解决Pandas的DataFrame输出截断和省略的问题
我们看一个现象:
import pandas as pd
titanic = pd.read_csv('titanic_data.csv')
print(titanic.head())
Titanic_data.csv是kaggle上的泰坦尼克数据集,通过pandas读入到一个dataframe中,我们看看其前5行记录。输出结果如下:
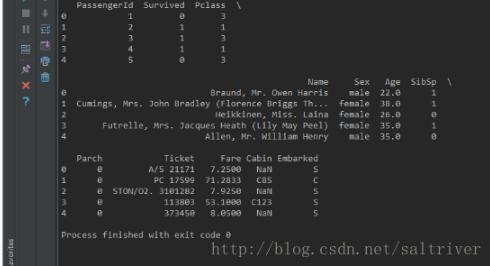
可以看到,记录被分成了3段截断输出,如果想在一行输出,该怎么办呢?这就需要设置pandas的option选项:
pd.set_option('display.width',200)
再看输出,这次5条记录在一行中显示了。

同时,我们注意到,索引为1的记录中,Name有省略号,并没有显示全。这时需要调整列宽。
pd.set_option('display.max_colwidth',100)
看看输出结果,这次显示全了。

同样,我们还可以控制max_row,max_column等参数,使得我们根据实际数据的显示要求进行设置。更多的设置项详见:
https://pandas.pydata.org/pandas-docs/stable/generated/pandas.set_option.html
以上这篇解决Pandas的DataFrame输出截断和省略的问题就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
浅析Python pandas模块输出每行中间省略号问题
关于Python数据分析中pandas模块在输出的时候,每行的中间会有省略号出现,和行与行中间的省略号....问题,其他的站点(百度)中的大部分都是瞎写,根本就是复制黏贴以前的版本,你要想知道其他问题答案就得去读官方文档吧. #!/usr/bin/python # -*- coding: UTF-8 -*- import numpy as np import pandas as pd import MySQLdb df = pd.read_csv('C:\\Users\\Administrato
-
python dataframe 输出结果整行显示的方法
在使用dataframe时遇到datafram在列太多的情况下总是自动换行显示的情况,导致数据阅读困难,效果如下: # -*- coding: utf-8 -*- import numpy as np import pandas as pd df = pd.DataFrame(np.random.randn(1, 20)) print df 显示效果: 0 1 2 3 4 5 6 \ 0 -1.193428 -0.870381 -0.970323 -1.062275 1.227282 -3.01
-
python中pandas.DataFrame排除特定行方法示例
前言 大家在使用Python进行数据分析时,经常要使用到的一个数据结构就是pandas的DataFrame,关于python中pandas.DataFrame的基本操作,大家可以查看这篇文章. pandas.DataFrame排除特定行 如果我们想要像Excel的筛选那样,只要其中的一行或某几行,可以使用isin()方法,将需要的行的值以列表方式传入,还可以传入字典,指定列进行筛选. 但是如果我们只想要所有内容中不包含特定行的内容,却并没有一个isnotin()方法.我今天的工作就遇到了这样的需
-
在Python中Dataframe通过print输出多行时显示省略号的实例
笔者使用Python进行数据分析时,通过print输出Dataframe中的数据,当Dataframe行数很多时,中间部分显示省略号,如下图所示: 0 项华祥 1 何炅 2 张艺飞 3 李仁港 4 崔龄燕 5 董春泽 6 邓超.俞白眉 7 叶伟信,邹凯光 8 肖洋 ... 57 刘镇伟 58 周拓如 59 陆剑青.梁乐民 60 陈木胜 61 李仁港 62 许安.杨龙澄 63 吴天明 64 李骏 65 申太罗 66 吕寅荣.亚历山德罗·卡罗尼 67 罗兰·艾默里奇 68 布莱恩·辛格 69 安东尼
-
pandas.DataFrame选取/排除特定行的方法
pandas.DataFrame选取特定行 使用Python进行数据分析时,经常要使用到的一个数据结构就是pandas的DataFrame,如果我们想要像Excel的筛选那样,只要其中的一行或某几行,可以使用isin()方法,将需要的行的值以列表方式传入,还可以传入字典,指定列进行筛选. >>> df = pd.DataFrame([['GD', 'GX', 'FJ'], ['SD', 'SX', 'BJ'], ['HN', 'HB', 'AH'], ['HEN', 'HEN', 'HL
-
解决pandas.DataFrame.fillna 填充Nan失败的问题
如果单独是 >>> df.fillna(0) >>> print(df) # 可以看到未发生改变 >>> print(df.fillna(0)) # 如果直接打印是可以看到填充进去了 >>> print(df) # 但是再次打印就会发现没有了,还是Nan 将其Nan全部填充为0,这时再打印的话会发现根本未填充,这是因为没有加上参数inplace参数. 一定要将inplace = True加入参数,这样才能让源数据发生改变并保存. &g
-
浅谈pandas中DataFrame关于显示值省略的解决方法
