Python接口自动化 之用例读取方法总结
目录
- 1. Python第三方库xlrd
- xlrd代码演示
- 2. Python第三方库pandas
- pandas代码演示
- 3. Python第三方库yaml
- yaml代码演示
- 总结
前言:
在软件测试中,为项目编写接口自动化用例已成为测试人员常驻的测试工作。本文以python为例,基于笔者曾使用过的三种用例数据读取方法:xlrd、pandas、yaml,下面简要地介绍下它们的使用方法及简单分析。
1. Python第三方库xlrd
xlrd模块可用于读取excel文档,是一种最常用的用例读取方式,使用方式如下。以演示惯例---注册接口为例,首先新建一个excel文档,文档中自定义接口用例参数:
(以下data均为随机生成,不涉及任何系统)
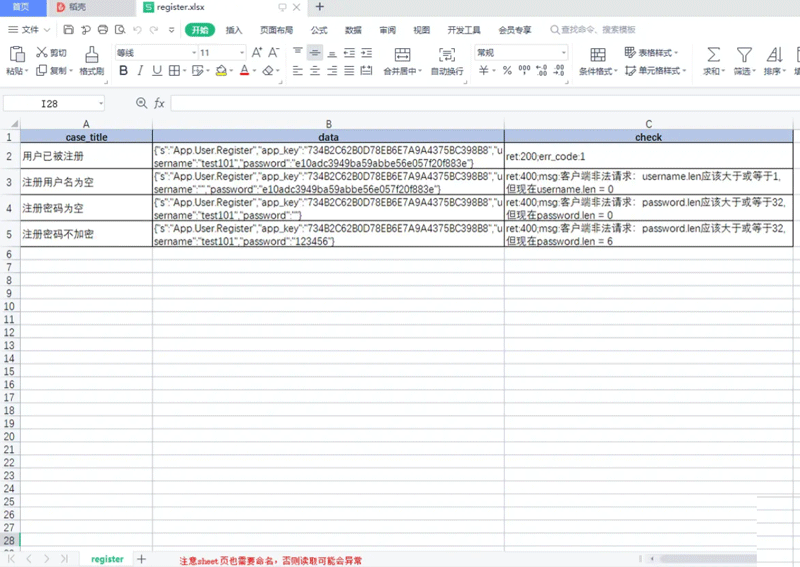
python已安装第三方库后,开始读取接口用例。本次为了方便演示,方法未进行封装。
xlrd代码演示
以下为实例代码:
import unittest
import xlrd
# 打开接口用例excel文件
excel_data = xlrd.open_workbook('register.xlsx')
# 读取excel文件中存放用例的sheet页,命名无要求
sheet = excel_data.sheet_by_name('register')
print(sheet.nrows)
print(sheet.row_values(1))
# 将读取到的用例全部追加到data列表中
data = []
for i in range(1, sheet.nrows):
data.append(sheet.row_values(i))
print(data)
class register(unittest.TestCase):
def test_register_check(self):
pass
执行py文件后,打印读取data列表,成功读取出excel文件中用例数据:
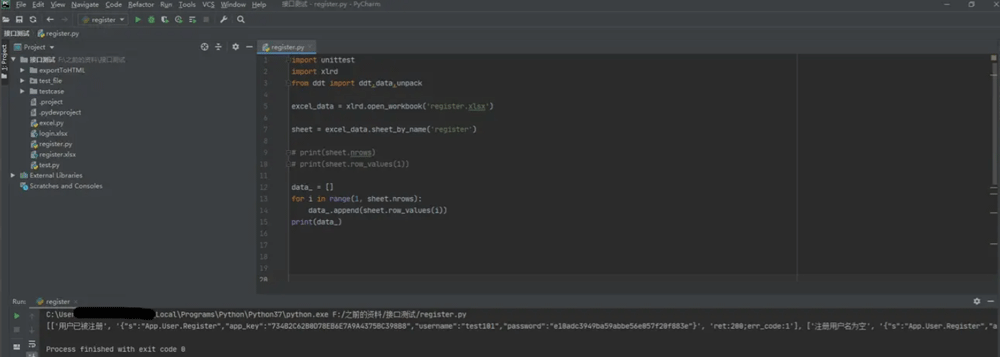
但是上面的方法会把整个excel文件的用例全部存放到一个列表中,数据取用不太方便。现在我们对数据进行拆分,结合ddt数据驱动方式,进行数据读取:
import unittest
import xlrd
from ddt import ddt,data,unpack
excel_data = xlrd.open_workbook('register.xlsx')
sheet = excel_data.sheet_by_name('register')
