深入浅析Node.js单线程模型
Node.js采用 事件驱动 和 异步I/O 的方式,实现了一个单线程、高并发的运行时环境,而单线程就意味着同一时间只能做一件事,那么Node.js如何利用单线程来实现高并发和异步I/O?本文将围绕这个问题来探讨Node.js的单线程模型:
1、高并发
一般来说,高并发的解决方案就是多线程模型,服务器为每个客户端请求分配一个线程,使用同步I/O,系统通过线程切换来弥补同步I/O调用的时间开销,比如Apache就是这种策略,由于I/O一般都是耗时操作,因此这种策略很难实现高性能,但非常简单,可以实现复杂的交互逻辑。
而事实上,大多数网站的服务器端都不会做太多的计算,它们只是接收请求,交给其它服务(比如从数据库读取数据),然后等着结果返回再发给客户端。因此,Node.js针对这一事实采用了单线程模型来处理,它不会为每个接入请求分配一个线程,而是用一个主线程处理所有的请求,然后对I/O操作进行异步处理,避开了创建、销毁线程以及在线程间切换所需的开销和复杂性。
2、事件循环
Node.js 在主线程中维护了一个事件队列,当接收到请求后,就将请求作为一个事件放入该队列中,然后继续接收其他请求。当主线程空闲时(没有请求接入时),就开始循环事件队列,检查队列中是否有要处理的事件,这时要分两种情况:如果是非I/O任务,就亲自处理,并通过回调函数返回到上层调用;如果是I/O任务,就从线程池中拿出一个线程来执行这个事件,并指定回调函数,然后继续循环队列中的其他事件。当线程中的I/O任务完成后,就执行指定的回调函数,并把这个完成的事件放到事件队列的尾部,等待事件循环,当主线程再次循环到该事件时,就直接处理并返回给上层调用。 这个过程就叫事件循环(Event Loop),如下图所示:
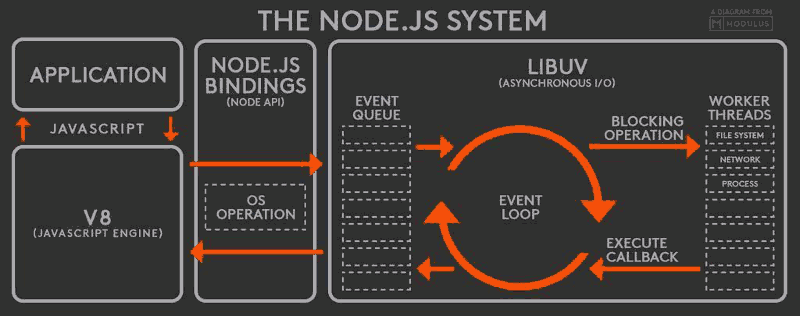
这个图是整个Node.js的运行原理,从左到右,从上到下,Node.js被分成了四层,分别是应用层、V8引擎层、Node API层 和 LIBUV层,
应用层: 即Javascript交互层,常见的就是Node.js的模块,比如 http,fs
V8引擎层: 即利用V8引擎来解析Javascript语法,进而和下层API交互
NodeAPI层: 为上层模块提供系统调用,一般是由C语言来实现,和操作系统进行交互
LIBUV层: 即Event Loop,是Node.js实现异步的核心,由LIBUV库来实现,而LIBUV中的线程池是由操作系统内核接受管理的。
从上述理解来看,Node.js的单线程仅仅是指Javascript运行在单线程中,而并非Node.js是单线程,在Node中,无论是Linux平台还是Windows平台,内部都是通过线程池来完成IO操作,而LIBUV就是针对不同平台的差异性实现了统一调用。
3、事件驱动
总结上面的过程可以发现,Node.js的核心是使用事件驱动模式实现了异步I/O,为了更具体、更清晰的理解和接受这个事实,我们用代码来描述Node.js的事件驱动模型:
3.1、事件队列
首先,我们需要定义一个事件队列,既然是队列,那就是一个先进先出(FIFO)的数据结构,我们用JS的数组来描述,如下:
/** * 定义事件队列 * 入队:unshfit() * 出队:pop() * 空队列:length == 0 */ eventQueue:[],
为了方便理解,我们规定:数组的第一个元素是队列的尾部,数组的最后一个元素是队列的头部, unshfit 就是在尾部插入一个元素,pop就是从头部弹出一个元素,这样就实现了一个简单的队列。
3.2、接收请求
定义一个总的入口来接收用户请求,如下所示:
/**
* 接收用户请求
* 每一个请求都会进入到该函数
* 传递参数request和response
*/
processHttpRequest:function(request,response){
//定义一个事件对象
var event = createEvent({