python的pandas库是一个非常好的工具,里面的DataFrame更是常用且好用,最近是越用越觉得设计的漂亮,pandas的很多细节设计的都非常好,有待使用过程中发掘. 好了,发完感慨,说一下最近DataFrame遇到的一个细节: 在使用DataFrame中有时候会遇到表格中的value显示不完全,像下面这样: In: import pandas as pd longString = u'''真正的科学家应当是个幻想家:谁不是幻想家,谁就只能把自己称为实践家.人生的磨难是很多的, 所以我们
-
pandas中的DataFrame按指定顺序输出所有列的方法
问题: 输出新建的DataFrame对象时,DataFrame中各列的显示顺序和DataFrame定义中的顺序不一致. 例如: import pandas as pd grades = [48,99,75,80,42,80,72,68,36,78] df = pd.DataFrame( {'ID': ["x%d" % r for r in range(10)], 'Gender' : ['F', 'M', 'F', 'M', 'F', 'M', 'F', 'M', 'M', 'M'],
-
解决Pandas的DataFrame输出截断和省略的问题
我们看一个现象: import pandas as pd titanic = pd.read_csv('titanic_data.csv') print(titanic.head()) Titanic_data.csv是kaggle上的泰坦尼克数据集,通过pandas读入到一个dataframe中,我们看看其前5行记录.输出结果如下: 可以看到,记录被分成了3段截断输出,如果想在一行输出,该怎么办呢?这就需要设置pandas的option选项: pd.set_option('display.wi
-
解决pandas展示数据输出时列名不能对齐的问题
列名用了中文的缘故,设置pandas的参数即可, 代码如下: import pandas as pd #这两个参数的默认设置都是False pd.set_option('display.unicode.ambiguous_as_wide', True) pd.set_option('display.unicode.east_asian_width', True) 以上这篇解决pandas展示数据输出时列名不能对齐的问题就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们.
-
浅谈pandas中Dataframe的查询方法([], loc, iloc, at, iat, ix)
pandas为我们提供了多种切片方法,而要是不太了解这些方法,就会经常容易混淆.下面举例对这些切片方法进行说明. 数据介绍 先随机生成一组数据: In [5]: rnd_1 = [random.randrange(1,20) for x in xrange(1000)] ...: rnd_2 = [random.randrange(1,20) for x in xrange(1000)] ...: rnd_3 = [random.randrange(1,20) for x in xrange(1
-
pandas实现DataFrame显示最大行列,不省略显示实例
如下所示: import pandas as pd #显示所有列 pd.set_option('display.max_columns', None) #显示所有行 pd.set_options('display.max_rows', None) None可以写具体的数字,写多少就显示多少,默认是显示100行 import pandas as pd pd.set_option('display.height', 1000) pd.set_option('display.max_rows', 50
-
pandas创建DataFrame对象失败的解决方法
目录 报错代码 报错翻译 报错原因 解决方法 创建DataFrame对象的四种方法 1. list列表构建DataFrame 2. dict字典构建DataFrame 3. ndarray创建DataFrame 4. Series创建DataFrame 报错代码 粉丝群一个小伙伴想pandas创建DataFrame对象,但是发生了报错(当时他心里瞬间凉了一大截,跑来找我求助,然后顺利帮助他解决了,顺便记录一下希望可以帮助到更多遇到这个bug不会解决的小伙伴),报错代码如下: import pan
-
pandas中DataFrame重置索引的几种方法
在pandas中,经常对数据进行处理 而导致数据索引顺序混乱,从而影响数据读取.插入等. 小笔总结了以下几种重置索引的方法: import pandas as pd import numpy as np df = pd.DataFrame(np.arange(20).reshape((5, 4)),columns=['a', 'b', 'c', 'd']) #得到df: a b c d 0 0 1 2 3 1 4 5 6 7 2 8 9 10 11 3 12 13 14 15 4 16 17 1
-

pandas中DataFrame数据合并连接(merge、join、concat)
pandas作者Wes McKinney 在[PYTHON FOR DATA ANALYSIS]中对pandas的方方面面都有了一个权威简明的入门级的介绍,但在实际使用过程中,我发现书中的内容还只是冰山一角.谈到pandas数据的行更新.表合并等操作,一般用到的方法有concat.join.merge.但这三种方法对于很多新手来说,都不太好分清使用的场合与用途.今天就pandas官网中关于数据合并和重述的章节做个使用方法的总结. 文中代码块主要有pandas官网教程提供. 1 concat co