# print(sheet.nrows)
# print(sheet.row_values(1))
data_ = []
for i in range(1, sheet.nrows):
data_.append(sheet.row_values(i))
print(data_)
# 引入的装饰器@ddt;导入数据的@data;拆分数据的@unpack
@ddt
class register(unittest.TestCase):
@data(*data_)
@unpack
def test_register(self, title, data, check):
print(data)
if __name__ == '__main__':
unittest.main()
通过ddt中的data及unpack方法,excel文件中的每条数据都是一个单独的列表,更便于提供给接口测试用例使用:
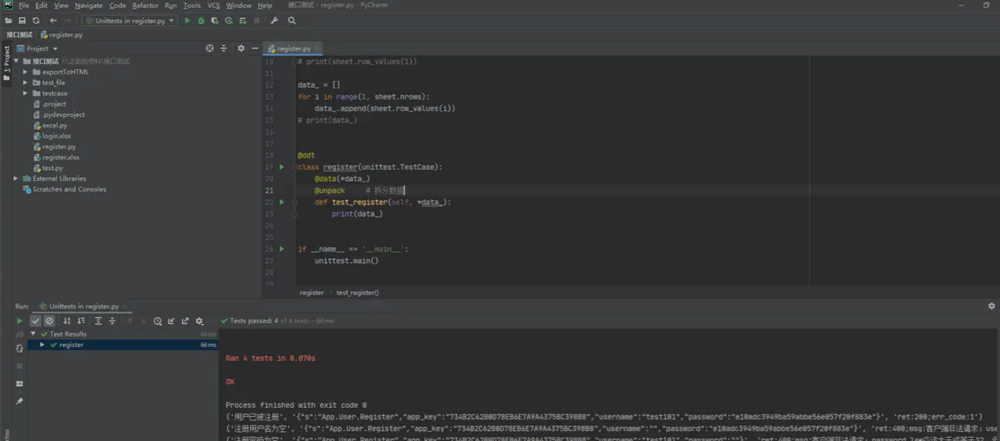
xlrd模块在接口自动化中的使用频率非常高,调用方法也非常简单。读取到excel测试用例后,还可以使用装饰器DDT进行数据拆分,使数据更加简化。
xlrd适用于项目接口数据较少、接口字段不经常调整的项目。如果项目中,接口数量非常多,在编写接口用例时,存放用例的excel文件内容会不断扩充。测试用例的易读性和维护性都会成为后期测试工作的难题,影响测试效率。
2. Python第三方库pandas
pandas是python的一个数据分析包,可帮助使用者处理大型数据集。使用pandas中的DataFrame(二维的表格型数据结构)方法,即可获取到excel表格中的测试数据。pandas与xrld一样,都可读取excel文件。
首先创建一个excel文件,存放测试数据:
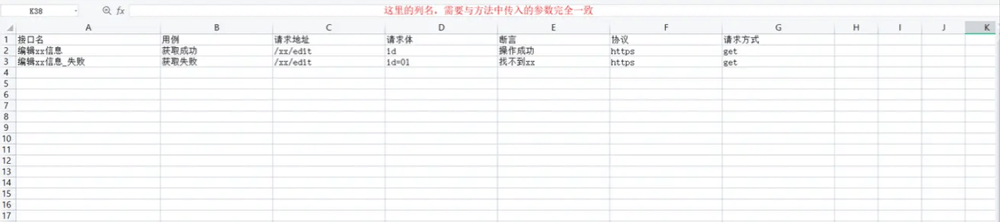
pandas代码演示
实例代码:
# 从excel文件中读取用例,name参数为sheet名称
def read_excel_data(inputdir,name):
dataframe = pandas.DataFrame(columns=['接口名','用例','请求地址','请求体','断言','协议','请求方式']) # 传入参数就是excel文件中的列名
try:
datafile = pandas.read_excel(inputdir,sheet_name=name)
dataframe = dataframe.append(datafile, ignore_index=True, sort=True)
except:
print("Warning:excel文件打开异常,请重试!")
