深入nodejs中流(stream)的理解
nodejs的fs模块并没有提供一个copy的方法,但我们可以很容易的实现一个,比如:
var source = fs.readFileSync('/path/to/source', {encoding: 'utf8'});
fs.writeFileSync('/path/to/dest', source);
这种方式是把文件内容全部读入内存,然后再写入文件,对于小型的文本文件,这没有多大问题,比如grunt-file-copy就是这样实现的。但是对于体积较大的二进制文件,比如音频、视频文件,动辄几个GB大小,如果使用这种方法,很容易使内存“爆仓”。理想的方法应该是读一部分,写一部分,不管文件有多大,只要时间允许,总会处理完成,这里就需要用到流的概念。
如上面高大上的图片所示,我们把文件比作装水的桶,而水就是文件里的内容,我们用一根管子(pipe)连接两个桶使得水从一个桶流入另一个桶,这样就慢慢的实现了大文件的复制过程。
Stream在nodejs中是EventEmitter的实现,并且有多种实现形式,例如:
- http responses request
- fs read write streams
- zlib streams
- tcp sockets
- child process stdout and stderr
上面的文件复制可以简单实现一下:
var fs = require('fs');
var readStream = fs.createReadStream('/path/to/source');
var writeStream = fs.createWriteStream('/path/to/dest');
readStream.on('data', function(chunk) { // 当有数据流出时,写入数据
writeStream.write(chunk);
});
readStream.on('end', function() { // 当没有数据时,关闭数据流
writeStream.end();
});
上面的写法有一些问题,如果写入的速度跟不上读取的速度,有可能导致数据丢失。正常的情况应该是,写完一段,再读取下一段,如果没有写完的话,就让读取流先暂停,等写完再继续,于是代码可以修改为:
var fs = require('fs');
var readStream = fs.createReadStream('/path/to/source');
var writeStream = fs.createWriteStream('/path/to/dest');
readStream.on('data', function(chunk) { // 当有数据流出时,写入数据
if (writeStream.write(chunk) === false) { // 如果没有写完,暂停读取流
readStream.pause();
}
});
writeStream.on('drain', function() { // 写完后,继续读取
readStream.resume();
});
readStream.on('end', function() { // 当没有数据时,关闭数据流
writeStream.end();
});
或者使用更直接的pipe
// pipe自动调用了data,end等事件
fs.createReadStream('/path/to/source').pipe(fs.createWriteStream('/path/to/dest'));
下面是一个更加完整的复制文件的过程
var fs = require('fs'),
path = require('path'),
out = process.stdout;
var filePath = '/Users/chen/Movies/Game.of.Thrones.S04E07.1080p.HDTV.x264-BATV.mkv';
var readStream = fs.createReadStream(filePath);
var writeStream = fs.createWriteStream('file.mkv');
var stat = fs.statSync(filePath);
var totalSize = stat.size;
var passedLength = 0;
var lastSize = 0;
var startTime = Date.now();
readStream.on('data', function(chunk) {
passedLength += chunk.length;
if (writeStream.write(chunk) === false) {
readStream.pause();
}
});
readStream.on('end', function() {
writeStream.end();
});
writeStream.on('drain', function() {
readStream.resume();
});
setTimeout(function show() {
var percent = Math.ceil((passedLength / totalSize) * 100);
