python实现随机梯度下降法
看这篇文章前强烈建议你看看上一篇python实现梯度下降法:
一、为什么要提出随机梯度下降算法
注意看梯度下降法权值的更新方式(推导过程在上一篇文章中有)
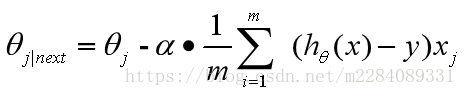
也就是说每次更新权值 都需要遍历整个数据集(注意那个求和符号),当数据量小的时候,我们还能够接受这种算法,一旦数据量过大,那么使用该方法会使得收敛过程极度缓慢,并且当存在多个局部极小值时,无法保证搜索到全局最优解。为了解决这样的问题,引入了梯度下降法的进阶形式:随机梯度下降法。
都需要遍历整个数据集(注意那个求和符号),当数据量小的时候,我们还能够接受这种算法,一旦数据量过大,那么使用该方法会使得收敛过程极度缓慢,并且当存在多个局部极小值时,无法保证搜索到全局最优解。为了解决这样的问题,引入了梯度下降法的进阶形式:随机梯度下降法。
二、核心思想
对于权值的更新不再通过遍历全部的数据集,而是选择其中的一个样本即可(对于程序员来说你的第一反应一定是:在这里需要一个随机函数来选择一个样本,不是吗?),一般来说其步长的选择比梯度下降法的步长要小一点,因为梯度下降法使用的是准确梯度,所以它可以朝着全局最优解(当问题为凸问题时)较大幅度的迭代下去,但是随机梯度法不行,因为它使用的是近似梯度,或者对于全局来说有时候它走的也许根本不是梯度下降的方向,故而它走的比较缓,同样这样带来的好处就是相比于梯度下降法,它不是那么容易陷入到局部最优解中去。
三、权值更新方式

(i表示样本标号下标,j表示样本维数下标)
四、代码实现(大体与梯度下降法相同,不同在于while循环中的内容)
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import axes3d
from matplotlib import style
#构造数据
def get_data(sample_num=1000):
"""
拟合函数为
y = 5*x1 + 7*x2
:return:
"""
x1 = np.linspace(0, 9, sample_num)
x2 = np.linspace(4, 13, sample_num)
x = np.concatenate(([x1], [x2]), axis=0).T
y = np.dot(x, np.array([5, 7]).T)
return x, y
#梯度下降法
def SGD(samples, y, step_size=2, max_iter_count=1000):
"""
:param samples: 样本
:param y: 结果value
:param step_size: 每一接迭代的步长
:param max_iter_count: 最大的迭代次数
:param batch_size: 随机选取的相对于总样本的大小
:return:
"""
#确定样本数量以及变量的个数初始化theta值
m, var = samples.shape
theta = np.zeros(2)
y = y.flatten()
#进入循环内
loss = 1
iter_count = 0
iter_list=[]
loss_list=[]
theta1=[]
theta2=[]
#当损失精度大于0.01且迭代此时小于最大迭代次数时,进行
while loss > 0.01 and iter_count < max_iter_count:
loss = 0
#梯度计算
theta1.append(theta[0])
theta2.append(theta[1])
#样本维数下标
rand1 = np.random.randint(0,m,1)
h = np.dot(theta,samples[rand1].T)
#关键点,只需要一个样本点来更新权值
for i in range(len(theta)):
theta[i] =theta[i] - step_size*(1/m)*(h - y[rand1])*samples[rand1,i]
#计算总体的损失精度,等于各个样本损失精度之和
for i in range(m):
h = np.dot(theta.T, samples[i])
#每组样本点损失的精度
every_loss = (1/(var*m))*np.power((h - y[i]), 2)
loss = loss + every_loss
print("iter_count: ", iter_count, "the loss:", loss)
