作用的多个字段)值都相同的数据。
在使用函数 row_number() over() 的时候,其是按先分组排序后,再取出每组的第一条记录来进行“去重”的(在本篇博文中如此)。当然,在此处咱们还可以通过不同的限制条件来进行“去重”,具体如何实现,就需要大家自己去动脑思考啦!
最后,在本篇博文中,作者详述了自己对用关键字 distinct 和函数 row_number() over() 进行数据“去重”的一些认识,希望以上的内容能够对大家有所帮助!
感谢阅读,希望能帮助到大家,谢谢大家对本站的支持!
相关推荐
-

SQL中distinct 和 row_number() over() 的区别及用法
1 前言 在咱们编写 SQL 语句操作数据库中的数据的时候,有可能会遇到一些不太爽的问题,例如对于同一字段拥有相同名称的记录,我们只需要显示一条,但实际上数据库中可能含有多条拥有相同名称的记录,从而在检索的时候,显示多条记录,这就有违咱们的初衷啦!因此,为了避免这种情况的发生,咱们就需要进行"去重"处理啦,那么何为"去重"呢?说白了,就是对同一字段让拥有相同内容的记录只显示一条记录. 那么,如何实现"去重"的功能呢?对此,咱们有两种方式可以实现该
-
带例子详解Sql中Union和Union ALL的区别
目录 前言 提前准备 测试 Union Union ALL Union Union All union Union All 最后 前言 一段时间没有用Union和Union,再用的时候忘了怎么用了...所以做一篇文章来记录自己学Union和Union的经历. 提前准备 在Sql Server 创建两张表,下面是创建表sql语句. create table Student1( Id varchar(50) not null, Name varchar(50) not null, Age int n
-
sql中的 where 、group by 和 having 用法解析
废话不多说了,直接给大家贴代码了,具体代码如下所示: --sql中的 where .group by 和 having 用法解析 --如果要用到group by 一般用到的就是"每这个字" 例如说明现在有一个这样的表:每个部门有多少人 就要用到分组的技术 select DepartmentID as '部门名称',COUNT(*) as '个数' from BasicDepartment group by DepartmentID --这个就是使用了group by +字段 进行了分组
-
jquery中attr、prop、data区别与用法分析
本文实例讲述了jquery中attr.prop.data区别与用法.分享给大家供大家参考,具体如下: 在高版本的jquery中获取标签的属性,可以使用attr().prop().data(),那么这些方法有什么区别呢? 对于HTML元素本身就带有的固有属性,在处理时,使用prop方法. 对于HTML元素我们自己自定义的DOM属性,在处理时,使用attr方法. .data()看作是存取data-xxx这样DOM附加信息的方法 上面的描述也许有点模糊,举几个例子就知道了. <a href="h
-
MySQL去重中distinct和group by的区别浅析
今天在写业务需要对数据库重复字段进行去重时,因为是去重,首先想到的是distinct关键字.于是一小时过去了....(菜鸟一个,大家轻点骂) 我把问题的过程用sql语句演示给大家演示一下 首先我使用的是mybatis-plus,代码如下 QueryWrapper<ProjectCompany> wrapper = new QueryWrapper<>(); wrapper.select("DISTINCT project_id,company_id,company_nam
-
Python中几种属性访问的区别与用法详解
起步 在Python中,对于一个对象的属性访问,我们一般采用的是点(.)属性运算符进行操作.例如,有一个类实例对象foo,它有一个name属性,那便可以使用foo.name对此属性进行访问.一般而言,点(.)属性运算符比较直观,也是我们经常碰到的一种属性访问方式. python的提供一系列和属性访问有关的特殊方法: __get__ , __getattr__ , __getattribute__ , __getitem__ .本文阐述它们的区别和用法. 属性的访问机制 一般情况下,属性访问的默认
-
JS中call(),apply(),bind()函数的区别与用法详解
call() 介绍 通过提供一个新的this值给当前调用的函数/方法,从而改变this指向. 语法 fn.call(this.Arg, arg1, arg2,...) thisArg:当前调用函数this指向的对象arg1, arg2:传递的其他参数(直接传给形参可不写) 特点 可以直接调用函数—fn.call() 可以改变被调用函数的this指向为指定的— fn.call(this.Arg) 返回值 使用调用者提供的值和参数调用该函数的返回值,也就是函数的返回值.若该方法没有返回值,则返回un
-
基于SQL中SET与SELECT赋值的区别详解
最近的项目写的SQL比较多,经常会用到对变量赋值,而我使用SET和SELECT都会达到效果.那就有些迷惑,这两者有什么区别呢?什么时候哪该哪个呢?经过网上的查询,及个人练习,总结两者有以下几点主要区别:假定有设定变量: 复制代码 代码如下: DECLARE @VAR1 VARCHAR(1) DECLARE @VAR2 VARCHAR(2) 1.SELECT可以在一条语句里对多个变量同时赋值,而SET只能一次对一个变量赋值,如下: 复制代码 代码如下: SELECT @VAR1='Y',@VAR2
-
SQL中distinct的用法(四种示例分析)
在使用mysql时,有时需要查询出某个字段不重复的记录,虽然mysql提供有distinct这个关键字来过滤掉多余的重复记录只保留一条,但往往只 用它来返回不重复记录的条数,而不是用它来返回不重记录的所有值.其原因是distinct只能返回它的目标字段,而无法返回其它字段,这个问题让我困扰很久,用distinct不能解决的话,我只有用二重循环查询来解决,而这样对于一个数据量非常大的站来说,无疑是会直接影响到效率的,所以浪费了我大量时间. 在表中,可能会包含重复值.这并不成问题,不过,有时您也许希
-
Asp.Net Core中服务的生命周期选项区别与用法详解
前言 最近在做一个小的Demo中,在一个界面上两次调用视图组件,并且在视图组件中都调用了数据库查询,结果发现,一直报错,将两个视图组件的调用分离,单独进行,却又是正常的,寻找一番,发现是配置依赖注入服务时,对于服务的生命周期没有配置得当导致,特此做一次实验来认识三者之间(甚至是四者之间的用法及区别). 本文demo地址(具体见WebApi控制器中):https://gitee.com/530521314/koInstance.git (本地下载) 一.服务的生命周期 在Asp.Net Core