To_list = dataframe.to_dict(orient='records') # 参数='records'时,转化后是 list形式
return To_list
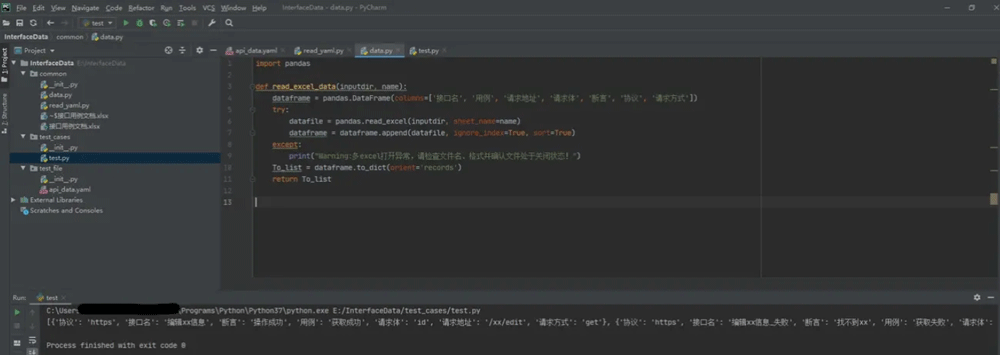
from common.data import read_excel_data
import pytest
def getdata(path):
getdata = read_excel_data(path, '编辑xx')
print(getdata)
path = r'..\common\接口用例文档.xlsx' # excel文件的路径,按实际项目结构指明
getdata(path)
调用封装好的方法,成功读取到excel文件中的全部用例数据:
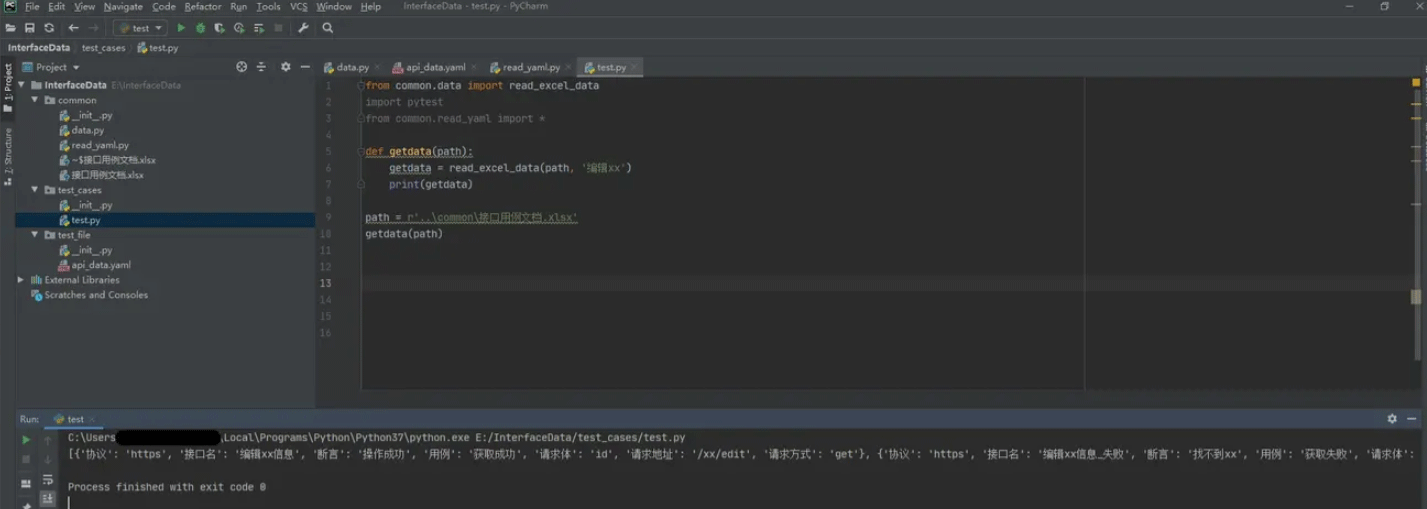
该方法与xlrd类似,也是通过读取二维表格中数据的方式,获取到我们所需接口用例。
通过xlrd等方法读取excel文件中的测试用例,是接口测试中比较主流的数据读取方式。但是通过上面的案例展示可以发现,如果excel文件中的数据越来越多,后期测试的维护成本是比较高的,同时表格格式在大篇幅数据中,也不方便阅读。这也是此类方法的一个弊端。
3. Python第三方库yaml
yaml是一种用来写配置文件的序列化语言,文件格式输出可以是列表、字典,也支持嵌套。层级关系用空格区分,但不支持tab缩进。
破折号和空格( “ - ” ):列表格式
# 以下数据会以list形式被读取 - testapi - url - get
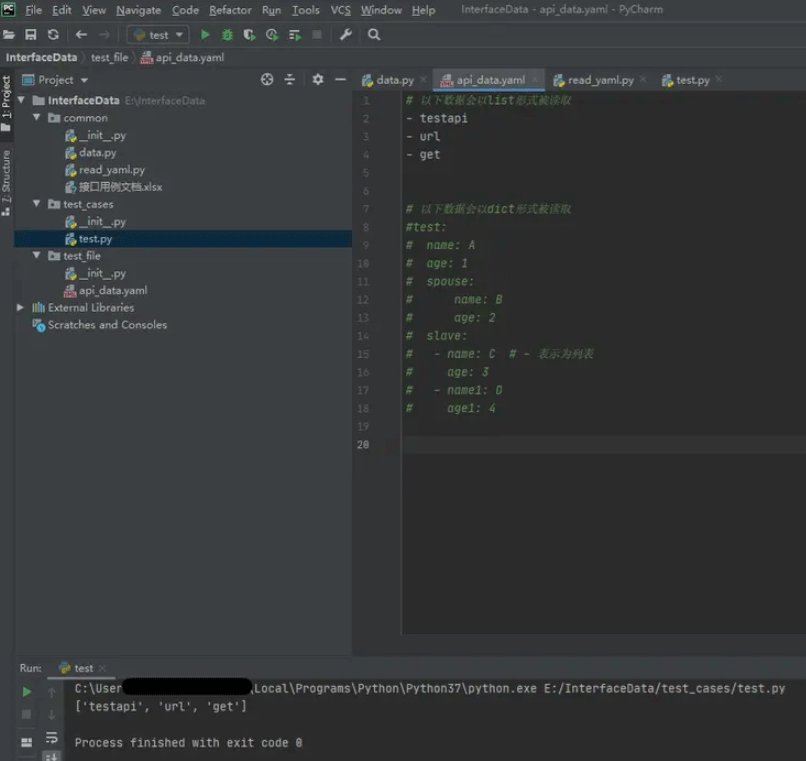
常见的yaml格式:
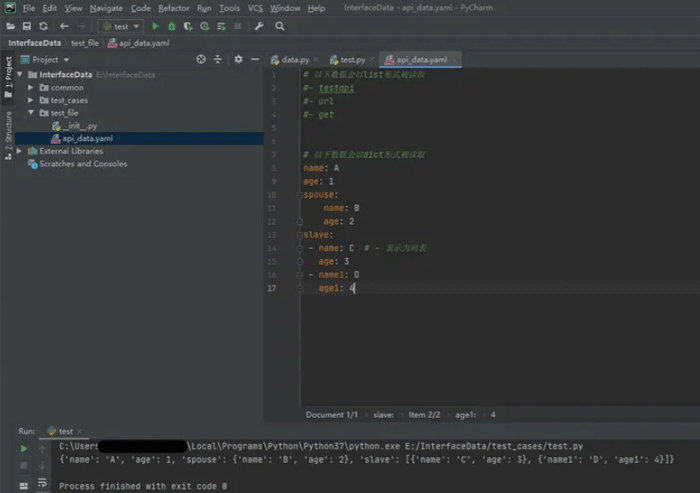
冒号和空格( “ :” ) :字典格式
# 以下数据会以dict形式被读取
name: A
age: 1
spouse:
name: B
age: 2
slave:
- name: C # - 表示为列表
age: 3
- name1: D
age1: 4
yaml代码演示
读取yaml文件中的dict数据,代码如下:
import os
import yaml
class LoadTestData:
# 设置路径,获取yaml文件数据
def load_data(self, file_name):
yaml_path = os.path.join(os.path.join(os.path.dirname(os.path.dirname(os.path.abspath(__file__))), 'test_file'), file_name)
yaml_data = yaml.load(open(yaml_path), Loader=yaml.FullLoader)