iter_list.append(iter_count)
loss_list.append(loss)
iter_count += 1
plt.plot(iter_list,loss_list)
plt.xlabel("iter")
plt.ylabel("loss")
plt.show()
return theta1,theta2,theta,loss_list
def painter3D(theta1,theta2,loss):
style.use('ggplot')
fig = plt.figure()
ax1 = fig.add_subplot(111, projection='3d')
x,y,z = theta1,theta2,loss
ax1.plot_wireframe(x,y,z, rstride=5, cstride=5)
ax1.set_xlabel("theta1")
ax1.set_ylabel("theta2")
ax1.set_zlabel("loss")
plt.show()
if __name__ == '__main__':
samples, y = get_data()
theta1,theta2,theta,loss_list = SGD(samples, y)
print(theta) # 会很接近[5, 7]
painter3D(theta1,theta2,loss_list)
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-

梯度下降法介绍及利用Python实现的方法示例
本文主要给大家介绍了梯度下降法及利用Python实现的相关内容,分享出来供大家参考学习,下面话不多说,来一起看看详细的介绍吧. 梯度下降法介绍 梯度下降法(gradient descent),又名最速下降法(steepest descent)是求解无约束最优化问题最常用的方法,它是一种迭代方法,每一步主要的操作是求解目标函数的梯度向量,将当前位置的负梯度方向作为搜索方向(因为在该方向上目标函数下降最快,这也是最速下降法名称的由来). 梯度下降法特点:越接近目标值,步长越小,下降速度越慢. 直观上
-
python梯度下降法的简单示例
梯度下降法的原理和公式这里不讲,就是一个直观的.易于理解的简单例子. 1.最简单的情况,样本只有一个变量,即简单的(x,y).多变量的则可为使用体重或身高判断男女(这是假设,并不严谨),则变量有两个,一个是体重,一个是身高,则可表示为(x1,x2,y),即一个目标值有两个属性. 2.单个变量的情况最简单的就是,函数hk(x)=k*x这条直线(注意:这里k也是变化的,我们的目的就是求一个最优的 k).而深度学习中,我们是不知道函数的,也就是不知道上述的k. 这里讨论单变量的情况: 在不知道
-
Python语言描述随机梯度下降法
1.梯度下降 1)什么是梯度下降? 因为梯度下降是一种思想,没有严格的定义,所以用一个比喻来解释什么是梯度下降. 简单来说,梯度下降就是从山顶找一条最短的路走到山脚最低的地方.但是因为选择方向的原因,我们找到的的最低点可能不是真正的最低点.如图所示,黑线标注的路线所指的方向并不是真正的地方. 既然是选择一个方向下山,那么这个方向怎么选?每次该怎么走? 先说选方向,在算法中是以随机方式给出的,这也是造成有时候走不到真正最低点的原因. 如果选定了方向,以后每走一步,都是选择最陡的方向,直到最低点.
-
python+numpy+matplotalib实现梯度下降法
这个阶段一直在做和梯度一类算法相关的东西,索性在这儿做个汇总, 一.算法论述 梯度下降法(gradient descent)别名最速下降法(曾经我以为这是两个不同的算法-.-),是用来求解无约束最优化问题的一种常用算法.下面以求解线性回归为题来叙述: 设:一般的线性回归方程(拟合函数)为:(其中的值为1) 则这一组向量参数选择的好与坏就需要一个机制来评估,据此我们提出了其损失函数为(选择均方误差): 我们现在的目的就是使得损失函数取得最小值,即目标函数为: 如果的值取到了0,意味着我们构造出了
-
Python编程实现线性回归和批量梯度下降法代码实例
通过学习斯坦福公开课的线性规划和梯度下降,参考他人代码自己做了测试,写了个类以后有时间再去扩展,代码注释以后再加,作业好多: import numpy as np import matplotlib.pyplot as plt import random class dataMinning: datasets = [] labelsets = [] addressD = '' #Data folder addressL = '' #Label folder npDatasets = np.zer
