python实现下载pop3邮件保存到本地
利用python进行unix管理一书中有一个登陆下载邮箱的脚本,实练了下还不错,对于邮箱备份来说还是比较快捷的,但是其命名方式是以编号和 文件大小来命名的,不方便阅读,于是进行了改进修改为发件人邮件地址命名,可能由于跨度时间较长,邮件排版有改变,有些邮件获取发件人的时候不能正确匹配。
1、命名方式是以编号和 文件大小来命名
#!/usr/bin/env python
#-*- coding: utf-8 -*-
#filename:receive_pop3_email_download.py
import poplib
username = 'dxx_study'
passwd = 'xXXXXXXX'
mail_server = 'pop.163.com'
p = poplib.POP3(mail_server)
p.user(username)
p.pass_(passwd)
for msg_id in p.list()[1]:
print msg_id
outf = open('%s.eml' % msg_id, 'w')
outf.write('\n'.join(p.retr(msg_id)[1]))
outf.close()
p.quit()
输出:
>>> ================================ RESTART ================================ >>> 1 6189 2 14284 3 1712 4 24912 5 129052 6 1399 7 23298 8 47902 9 2334 10 48887 11 1081 12 34930 13 2098 14 26316 15 32381 16 1822

2、发件人邮件地址命名
#!/usr/bin/env python
#-*- coding: utf-8 -*-
#filename:receive_pop3_email.py
import poplib, re
username = 'dxx_study'
passwd = 'xuXXXXXu'
mail_server = 'pop.163.com'
p = poplib.POP3(mail_server)
#p.set_debuglevel(2)#设置调试信息打印级别
#s = p.getwelcome()#打印欢迎信息
p.user(username)
p.pass_(passwd)
p.stat()
#p.list()#返回收件箱邮件数目,邮件大小,与p.list()[0]相同
#p.retr(42)#提取对应邮件的内容
#print p.top(42,42)#提取对应邮件,可以对内容按行数提取
#p.uidl()#Return message digest (unique id) list
#p.list()[1]#依次返回每个邮件大小,如['1 6189', '2 14284', '3 1712',....]
#p.retr(2)[0]#返回第二封个邮件14284 octets大小
def file_name(text):#这个匹配效率比较低,值得改进
pattern = u"Sender: (.*)"
file_name = re.search(pattern, text, re.I)
if file_name == None:
exit
else:
return file_name.group(1)
def download_mail():
for msg_id in p.list()[1]:
retr = p.retr(msg_id)[1]
for i in range(0,len(retr)):
name = file_name(retr[i])#利用filename进行正则匹配获取发件人
if name == None:
exit
else:
outf = open('%s.eml' % name, 'w')
outf.write('\n'.join(retr))
outf.close()
download_mail()
p.quit()
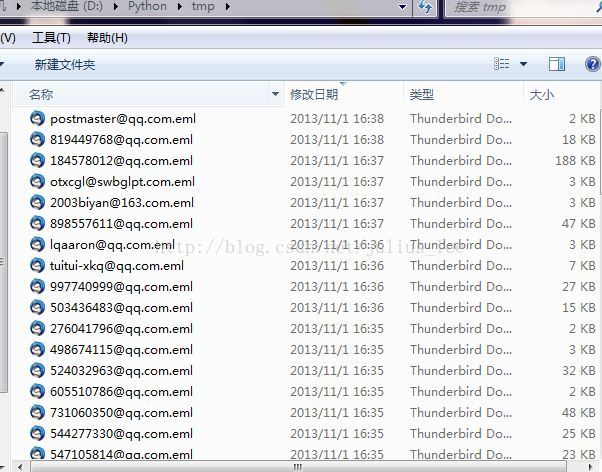
以上功能对于备份邮件还是比较有用的,因为附件也下载下来了。由于pop3邮件服务比较过时了,服务也不够稳定,目前采用IMAP的比较流行,后面有空再写个支持后者的,能支持用户自己输入选择,提取各个邮件客户端的。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
python+POP3实现批量下载邮件附件
最近新开学,接到了给老板的本科课程当助教的工作,百十来号人一学期下来得有四五次作业发进邮箱里,需要我来统计打分,想想挨个点进去下载附件的过程就头大,于是萌生了写个脚本来统计作业的想法. 其实python里收发邮件都有很方便的包,合理使用就好,可以解决绝大多数的邮件收发任务.但是这个脚本写下来还是花了不少时间,其中最大的一部分时间是花在了python的编码问题上,python2和python3的编码预设有些许的不一样,在python3中又取消了unicode这个方法,这就导致很多在python2中
-
python实现批量解析邮件并下载附件
python中的email模块可以方便的解析邮件,先上代码 #-*- encoding: gb2312 -*- import os import email def mail_to_text(mailname,datapath,index): #由于批处理的邮件包含的附件名称相同,这里传入一个index作为区别符 fp=open(mailname,"r") msg=email.message_from_file(fp) for par in msg.walk(): if not par
-
python登录pop3邮件服务器接收邮件的方法
本文实例讲述了python登录pop3邮件服务器接收邮件的方法.分享给大家供大家参考.具体实现方法如下: import poplib, string PopServerName = "mail.yourserver.com" PopServer = poplib.POP3(PopServerName) print PopServer.getwelcome() PopServer.user('yourName') PopServer.pass_('yourPass') r, items,