# print(yaml_data)
return yaml_data
def get_yaml_data(api_file, api_name):
'''
获取yaml中 api_name的数据
:param api_file: api文件位置
:param api_name: api文件名称
:return: 文件数据
'''
data = LoadTestData().load_data(api_file)[api_name]
print(data)
return data
if __name__ == '__main__':
file_name = 'api_data.yaml'
api_name = 'test'
# LoadTestData().load_data(file_name)
get_yaml_data(file_name,api_name )
print('读取成功')
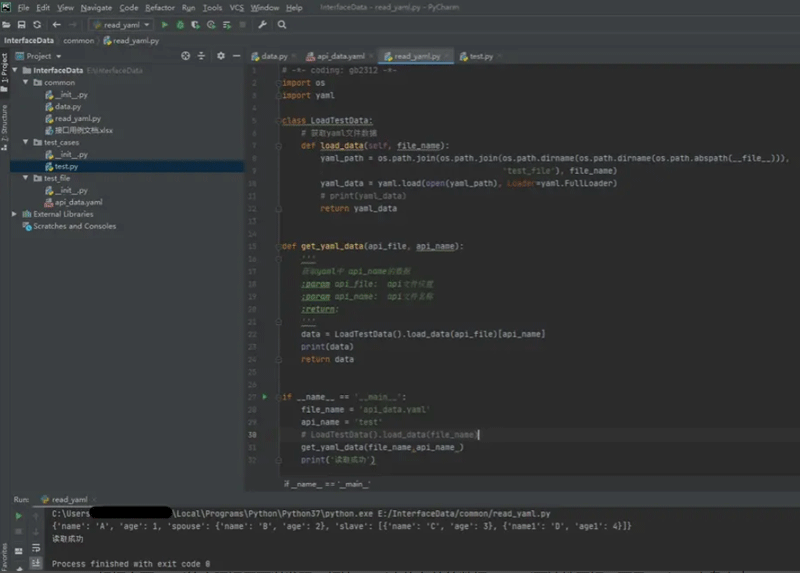
请注意yaml.load在调用时,可能会因为yaml版本较高而提示异常。解决方法:指定loader = yaml.FullLoader可解决异常。
根据上面yaml的实际运用可以发现,相比excel表格存放的数据,yaml可读性更好,而且python本身也支持新建yaml文件,与脚本语言的交互性更佳。对于不同的测试模块,也可以新建不同的yaml文件,实现了功能模块之间的测试数据隔离。
总结
测试中,不管是以excel表格存放数据还是yaml文件存放数据,都能做到快速集成组装测试数据。但excel表格存放数据过大时,有可读性降低及脚本执行时间较长等问题。yaml拥有简洁、与python交互性高,可以把功能模板的测试数据相互隔离等优点。但也需要对yaml的写法规范有一些了解,才能正确使用。
到此这篇关于Python接口自动化 之用例读取方法总结的文章就介绍到这了,更多相关Python 用例读取内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python中playwright结合pytest执行用例的实现
目录 安装pytest插件 编写测试用例 忽略 HTTPS 错误和设置自定义视口大小 持久上下文 playwright结合Pytest为您的 Web 应用程序编写端到端的测试. 安装pytest插件 C:\Users\lifeng01>pip install pytest-playwright Collecting pytest-playwright Using cached pytest_playwright-0.2.2-py3-none-any.whl (9.8 kB) Requiremen
-

Python自动化实战之接口请求的实现