params:request.params, //传递请求参数
result:null, //存放请求结果
callback:function(){} //指定回调函数
});
//在队列的尾部添加该事件
eventQueue.unshift(event);
},
这个函数很简单,就是把用户的请求包装成事件,放到队列里,然后继续接收其他请求。
3.3、事件循环
当主线程处于空闲时就开始循环事件队列,所以,我们再定义一个事件循环的函数:
/**
* 事件循环主体,主线程择机执行
* 循环遍历事件队列
* 处理事件
* 执行回调,返回给上层
*/
eventLoop:function(){
//如果队列不为空,就继续循环
while(this.eventQueue.length > 0){
//从队列的头部拿出一个事件
var event = this.eventQueue.pop();
//如果是IO任务
if(isIOTask(event)){
//从线程池里拿出一个线程
var thread = getThreadFromThreadPool();
//交给线程处理
thread.handleIOTask(event)
}else {
//非IO任务处理后,直接返回结果
var result = handleEvent(event);
//最终通过回调函数返回给V8,再由V8返回给应用程序
event.callback.call(null,result);
}
}
},
主线程不停的检测事件队列,对于IO任务就交给线程池来处理,非IO任务就自己处理并返回。
3.4、线程池
线程池接到任务以后,直接处理IO操作,比如读取数据库:
当IO
/**
* 处理IO任务
* 完成后将事件添加到队列尾部
* 释放线程
*/
handleIOTask:function(event){
//当前线程
var curThread = this;
//操作数据库
var optDatabase = function(params,callback){
var result = readDataFromDb(params);
callback.call(null,result)
};
//执行IO任务
optDatabase(event.params,function(result){
//返回结果存入事件对象中
event.result = result;
//IO完成后,将不再是耗时任务
event.isIOTask = false;
//将该事件重新添加到队列的尾部
this.eventQueue.unshift(event);
//释放当前线程
releaseThread(curThread)
})
}
任务完成以后就执行回调,把请求结果存入事件中,并将该事件重新放入队列中,等待循环,最后释放线程。当主线程再次循环到该事件时,就直接处理了。
4、Node.js软肋
以上四步简单描述了Node.js事件驱动模型,至此,我们对Node.js应该有了一个简单而又清晰的认识,但Node.js 并不是什么都能做。
上面提到,如果是I/O任务,Nodejs就把任务交给线程池来异步处理,高效简单,因此Node.js适合处理I/O密集型任务,但不是所有的任务都是I/O密集型任务,当碰到CPU密集型任务时,就是只用CPU计算的操作,比如要对数据加解密(node.bcrypt.js),数据压缩和解压(node-tar),这时Node.js就会亲自处理,一个一个的计算,前面的任务没有执行完,后面的任务只能干等着,如下图所示:
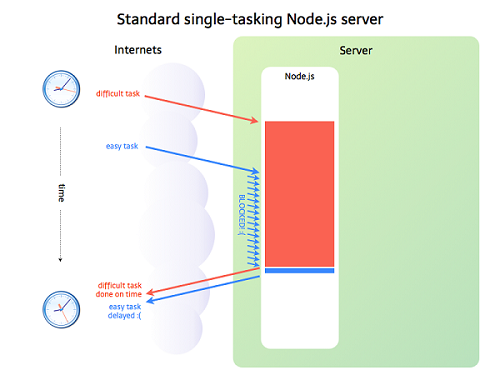
在事件队列中,如果前面的CPU计算任务没有完成,那么后面的任务就会被阻塞,出现响应缓慢的情况,如果操作系统本身就是单核,那也就算了,但现在大部分服务器都是多CPU或多核的,而Node.js只有一个EventLoop,也只占用一个CPU/内核,当Node.js被CPU密集型任务占用,导致其他任务被阻塞时,却还有CPU/内核处理闲置状态,造成资源浪费。因此Node.js不适合CPU密集型任务。