var size = Math.ceil(passedLength / 1000000);
var diff = size - lastSize;
lastSize = size;
out.clearLine();
out.cursorTo(0);
out.write('已完成' + size + 'MB, ' + percent + '%, 速度:' + diff * 2 + 'MB/s');
if (passedLength < totalSize) {
setTimeout(show, 500);
} else {
var endTime = Date.now();
console.log();
console.log('共用时:' + (endTime - startTime) / 1000 + '秒。');
}
}, 500);
可以把上面的代码保存为copy.js试验一下
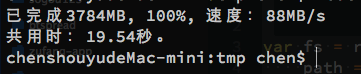
我们添加了一个递归的setTimeout(或者直接使用setInterval)来做一个旁观者,每500ms观察一次完成进度,并把已完成的大小、百分比和复制速度一并写到控制台上,当复制完成时,计算总的耗费时间,效果如图:

我们复制了一集1080p的权利的游戏第四季第7集,大概3.78G大小,由于使用了SSD,可以看到速度还是非常不错的,哈哈哈~ 复制完成后,显示总花费时间
结合nodejs的readline, process.argv等模块,我们可以添加覆盖提示、强制覆盖、动态指定文件路径等完整的复制方法,有兴趣的可以实现一下,实现完成,可以
ln -s /path/to/copy.js /usr/local/bin/mycopy
这样就可以使用自己写的mycopy命令替代系统的cp命令
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-

Node.js中流(stream)的使用方法示例
前言 本文主要给大家介绍了关于Node.js 流(stream)的使用方法,分享出来供大家参考学习,下面话不多说,来一起看看详细的介绍: 流是基于事件的API,用于管理和处理数据,而且有不错的效率.借助事件和非阻塞I/O库,流模块允许在其可用的时候动态处理,在其不需要的时候释放掉. 使用流的好处 举一个读取文件的例子: 使用fs.readFileSync同步读取一个文件,程序会被阻塞,所有的数据都会被读取到内存中. 换用fs.readFile读取文件,程序不会被阻塞,但是所有的数据依旧会被一次性
-
Node.js中的缓冲与流模块详细介绍
缓冲(buffer)模块 js起初就是为浏览器而设计的,所以能很好的处理unicode编码的字符串,但不能很好的处理二进制数据.这是Node.js的一个问题,因为Node.js旨在网络上发送和接收经常是以二进制格式传输的数据.比如: - 通过TCP连接发送和接收数据: - 从图像或者压缩文件读取二进制数据: - 从文件系统读写数据: - 处理来自网络的二进制数据流 而Buffer模块为Node.js带来了一种存储原始数据的方法,于是可以再js的上下文中使用二进制数据.每当需要在Node.j
-
Nodejs Stream 数据流使用手册
1.介绍 本文介绍了使用 node.js streams 开发程序的基本方法. <code class="hljs mizar">"We should have some ways of connecting programs like garden hose--screw in another segment when it becomes necessary to massage data in another way. This is the way of
-
详解Node.js串行化流程控制
串行任务:需要一个接着一个坐的任务叫做串行任务. 可以使用回调的方式让几个异步任务按顺序执行,但如果任务过多,必须组织一下,否则过多的回调嵌套会把代码搞得很乱. 为了用串行化流程控制让几个异步任务按顺序执行,需要先把这些任务按预期的执行顺序放到一个数组中,这个数组将起到队列的作用:完成一个任务后按顺序从数组中取出下一个. 数组中的每个任务都是一个函数.任务完成后应该调用一个处理器函数,告诉它错误状态和结果. 为了演示如何实现串行化流程控制,我们准备做个小程序,让它从一个随机选择的RSS预定源中获
-
用NODE.JS中的流编写工具是要注意的事项
Node.js中的流十分强大,它对处理潜在的大文件提供了支持,也抽象了一些场景下的数据处理和传递.正因为它如此好用,所以在实战中我们常常基于它来编写一些工具 函数/库 ,但往往又由于自己对流的某些特性的疏忽,导致写出的 函数/库 在一些情况会达不到想要的效果,或者埋下一些隐藏的地雷.本文将会提供两个在编写基于流的工具时,私以为有些用的两个tips. 一,警惕EVENTEMITTER内存泄露 在一个可能被多次调用的函数中,如果需要给流添加事件监听器来执行某些操作.那么则需要警惕添加监听器而导致的内
-
深入nodejs中流(stream)的理解