目录 使用 Python 发送 请求 Python 发送请求的方式 requests 库的配置 天行数据 - 空气质量接口 利用 requests 发送查询 空气质量接口 请求 在前文说过,如果想要更好的做接口测试,我们要利用自己的代码基础与代码优势,所以该章节不会再介绍商业化的.通用的接口测试工具,重点介绍如何通过 python 编码来实现我们的接口测试以及通过 Pycharm 的实际应用编写一个简单接口测试. 使用 Python 发送 请求 应为从最开始写这个 Python全栈系列 一直使用
-
Python教程之pytest命令行方式运行用例
目录 前言 pycharm里命令行运行用例 终端中使用pytest 用例全部运行 打印详情-v 指定组别 使用表达式指定某些用例-k 遇到失败即停止运行-x 指定运行某个测试py文件 指定运行某个class 指定运行某个方法: 其他 总结 前言 用命令行方式调用用例是我们最常用的方式,这方面确实比java的TestNG框架要好用许多,至少不用写xml文件,为了提供定制化运行用例的方式,pytest提供了许多运行命令以供定制化运行某一类测试用例或者某个测试用例等: pycharm里命令行运行用例
-
Python接口自动化之文件上传/下载接口详解
目录 〇.前言 一.文件上传接口 1. 接口文档 2. 代码实现 二.文件下载接口 1. 接口文档 2. 代码实现 总结 〇.前言 文件上传/下载接口与普通接口类似,但是有细微的区别. 如果需要发送文件到服务器,例如:上传文档.图片.视频等,就需要发送二进制数据,上传文件一般使用的都是 Content-Type: multipart/form-data 数据类型,可以发送文件,也可以发送相关的消息体数据. 反之,文件下载就是将二进制格式的响应内容存储到本地,并根据需要下载的文件的格式来写文件名,
-
Python接口自动化浅析如何处理动态数据
在上一篇Python接口自动化测试系列文章:Python接口自动化浅析logging封装及实战操作,主要介绍如何提取token.将token作为类属性全局调用及充值接口如何携带token进行请求. 以下主要介绍:接口自动化过程中,动态数据如何生成.动态数据与数据库数据进行对比并替换. 一.应用场景F 注册接口参数需要手机号,手机号如何动态生成? 生成的手机号如何与数据库数据进行对比? 未注册的手机号如何替换用例数据中的手机号? 二.动态手机号处理思路 编写函数,生成随机的手机号: 将生成的手机号
-
python+pytest接口自动化之token关联登录的实现