-
python实现随机梯度下降法
看这篇文章前强烈建议你看看上一篇python实现梯度下降法: 一.为什么要提出随机梯度下降算法 注意看梯度下降法权值的更新方式(推导过程在上一篇文章中有) 也就是说每次更新权值都需要遍历整个数据集(注意那个求和符号),当数据量小的时候,我们还能够接受这种算法,一旦数据量过大,那么使用该方法会使得收敛过程极度缓慢,并且当存在多个局部极小值时,无法保证搜索到全局最优解.为了解决这样的问题,引入了梯度下降法的进阶形式:随机梯度下降法. 二.核心思想 对于权值的更新不再通过遍历全部的数据集,而是选择其中
-
python机器学习逻辑回归随机梯度下降法
目录 写在前面 随机梯度下降法 参考文献 写在前面 随机梯度下降法就在随机梯度上.意思就是说当我们在初始点时想找到下一点的梯度,这个点是随机的.全批量梯度下降是从一个点接着一点是有顺序的,全部数据点都要求梯度且有顺序. 全批量梯度下降虽然稳定,但速度较慢: SGD虽然快,但是不够稳定 随机梯度下降法 随机梯度下降法(Stochastic Gradient Decent, SGD)是对全批量梯度下降法计算效率的改进算法.本质上来说,我们预期随机梯度下降法得到的结果和全批量梯度下降法相接近:SGD的
-
Spark MLlib随机梯度下降法概述与实例
机器学习算法中回归算法有很多,例如神经网络回归算法.蚁群回归算法,支持向量机回归算法等,其中也包括本篇文章要讲述的梯度下降算法,本篇文章将主要讲解其基本原理以及基于Spark MLlib进行实例示范,不足之处请多多指教. 梯度下降算法包含多种不同的算法,有批量梯度算法,随机梯度算法,折中梯度算法等等.对于随机梯度下降算法而言,它通过不停的判断和选择当前目标下最优的路径,从而能够在最短路径下达到最优的结果.我们可以在一个人下山坡为例,想要更快的到达山低,最简单的办法就是在当前位置沿着最陡峭的方向下
-
Python实现批量梯度下降法(BGD)拟合曲线
1. 导入库 import numpy as np #矩阵运算 import matplotlib.pyplot as plt #可视化 import random #产生数据扰动 2. 产生数据 拟合曲线 y = 2 × x2 + x + 1 X_m = np.mat([[i**2, i, 1] for i in range(-10,10)]) #矩阵类型,用于运算 y_m = np.mat([[2*x[0,0]+x[0,1]+1+random.normalvariate(0,1)] for
-
python实现随机梯度下降(SGD)
使用神经网络进行样本训练,要实现随机梯度下降算法.这里我根据麦子学院彭亮老师的讲解,总结如下,(神经网络的结构在另一篇博客中已经定义): def SGD(self, training_data, epochs, mini_batch_size, eta, test_data=None): if test_data: n_test = len(test_data)#有多少个测试集 n = len(training_data) for j in xrange(epochs): random.shuf
-
Python模拟随机游走图形效果示例
本文实例讲述了Python模拟随机游走图形效果.分享给大家供大家参考,具体如下: 在python中,可以利用数组操作来模拟随机游走. 下面是一个单一的200步随机游走的例子,从0开始,步长为1和-1,且以相等的概率出现.纯Python方式实现,使用了内建的 random 模块: # 随机游走 import matplotlib.pyplot as plt import random position = 0 walk = [position] steps = 200 for i in range
-
Keras SGD 随机梯度下降优化器参数设置方式
SGD 随机梯度下降 Keras 中包含了各式优化器供我们使用,但通常我会倾向于使用 SGD 验证模型能否快速收敛,然后调整不同的学习速率看看模型最后的性能,然后再尝试使用其他优化器. Keras 中文文档中对 SGD 的描述如下: keras.optimizers.SGD(lr=0.01, momentum=0.0, decay=0.0, nesterov=False) 随机梯度下降法,支持动量参数,支持学习衰减率,支持Nesterov动量 参数: lr:大或等于0的浮点数,学习率 momen