5、Node.js适用场景
5.1、RESTful API
这是适合 Node 的理想情况,因为您可以构建它来处理数万条连接。它仍然不需要大量逻辑;它本质上只是从某个数据库中查找一些值并将它们组成一个响应。由于响应是少量文本,入站请求也是少量的文本,因此流量不高,一台机器甚至也可以处理最繁忙的公司的 API 需求。
5.2、实时程序
比如聊天服务,聊天应用程序是最能体现 Node.js 优点的例子:轻量级、高流量并且能良好的应对跨平台设备上运行密集型数据(虽然计算能力低)。同时,聊天也是一个非常值得学习的用例,因为它很简单,并且涵盖了目前为止一个典型的 Node.js 会用到的大部分解决方案。
以上所述是小编给大家介绍的Node.js单线程模型,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
相关推荐
-
Node.js事件循环(Event Loop)和线程池详解
Node的"事件循环"(Event Loop)是它能够处理大并发.高吞吐量的核心.这是最神奇的地方,据此Node.js基本上可以理解成"单线程",同时还允许在后台处理任意的操作.这篇文章将阐明事件循环是如何工作的,你也可以感受到它的神奇. 事件驱动编程 理解事件循环,首先要理解事件驱动编程(Event Driven Programming).它出现在1960年.如今,事件驱动编程在UI编程中大量使用.JavaScript的一个主要用途是与DOM交互,所以使用基于事件
-

深入浅析Node.js单线程模型
Node.js采用 事件驱动 和 异步I/O 的方式,实现了一个单线程.高并发的运行时环境,而单线程就意味着同一时间只能做一件事,那么Node.js如何利用单线程来实现高并发和异步I/O?本文将围绕这个问题来探讨Node.js的单线程模型: 1.高并发 一般来说,高并发的解决方案就是多线程模型,服务器为每个客户端请求分配一个线程,使用同步I/O,系统通过线程切换来弥补同步I/O调用的时间开销,比如Apache就是这种策略,由于I/O一般都是耗时操作,因此这种策略很难实现高性能,但非常简单,可以实
-
深入浅析Node.js 事件循环
Node.js 是单进程单线程应用程序,但是通过事件和回调支持并发,所以性能非常高. (来源于Javascript是单线程又是异步的,但是这种语言有个共同的特点:它们是 event-driven 的.驱动它们的 event 来自一个异构的平台.) Node.js 的每一个 API 都是异步的,并作为一个独立线程运行,使用异步函数调用,并处理并发. Node.js 基本上所有的事件机制都是用设计模式中观察者模式实现. Node.js 单线程类似进入一个while(true)的事件循环,直到没有事件
-
深入浅析Node.js 事件循环、定时器和process.nextTick()
什么是事件循环 尽管JavaScript是单线程的,但通过尽可能将操作放到系统内核执行,事件循环允许Node.js执行非阻塞I/O操作. 由于现代大多数内核都是多线程的,因此它们可以处理在后台执行的多个操作. 当其中一个操作完成时,内核会告诉Node.js,以便可以将相应的回调添加到 轮询队列 中以最终执行. 我们将在本主题后面进一步详细解释. 事件循环解释 当Node.js启动时,它初始化事件循环,处理提供的输入脚本(或放入 REPL ,本文档未涉及),这可能会进行异步API调用,调度计时器或
-
浅析Node.js中使用依赖注入的相关问题及解决方法
最近,我转向使用依赖注入来帮助理解分离代码的简单途径,并有助测试.然而,Node.js中的模块依赖Node提供的系统API,这很难判断私有依赖被恰当的使用.一般的依赖注入很难在这种情况下使用,但现在不要放弃希望. requireCauses 问题 Node.js很容易依照需求导入依赖.它运行的很好,并且比AMD模式加载器例如RequireJS要简单.当我们模拟那些依赖的时候问题就来了.如果Node.js中模型的加载是受控的,我们怎么做才能控制让伪对象在测试期间被使用到?我们可以使用Node的vm