-
python实现下载pop3邮件保存到本地
利用python进行unix管理一书中有一个登陆下载邮箱的脚本,实练了下还不错,对于邮箱备份来说还是比较快捷的,但是其命名方式是以编号和 文件大小来命名的,不方便阅读,于是进行了改进修改为发件人邮件地址命名,可能由于跨度时间较长,邮件排版有改变,有些邮件获取发件人的时候不能正确匹配. 1.命名方式是以编号和 文件大小来命名 #!/usr/bin/env python #-*- coding: utf-8 -*- #filename:receive_pop3_email_download.py i
-
用Python下载一个网页保存为本地的HTML文件实例
我们可以用Python来将一个网页保存为本地的HTML文件,这需要用到urllib库. 比如我们要下载山东大学新闻网的一个页面,该网页如下: 实现代码如下: import urllib.request def getHtml(url): html = urllib.request.urlopen(url).read() return html def saveHtml(file_name, file_content): # 注意windows文件命名的禁用符,比如 / with open(fil
-
java 从服务器下载文件并保存到本地的示例
昨天在做一个项目时,用到了从服务器上下载文件并保存到本地的知识,以前也没有接触过,昨天搞了一天,这个小功能实现了,下面就简单的说一下实现过程: 1.基础知识 当我们想要下载网站上的某个资源时,我们会获取一个url,它是服务器定位资源的一个描述,下载的过程有如下几步: (1)客户端发起一个url请求,获取连接对象. (2)服务器解析url,并且将指定的资源返回一个输入流给客户. (3)建立存储的目录以及保存的文件名. (4)输出了写数据. (5)关闭输入流和输出流. 2.实现代码的方法 /** *
-
python小技巧——将变量保存在本地及读取
在用jupyter notebook写python代码的过程中会产生很多变量,而关闭后或者restart jupyter kernel后所有变量均会消失,想要查看变量就必须将代码重新再运行一遍,而想在另一个jupyter notebook中调用变量就更加麻烦.在运行时间很长的代码中将变量保存下来能够节省很多事. 那就开始吧! 我用到的包是pickle 1.在使用之前首先需要导入包: import pickle 2.导入包后即可开始实质性操作,我们定义保存变量和读取变量的函数. 保存变量函数: d
-

python做图片搜索引擎并保存到本地详情
前言 我们先说一下思路:先对目标网站发送请求,获取html源码,然后对源码里面的所以图片链接进行筛选,然后再次对图片链接发送请求,然后保存. 思路大致是这样,话不多说,直接上代码: 用到的模块: import requests #请求库 第三方库,需要安装: pip install requests import re #筛选库,py自带,无需安装 查找接口: 打开F12打开开发者工具,点击网络.Fetch/XHR.载荷.依次点下去,可以看到查询参数有两个,分别是:word:风景图
-
vue中如何下载文件导出保存到本地
目录 vue下载文件导出保存到本地 另一种情况 vue中a标签下载本地文件-未找到,原因及解决 错误代码 原因 解决 vue下载文件导出保存到本地 先分析如何下载:先有一个链接地址,然后使用 location.href或window.open()下载到本地 看看返回数据 res.config.url 中是下载链接地址,res.data 中是返回的二进制数据 如何下载 ... <el-button icon="el-icon-download" @click="downl
-
PHP实现下载远程图片保存到本地的方法
在使用 PHP 做简单的爬虫的时候,我们经常会遇到需要下载远程图片的需求,所以下面来简单实现这个需求. 1.使用 curl 比如我们有下面这两张图片: $images = [ 'https://dn-laravist.qbox.me/2015-09-22_00-17-06j.png', 'https://dn-laravist.qbox.me/2015-09-23_00-58-03j.png' ]; 第一步,我们可以直接来使用最简单的代码实现: function download($url, $
-
php获取远程图片并下载保存到本地的方法分析
本文实例讲述了php获取远程图片并下载保存到本地的方法.分享给大家供大家参考,具体如下: 远程图片指的是远端服务器上的数据我们可以通过php的许多函数来读取下载了,这里整理了两个可以自动下载远程图片并下载保存到本地的例子. 例1,可以自动识别图片类型然后进行对应的保存 /* *功能:php完美实现下载远程图片保存到本地 *参数:文件url,保存文件目录,保存文件名称,使用的下载方式 *当保存文件名称为空时则使用远程文件原来的名称 */ function getImage($url,$save_d
-
分享PHP源码批量抓取远程网页图片并保存到本地的实现方法
做为一个仿站工作者,当遇到网站有版权时甚至加密的时候,WEBZIP也熄火,怎么扣取网页上的图片和背景图片呢.有时候,可能会想到用火狐,这款浏览器好像一个强大的BUG,文章有版权,屏蔽右键,火狐丝毫也不会被影响. 但是作为一个热爱php的开发者来说,更多的是喜欢自己动手.所以,我就写出了下面的一个源码,php远程抓取图片小程序.可以读取css文件并抓取css代码中的背景图片,下面这段代码也是针对抓取css中图片而编写的. <?php header("Content-Type: text/ht
-
详解Python下载图片并保存本地的两种方式
一:使用Python中的urllib类中的urlretrieve()函数,直接从网上下载资源到本地,具体代码: import os,stat import urllib.request img_url="https://timgsa.baidu.com/timg?image&quality=80&size=b9999_10000&sec=1516371301&di=d99af0828bb301fea27c2149a7070" \ "d44&am