目录 一. 什么是token 二. token场景处理 这里介绍如下两种处理思路. 1. 思路一 2. 思路二 三. 总结 在PC端登录公司的后台管理系统或在手机上登录某个APP时,经常会发现登录成功后,返回参数中会包含token,它的值为一段较长的字符串,而后续去请求的请求头中都需要带上这个token作为参数,否则就提示需要先登录. 这其实就是状态或会话保持的第三种方式token. 一. 什么是token token 由服务端产生,是客户端用于请求的身份令牌.第一次登录成功时,服务端会生成一个
-
python接口自动化测试数据和代码分离解析
目录 common中存放的是整个项目中公共使用的封装方法 数据分离的第一步先找到工程项目路径 数据分离的第二步封装一个读取yml文件的函数或类方法 数据分离的第三步测试用例中引入数据并运行 common中存放的是整个项目中公共使用的封装方法 从工程目录上可以看到区分 datas中专门存放测试数据(yml文件) cases中专门集中存放测试用例 ... 数据分离的第一步先找到工程项目路径 # -*- encoding: utf-8 -*- """ @__Software__:
-
Python+Opencv答题卡识别用例详解
使用Python3和Opencv识别一张标准的答题卡.大致的过程如下: 1.读取图片 2.利用霍夫圆检测,检测出四个角的黑圆位置,从确定四个角的位置 3.利用透视变换和四个角的位置,矫正图片(直接用的网上的图片,没有拍照,所以这一步没有实现) 4.裁剪四个边框,获取边框上小黑格的位置 5.根据小黑格的位置确定每个涂卡区域的位置 6.将答题卡腐蚀和膨胀,遍历所有的格子的区域,计算每个区域内像素值为0的个数,若数量达到某个值,那么就确认这个格子是被黑笔涂过,并记录该位置的题目选项. 具体的实现 一.
-
Python接口自动化浅析如何处理接口依赖
在前面的Python接口自动化测试系列文章:Python接口自动化浅析logging封装及实战操作, 其中介绍了将logging常用配置放入yaml配置文件.logging日志封装及结合登录用例讲解日志如何在接口测试中运用. 以下主要介绍如何提取token.将token作为类属性全局调用及充值接口如何携带token进行请求. 一.场景说明 在面试接口自动化时,经常会问,其他接口调用的前提条件是当前用户必须是登录状态,如何处理接口依赖? 在此之前我们介绍过session管理器保存会话状态. 如果接
-
python+pytest接口自动化之日志管理模块loguru简介
目录 安装 简单示例 add()常用参数说明 使用 python自带日志管理模块logging,使用时可进行模块化配置,详细可参考博文Python日志采集(详细). 但logging配置起来比较繁琐,且在多进行多线程等场景下使用时,如果不经过特殊处理,则容易出现日志丢失或记录错乱的情况. python中有一个用起来非常简便的第三方日志管理模块--loguru,不仅可以避免logging的繁琐配置,而且可以很简单地避免在logging中多进程多线程记录日志时出现的问题,甚至还可以自定义控制台输出的