-
快速掌握Node.js事件驱动模型
一.传统线程网络模型 在了解Node.js事件驱动模型之前,我们先了解一下传统的线程网络模型,请求进入web服务器(IIS.Apache)之后,会在线程池中分配一个线程来线性同步完成请求处理,直到请求处理完成并发出响应,结束之后线程池回收. 这就会就会带来以下几个问题 : 1.由于线程池中线程个数有限,对于频繁请求时,就会出现等待,严重的甚至会把服务器挂掉 2.对于高并发的时候,为了防止出现脏数据就会使用锁来解决,一些I/O事务可能消耗很长得时间,这样就会出现一些线程等待,效率低下 二.事件驱动
-
浅析Node.js非对称加密方法
前言 刚回答了SegmentFault上一个兄弟提的问题<非对称解密出错>.这个属于Node.js在安全上的应用,遇到同样问题的人应该不少,基于回答的问题,这里简单总结下. 非对称加密的理论知识,可以参考笔者前面的文章<NODEJS进阶:CRYPTO模块之理论篇>. 完整的代码可以在 <Nodejs学习笔记> 找到,也欢迎大家关注 程序猿小卡的GitHub. 加密.解密方法 在Node.js中,负责安全的模块是crypto.非对称加密中,公钥加密,私钥解密,加解密对应的
-
浅析Node.js查找字符串功能
需求如下: 整个目录下大概有40几M,文件无数,由于时间久了, 记不清那个字符串具体在哪个文件,于是.强大,亮瞎双眼的Node.js闪亮登场: windows下安装Node.js和安装普通软件毫无差别,装完后打开Node.js的快捷方式,或者直接cmd,你懂的. 创建findString.js var path = require("path"); var fs = require("fs"); var filePath = process.argv[2]; var
-
浅析Node.js 中 Stream API 的使用
本文由浅入深给大家介绍node.js stream api,具体详情请看下文吧. 基本介绍 在 Node.js 中,读取文件的方式有两种,一种是用 fs.readFile ,另外一种是利用 fs.createReadStream 来读取. fs.readFile 对于每个 Node.js 使用者来说最熟悉不过了,简单易懂,很好上手.但它的缺点是会先将数据全部读入内存,一旦遇到大文件的时候,这种方式读取的效率就非常低下了. 而 fs.createReadStream 则是通过 Stream 来读取
-
浅析Node.js中的内存泄漏问题
这篇文章是由Mozilla的Identity团队带来的 A Node.JS Holiday Season系列文章的首篇,该团队上个月发布了 Persona的第一个测试版本.在开发Persona时我们构建了一系列的工具,包括了从调试,到本地化,到依赖管理以及更多的方面.在这一系列的文章中我们将与社区分享我们的经验和这些工具,这对任何想用node.js建立一个高可用性服务的人都很有用.我们希望您能喜欢这些文章,并期待看到您的想法和贡献. 我们将从一篇关于Node.js的实质性问题:内存泄漏的主题文章
-
浅析Node.js实现HTTP文件下载
前言 HTTP实现文件下载时,只要在服务器设置好相关响应头,并使用二进制传输文件数据即可,而客户端(浏览器)会根据响应头接收文件数据.而在Node.js中,设置好响应头后,读取文件流,再使用".pipe()"方法将流转接到响应对象Response就可以实现一个简单的文件下载服务器. 1. 文件下载介绍 HTTP基于请求头和响应头实现状态交互,在得到服务器正确响应状态后,而客户端首先会解析响应头,并根据响应头来接收和展示数据(响应体).对于文件下载来说,其实现过程如下: 1.客户端发起文