nodejs的fs模块并没有提供一个copy的方法,但我们可以很容易的实现一个,比如: var source = fs.readFileSync('/path/to/source', {encoding: 'utf8'}); fs.writeFileSync('/path/to/dest', source); 这种方式是把文件内容全部读入内存,然后再写入文件,对于小型的文本文件,这没有多大问题,比如grunt-file-copy就是这样实现的.但是对于体积较大的二进制文件,比如音频.视频文件,动
-
NodeJS 中Stream 的基本使用
在 NodeJS 中,我们对文件的操作需要依赖核心模块 fs , fs 中有很基本 API 可以帮助我们读写占用内存较小的文件,如果是大文件或内存不确定也可以通过 open . read . write . close 等方法对文件进行操作,但是这样操作文件每一个步骤都要关心,非常繁琐, fs 中提供了可读流和可写流,让我们通过流来操作文件,方便我们对文件的读取和写入. 可读流 1.createReadStream 创建可读流 createReadStream 方法有两个参数,第一个参数是读取文
-
Nodejs探秘之深入理解单线程实现高并发原理
前言 从Node.js进入我们的视野时,我们所知道的它就由这些关键字组成 事件驱动.非阻塞I/O.高效.轻量,它在官网中也是这么描述自己的. Node.js® is a JavaScript runtime built on Chrome's V8 JavaScript engine. Node.js uses an event-driven, non-blocking I/O model that makes it lightweight and efficient. 于是在我们刚接触Node
-
理解nodejs的stream和pipe机制的原理和实现
前言 前几天别人请教我关于pipe的问题,我发现我虽然用了nodejs很久,但是由于每次用的不多所以经常回避stream的使用,导致一直不熟,现在重新学习整理一下相关知识. 通过nodeschool学习stream nodeschool有一个stream-adventure教程教导stream的使用,很简单 简单stream进行pipe 首先,我们可以通过管道将输入定位到输出,输入输出可以是控制台或者文件流或者http请求,比如 process.stdin.pipe(process.stdout
-
详解nodeJs文件系统(fs)与流(stream)
一.简介 本文将介绍node.js文件系统(fs)和流(stream)的一些API已经参数使用情况. 二.目录 文件系统将介绍以下方法: 1.fs.readFile 2.fs.writeFile 3.fs.open 4.fs.read 5.fs.stat 6.fs.close 7.fs.mkdir 8.fs.rmdir 9.fs.readdir 10.fs.unlink stream流的四种类型readable,writable,duplex,transform以及stream对象的事件. 三.
-
初探nodeJS
一.node概要 对nodeJS早有耳闻,但是一直迟迟没有对它下手,哈哈哈,今儿咱就来初探一下它. nodeJS是个啥东东? nodeJS,我的理解就是可以运行在后端的JavaScript. 为什么它能够在后端运行呢? 这就得归功于V8引擎(V8是Google Chrome浏览器的JavaScript引擎),通过对高性能V8引擎的封装,并通过一系列优化的API类库,使其就能够在后端运行了. 并且node有两大特点: 1.基于事件驱动: 2.无阻塞. 从而nodeJS非常适合处理并发请求. 大家都
-
nodejs前端自动化构建环境的搭建
为了UED前端团队更好的协作开发同时提高项目编码质量,我们需要将Web前端使用工程化方式构建: 目前需要一些简单的功能: 1. 版本控制 2. 检查JS 3. 图片合并 4. 压缩CSS 5. 压缩JS 6. 编译SASS 这些都是每个Web项目在构建.开发阶段需要做的事情.前端自动化构建环境可以把这些重复工作一次配置,多次重复执行,极大的提高开发效率. 目前最知名的构建工具: Gulp.Grunt.NPM + Webpack: grunt是前端工
-
吊打Java面试官之Lambda表达式 Stream API
目录 一.jdk8新特性简介 二.Lambda表达式 简单理解一下Lambda表达式 Lambda表达式的使用 三.函数式接口 1.什么是函数式接口 2.如何理解函数式接口 3.Java内置四大核心函数式接口 四.方法引用与构造器引用 方法引用 构造器引用和数组引用 五.Stream API 1.Stream API的说明 2.为什么要使用Stream API 3.创建Stream的四种方式 4.Stream的中间操作及其测试 5.Stream的终止操作及其测试 六.Optional类的使用 O
-
Redis Stream类型的使用详解
目录 一.背景 二.redis中Stream类型的特点 三.Stream的结构 四.Stream的命令 1.XADD 往Stream末尾添加消息 1.命令格式 2.举例 2.XRANGE查看Stream中的消息 1.命令格式 2.准备数据 3.举例 3.XREVRANGE反向查看Stream中的消息 4.XDEL删除消息 1.命令格式 2.准备数据 3.举例 5.XLEN查看Stream中元素的长度 1.命令格式 2.举例 6.XTRIM对Stream中的元素进行修剪 1.命令格式 2.准备数据